







目录
HAClient端
首先要去connect一下master,从而建立一个SocketChannel连接通道,并把这个通道对应的文件描述符,注册到多路复用器selector上,并注册一个针对该通道的READ读事件,从而能读取Master发过来的心跳包、Commitlog数据
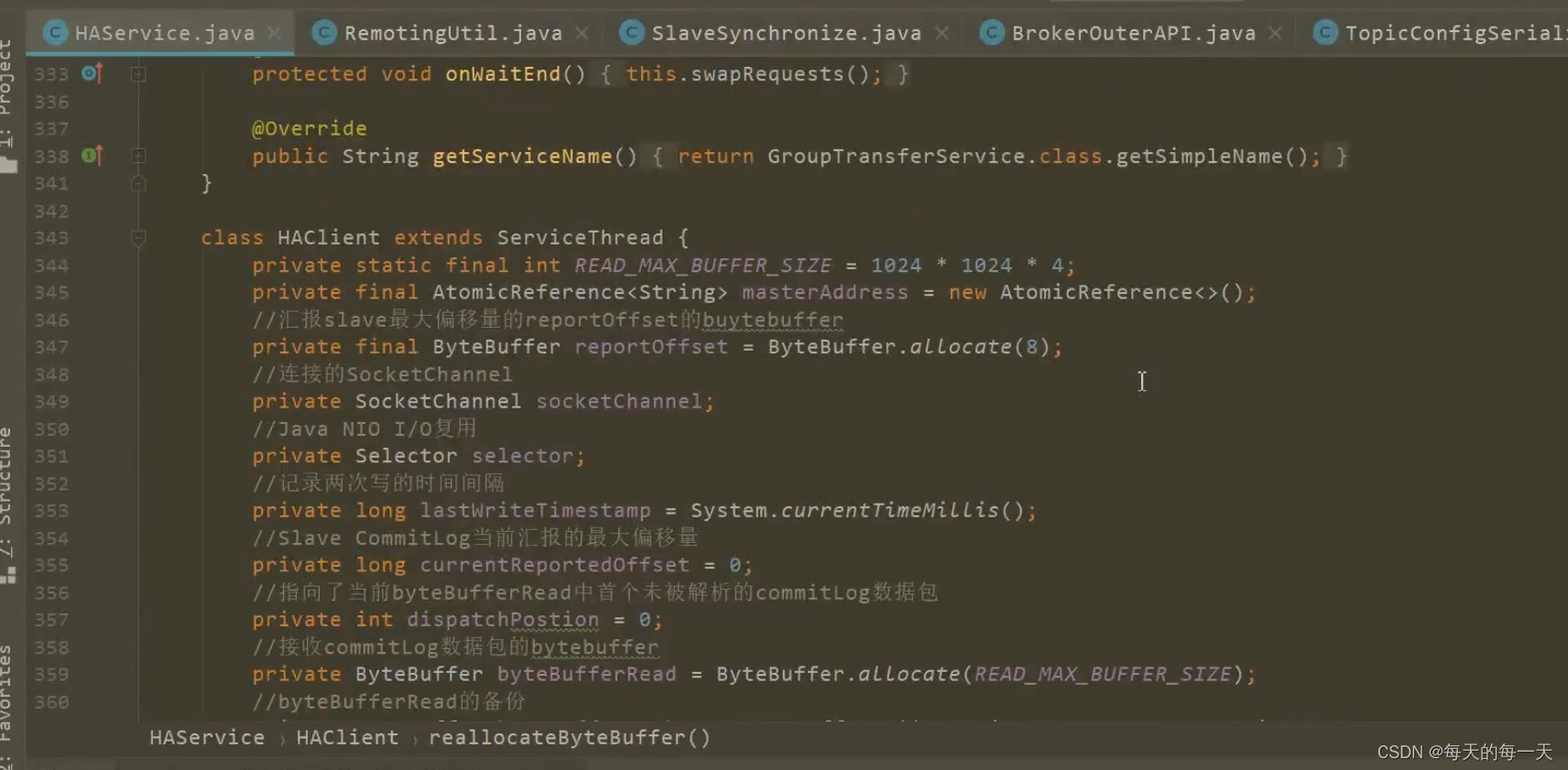
一个HAClient就是一个服务线程,负责处理当前slave与master之间连接中的数据往来
一个HAClient就持有一个Selector,也就是一个IO多路复用器
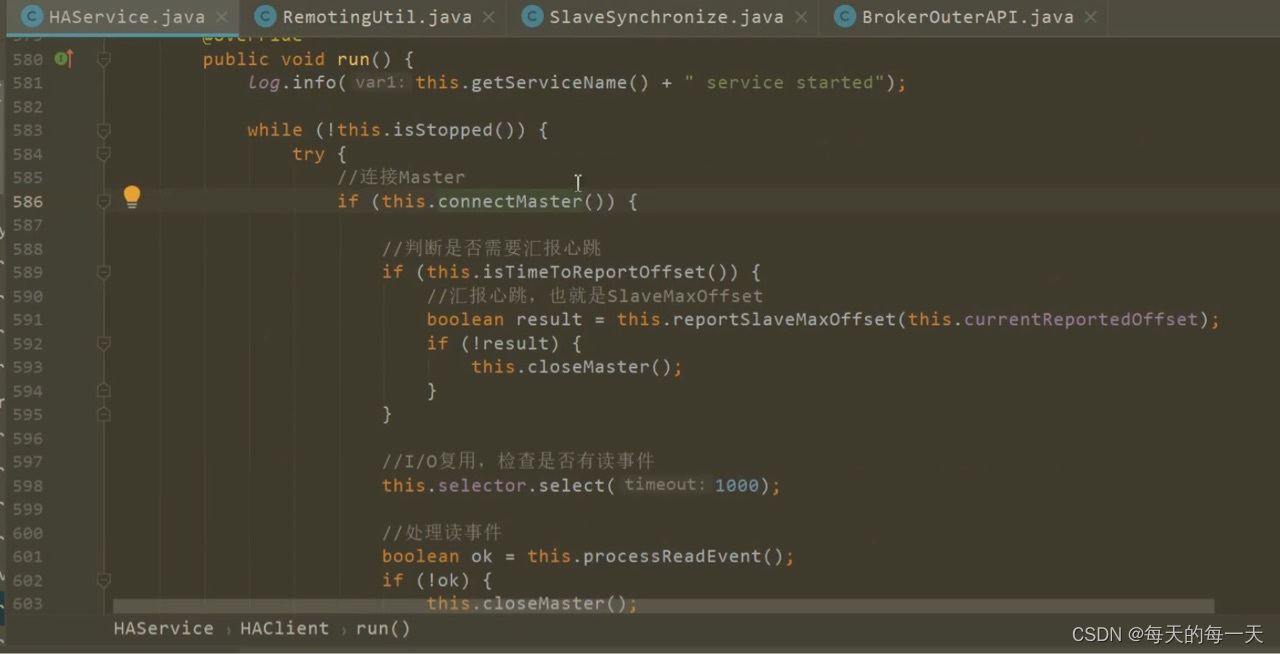
通过死循环,来每隔一段时间,往master的ReadSocketService线程,发送一次心跳,心跳数据就是当前slave的commitlog最大物理偏移
核心逻辑就是,不断循环select,一旦发现通道中有数据到达,则将通道中的数据读取到byteBufferRead字节数组中来,然后根据粘包/拆包,将byteBufferRead字节数组中的数据,切分成一个个的数据包,每个数据包中附带一段commitlog,每次往磁盘commitlog文件末尾append追加一个数据包中的一段commitlog
这一套流程,都在HAClient这一个服务单线程中完成的
处理读事件processReadEvent
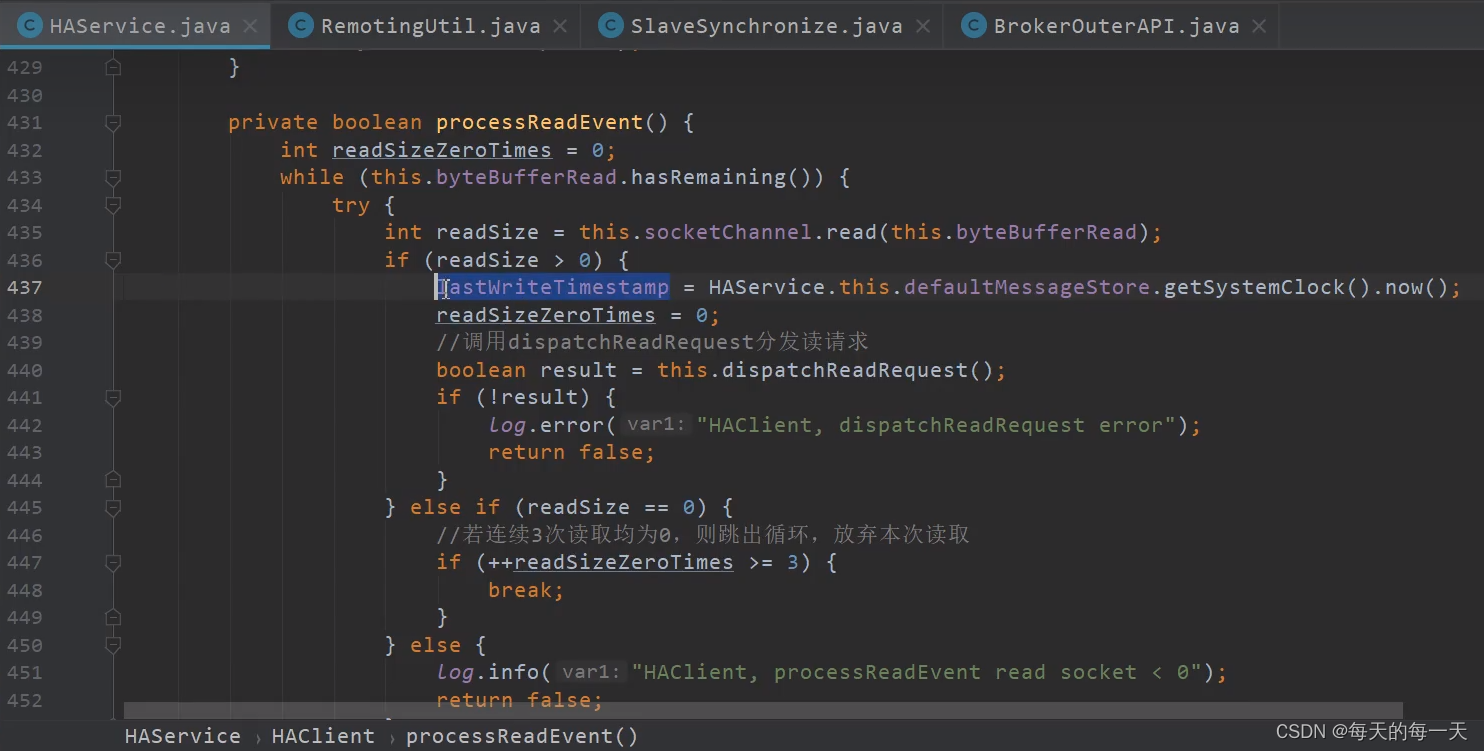
使用while循环,如果连续三次都没有从通道中读取到数据,则跳出循环。这样写,就是因为前面selector.select(1000) ,没有判断返回值,而是不管超时不超时,流程都继续往后走了
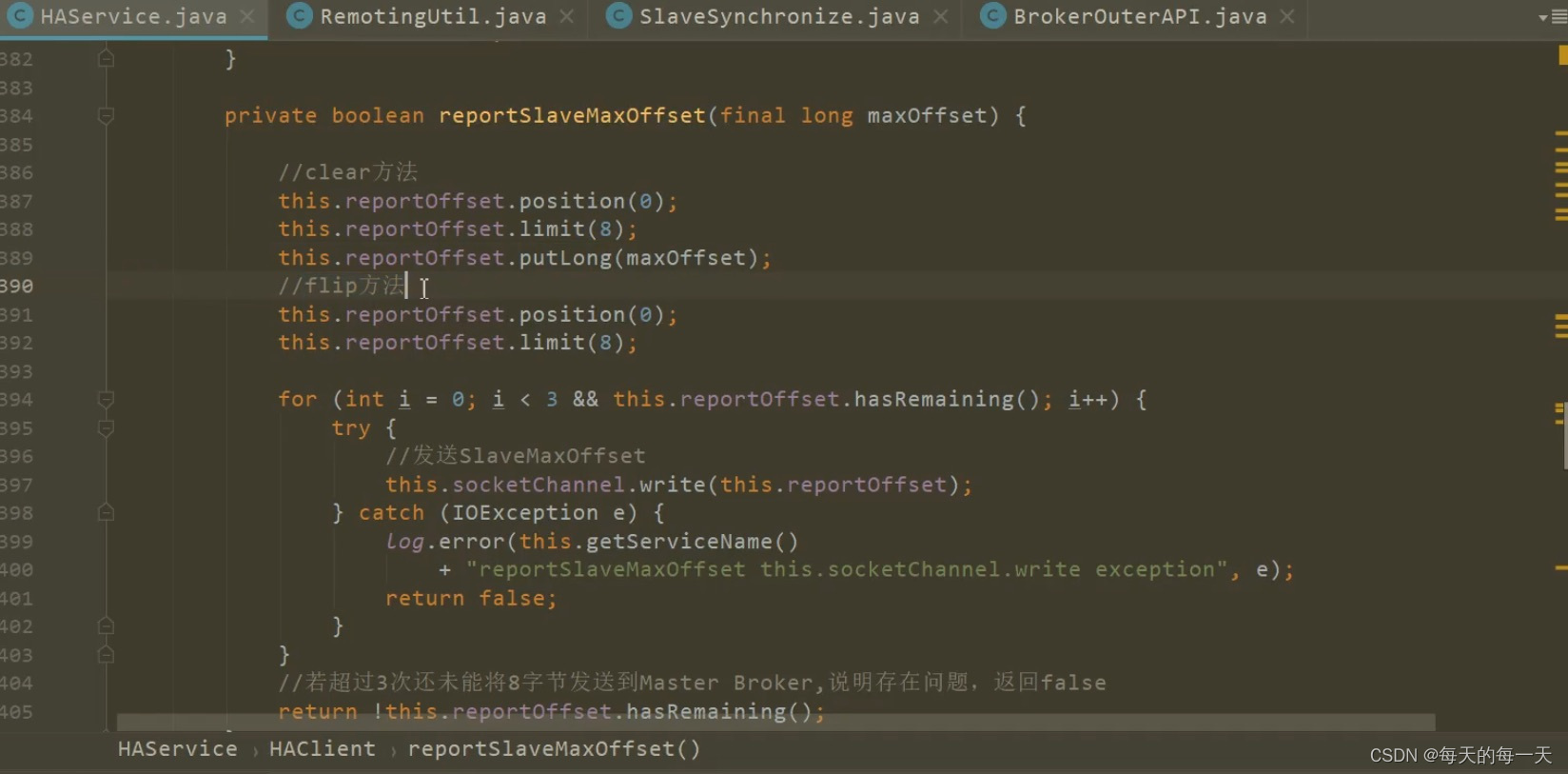
解析Master过来的每个commitlog数据包
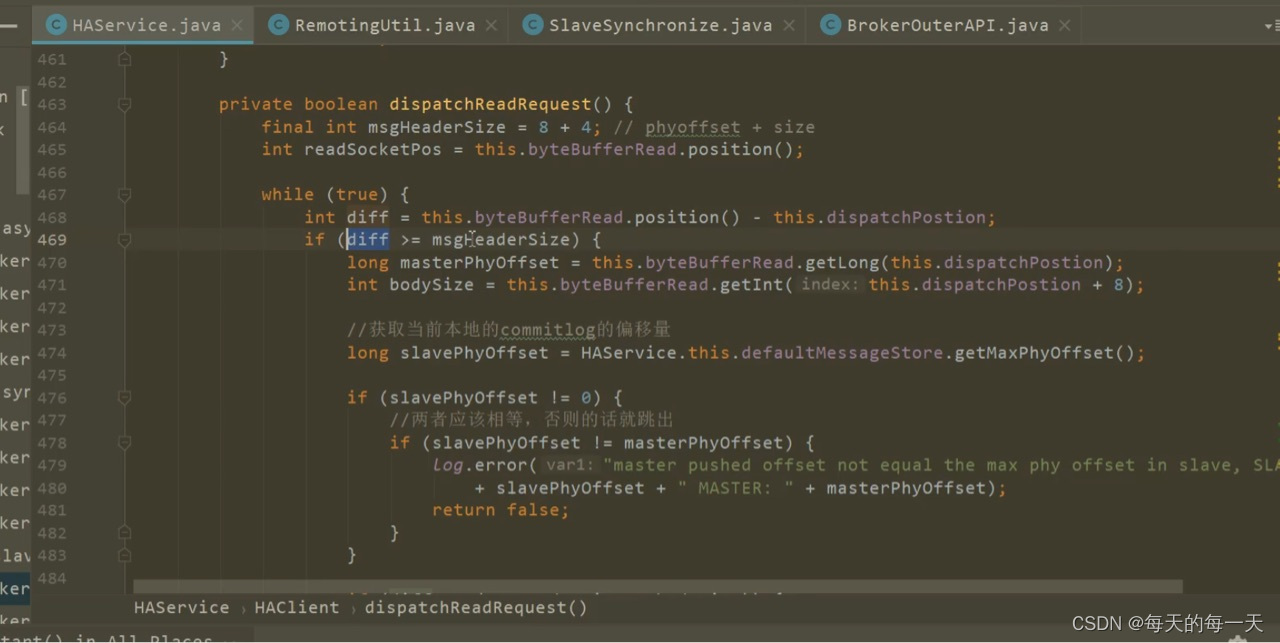
478行,slave每次接收到master发过来的一批commitlog数据时,会看master传过来的这段commitlog的起始端对应的全局物理偏移量,和slave本地存储的批commitlog数据的最大物理偏移量,是否相等。如果相等,也说明master端没有给slave漏掉某一段commitlog,说明本次master传过来的这段commitlog片段,可以直接拼接在slave本地的commitlog之后。如果不相等,则说明master端给slave漏掉某一段commitlog
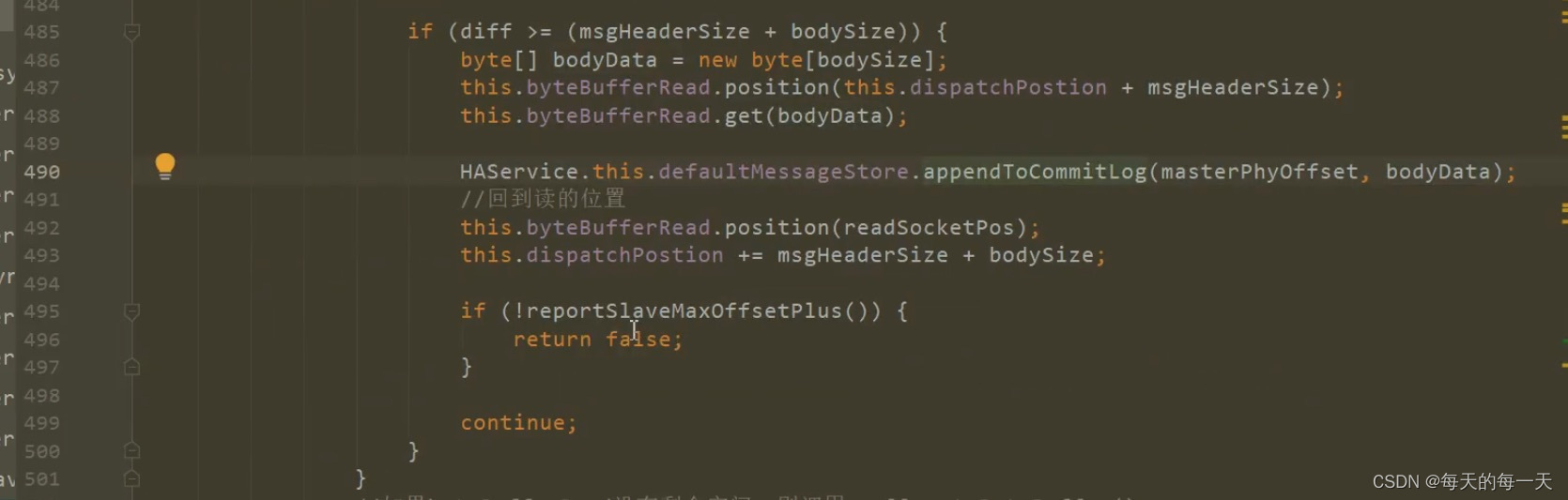
490行,执行当前commitlog数据包的append到本地磁盘的动作,同时还会同步唤醒reputMessageService线程
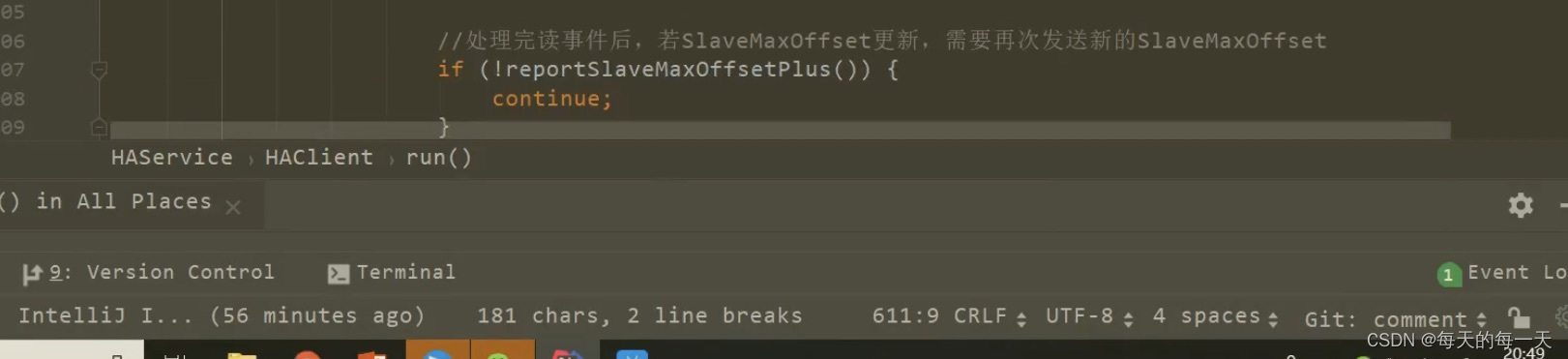
492行,比如当前byteBufferRead有3.7个数据包,我们第一次while循环处理完并将第一个数据包中的commitlog数据追加到本地磁盘后,开始进行第二次while循环前,先将dispatchPosition划动到下一个数据包的开端,将position恢复到byteBufferRead中已有数据的末端,然后开始第二次while循环,开始准备将第二个数据包append到磁盘,注意,每轮while循环都会往master report上报一次slave的maxPhyPosition
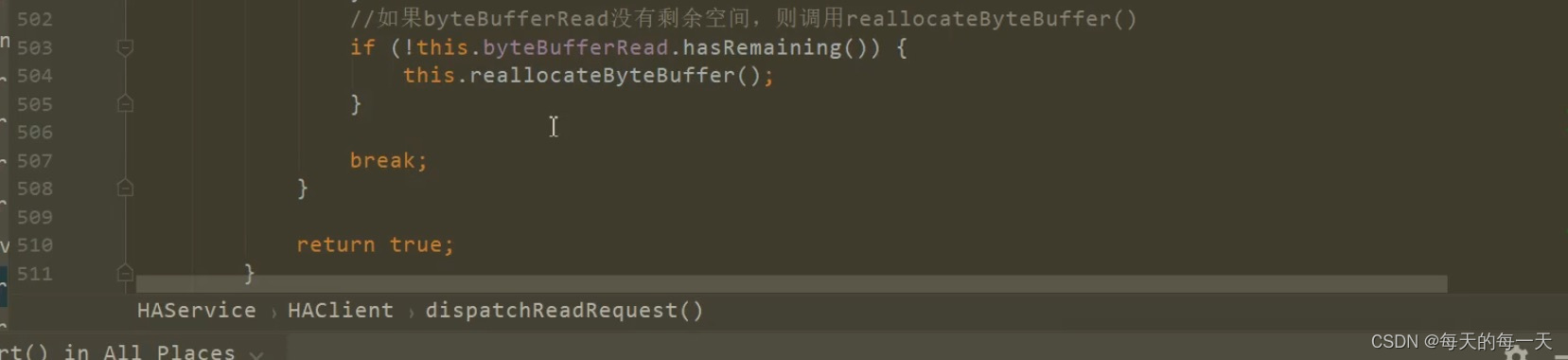
一直到某一轮循环发现diff小于8+4后,来开始执行503行,并break跳出循环
503行,两块byteBufferRead交换逻辑,如果当前的byteBufferRead写满后,也交换另一块空的byteBuffer作为新的byteBufferRead
注意,在append的时候,还会同步唤醒reputMessageService线程,来现场构建ConsumeQueue和IndexFile 
在每个commitlog数据包,append成功后,都会给master上报一次当前commitlog最大位置
两块byteBufferRead交换逻辑
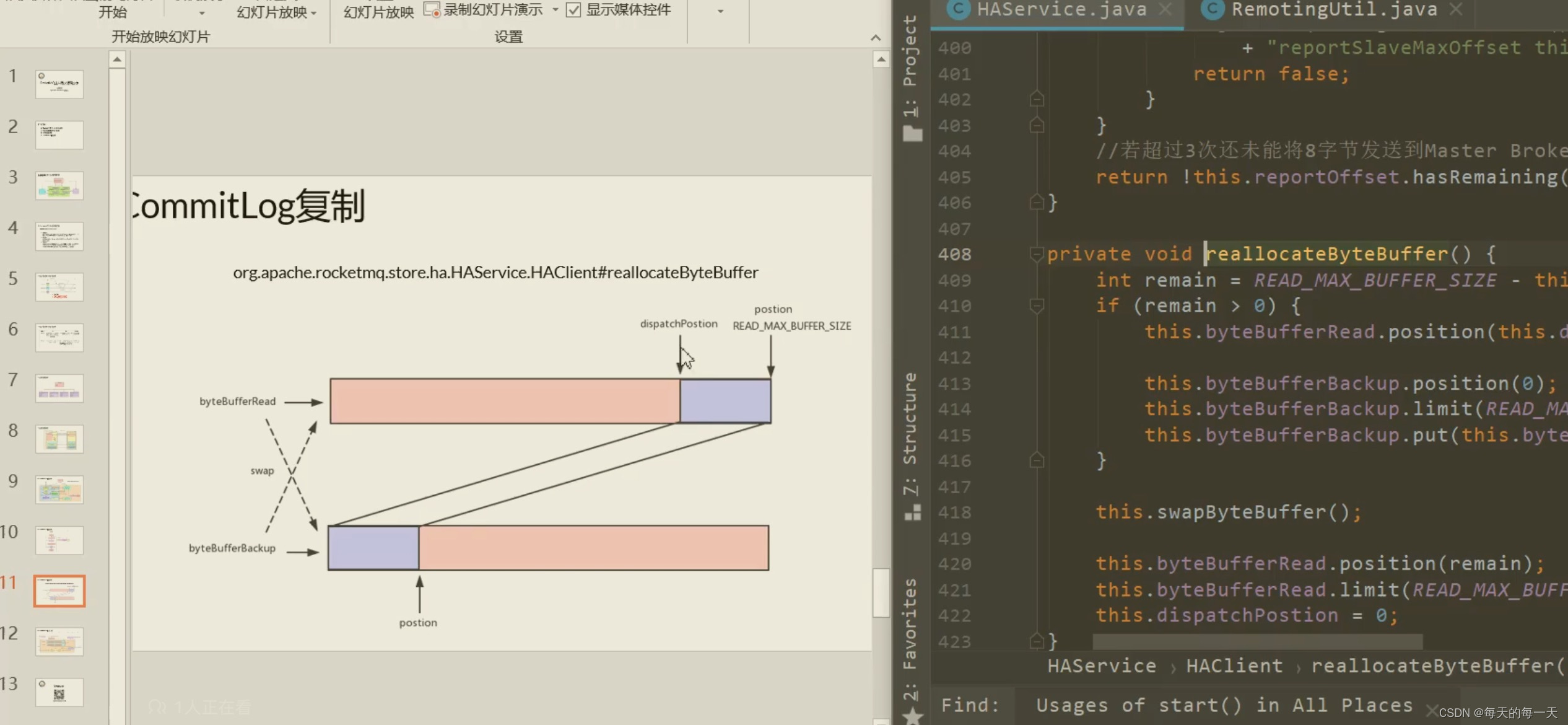
因为应用层,如果只定义一个byteBuffer字节数组,不停的从内核中读数据往里面写,它总有被写满的时候,所以定义了两个byteBuffer字节数组,轮着来写,上一个写满了就转头去写另一个,并且把上一个因为粘包拆包解析读取还剩余的比如0.7个数据包,拷贝到另一个byteBuffer字节数组中去
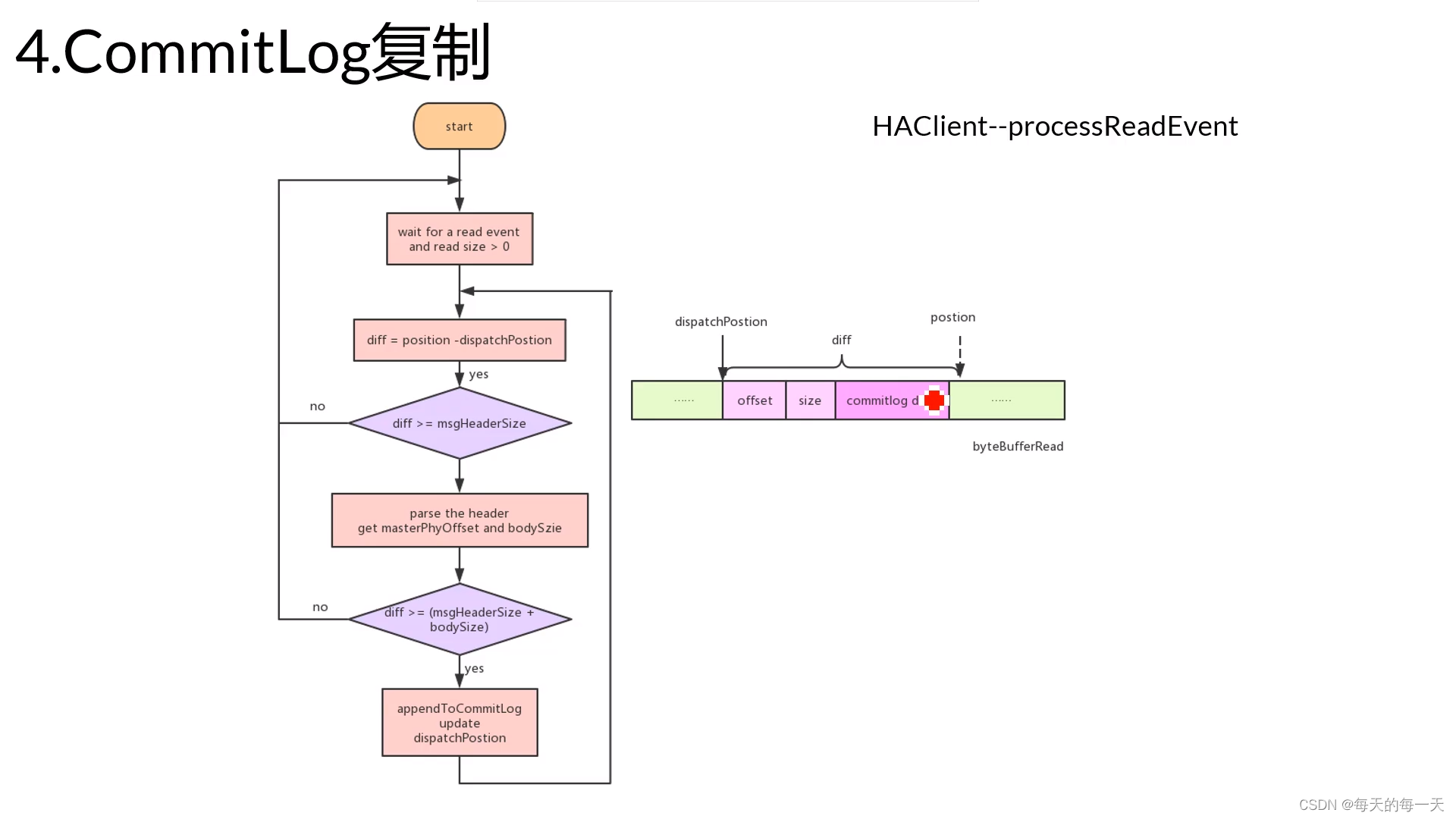
当HAClient端的selector多路复用器,监听到有READ事件进来,也就是master端有数据写过来时,就会通过socketChannel.read(byteBufferRead),来把通道中的master写过来的心跳数据包、commitlog数据包数据,从内核读取到应用层的byteBufferRead中来
byteBufferRead,每次dispatchPosition都是一个完整数据包的开始位置、offset是后面带的那段commitlog数据,在master中commitlog磁盘总数据的全局物理偏移量、size是后面带的那段commitlog数据的字节数
此时,应用层就需要自己对byteBufferRead中的数据进行切分,也就是粘包拆包处理,因为此时byteBufferRead中可能有3.7个数据包
byteBufferRead中,dispatchPosition一个完整数据包的开始位置,position是byteBuffer当前数据末端所在的位置,此时
- 如果dispatchPosition和position之间的差值diff大于8+4字节,则可以进行解析将offset和size解析出来
- 如果dispatchPosition和position之间的差值diff小于8+4字节,则说明当前这段数据还不够拼装解析成offset和size,所以,就需要多路复用器继续等待新的IO READ事件的到来,应用线程从而能从内核通道中读取更多的字节数据,并将之追加到position往后的位置,直至dispatchPosition和position之间的差值diff大于8+4字节,则可以开始第1步的动作
- 解析出offset和size后,又要看diff是不是大于8+4 + bodySize,如果大于,则开始slave真正的将master传过来的commitlog append到磁盘本地commitlog文件后,如果小于,则多路复用器又继续等待新的IO READ事件
- 将dispatchPosition更新到下一个数据包,在byteBufferRead中的位置
粘包/半包问题
整个网络通信传输,RocketMQ采用了java nio包中的selector io多路复用技术,应用这个技术读取数据时,是直接面对的tcp数据,而tcp是面向字节流的而不是面向数据包的,所以,我们无法保证tcp通道的接收缓冲区中的字节流数据一定就是一个数据包,可能是0.8个数据包,可能是2.3个数据包,当然也可能刚好就是一个或者两个完整的数据包,这是不确定的事情
我们应用程序猿,能做的就是把内核中的tcp通道的接收缓冲区中的已经接收到的字节流数据,从内核读取到应用层的byte buffer字节数组中,然后在应用层自己根据数据包协议头的offset + dataSize,来进行拆包粘包
Master端
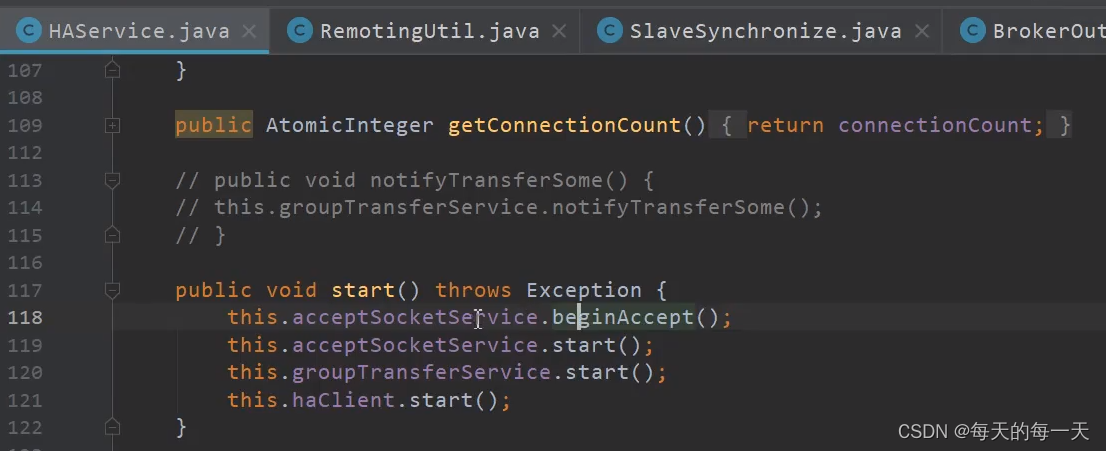
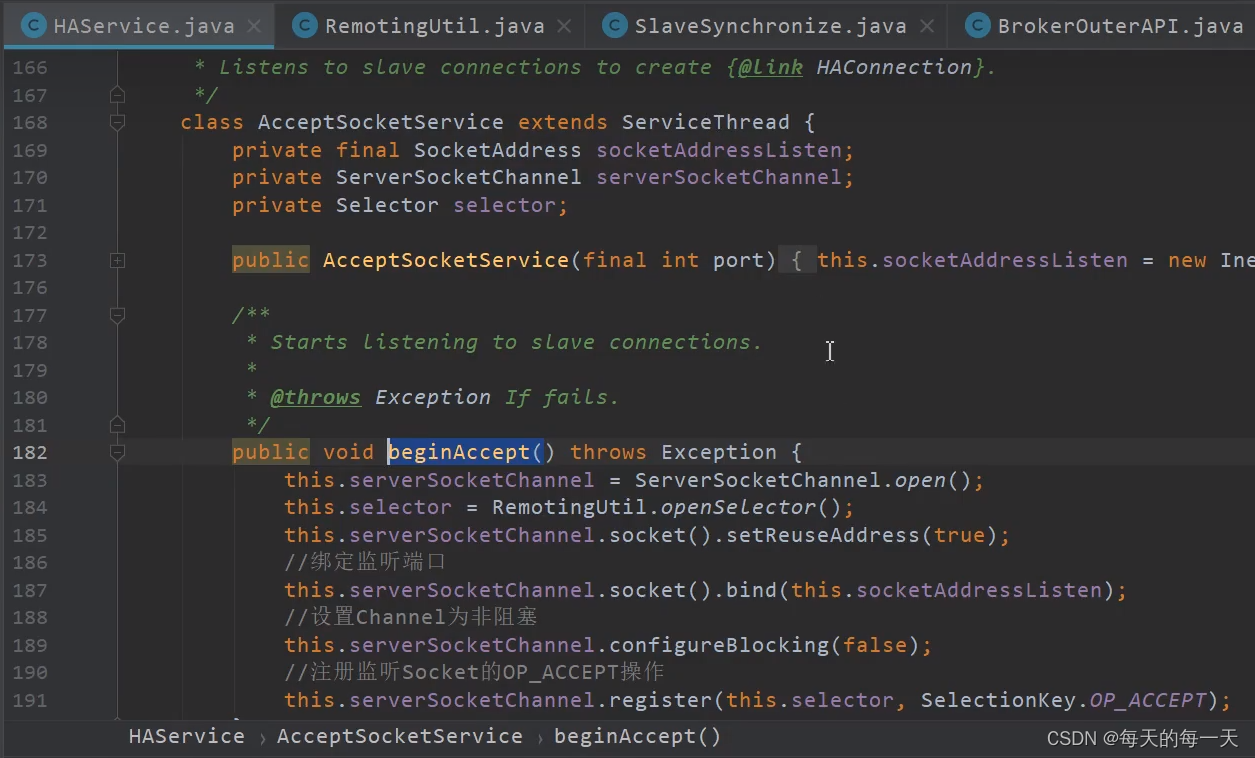
AcceptSocketService实现原理
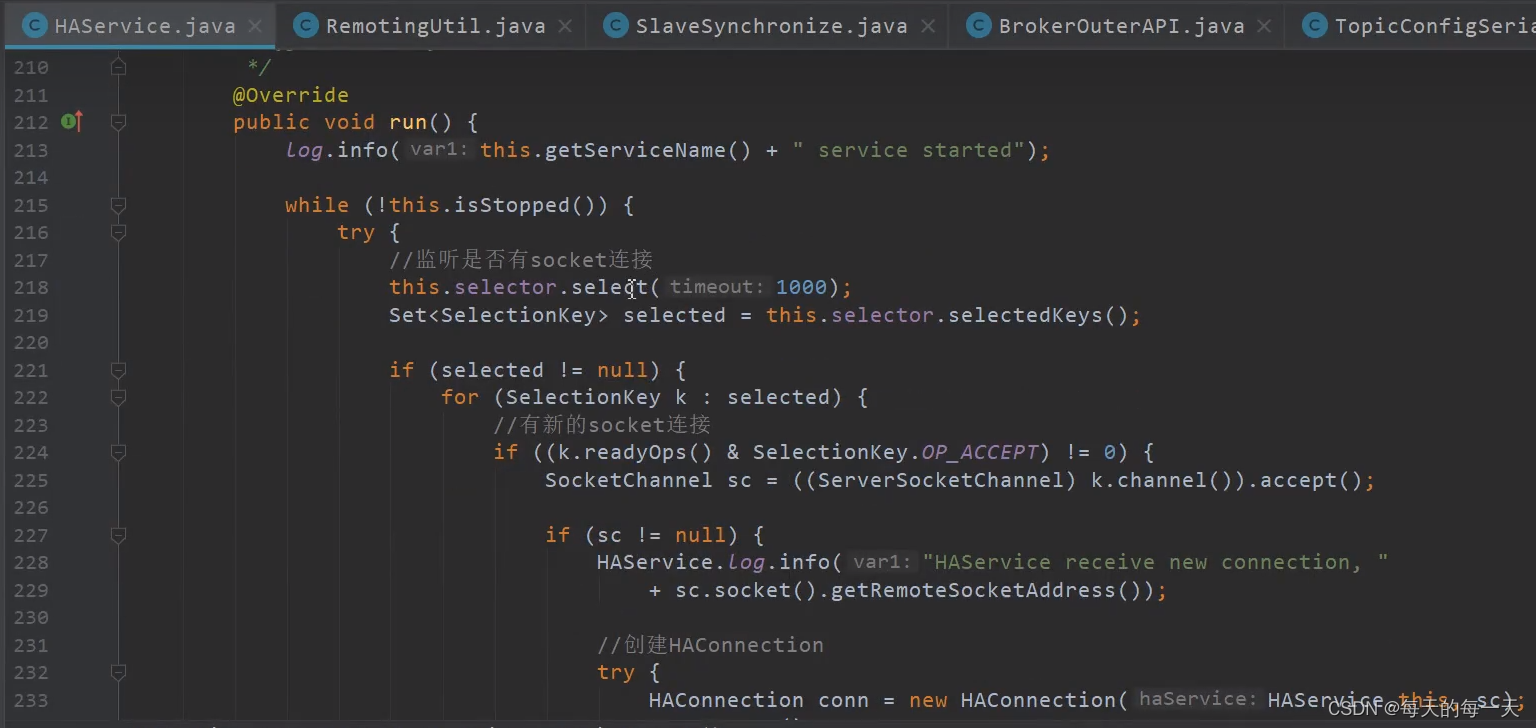
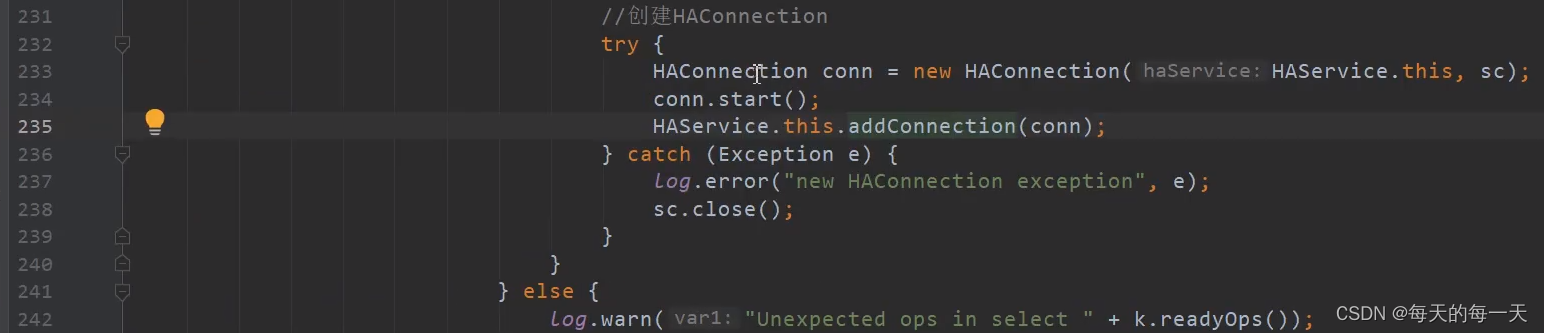
如果一个Master有两个slave,则235行的集合中就有有两个HAConnection
HAConnection实现原理
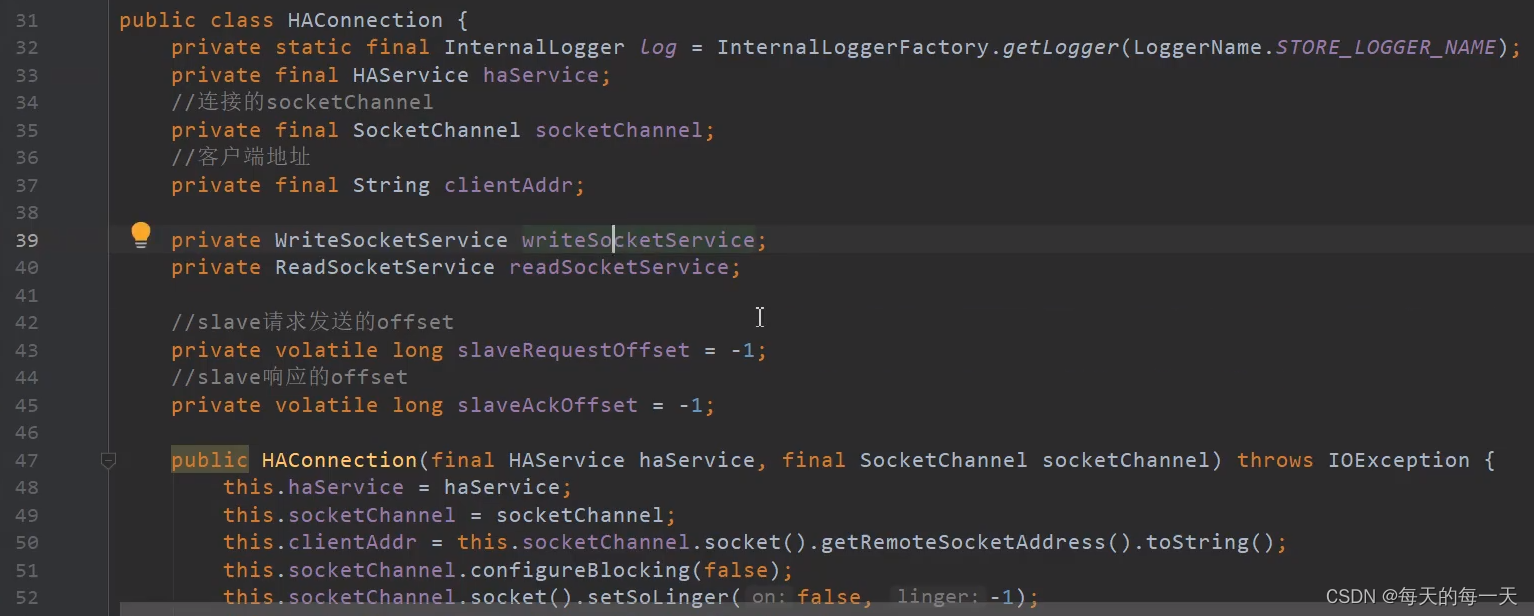

ReadSocketService
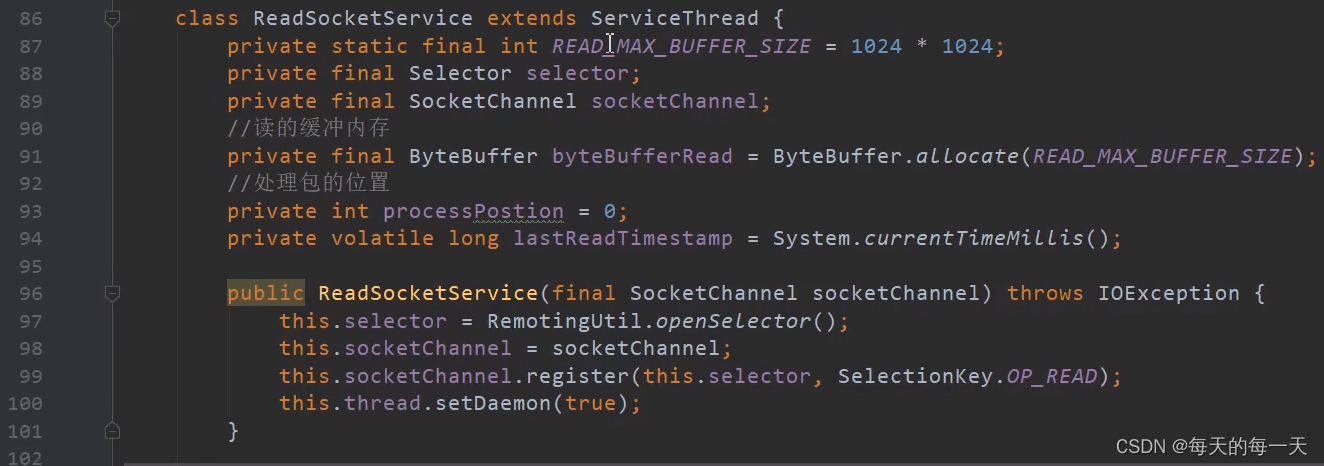
这个服务线程,在99行初始化的时候,该selector就被初始化为了关注READ读事件,也就是关注从slave写过来的数据
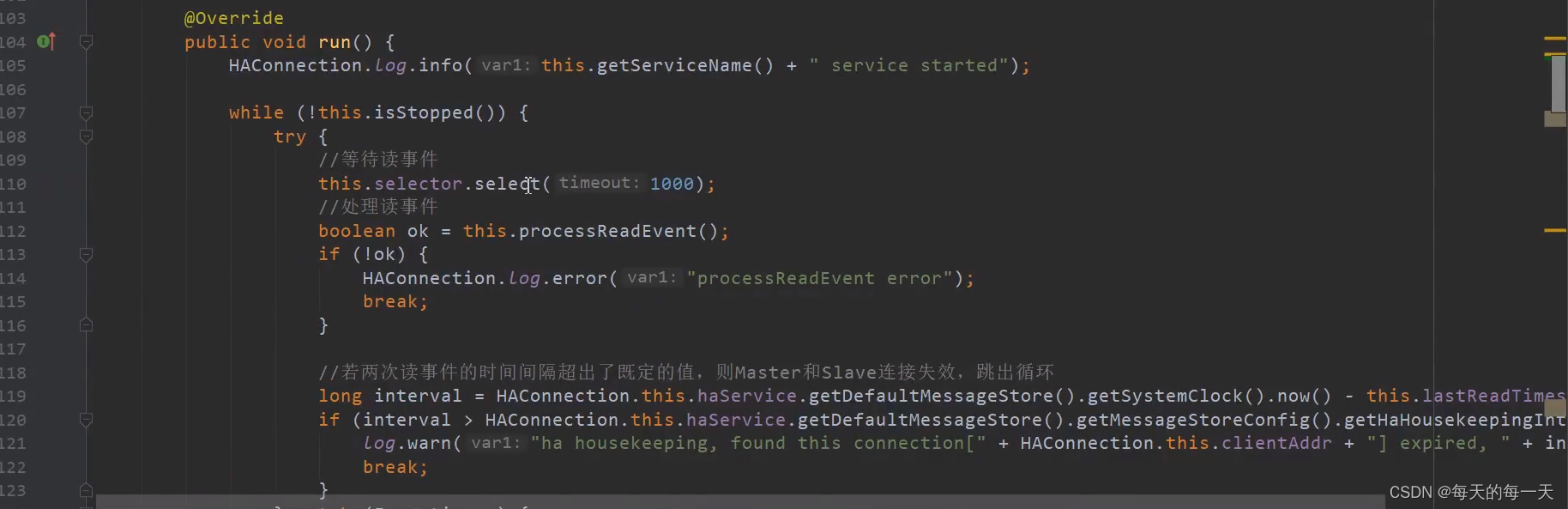
处理读事件
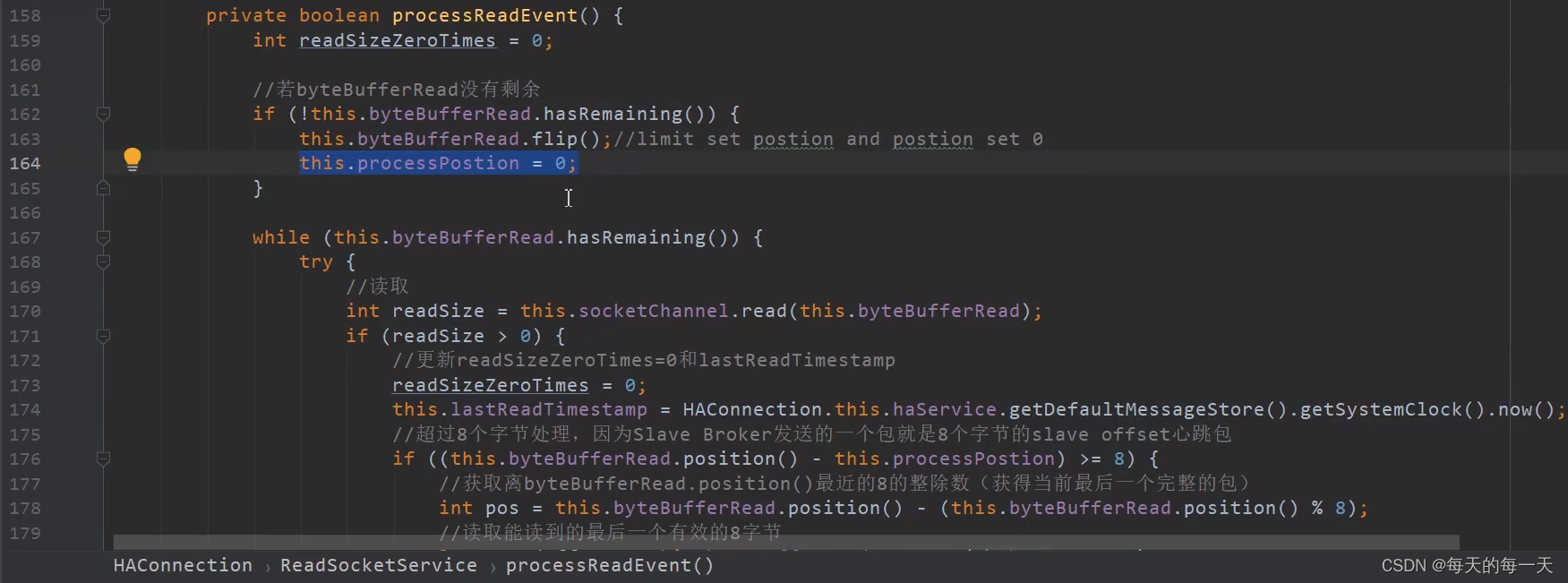
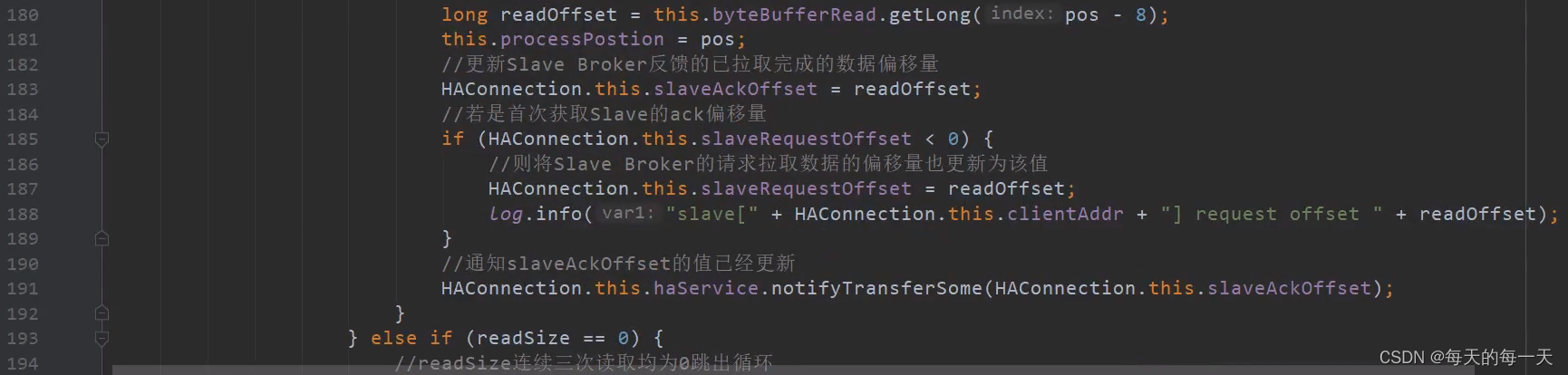
185行,可以看出这段READ逻辑,既用来读取slave发过来的响应当前slave已经有的commitlog的全局offset,也用来读取slave发过来的要拉取的某段commitlog的起始offset
slave向master返回拉取偏移量。这里有两重意义,对于slave来说,是发送下一次待拉取的消息偏移量、而对于master来说,既可以认为是slave本地请求拉取消息偏移量,也可以理解为slave的消息同步ACK确认消息
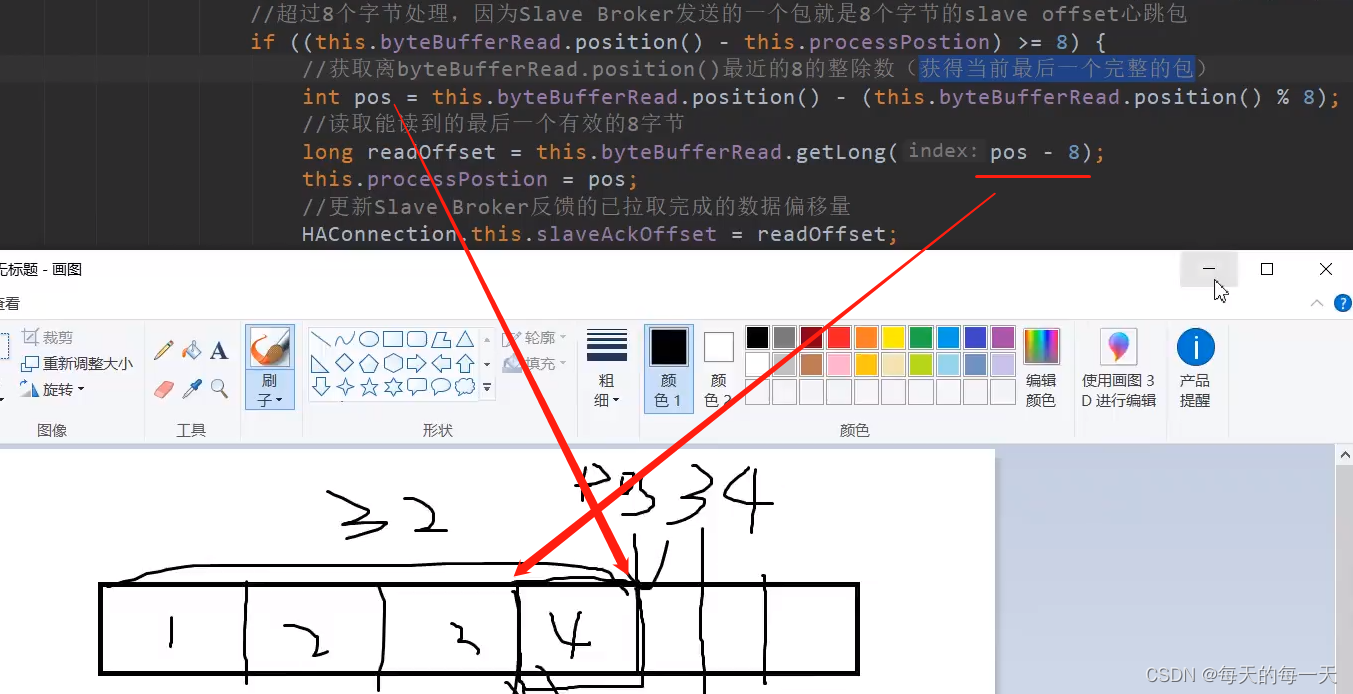
因为我们当前就是处理最后一个包,前面的都处理过了
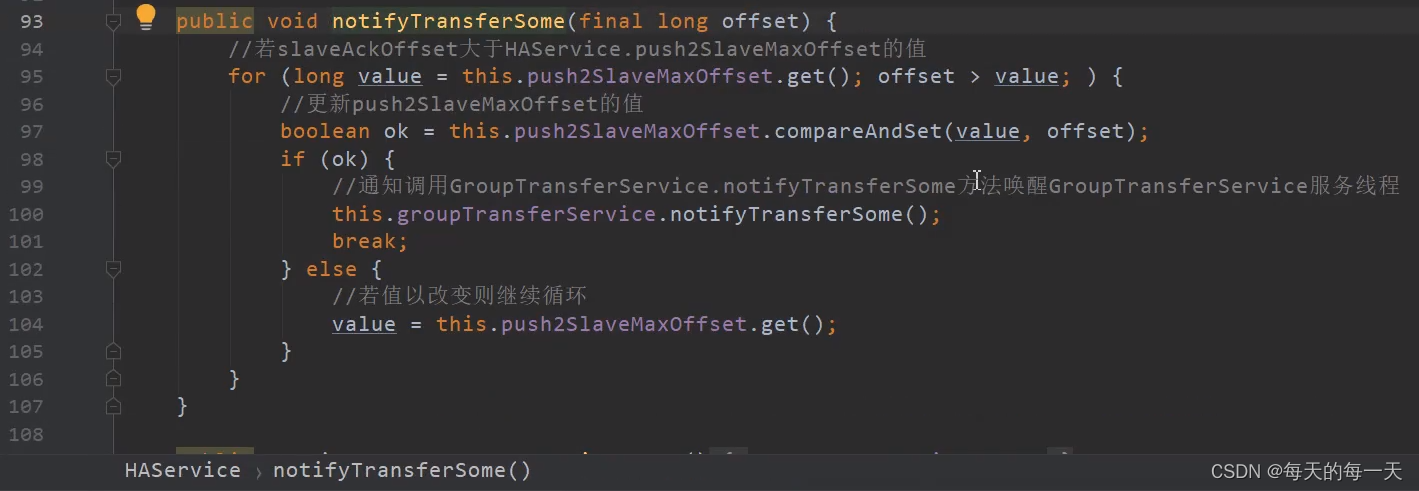
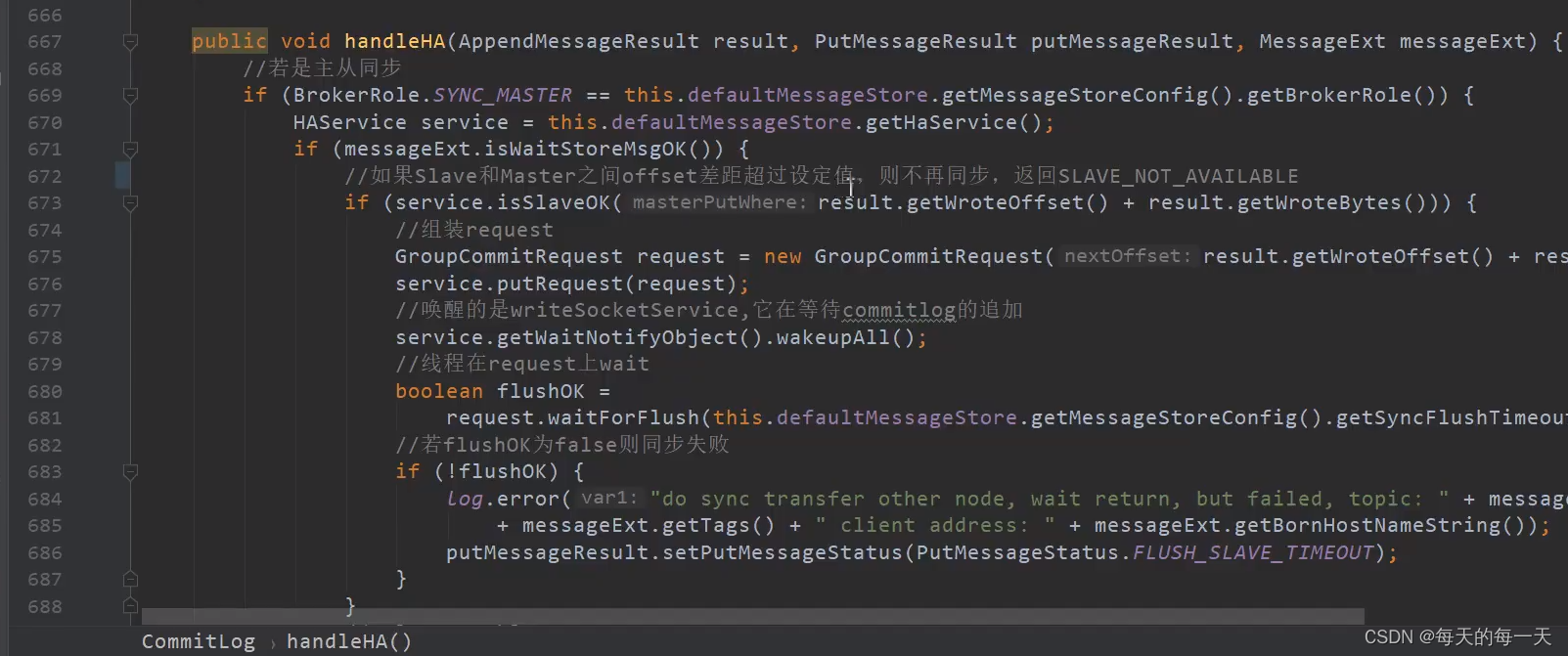
由于可能存在多个slave,多个slave就可能有多个连接,来同时连接到同一个master,这是就可能涉及到一些并发处理,比如有多个线程同时去更改push2SlaveMaxOffset这个值,所以97行是一个原子的更新操作
这里如果更新push2SlaveMaxOffset成功,则会去唤醒GroupTransferService线程,因为GroupTransferService每wait 1s才会醒来自己执行一轮
WriteSocketService
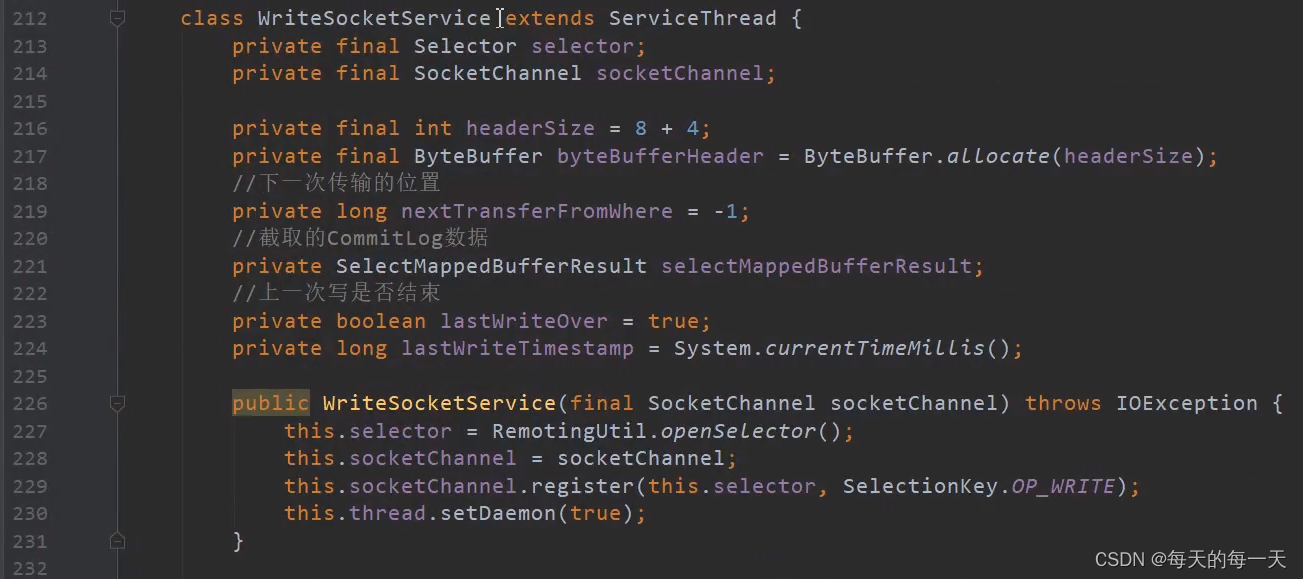
WRITE事件
@Override
public void run() {
HAConnection.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
// OP_WRITE,等待写事件
this.selector.select(1000);
/*
* 说明,master还未收到slave的拉取请求,放弃本次事件处理
* slaveRequestOffset在收到slave broker拉取请求时更新
* */
if (-1 == HAConnection.this.slaveRequestOffset) {
Thread.sleep(10);
continue;
}
/*
* nextTransferFromWhere等于-1,表示初次进行数据传输,需要计算需要传输的物理偏移量
* 如果不是开机以后的第一次传输,而是第二次以后的,就不会再进这一段if逻辑了
* */
if (-1 == this.nextTransferFromWhere) {
/*
* 如果slaveRequestOffset等于0,则从当前最后一个commitlog文件起始偏移量开始传输,
* 否则,根据slave broker的拉取请求偏移量开始传输
* */
if (0 == HAConnection.this.slaveRequestOffset) {
long masterOffset = HAConnection.this.haService.getDefaultMessageStore().getCommitLog().getMaxOffset();
masterOffset = masterOffset - (masterOffset %
// commitlog文件的大小:1G
HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getMappedFileSizeCommitLog());
if (masterOffset < 0) {
masterOffset = 0;
}
this.nextTransferFromWhere = masterOffset;
} else {
this.nextTransferFromWhere = HAConnection.this.slaveRequestOffset;
}
log.info("master transfer data from " + this.nextTransferFromWhere + " to slave[" + HAConnection.this.clientAddr
+ "], and slave request " + HAConnection.this.slaveRequestOffset);
}
/*
* lastWriteOver 上一次写是否结束:
* 因为通道是非阻塞的,所以不一定会一次写完,所以要有这个标志位
*
* nio设置非阻塞时,并不是等所有数据写完再返回,而是写一部分就返回
* */
if (this.lastWriteOver) {
long interval = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now() - this.lastWriteTimestamp;
// 写的时间间隔,超过了预定心跳发送间隔,发送一个心跳包,包中没有commitlog数据
// 心跳包,是为了避免长连接,由于commitlog一直没有新数据进来导致空闲而被关闭
if (interval > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaSendHeartbeatInterval()) {
// Build Header
this.byteBufferHeader.position(0);
this.byteBufferHeader.limit(headerSize);
this.byteBufferHeader.putLong(this.nextTransferFromWhere);// offset 不变
this.byteBufferHeader.putInt(0);// size为0,即包中没有commitlog数据
this.byteBufferHeader.flip();
// 传输数据
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
// 上次传输没有结束,继续传输数据
} else {
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
// ---------------------------------- 上面都是校验,前戏,下面才是每一轮write的重头戏 --------------------------------------------------------------
/*
* 下面是构造,并传送一个完整的commitlog数据包
* */
SelectMappedBufferResult selectResult = HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere);
if (selectResult != null) {
int size = selectResult.getSize();
if (size > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize()) {
// 默认最多只能传32k,超过32k,需要做数据截断
size = HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize();
}
long thisOffset = this.nextTransferFromWhere;
// nextTransferFromWhere,会在这里随着每增加一个数据包,这个nextTransferFromWhere就往后挪动32k的位置
this.nextTransferFromWhere += size;
/*
* 比如,
* 第一次传送时,nextTransferFromWhere为0,则thisOffset也变成0,就传送0 -> (32k-1)之间的数据,然后置nextTransferFromWhere为32k
* 第二次传送时,nextTransferFromWhere为32k,则thisOffset也变成32k,就传送32 -> (64k-1)之间的数据,然后置nextTransferFromWhere为64k
* 第三次传送时,nextTransferFromWhere为64k
* .....
* 如果一直有数据传输,则每隔一秒,就会往slave传入32k的消息数据,无限循环
* */
selectResult.getByteBuffer().limit(size);
this.selectMappedBufferResult = selectResult;
// Build Header
this.byteBufferHeader.position(0);
this.byteBufferHeader.limit(headerSize);
this.byteBufferHeader.putLong(thisOffset);
this.byteBufferHeader.putInt(size);
this.byteBufferHeader.flip();
// 传输数据
this.lastWriteOver = this.transferData();
} else {
// 若没有获取到commitlog数据,则等待应用层追加
HAConnection.this.haService.getWaitNotifyObject().allWaitForRunning(100);
}
} catch (Exception e) {
HAConnection.log.error(this.getServiceName() + " service has exception.", e);
break;
}
}
HAConnection.this.haService.getWaitNotifyObject().removeFromWaitingThreadTable();
if (this.selectMappedBufferResult != null) {
this.selectMappedBufferResult.release();
}
this.makeStop();
readSocketService.makeStop();
haService.removeConnection(HAConnection.this);
SelectionKey sk = this.socketChannel.keyFor(this.selector);
if (sk != null) {
sk.cancel();
}
try {
this.selector.close();
this.socketChannel.close();
} catch (IOException e) {
HAConnection.log.error("", e);
}
HAConnection.log.info(this.getServiceName() + " service end");
}
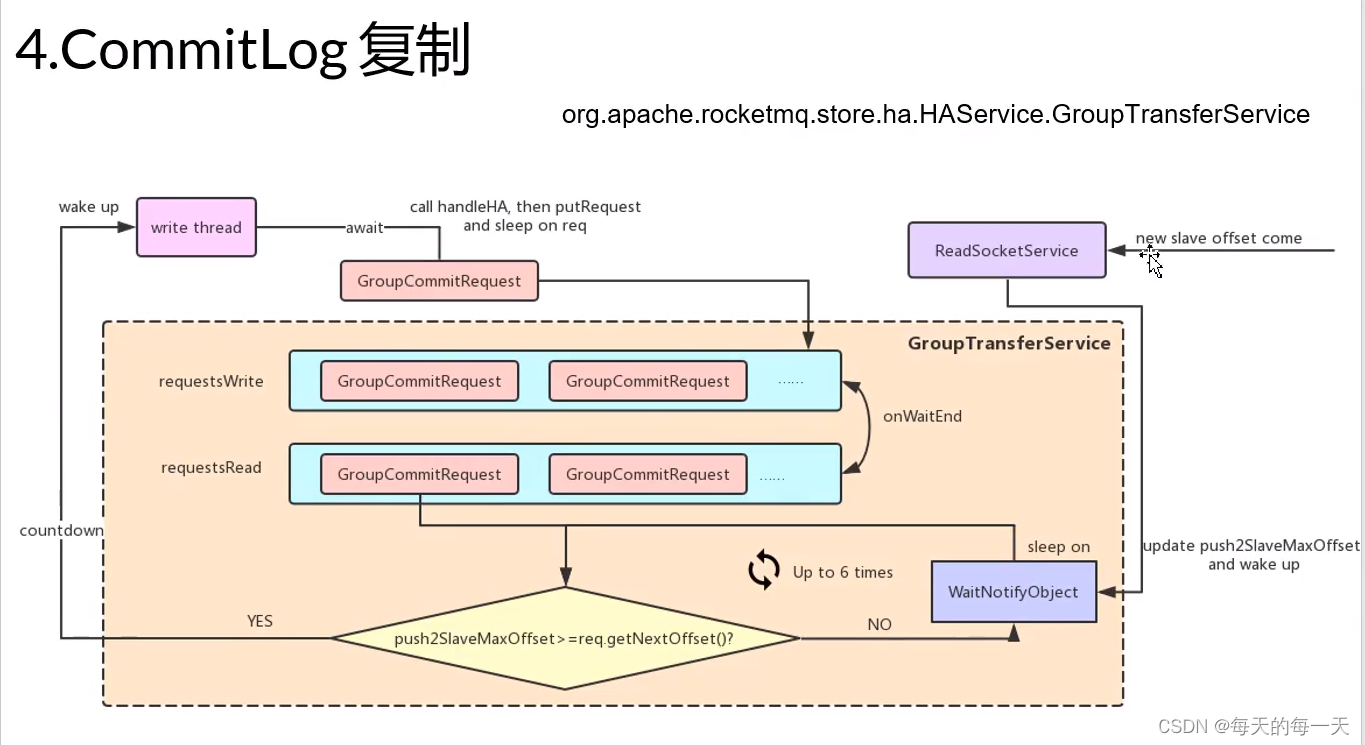
GroupTransferService实现原理
主要是同步复制的场景下
push2SlaveMaxOffset大于等于request中的offset,则说明当前commitRequest中携带的消息,已经复制到了slave上,如果是小于的,则GroupTransferService线程会睡在WaitNotifyObject上,但是有睡眠超时时间,如果睡醒又判断一次push2SlaveMaxOffset是否大于等于request中的offset,重复了6次,都是小于,那么就会给producer端发回一个同步slave超时的状态
678行,可能有多个slave的写线程,都因为没有新的消息进入commitlog而处于睡眠状态,所以此时如果有新的消息进来后,就需要通过wakeAll()唤醒所有的slave写线程
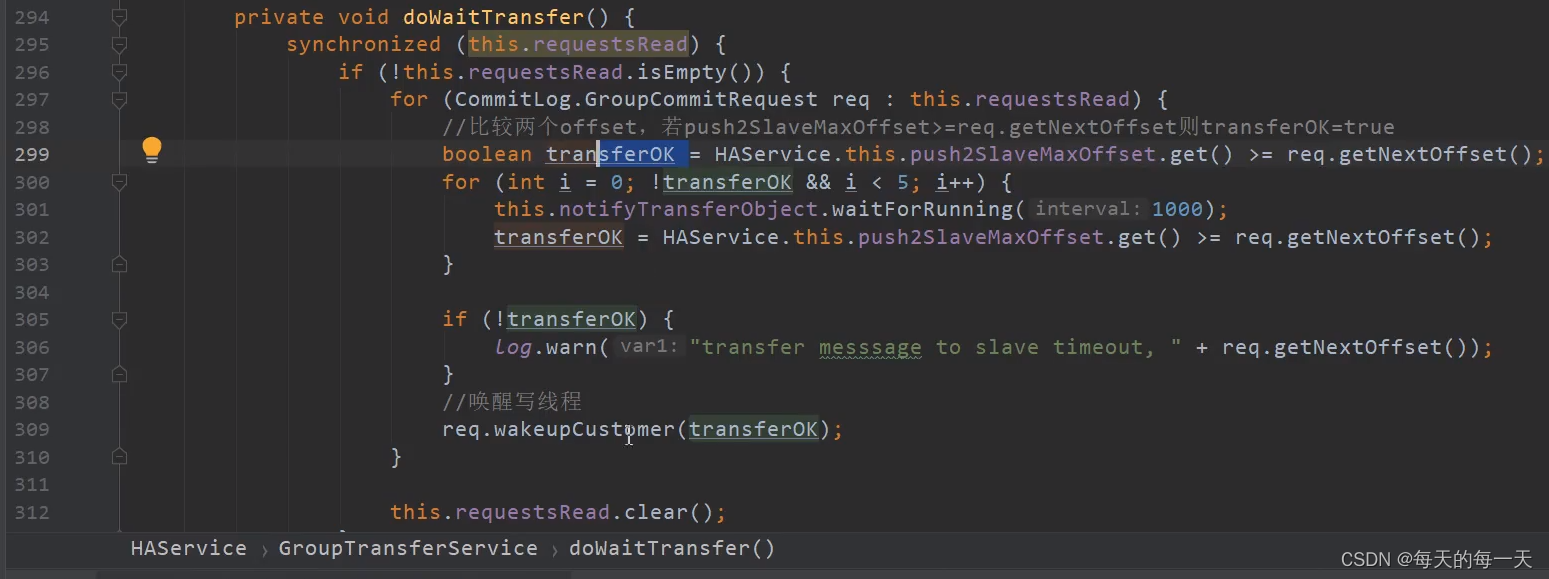
可以看到,不管同步slave是否成功,最终都会去唤醒producer写线程,只是会去给producer返回一个FLUSH_SLAVE_TIMEOUT
五大线程的协调关系
消息写入主线程:就是当同步slave未完成之前,自己睡在GroupCommitRequest上,多个GroupCommitRequest组成一批,由GroupTransferService统一管理
GroupTransferService:就是统一管理一批同时进来的,因为还未成功同步slave而阻塞住的消息写入主线程,每wait 1s后就自己醒来判断一次当前管理的这批阻塞线程,有谁完成了同步,则将它唤醒
ReadSocketService:每个M-S连接特有的线程,用于接收slave当前已同步的偏移量,既然收到slave的反馈,则需要唤醒某些消息发送主线程。ReadSocketService在成功更新push2SlaveMaxOffset后就会唤醒GroupTransferService,GroupTransferService再去比较主从位点来决定唤醒哪些消息发送主线程
WriteSocketService:每个M-S连接特有的线程,
HAClient:通过死循环,来每隔一段时间,往master的ReadSocketService线程,发送一次心跳,心跳数据就是当前slave的commitlog最大物理偏移
具体流程
当前同时有3个消息写入主线程进来,成功将消息写入commitlog后开始handleHA,此时一个wakeAll()将分别针对两台slave的WriteSocketService线程唤醒,然后3个主线程直接睡在各自的GroupCommitRequest上
当ReadSocketService每接收到一次slave上报过来的新的offset,并成功更新push2SlaveMaxOffset后,就会唤醒睡3个睡在各自的GroupCommitRequest上的主线程,主线程就可以给producer端发回消息写入并同步slave成功
WriteSocketService线程因为没有没有新的消息进来,当前正睡在HAService的WaitNotifyObject上
其他组件的主从复制
MySQL
主从复制的过程是这样的:首先从库在连接到主节点时会创建一个 IO 线程,用以请求主库更新的 binlog,并且把接收到的 binlog 信息写入一个叫做 relay log 的日志文件中,而主库也会创建一个 log dump 线程来发送 binlog 给从库;同时,从库还会创建一个 SQL 线程读取 relay log 中的内容,并且在从库中做回放,最终实现主从的一致性。这是一种比较常见的主从复制方式。
在这个方案中,使用独立的 log dump 线程是一种异步的方式,可以避免对主库的主体更新流程产生影响,而从库在接收到信息后并不是写入从库的存储中,是写入一个 relay log,是避免写入从库实际存储会比较耗时,最终造成从库和主库延迟变长。
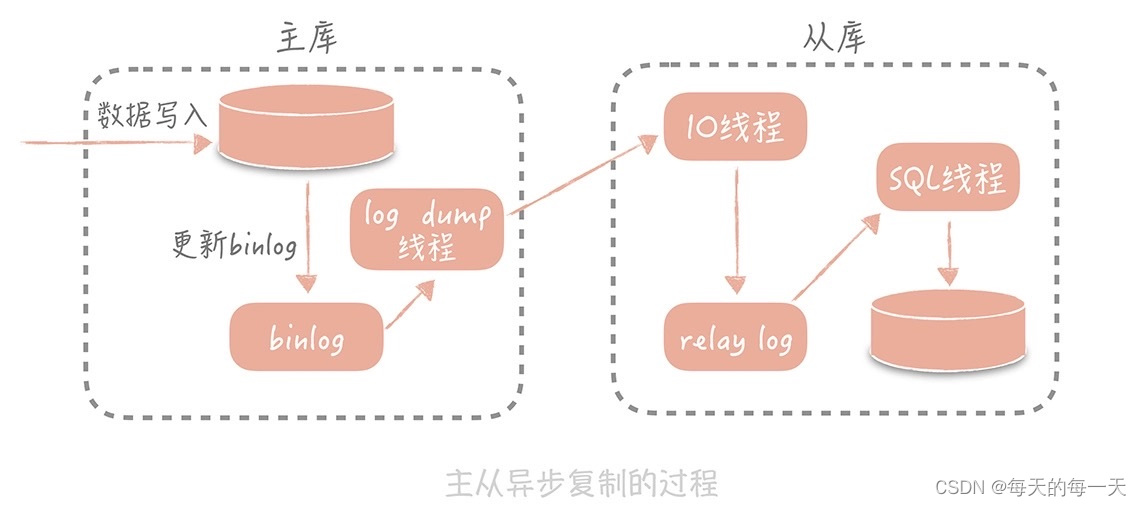
你会发现,基于性能的考虑,主库的写入流程并没有等待主从同步完成就会返回结果,那么在极端的情况下,比如说主库上 binlog 还没有来得及刷新到磁盘上就出现了磁盘损坏或者机器掉电,就会导致 binlog 的丢失,最终造成主从数据的不一致。不过,这种情况出现的概率很低,对于互联网的项目来说是可以容忍的














 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









