






在AI时代,相信大家日常听过或接触过不少大模型,从2023年一夜爆火的ChatGPT,到如今各行各业竞相发布,大模型可谓是遍地开花。
大模型幻觉问题
大模型的AI能力给我们日常写作、开发以及生活带来便利的同时,又不可避免的出现了大模型幻觉问题,时常感觉大模型在一本正经胡说八道,生成的内容不尽如人意。
为了解决大模型幻觉问题,目前最常用的解决方案有两种,要么模型微调,要么使用RAG,其本质区别是把相关知识训练到大模型中,还是放到提示词中告知给大模型。模型微调周期长难度大成本高,相对来说RAG会比较容易,基于此,RAG已经成为当下最火热的大模型应用解决方案。
通用RAG解决方案
RAG(Retrieval-augmented Generation:检索增强生成)将大模型生成式AI能力与私域知识相结合,通过给大模型补充来自外部实时与个性化的知识,从而解决通用大模型在垂直领域的知识局限性以及数据安全性问题,辅助大模型生成更准确、更可靠的内容。
RAG通常从技术层面来说可以细分为以下两个阶段:
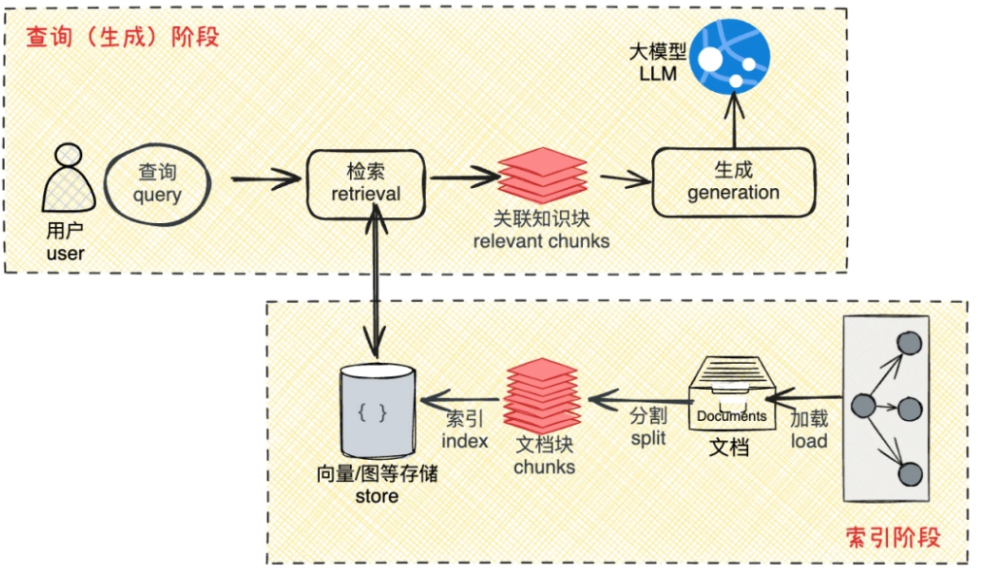
索引阶段:将外部的私域知识,如文档、代码、表格、图片等切分成文档块,并将切分后的文档块通过Embedding模型转换为向量数据进行存储,形成外部知识库。
查询(生成)阶段:在查询阶段会经历【检索—增强—生成】环节,首先根据用户提问内容查询外部知识库,再将用户提问内容及相关知识块嵌入到提示词模板形成增强后的Prompt,并输入到大模型,最后通过大模型的AI能力生成问题的答案反馈给用户。
开发领域RAG解决方案
如果你是一个开发人员,那你肯定或多或少用过AI智能编码助手。在我们写代码时它能自动补全生成后面的代码!是不是好神奇?这又是怎么做到的?
下面以iFlyCode编程助手为例,来详细分解下核心实现。
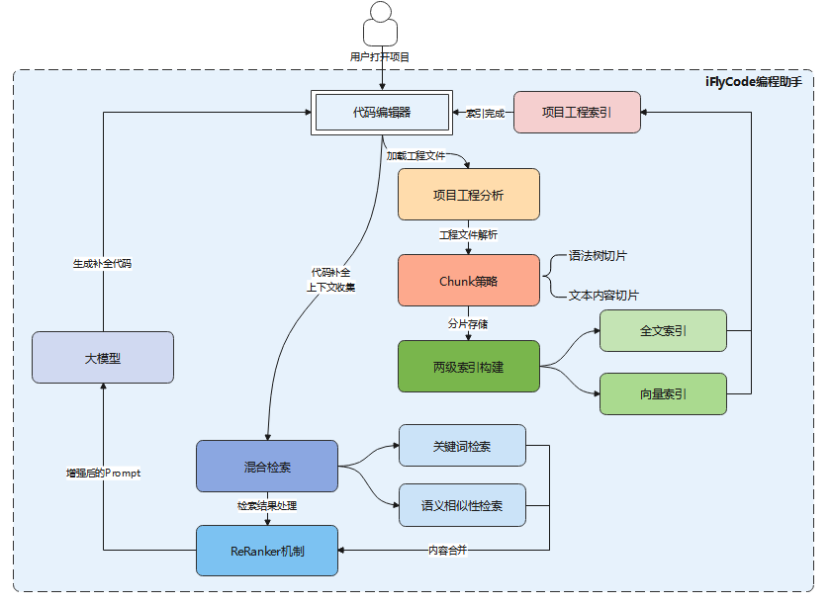
项目工程分析:iFlyCode通过项目工程分析会收集项目工程信息,包括项目仓库信息、项目工程目录结构、项目代码结构以及文件相关性计算等,从而进行后续的分片解析和上下文收集。
Chunk策略:针对项目工程分析获取到的有效工程文件可以采用多种Chunk策略进行分片,Chunk分片需要关注分片内容的完整性和相关性,避免召回的内容片段上下文语义失联:
-
针对代码文件可以基于代码语法树来分析不同语言的代码结构,从代码语法树结构中切分提取不同层级维度的代码分片等;
-
针对文本文件,包括纯文本、表格、图片等,需要进行版面分析、图像识别和内容清洗等处理后再完成文本文件的切片。
两级索引构建:为了更好的理解用户输入,iFlyCode引入了本地索引机制,用于将项目的工程文件分片结果及时存储到不同的索引库中,从而保证检索结果的实效性。同时在存储本地代码知识库时考虑不同切片数据的特点,将数据划分为两类索引进行存储,即为全文索引和向量索引。
混合检索:在两级索引构建完成后,检索阶段可以分别从不同的索引库中进行检索召回TopN个相似数据,比如基于NLP自然语言进行关键词检索,基于Embedding模型转换后的向量数据进行语义相似性检索,从而检索到相关结果。
ReRanker机制:由于全文和向量索引检索结果合并后数据质量不高,给用户带来的搜索体验不够友好,因此针对并混合检索结果需要进一步处理,如数据过滤、相似度计算、reranker精排等,确保输入到大模型的知识片段是高质量的,从而实现大模型的生成结果的准确性和可靠性。
代码补全功能体验
了解了核心实现后,下面让我们一起体验下iFlyCode代码补全实际效果。
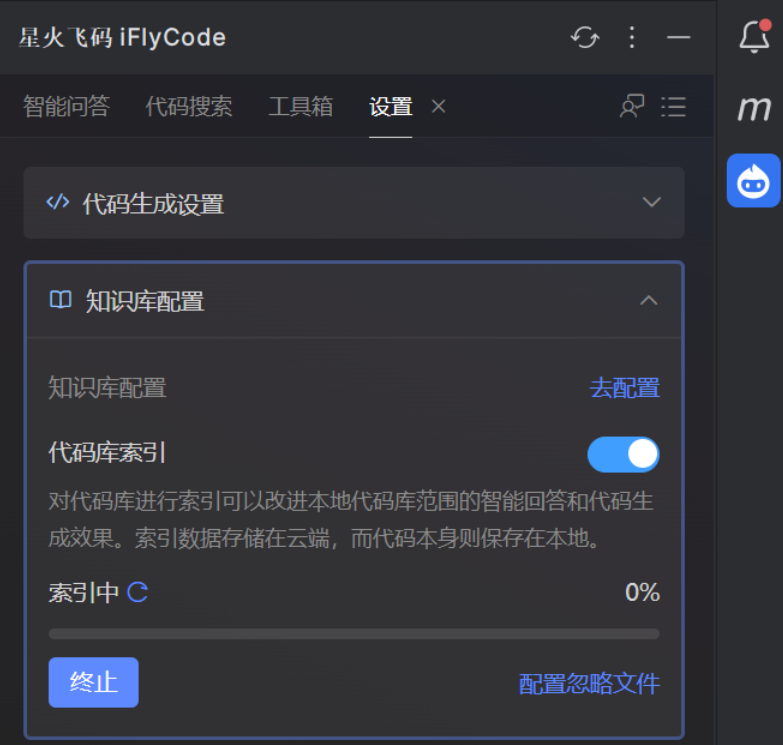
1、首先在IDE编辑器中打开一个项目工程,并在设置面板开启代码库索引,此时会自动进行项目工程分析并开始构建索引,如下图:
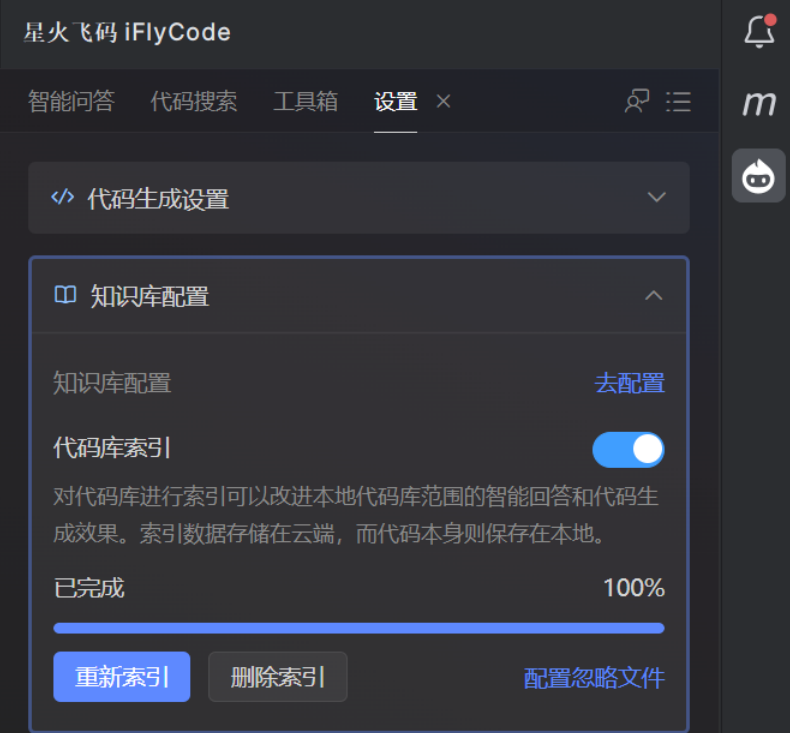
2、此时稍等片刻会完成本地代码库索引构建。如下图:
3、在代码库索引构建完成后手动开启代码补全开关,如下图:
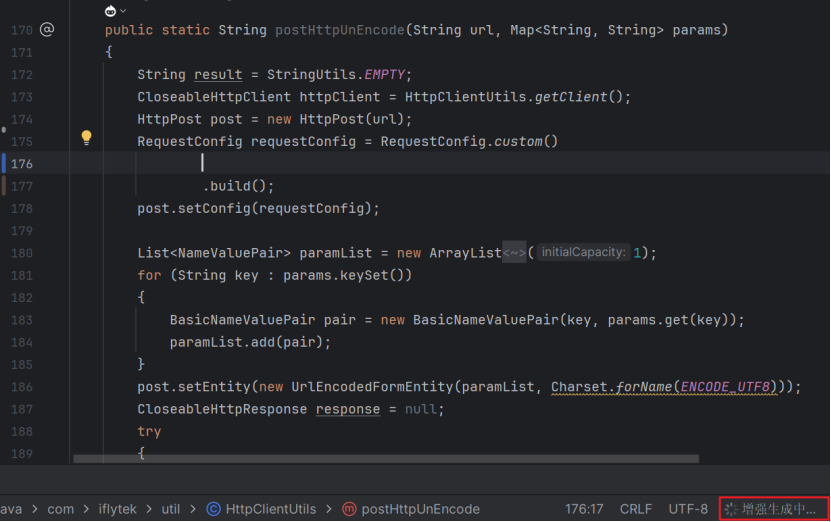
4、打开任意代码文件,在函数中进行回车,此时会自动触发代码补全,在编辑器右下角提示【增强生成中...】,如下图:
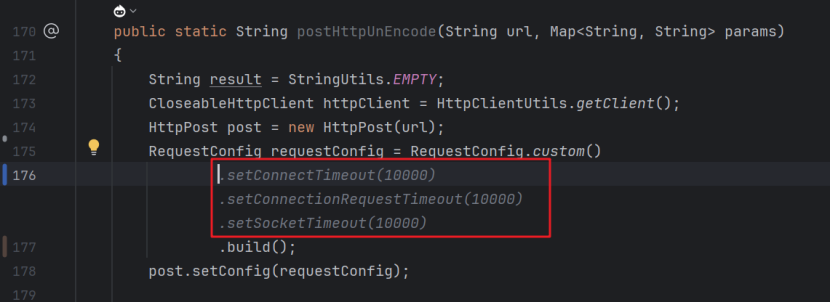
5、补充完成后在回车的地方可以看到灰显的补全代码,如下图:
针对灰显的代码,用户通过Tab或Esc决定是否采纳,或部分采纳补全代码。当然,RAG不只有在代码补全的场景下会用到,在项目工程问答等方面也可以看到它的身影,整体处理流程都大同小异,此处不再赘述。
结 尾
正是有了那么多实用功能的加持,让我们写代码就像Tab、Tab、Tab一样简单!
最后再给大家爆料一个消息:预计就在近期,星火飞码iFlyCode将上线模型选择功能,新增DeepSeek-V3 和 DeepSeek-R1 模型,届时,用户可在星火飞码官网或IDE插件中下载最新版本插件,免费体验多模型切换能力,畅享更快更优的编程体验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









