







1. MySQL 可扩展设计
数据库扩展解决了什么问题?
- 做热备份,保证多活,方便故障切换
- 负载均衡、读写分离
1.1 主从架构:Master-Slaves
在实际应用场景中,MySQL 复制 90% 以上都是一个 Master 复制到一个或者多个 Slave 的架构模式。
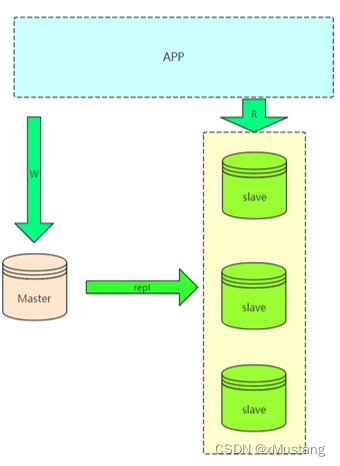
缺点:
- master 不能停机,停机就不能接收写请求。
- slave 过多会出现延迟。
由于 master 需要进行常规维护停机了,那必须要把一个slave提成master,会存在某一个 slave 提成 master 后,存在当前 master 和挂掉之前的 master 数据不一致的情况,并且之前 master 并没有保存当前 master 节点的 binlog 文件和 pos 位置。
1.2 双主架构:Master-Master
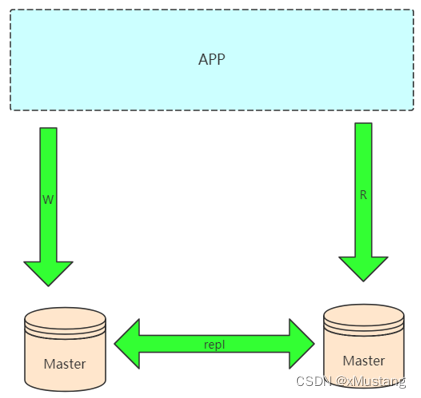
配合第三方的工具,比如 keepalived 轻松做到 IP 的漂移,当一个 master 挂掉后,请求转移到另一个 master。
1.3 级联复制架构:Master-Slaves-Slaves…
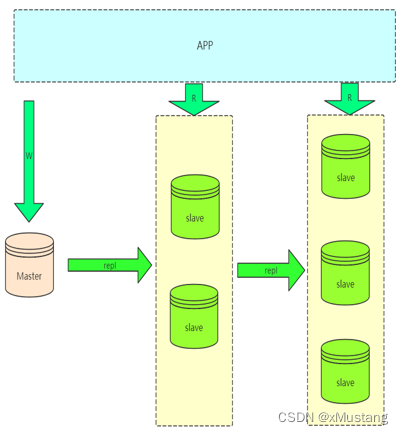
如果读压力加大,就需要更多的 slave 来解决,但是如果 slave 的复制全部从 master 复制,势必会加大 master 的复制 IO 的压力,所以就出现了级联复制,减轻 master 压力。缺点是 slave 延迟更加大了。
1.4 双主与级联复制架构:Master-Master-Slaves
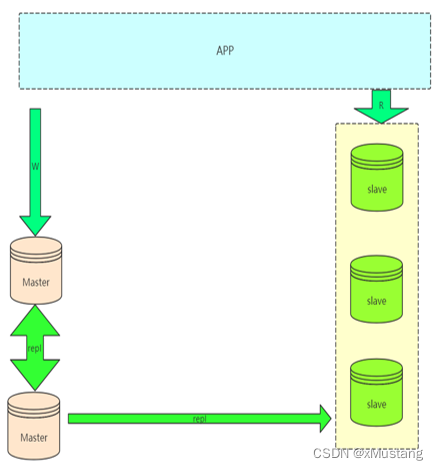
这样解决了单点 master 的问题,解决了 slave 级联延迟的问题。
1.5 复制机制
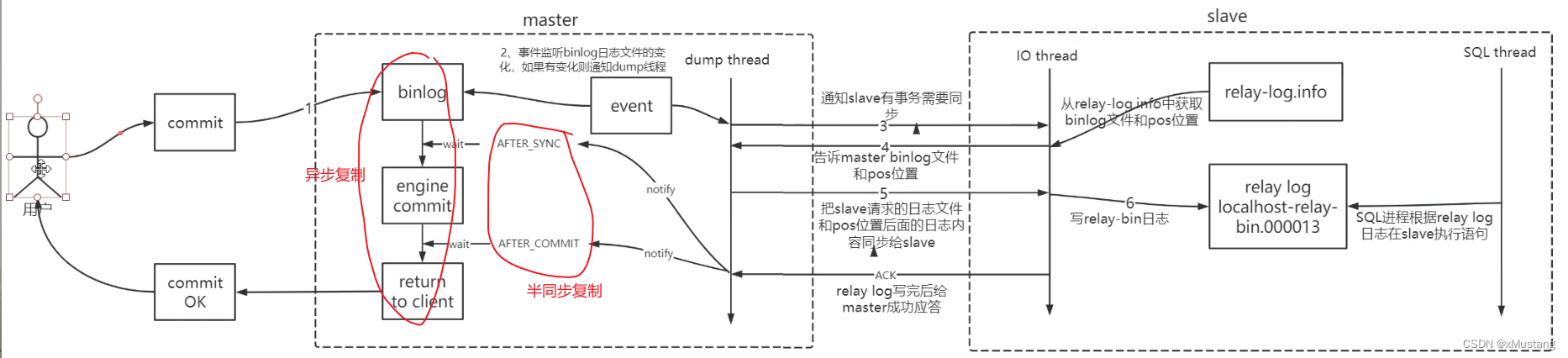
MySQL 复制支持异步复制、半同步复制:异步复制时不需要等待 slave 返回。
半同步复制失败后会切换为异步。
1.6 主从复制配置
master配置
server-id=135
log-bin=mysql-bin
auto_increment_increment=2
auto_increment_offset=1
lower_case_table_names=1
#binlog-do-db=mstest //要同步的mstest数据库,要同步多个数据库
#binlog-ignore-db=mysql //要忽略的数据库
slave配置
server-id=133
log-bin=mysql-bin
auto-increment-increment=2
auto-increment-offset=2
lower_case_table_names=1
#replicate-do-db = wang #需要同步的数据库
#binlog-ignore-db = mysql
#binlog-ignore-db = information_schema
- 在 master mysql 添加权限
GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;
- 在 master 上查看 master 的二进制日志
show master status;

- 在 slave 中设置 master 的信息
change master to master_host='192.168.88.135',master_port=3307,master_user='repluser',master_password='Jack@123456',master_log_file='mysql-bin.000001',master_log_pos=154;
- 开启 slave,启动 SQL 和 IO 线程
start slave;
- 查看 slave 的状态
show slave status\G
- 查看二进制日志是否开启
show global variables like "%log%";
- 查看进程信息
SHOW PROCESSLIST;
- 允许root远程连接
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'youpassword' WITH GRANT OPTION;
FLUSH PRIVILEGES;
1.7 半同步复制配置
- 加载 lib,所有主从节点都要配置
主库:install plugin rpl_semi_sync_master soname ‘semisync_master.so’;
从库:install plugin rpl_semi_sync_slave soname ‘semisync_slave.so’; - 查看,确保所有节点都成功加载。show plugins;
- 启用半同步
先启用从库上的参数,最后启用主库的参数。
从库:set global rpl_semi_sync_slave_enabled = {0|1}; # 1:启用,0:禁止
主库:
set global rpl_semi_sync_master_enabled = {0|1}; # 1:启用,0:禁止
set global rpl_semi_sync_master_timeout = 10000; # 单位为ms
2. MySQL 切分
数据切分指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
数据切分分为两种:
- 垂直切分
- 水平切分
2.1 数据库垂直切分
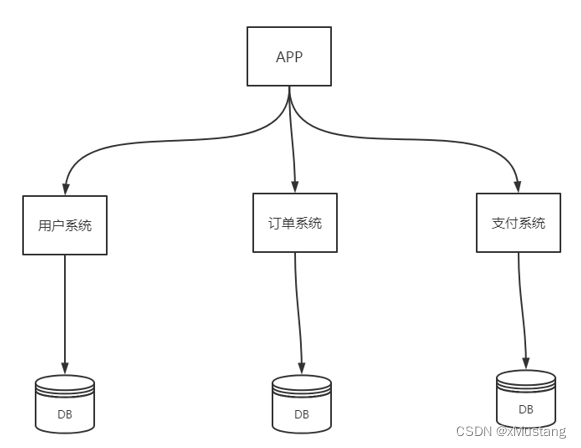
垂直切分的优点:
- 数据库的拆分简单明了,拆分规则明确;
- 应用程序模块清晰明确,整合容易;
- 数据维护方便易行,容易定位;
垂直切分缺点:
- 跨库 join
- 代码要重构,会有分布式事务问题
- 跨库分页问题。
部分表关联无法在数据库级别完成,需要在程序中完成,存在跨库 join 的问题,对于这类的表,就需要去做平衡,是数据库让步业务,共用一个数据源,还是分成多个库,业务之间通过接口来做调用;在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到了一定的规模,负载很大的情况,就需要必须去做分割。
对于访问极其频繁且数据量超大的表仍然存在性能瓶颈,不一定能满足要求。
事务处理相对更为复杂。
切分达到一定程度之后,扩展性会遇到限制。
过多切分可能会带来系统过渡复杂而难以维护。
2.2 数据库水平拆分
水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。
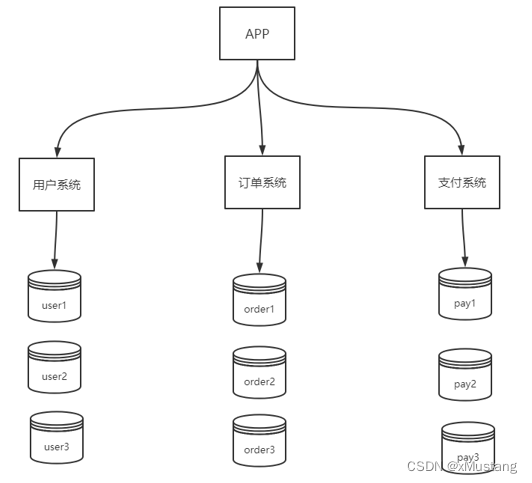
水平切分的优点:
- 表关联基本能够在数据库端全部完成;
- 不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
- 应用程序端整体架构改动相对较少;
- 事务处理相对简单;
- 只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点:
- 切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
- 后期数据的维护难度有所增加,人为手工定位数据更困难;
- 应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
- 跨节点合并排序分页问题
- 多数据源管理问题















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









