






数据预处理
因为不同数据表述的含义不同,将多个数据放在一块就会让人难以进行比较参考,这要是让模型进行学习,不得学废了。如果用官方的语言来说也就是,特征的单位或者大小相差较大,会影响目标的结果,使模型或者算法无法学到其他的特征。
为了解决这一=问题,就需要对数据进行预处理,常见的一般是归一化和标准化,
例如
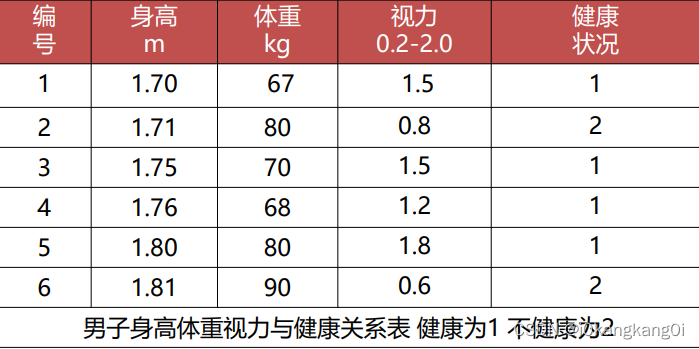 上述方案就是对数据进行标准化处理后的结果。看吧,让数据变得特征更加明显了吧。
上述方案就是对数据进行标准化处理后的结果。看吧,让数据变得特征更加明显了吧。
归一化
这需要运用数学的芝士了,也就是将多个数据特征转换成(0,1)之间,一般默认是这样的。
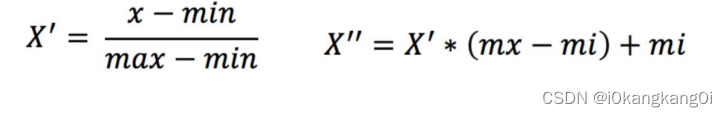
用python代码如何实现
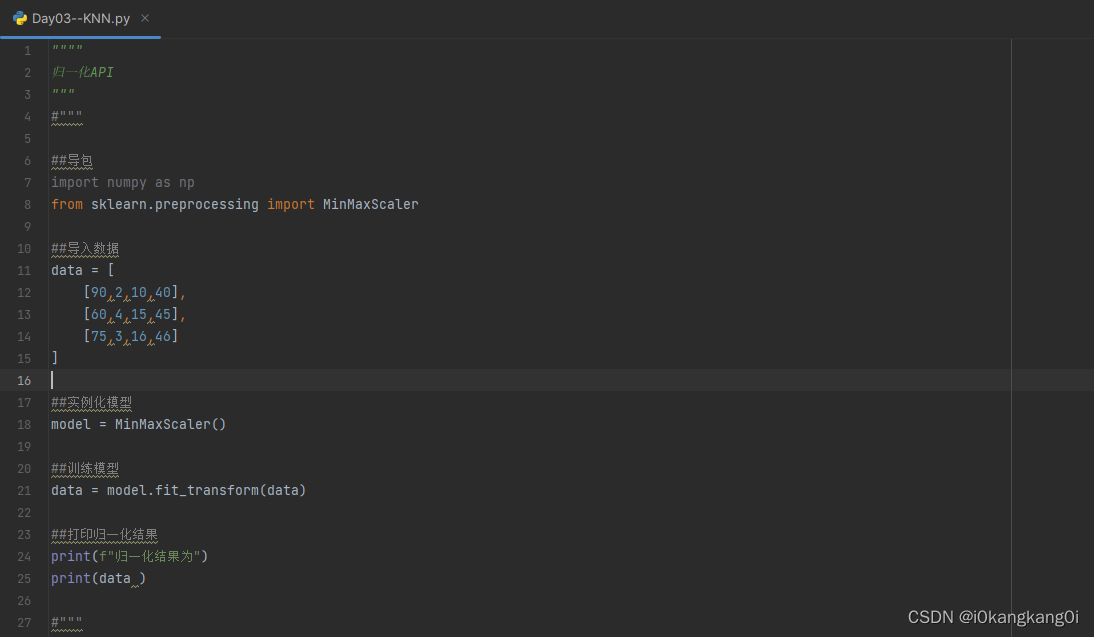
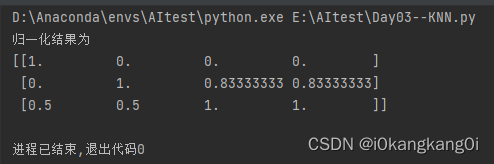
调用数据归一化API,对上述数据data进行归一化处理,运行结果为:
算法实例讲解
对于每个特征,我们计算其最小值𝑋𝑚𝑖𝑛Xmin和最大值𝑋𝑚𝑎𝑥Xmax,然后将每个特征的值进行变换到[0, 1]的范围内。
对于给定的原始数据data:
90 2 10 40
60 4 15 45
75 3 16 46
我们计算每列特征的最小值和最大值如下
第一列特征的最小值为20,最大值为60,最大值为90
再套入上述归一化公式中就可以得出,这一列这一个特征值归一化的结果也就是1.0
对每一个特征重复进行上述操作即可得到这些特征归一化结果。
数据标准化
对数据进行处理将其转换成均值为0,标准差为1的标准正态分布数据。
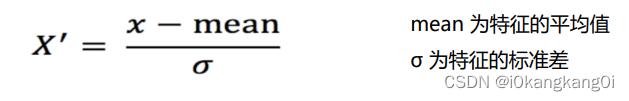
科普一下标准差的求法:


用python代码如何实现

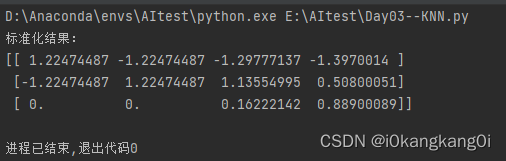
调用数据标准化API,对上述数据data进行标准化处理,运行结果为:
算法实例讲解
我们使用了StandardScaler对数据进行标准化处理。标准化是一种常见的数据预处理技术,它通过将数据转换为均值为0,标准差为1的标准正态分布来消除特征之间的量纲差异。
对于与给定的原始数据
90 2 10 40
60 4 15 45
75 3 13 46
我们使用StandardScaler对数据进行标准化处理,具体步骤如下:
-
计算每列特征的均值和标准差。
-
对每个特征的值进行标准化处理
得到结果就是上述运行的结果
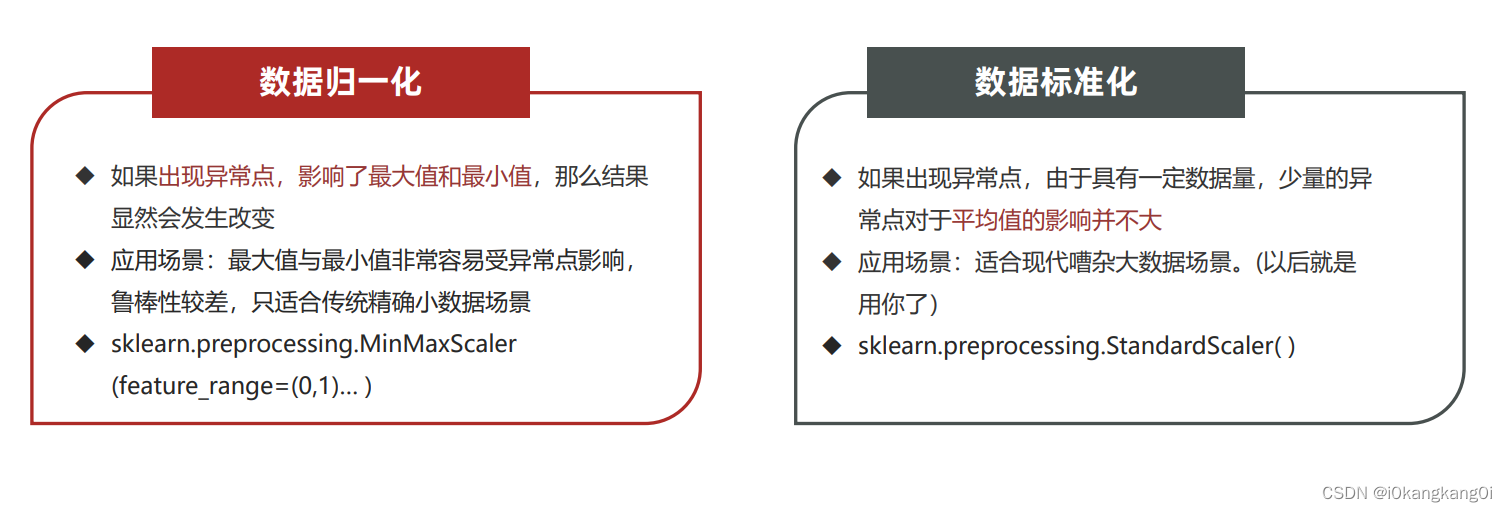
对归一化和标准化的总结
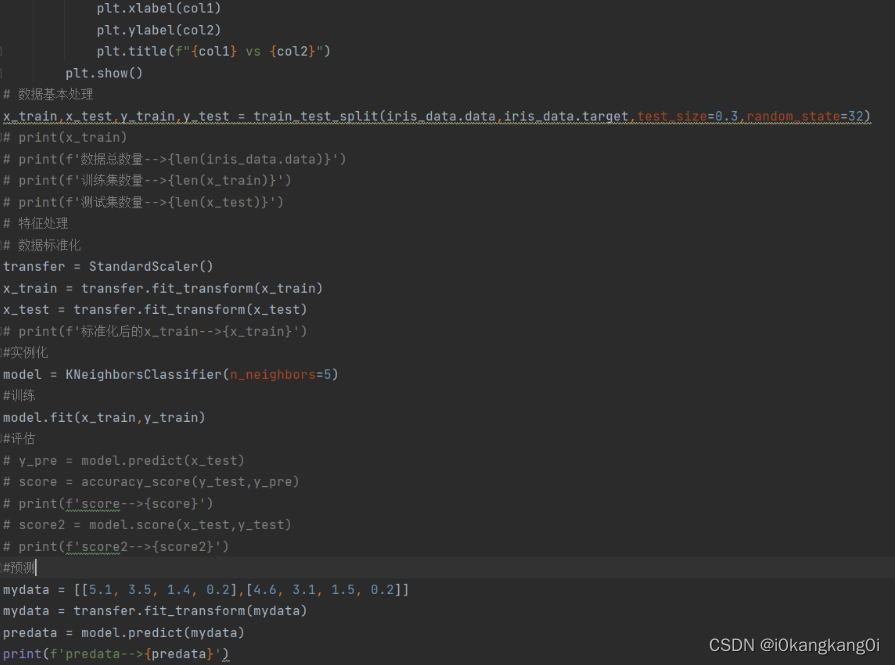
项目实训,利用KNN算法对鸢尾花分类
实现流程:
-----获得数据集
-----数据基本处理
-----数据集处理(进行标准化处理)
-----模型训练
-----模型评估
-----模型预测

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









