







WSDM 2024接收的论文已经公布,全部收录论文可前往以下地址。
网址:https://www.wsdm-conference.org/2024/accepted-papers/
其中推荐系统相关论文三十余篇,下文列举了部分论文的标题以及摘要,欢迎关注公众号【深度学习推荐算法】
1、Defense Against Model Extraction Attacks on Recommender Systems(南阳理工)【推荐系统攻防】
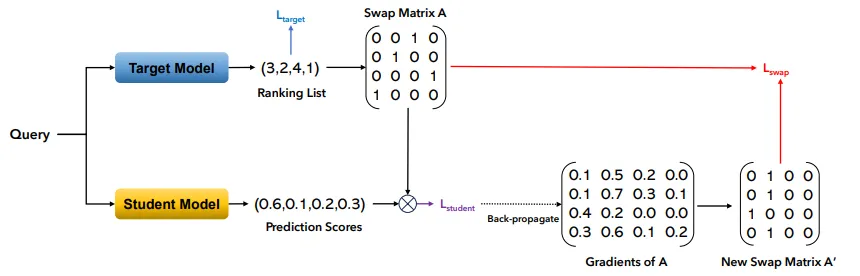
推荐系统的鲁棒性已成为研究界的一个重要课题。人们提出了许多对抗性攻击,但其中大多数都依赖于大量的先验知识,例如所有的白盒攻击或大多数黑盒攻击都假定某些外部知识是可用的。在这些攻击中,模型提取攻击是一种很有前途的实用方法,它通过反复查询目标模型来训练一个代理模型。然而,在防御推荐系统的模型提取攻击方面,现有文献还存在很大差距。在本文中,我们介绍了基于梯度的排名优化GRO,这是第一种旨在对抗此类攻击的防御策略。我们将这种防御形式化为一个优化问题,旨在使受保护目标模型的损失最小化,同时使攻击者代理模型的损失最大化。由于top-k排序列表是不可微的,因此我们将其转换为可微的交换矩阵。这些交换矩阵是学生模型的输入,学生模型会模仿代理模型的行为。通过反向传播学生模型的损失,我们得到了交换矩阵的梯度。这些梯度用于计算交换损失,使学生模型的损失最大化。我们在三个基准数据集上进行了实验,以评估GRO 的性能。
图 1:GRO 的工作流程,目标模型为输入查询生成一个排名列表,排名列表被转换成交换矩阵 A,然后将 A 与学生模型的输出相乘,计算出其损失。我们将损失并获得 A 的梯度,然后将其转换为新的交换矩阵 A′。利用 A 和 A′ 来学习一个能骗过学生模型的目标模型。
2、Motif-based Prompt Learning for Universal Cross-domain Recommendation(首都师范)【基于Motif的通用跨域推荐提示学习】
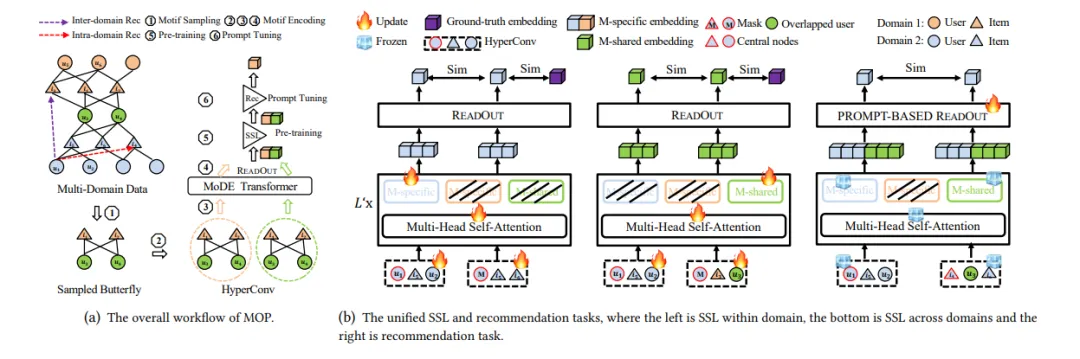
跨域推荐(CDR)是通过将一般知识从源域转移到目标域来解决数据稀缺和冷启动问题的关键技术。然而,由于其固有的复杂性,现有的 CDR模型在适应各种场景方面存在局限性。为了应对这一挑战,最近的研究成果引入了通用 CDR 模型,利用共享嵌入来捕捉跨领域的一般知识,并通过“多任务学习 ”或 “预训练、微调”范式进行传输。然而,这些模型往往忽略了跨领域的更广泛的结构拓扑,也未能统一训练目标,从而可能导致负迁移。为了解决这些问题,我们提出了一种基于图案的提示学习框架–MOP,它引入了基于图案的共享嵌入来封装通用领域知识,同时满足域内和域间CDR任务的需要。具体来说,我们设计了三种典型的图案:蝴蝶、三角形和随机行走,并通过基于图案的编码器对它们进行编码,从而获得基于图案的共享嵌入。此外,我们在“预训练&提示调整”范式下训练MOP。通过将预训练和推荐任务统一为一个共同的基于主题的相似性学习任务,并集成可调整的提示参数来指导模型的下游推荐任务,MOP在有效传递领域知识方面表现出色。在四个不同的CDR 任务上的实验结果表明,MOP 比最先进的模型更有效。
图 2:MOP 的整个框架。图 2(b) 显示了一个域内 CDR 实例,即在域内向𝑢1 推荐𝑖4。对于域间 CDR,即向𝑢1 推荐𝑖3,我们只对𝑢1 使用 M 共享嵌入式,但对𝑖3 同时使用 M 共享嵌入式和 M 特定嵌入式来执行推荐任务。
3、To Copy, or not to Copy; That is a Critical Issue of the Output Softmax Layer in Neural Sequential Recommenders(亚马逊)【复制或不复制;这是神经序列推荐器中输出Softmax层的一个关键问题】
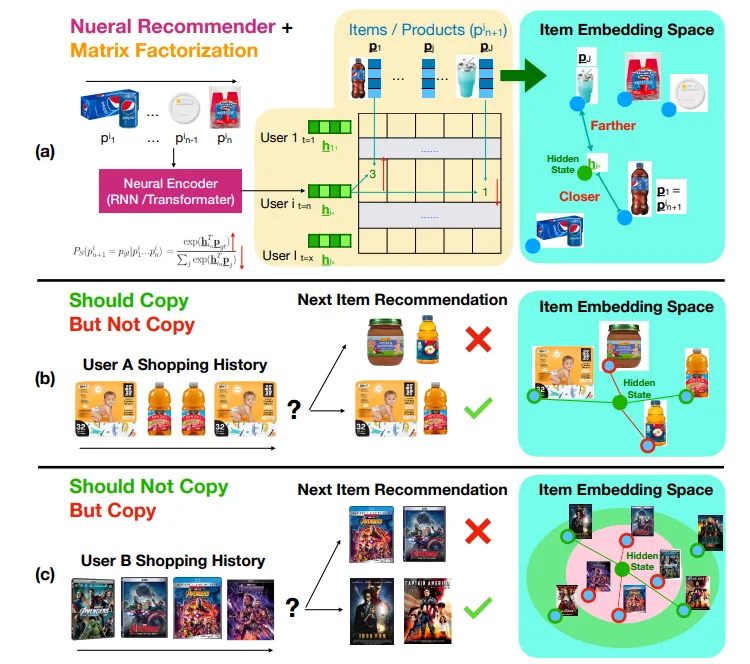
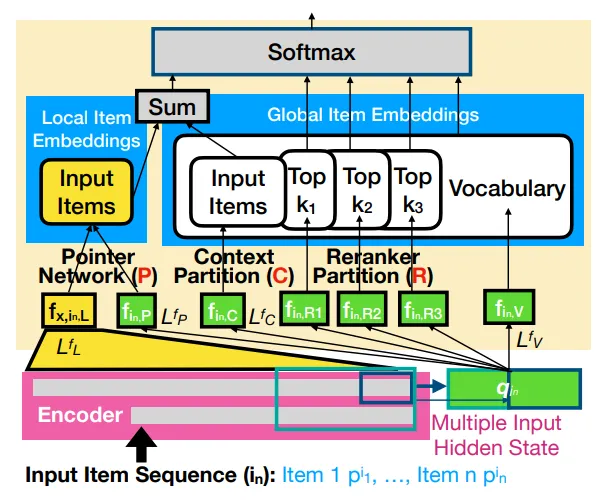
最近的研究表明,现有的神经模型很难处理连续推荐任务中的重复项目。然而,我们对这一困难的理解仍然有限。在本研究中,我们发现了问题的主要根源:输出软最大层中的单一隐藏状态嵌入和静态项目嵌入,从而大大推进了这一领域的研究。具体来说,softmax 层中全局项嵌入的相似性结构有时会迫使单隐态嵌入接近新项,而复制是更好的选择;有时又会迫使隐态接近输入中的项,这是不恰当的。为了缓解这一问题,我们将最近提出的软最大(softmax)替代方案(如 softmax-CPR)应用于顺序推荐任务,并证明新的软最大架构可以释放神经编码器的能力,让它学会何时复制输入序列中的项目,何时将其排除在外。只需对 SASRec 和 GRU4Rec 的输出 softmax 层做一些简单的修改,softmax-CPR 就能在 12 个数据集中实现一致的改进。在模型大小几乎相同的情况下,我们的最佳方法不仅在 5 个有重复项的数据集中将 GRU4Rec 的平均 NDCG@10 提高了 10%(分别为 4%-17%),而且还在 7 个无重复项的数据集中提高了 24%(8%-39%)。
图 2:神经顺序推荐器中输出软最大层的优点和问题。(a) 输出软最大层隐式地将交互矩阵分解为全局项目嵌入和神经编码器的隐藏状态。在这个例子中,项目嵌入空间的相似性结构有助于提高推荐器的泛化能力。(b) 在一个有许多重复物品的数据集中,推荐器经常需要从购物历史中复制物品,但嵌入空间中的物品相似性结构无法让推荐器输出所需的分布。© 在只有少量或没有重复商品的数据集中,模型需要学会不推荐用户已经接触过的商品,而是推荐与之相似的商品。理想的分布将在项目嵌入空间中形成一个甜甜圈形状,而这是 softmax 层中的单一隐藏状态和静态项目嵌入所无法模拟的。
图 4:softmax-CPR 和多输入隐藏状态(Mi)的结构。
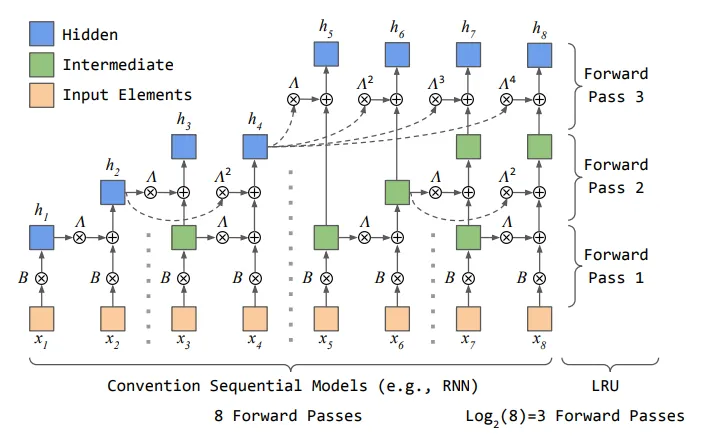
4、Linear Recurrent Units for Sequential Recommendation(伊利诺伊)【序列推荐的线性递归单元】
最先进的顺序推荐在很大程度上依赖于基于自注意力机制的推荐模型。然而,这种模型的计算成本很高,而且对于实时推荐来说速度往往太慢。此外,自注意操作是在序列级别上进行的,因此低成本的增量推理具有挑战性。受高效语言建模最新进展的启发,我们提出了用于序列推荐的线性递归单元(LRURec)。与递归神经网络类似,LRURec 可提供快速推理,并能实现对连续输入的增量推理。通过在我们的框架中分解线性递归操作和设计递归并行化,LRURec 提供了减少模型大小和可并行训练的额外优势。此外,我们还通过一系列修改优化了 LRURec 的架构,以解决缺乏非线性的问题并改善训练动态性。为了验证我们提出的 LRURec 的有效性,我们在多个真实数据集上进行了广泛的实验,并将其性能与最先进的顺序推荐器进行了比较。实验结果证明了 LRURec 的有效性,它的性能始终显著优于基线。实验结果还凸显了 LRURec 在并行化训练范式和长序列快速推理方面的效率,显示了它在进一步提升用户序列推荐体验方面的潜力。
图 2:LRURec 的递归并行化,我们展示了递归分割和并行前向传递。
图 3:LRURec 的整体架构。
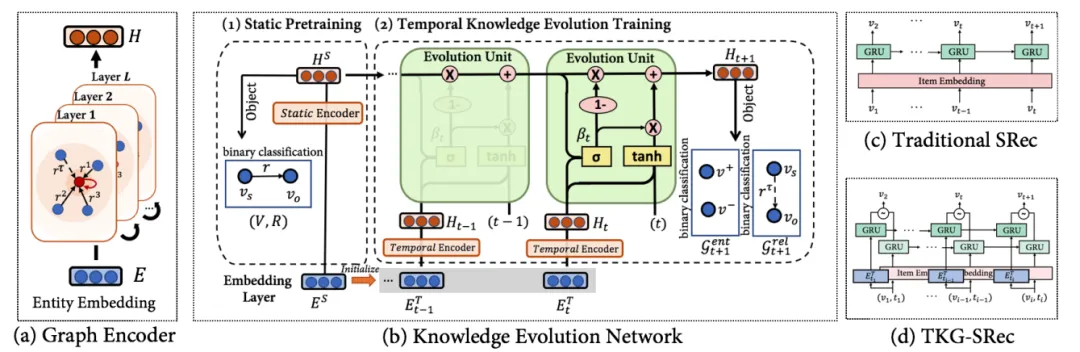
5、User Behavior Enriched Temporal Knowledge Graph for Sequential Recommendation(新加坡国立,华为)【用户行为丰富知识图谱,用于序列推荐】
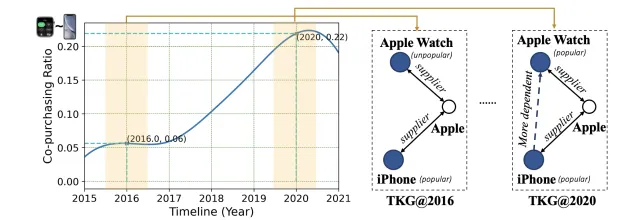
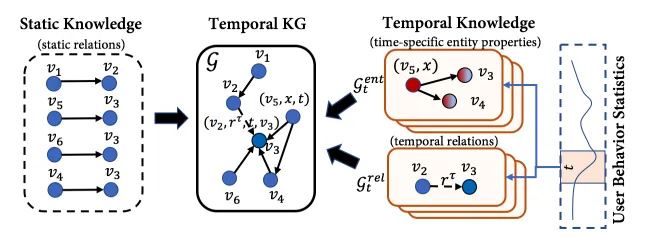
知识图谱(KG)通过提供项目之间的外部连接来增强推荐效果。然而,在连续推荐中提炼相关知识的研究还很有限,因为项目之间的联系会随着时间的推移而发生变化。为了解决这个问题,我们引入了时态知识图谱(TKG),它将用户行为的此类动态特征纳入原始知识图谱,同时强调顺序关系。TKG 同时捕捉实体动态(节点)和结构动态(边)的模式。考虑到现实世界中的应用具有大规模且快速演变的用户行为模式,我们提出了一种名为 TKG-SRec 的高效两阶段框架,该框架利用时态 KG 强化了顺序推荐。在第一阶段,我们使用新颖的知识进化网络(Knowledge Evolution Network,KEN)学习动态实体嵌入,该网络将预先训练的静态知识与不断进化的时态知识结合在一起。在第二阶段,下游顺序推荐模型将这些特定时间的动态实体嵌入与兼容的神经骨干(如 GRU、Transformers 和 MLP)结合使用。我们在四个数据集上进行了广泛的实验,结果表明 TKG-SRec 的性能比目前最先进的产品平均高出 5%。详细分析验证了这种经过过滤的时态知识能更好地调整实体嵌入,从而实现顺序推荐。总之,TKG-SRec 提供了一种有效且高效的方法。
图 1:TKG 利用了实体间的动态关系:(左)共同购买 iPhone 和 Apple Watch 随着时间的推移变得越来越重要;(右)导致 TKG 中的两个实体之间产生了新的依赖关系。
图 2:根据静态知识和时态知识构建时态 KGs。实线箭头表示静态关系,虚线箭头表示时间关系。
图 3:时态知识图谱增强序列推荐框架。KEN 组件(b)利用(a)图编码器学习动态实体嵌入,顺序推荐组件(d)利用动态实体嵌入技术,将其融入基于 RNN 的传统骨干网(c)中。
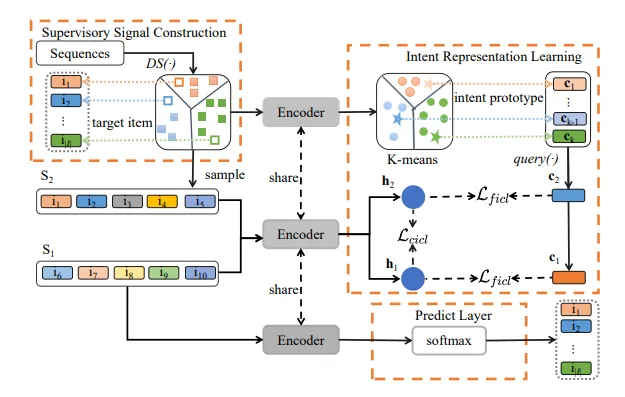
6、Intent Contrastive Learning with Cross Subsequences for Sequential Recommendation(东吴大学)【基于跨子序列的意图对比学习序列推荐】
用户的购买行为主要受其意图的影响(如购买装饰用的衣服、购买绘画用的画笔等)。对用户的潜在意图进行建模可以显著提高推荐的性能。以往的研究通过考虑辅助信息中的预定义标签或引入随机数据增强来学习潜在空间中的目的,从而对用户意图进行建模。然而,对于推荐系统来说,辅助信息是稀疏的,并不总是可用的,而且引入随机数据增强可能会引入噪声,从而改变隐藏在序列中的意图。因此,利用用户意图进行序列推荐(SR)可能具有挑战性,因为用户意图经常变化且无法观测。本文提出了用于序列推荐的跨序列对比学习(ICSRec)来模拟用户的潜在意图。具体来说,ICSRec 首先使用动态滑动操作将用户的连续行为分割成多个子序列,然后将这些子序列带入编码器,生成用户意图的表示。为了解决没有明确目的标签的问题,ICSRec 假设具有相同目标项的不同子序列可能代表相同的意图,并提出了粗粒度意图对比学习来拉近这些子序列的距离。然后,提到了细粒度意图对比学习,以捕捉连续行为中子序列的细粒度意图。在四个真实世界数据集上进行的大量实验证明,与基线方法相比,所提出的 ICSRec 模型性能更优。
图 2:ICSRec 的模型架构。其中,𝑆2 和 𝑆1 表示具有相同目标项的两个子序列;h2 和 h1 表示通过编码器 𝑓𝜃(-) 得到的两个粗粒度意图;c2 和 c1 表示通过聚类得到的两个细粒度意图。
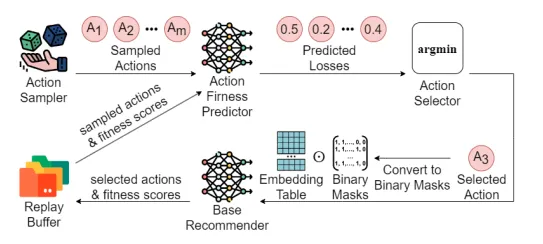
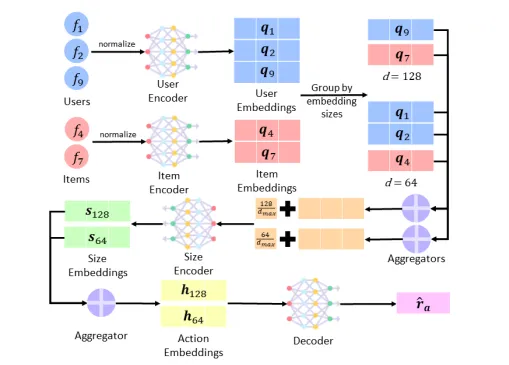
7、Budgeted Embedding Table For Recommender Systems(昆士兰)【推荐系统的嵌入表研究】
当代推荐系统(RS)的核心是为用户提供优质推荐体验的潜在因素模型。这些模型使用嵌入向量来表示用户和项目,嵌入向量通常大小统一且固定。随着用户和项目数量的不断增加,这种设计变得低效且难以扩展。最近的轻量级嵌入方法使不同的用户和项目可以有不同的嵌入大小,但通常有两个主要缺点。首先,这些方法将嵌入大小的搜索限制在对推荐质量和内存复杂度之间的启发式平衡进行优化,而在这种情况下,需要针对每次内存预算请求对权衡系数进行手动调整。隐式执行的内存复杂度项甚至可能无法限制参数的使用,导致生成的嵌入表无法严格满足内存预算要求。其次,大多数解决方案,尤其是基于强化学习的解决方案,都是在逐个实例的基础上推导和优化每个用户/项目的嵌入大小,这妨碍了搜索效率。在本文中,我们提出了 Budgeted Embedding Table (BET),这是一种生成表级操作(即所有用户和项目的嵌入大小)的新方法,可保证满足预先指定的内存预算。此外,通过利用基于集合的行动表述和参与集合表示学习,我们提出了一种创新的行动搜索策略,该策略由行动适配性预测器驱动,可有效评估每个表级行动。实验表明,在不同的内存预算下,当 BET 与三种流行的推荐模型配对使用时,在两个真实数据集上都能获得最先进的性能。
图 1:BET 概述。
图 3:基于 DeepSets 的适配性预测器概览。
8、Pre-trained Recommender Systems: A Causal Debiasing Perspective(威斯康星,亚马逊)【预训练推荐系统:因果去偏的视角】
最近关于预训练视觉/语言模型的研究已经证明了人工智能领域一种新的、有前途的解决方案构建范式的实际好处,即可以在描述通用任务空间的广泛数据上对模型进行预训练,然后将其成功地调整为解决广泛的下游任务,即使在训练数据非常有限的情况下(例如,在零或少量学习场景中)也是如此。受这一进展的启发,我们在本文中研究了将这种范式应用于推荐系统的可能性和挑战,因为从预训练模型的角度来看,对推荐系统的研究较少。特别是,我们建议开发一种通用推荐器,通过对从不同领域提取的通用用户-物品交互数据进行训练来捕捉通用交互模式,然后快速调整,以提高在未见过的新领域(数据有限)中的少量学习性能。然而,与视觉/语言数据在语义空间中具有很强的一致性不同,在不同领域(如不同国家或不同电子商务平台)收集的推荐数据所包含的普遍模式往往被领域内和跨领域的偏差所遮蔽,这些偏差是由用户和项目基础的文化差异以及他们对不同电子商务平台的使用所隐含强加的。正如我们的实验所显示的,数据中的这种异质性偏差往往会阻碍预训练模型的有效性。为了应对这一挑战,我们进一步引入并正式确定了因果去除法的观点,并通过一个名为PreRec的分层贝叶斯深度学习模型加以证实。我们对真实世界数据的实证研究表明,在跨市场和跨平台场景下,所提出的模型可以显著提高零学习和少学习设置下的推荐性能。
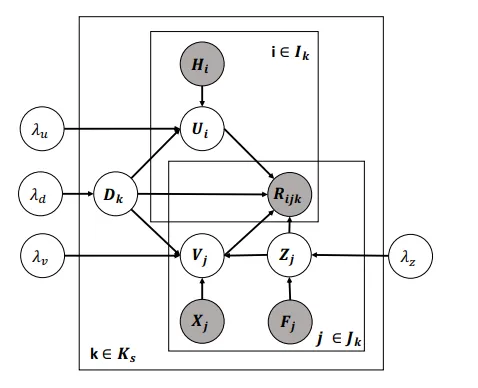
图 1:我们的概率图模型PGM用于PreRec. U𝑖 和 H𝑖 代表用户𝑖 和相应的用户,V𝑗, X𝑗, and Z𝑗 代表项目𝑗、其文字描述(如电影简介)及其受欢迎程度效应;F𝑗 代表影响项目受欢迎程度的所有重要因素;D𝑗 代表项目𝑗、其文字描述(如电影简介)及其受欢迎程度效应。D𝑘 代表领域𝑘,𝑠代表所有源域,而𝑘和𝐼𝑘分别代表域𝑘中的所有项目和所有用户。𝜆𝑢、𝜆𝑣、𝜆𝑑、𝜆𝑧是与分布方差有关的超参数。
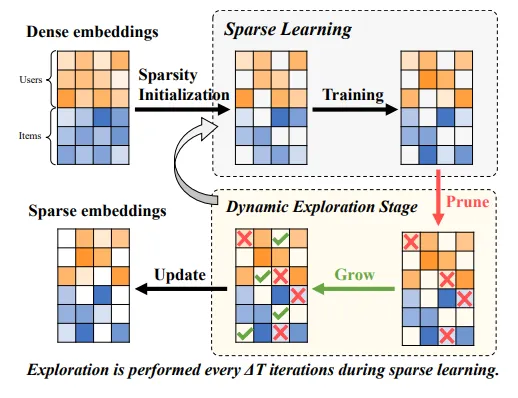
9、Dynamic Sparse Learning: A Novel Paradigm for Efficient Recommendation(中科大)【动态稀疏学习:一种高效推荐的新范式】
在基于深度学习的推荐系统领域,由于用户和项目数量不断增加,计算需求也随之增加,这给实际部署带来了巨大挑战。这一挑战主要有两个方面:缩小模型大小,同时有效学习用户和项目表征,以实现高效推荐。尽管在模型压缩和架构搜索方面取得了相当大的进步,但流行的方法仍面临着明显的限制。其中包括模型压缩中的预训练/再训练和架构设计中的广泛搜索空间所带来的大量额外计算成本。此外,管理复杂性和遵守内存限制也是个问题,尤其是在有严格时间或空间限制的情况下。为了解决这些问题,本文介绍了一种专为推荐模型量身定制的新型学习范式–动态稀疏学习(DSL)。DSL 创新性地从头开始训练一个轻量级稀疏模型,在训练过程中定期评估和动态调整每个权重的重要性和模型的稀疏性分布。这种方法确保了在整个学习周期中始终保持最小的参数预算,为提高从训练到推理的 “端到端 ”效率铺平了道路。我们广泛的实验结果表明了 DSL 的有效性,它大大降低了训练和推理成本,同时提供了相当的推荐性能。
本文工作的代码链接:https://github.com/shuyao-wang/DSL
图 1:动态稀疏学习 (DSL) 框架概览。
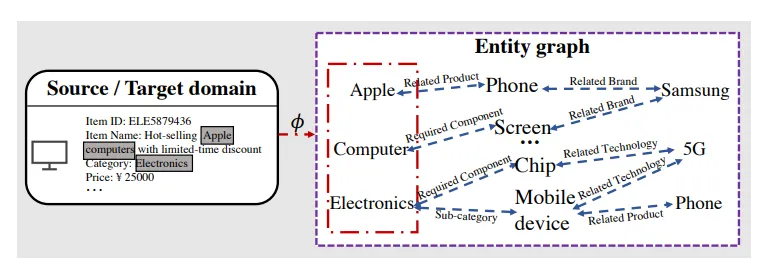
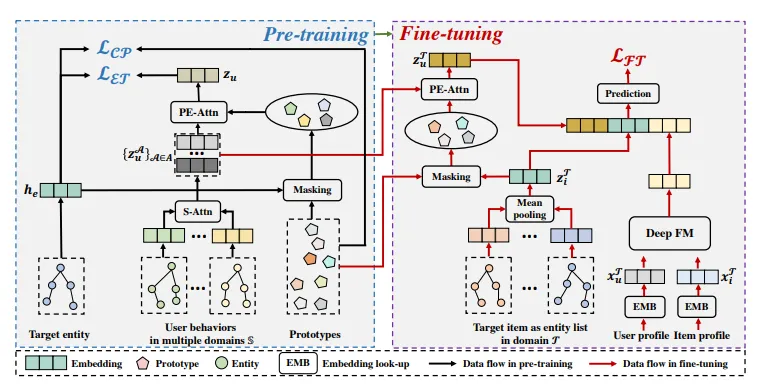
10、PEACE: Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation(蚂蚁)【PEACE:用于跨域推荐的原型lEarning增强可迁移框架】
为了帮助商家/客户通过小应用程序提供/获取各种服务,在线服务平台在有效的内容交付中占据了至关重要的地位,其中如何为客户推荐服务提供商推出的新领域中的项目变得更加迫切。然而,源域和多样化目标域之间不可忽视的差距给跨域推荐系统带来了相当大的挑战,在工业环境中往往会导致性能瓶颈。虽然实体图有可能成为领域间的桥梁,但不成熟的利用方式仍无法提炼出有用的知识,甚至会诱发负迁移问题。为此,我们提出了 PEACE,一个用于跨领域推荐的原型学习增强型可转移框架。为了弥补领域差距,PEACE 建立在多兴趣和面向实体的预训练架构之上,这不仅有利于以多粒度方式学习广义知识,还有助于利用实体图中的更多结构信息。然后,我们将原型学习引入源域的预训练中,通过对比原型学习模块和原型增强关注机制,大大改进了用户和项目的表征,从而实现自适应知识利用。为了减轻在线服务的压力,PEACE 以轻量级的方式进行了精心部署,在线和离线环境下都观察到了显著的性能改进。
图 1:项目-实体映射和图式推理的总体流程图推理
图 2:PEACE 的整体架构,其中 S-Attn 和 PEAttn 分别表示自注意和原型增强注意。
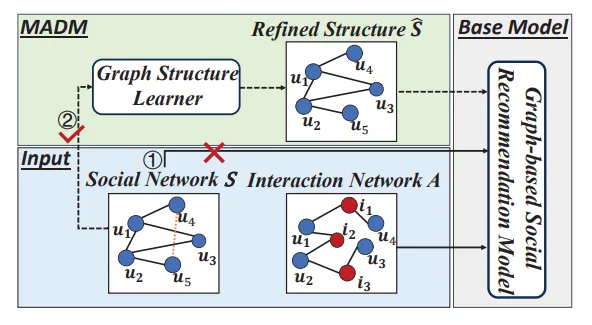
11、MADM: A Model-agnostic Denoising Module for Graph-based Social Recommendation(上交)【MADM:一个基于图的社交推荐的模型无关去噪模块】
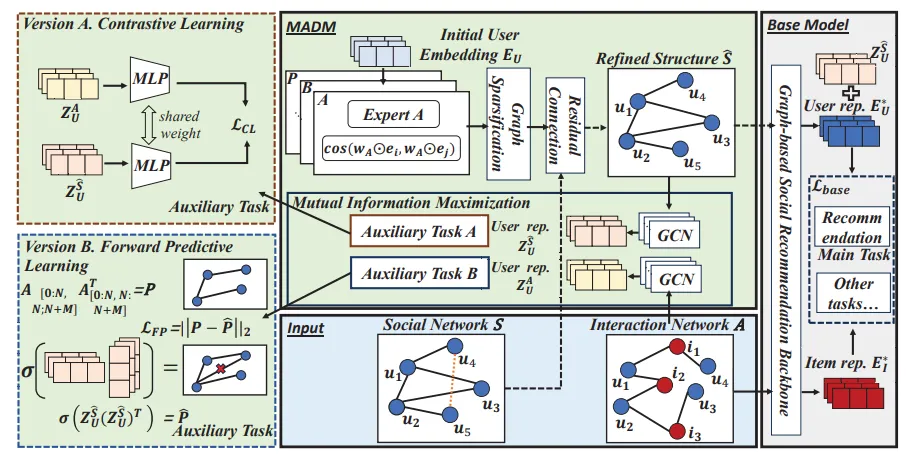
基于图的社交推荐通过利用社交关系中包含的高阶邻接信息来提高推荐的预测准确性。然而,大多数研究都忽略了社会关系可能对推荐产生噪声的问题。一些研究试图通过对社交图去噪来解决这一问题,但它们存在以下问题:1)对其他基于图的社交推荐模型的适应性问题;2)用户社交表征学习不足的问题。为了解决这些局限性,我们提出了一种与模型无关的图去噪模块(简称为 MADM),该模块可以即插即用,为基础模型提供精细的社会结构。同时,为了使用户社交表征最小化并足以用于推荐,MADM 进一步采用了用户社交表征与交互图之间的互信息最大化(MIM),并实现了两种 MIM 方式:对比学习和前向预测学习。我们从信息论(Information Theory)和多视角学习(Multi-view Learning)的角度提出了理论见解和保证,以解释其合理性。在三个真实世界数据集上的广泛实验证明了 MADM 的有效性。
图 1:在基础模型中应用 MADM 的示意图。我们的 MADM 不提供有噪声的社交网络,而是作为即插即用的社交图谱去噪模块来工作,可作为即插即用的社会图去噪模块,为基础模型提供精细的社会结构。
图 2:整体架构分为三个部分。蓝色部分是输入。灰色部分是基础模型可以是任何基于图的社交推荐模型。绿色部分展示了 MADM 如何作为一个插件来学习完善的社交图结构,以增强基础模型的稳健性。
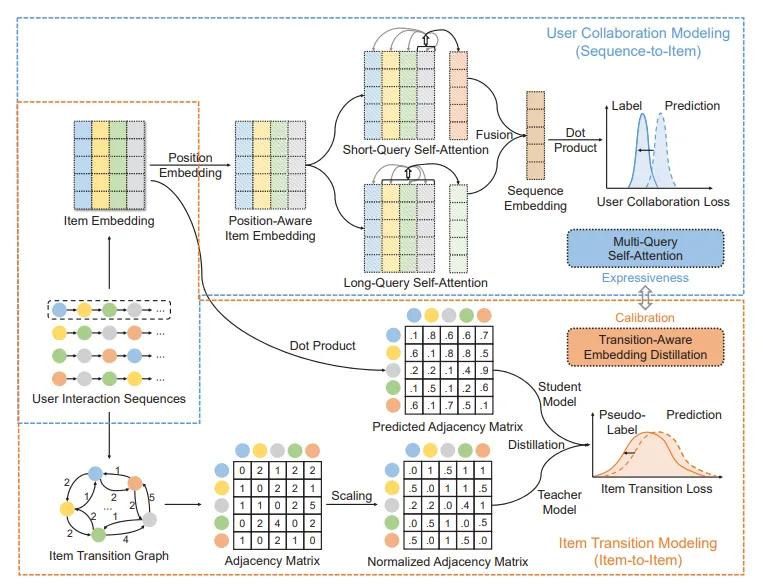
12、Collaboration and Transition: Distilling Item Transitions into Multi-Query Self-Attention for Sequential Recommendation(蒙特利尔,快手)【协作与转换:提取项目转换为序列推荐的多查询自注意力机制】
现代推荐系统采用各种顺序模块(如自注意力)来学习动态的用户兴趣。然而,这些方法在捕捉用户交互序列中的协作信号和过渡信号方面效果不佳。首先,自注意力架构使用单个项目的嵌入作为关注查询,因此捕捉协作信号具有挑战性。其次,这些方法通常采用自动回归框架,无法学习全局项目过渡模式。为了克服这些局限性,我们提出了一种新方法,称为 “多查询自注意力与过渡感知嵌入蒸馏(MQSA-TED)”。首先,我们提出了一个 L-query 自注意力模块,它采用灵活的关注查询窗口大小来捕捉协作信号。此外,我们还引入了一种多查询自注意力方法,通过结合长查询和短查询自注意机制,在用户偏好建模中平衡偏差-方差权衡。其次,我们开发了过渡感知嵌入提炼模块,将全局项目到项目的过渡模式提炼为项目嵌入,从而使模型能够记忆和利用过渡信号,并作为协作信号的校准器。在四个真实数据集上的实验结果证明了所提模块的有效性。
图 2:MQSA-TED 方法示意图,它由两个主要部分组成:1) 用于用户协作建模的多头自注意力机制(Multi-Query Self Attention), 2) 用于项目转换建模的转换感知嵌入蒸馏(TransitionAware Embedding Distillation)。
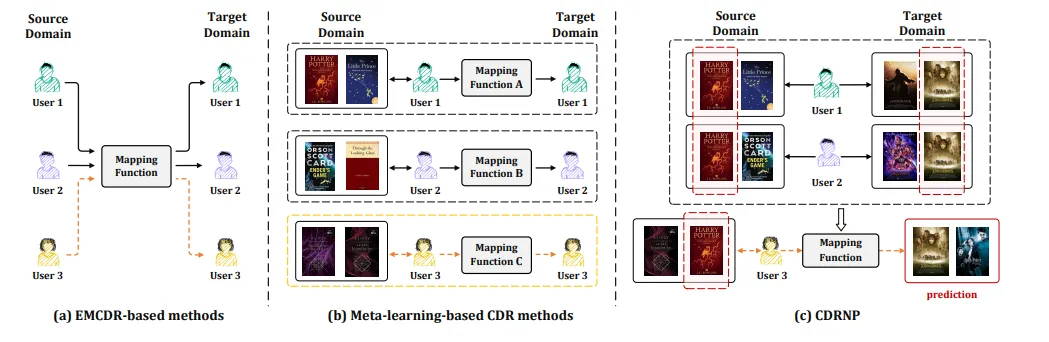
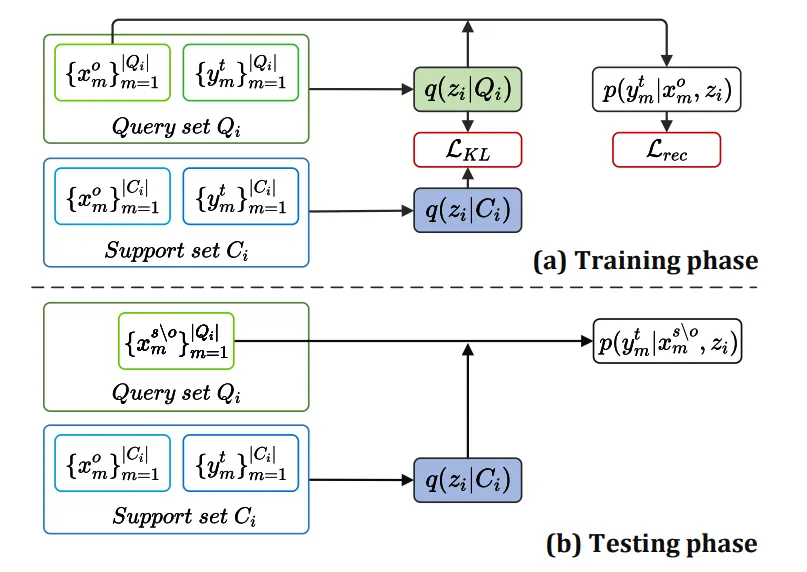
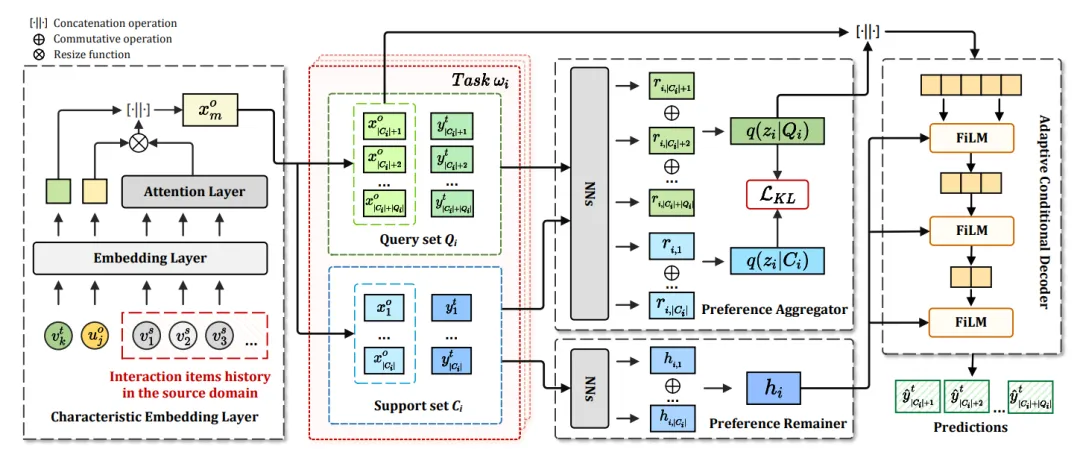
13、CDRNP: Cross-Domain Recommendation to Cold-Start Users via Neural Process(中科院)【CDRNP:通过神经过程向冷启动用户提供跨领域推荐】
跨域推荐(CDR)已被证明是解决用户冷启动问题的一种有前途的方法,其目的是通过转移源域中的用户偏好,为目标域中的用户提供推荐。传统的 CDR 研究遵循嵌入和映射(EMCDR)范式,通过学习用户共享的映射函数将用户表征从源域转移到目标域,而忽略了用户的特定偏好。最近的 CDR 研究试图在元学习范式中学习用户特定的映射函数,这种范式将每个用户的 CDR 视为一项单独的任务,但忽略了用户之间的偏好相关性,从而限制了用户表征的有利信息。此外,这两种范式在映射过程中都忽略了两个领域中用户与项目之间的明确交互。为解决上述问题,本文提出了一种新颖的带有神经过程(NP)的 CDR 框架,称为 CDRNP。特别是,它开发了元学习范式来利用用户特定偏好,并进一步通过 NP 引入随机过程来捕捉重叠用户和冷启动用户之间的偏好相关性,从而通过将用户特定偏好和共同偏好相关性映射到预测概率分布来生成更强大的映射函数。此外,我们还引入了一个偏好保持器来增强重叠用户的共同偏好,最后设计了一个带有偏好调制的自适应条件解码器,以便对目标域中有项目的冷启动用户进行预测。实验结果表明,在三个真实 CDR 场景中,CDRNP 优于之前的 SOTA 方法。
图 1:用户 1 和用户 2 是重叠用户,用户 3 是冷启动用户。(a) 通过学习用户共享的映射函数,基于 EMCDR 方法的框架。(b) 通过学习特定用户的映射函数,基于元学习的 CDR 方法框架。© 通过捕捉用户之间的偏好相关性而建立的 CDRNP 框架。
图 2:我们的模型 CDRNP 与 NP 在训练和测试阶段的示意图。训练和测试阶段的图示。
图 3:训练阶段的 CDRNP 框架。特征嵌入层用于生成𝒙𝑜𝑚。这两个C𝑖 和 Q𝑖 都被编码以生成变分先验和后验。从偏好保持器中学习到的𝒉𝑖 用于调节解码器参数。从△(𝒛𝑖|Q𝑖)中采样的𝒛𝑖 被用于调节解码器参数,然后与 Q𝑖 中的𝒙𝑜𝑚连接,通过解码器预测 Q𝑖 的𝑦ˆ𝑡𝑚。
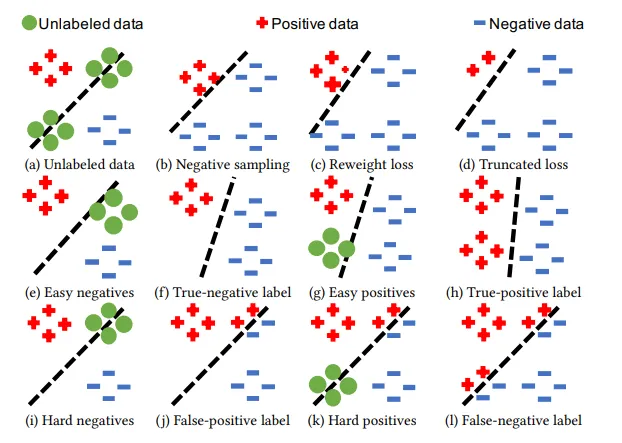
14、Inverse Learning with Extremely Sparse Feedback for Recommendation(卡耐基梅隆,快手)【具有极稀疏反馈的反向学习推荐】
现代个性化推荐服务通常依赖于用户的显性或隐性反馈来提高服务质量。显性反馈指的是评分等行为,而隐性反馈指的是用户点击等行为。然而,在 Tiktok 和 Reels 等全屏视频观看体验中,由于没有点击操作,用户的反馈并不明确,因此在建模训练中引入了噪声。现有的去噪推荐方法主要关注正向实例,而忽略了大量采样负反馈中的噪声。本文提出了一种元学习方法,从损失和梯度的角度对未标注数据进行注释,该方法同时考虑了正负实例中的噪声。具体来说,我们首先提出了一种反向双损失(IDL)来提高真标签学习并防止假标签学习。然后,我们进一步提出了反梯度(IG)方法,以探索正确的更新梯度,并基于元学习调整更新。最后,我们在基准数据集和工业数据集上进行了大量实验,结果表明,与最先进的方法相比,我们提出的方法能显著提高 AUC 9.25%。进一步的分析验证了所提出的反向学习框架与模型无关,可以改进各种推荐骨干网。源代码以及最佳超参数设置可从以下链接获取:
https://github.com/Guanyu-Lin/InverseLearning
图 1:现有解决方案和我们的反向对偶损耗的有效性和局限性说明。(a)-(d) 是现有解决方案的示例:(a) 说明存在大量未标记数据;(b) 说明传统的负采样方法;© 说明 DenoisingRec 的重加权损失;(d) 说明 DenoisingRec 在假阴性实例上的截断损失。(e)-(f)说明了我们的反二元损失在简易采样中的有效性:(e)说明了简易负实例采样;(f)说明了将采样实例标注为真负值;(g)说明了简易正实例采样;(h)说明了将采样实例标注为真正值并近似于地面实况。(i)-(l)说明了我们的反向二元损失法在硬采样时的局限性:(i) 说明了硬阴性实例被采样;(j) 说明了将部分采样实例标记为假阳性;(k) 说明了硬阳性实例被采样;(l) 说明了将部分采样实例标记为假阴性。
图 2:反梯度自适应图示
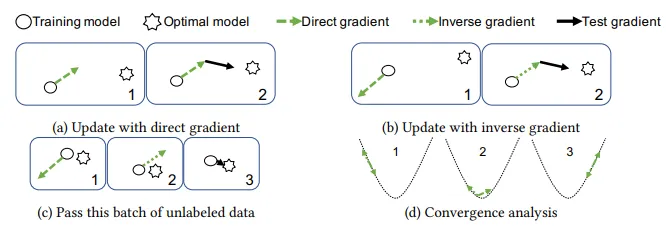
15、Contextual MAB Oriented Embedding Denoising for Sequential Recommendation(北邮)【面向上下文MAB的序列推荐嵌入去噪】
深度神经网络现已成为顺序推荐的事实标准。在现有技术中,会为每个项目分配一个嵌入向量,将后者的所有特征都编码到潜在空间中。然后,推荐被转移到设计一个相似度量来推荐用户的下一步行为。在这里,我们将嵌入向量的每个维度视为一个(潜在)特征。虽然有效,但不知道哪个特征对项目具有什么语义。实际上,在现实中,这一优点是非常可取的,因为一组特定的特征可以诱发项目之间的特定关系,而其他特征则是徒劳的。遗憾的是,以往的处理方法忽略了在这种细粒度水平上的特征语义学习。当每个项目都包含多个潜在方面时,项目之间的关系就会变得非常复杂。现有的解决方案很容易无法实现更好的推荐性能。因此,有必要将项目嵌入拆分开来,并以上下文感知的方式提取可信的特征。为了解决这个问题,我们在这项工作中提出了一种新颖的基于上下文多臂匪特算法的嵌入式去噪模型(简称 COMED),用于自适应地识别相关维度的特征,以获得更好的推荐效果。具体来说,COMED 将嵌入式去噪任务表述为一个上下文多臂匪特(Contextual Multi-armed Bandit)问题。对于项目嵌入的每个特征,我们都会分配一个双臂神经匪特来确定是否应保留其组成语义,从而将整个过程视为嵌入去噪。通过将去噪后的嵌入作为上下文信息进行汇总,我们进一步设计了一个由历史交互序列与目标项目之间的相似性推导出的奖励函数,以近似匪帮的最大预期回报,从而实现高效学习。考虑到串行运行机制的训练效率可能较低,我们还设计了一种快速学习策略,以加速翻新的序列嵌入与神经匪帮并行行动之间的共同指导,从而获得更好的推荐。在四个广泛认可的基准上进行的综合试验证明了我们框架的效率和功效。
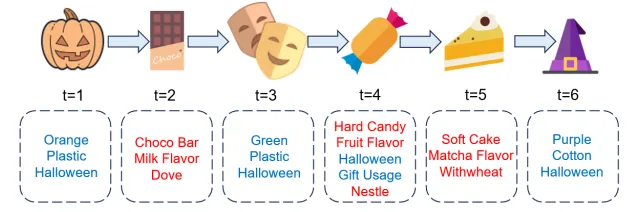
图 1:举例说明特征对推荐的不同作用。红色维度代表与巧克力→糖果→蛋糕模式相关的特征,蓝色维度代表与南瓜→面具→糖果→巫师帽模式相符的特征。
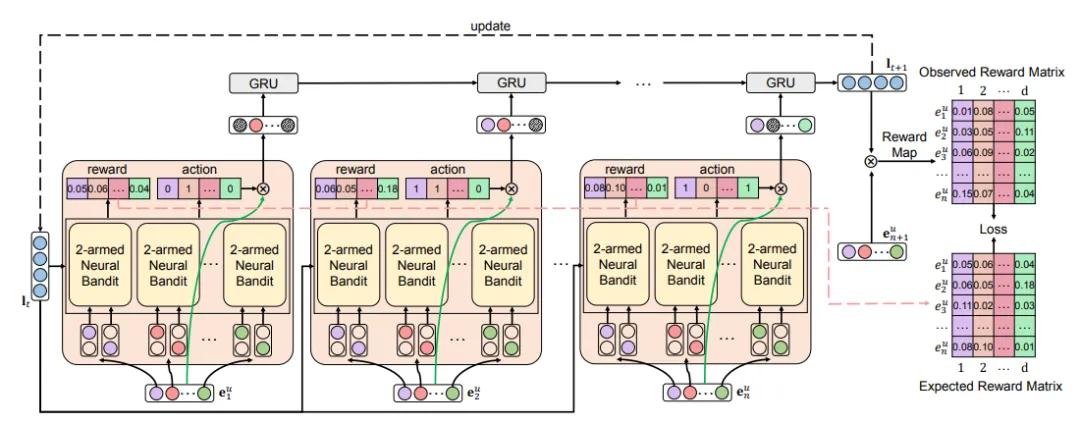
图 2:基于上下文 MAB 的嵌入式去噪算法(简称 Comed)学习去噪表征的整体架构。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











