







WSDM 2023的论文录用结果已出,推荐系统相关的论文方向包含序列推荐,点击率估计等领域,涵盖图学习,对比学习,因果推断,知识蒸馏等技术,累计包含近四十篇论文,下文列举了部分论文的标题以及摘要,更多内容欢迎关注公众号【深度学习推荐算法】,论文地址:
https://www.wsdm-conference.org/2023/program/accepted-papers
1 Federated Unlearning for On-Device Recommendation【联邦学习,昆士兰,多家公司】
推荐系统中日益增长的数据隐私问题使得联邦推荐受到越来越多的关注。现有的联邦推荐系统主要关注如何有效、安全地从用户在设备上的交互数据中学习个人兴趣和偏好。然而,它们都没有考虑如何有效地抹去用户对联邦训练过程的贡献。我们认为这种双重设置是必要的。首先,从隐私保护的角度来看,“被遗忘权(RTBF)”要求用户有权撤回其数据贡献。如果没有可逆的能力,联邦推荐系统就有违反数据保护法规的风险。另一方面,使联邦推荐器能够忘记特定用户可以提高其鲁棒性和对恶意客户端攻击的抵抗力。
为了支持联邦推荐系统中的用户遗忘,我们提出了一种有效的遗忘方法FRU(Federated Recommendation Unlearning),其灵感来自数据库管理系统中基于日志的事务回滚机制。它通过回滚和校准历史参数更新来删除用户的贡献,然后使用这些更新来加速联邦推荐器重建。然而,将所有历史参数更新存储在资源受限的个人设备上是一项挑战,甚至是不可行的。针对这一挑战,我们提出了一种小规模负采样方法来减少项目嵌入更新的数量,并提出了一种基于重要性的更新选择机制来仅存储重要的模型更新。为了评估 FRU 的有效性,我们提出了一种通过一组受损用户来干扰联邦推荐系统的攻击方法。然后,我们使用 FRU 通过消除这些用户的影响来恢复推荐系统。最后,我们利用两个广泛使用的联邦推荐系统在两个真实推荐数据集(即 MovieLens-100k 和 Steam-200k)上进行了广泛的实验,以证明我们提出的方法的效率和有效性。

算法1 FRU(联邦推荐反学习)。
2 Uncertainty Quantification for Fairness in Two-Stage Recommender Systems【两阶段推荐系统公平性的不确定性量化,康奈尔大学】
许多大型推荐系统由两个阶段组成。第一阶段有效地筛选整个项目池,以找出一小部分有希望的候选者,第二阶段模型从中挑选出最终的推荐。在本文中,我们研究如何确保这种两阶段架构中项目的群体公平性。特别是,我们发现现有的第一阶段推荐系统可能会选择一组不可挽回的不公平候选者,以至于第二阶段推荐系统没有希望提供公平的推荐。为此,受不确定性量化的最新进展的启发,我们提出了两个阈值策略选择规则,可以为第一阶段推荐系统的公平性提供无分布和有限样本保证。更具体地说,给定查询和项目的任何相关性模型以及每个阈值策略的相关项目预期数量的逐点下限置信度,这两个规则会找到接近最优的候选集,其中包含来自每组项目的预期足够多的相关项目。为了实例化规则,我们演示了如何从可能部分和有偏见的用户反馈数据中得出这种置信度界限,这些数据在许多大型推荐系统中都很丰富。此外,我们还提供了有限样本和渐近分析,以说明这两条阈值选择规则与最佳阈值的接近程度。除了理论分析之外,我们还通过实证研究证明,这两条规则可以始终如一地从每组中选择足够多的相关项目,同时在各种设置下最小化候选集的大小。

算法 1 公平的第一阶段阈值策略选择
3 DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation【DGRec:具有多种embedding生成的用于推荐的图神经网络,字节,伊利诺】
近年来,基于图神经网络 (GNN) 的推荐系统因其出色的准确性而受到越来越多的关注。GNN 模型将用户-项目交互表示为二分图,通过聚合邻居的嵌入来生成用户和项目表示。然而,这种聚合过程通常纯粹基于图结构积累信息,忽略了聚合邻居的冗余,导致推荐列表的多样性较差。在本文中,我们提出通过直接改进嵌入生成过程来实现基于 GNN 的推荐系统的多样化。具体来说,我们利用以下三个模块:子模块邻居选择为每个 GNN 节点找到一个多样化邻居子集进行聚合,层注意力为每一层分配注意力权重,以及损失重加权以专注于学习属于长尾类别的项目。将这三个模块融合到 GNN 中,我们提出了 DGRec(基于 GNN 的多样化推荐系统)以实现多样化推荐。在真实数据集上的实验表明,所提出的方法可以实现最佳多样性,同时保持与最先进的基于 GNN 的推荐系统相当的准确率。我们开源了 DGRec:
https://github.com/YangLiangwei/DGRec
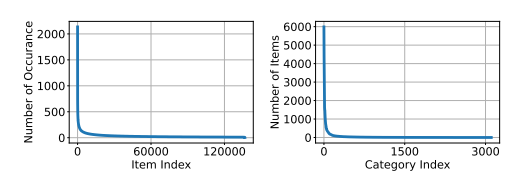
图 1:淘宝数据集上推荐系统的长尾分布
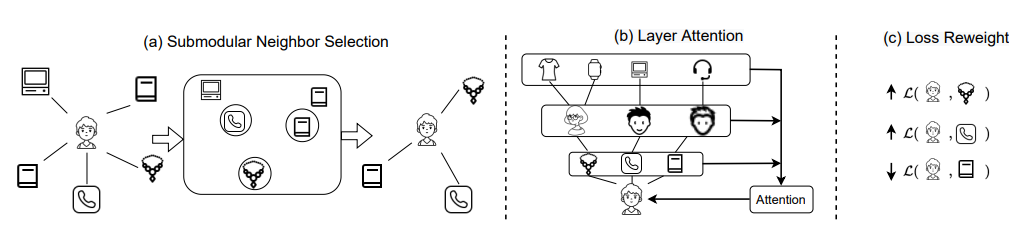
图 2:DGRec 的框架。(a) 子模块邻居选择模块(第 3.2 节)在嵌入空间上找到多样化的邻居子集进行聚合。(b) 层注意模块(第 3.3 节)缓解了高阶连接的过度平滑问题。© 损失重加权模块(第 3.4 节)调整每个样本的权重,以专注于长尾类别的训练。
4 Unbiased Knowledge Distillation for Recommendation【无偏知识蒸馏推荐系统,中科大】
作为一种有前途的模型压缩解决方案,知识蒸馏 (KD) 已应用于推荐系统 (RS) 以减少推理延迟。传统解决方案首先从训练数据中训练一个完整的教师模型,然后将其知识(即软标签)转移到监督紧凑学生模型的学习。然而,我们发现这种标准的蒸馏范式会引起严重的偏见问题——蒸馏后,热门商品会得到更强烈的推荐。这种影响会阻止学生模型做出准确和公平的推荐,从而降低 RS 的有效性。在这项工作中,我们确定了 KD 中偏见的根源——它源于来自教师的有偏见的软标签,并在蒸馏过程中进一步传播和强化。为了纠正这个问题,我们提出了一种具有分层蒸馏策略的新型 KD 方法。它首先根据商品的受欢迎程度将其分成多个组,然后提取每个组内的排名知识来监督学生的学习。我们的方法简单且与教师无关——它在蒸馏阶段工作,而不会影响教师模型的训练。我们进行了广泛的理论和实证研究,以验证我们提案的有效性。我们的代码发布在:
https://github.com/chengang95/UnKD
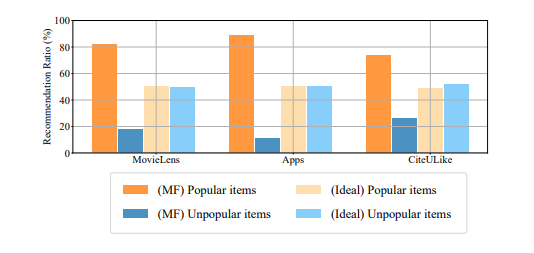
图 1:MF 模型中前 10 个推荐列表中热门/不热门商品的比例。我们还提供了测试数据中的理想比例以供比较。
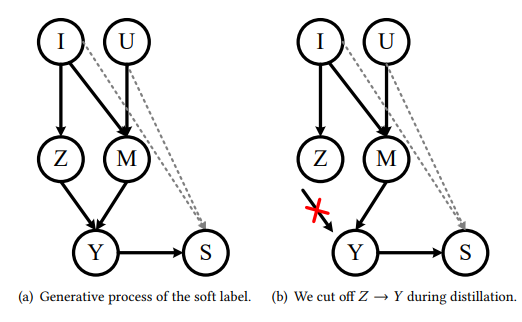
图 2:描述知识蒸馏的因果图。𝑈:用户,I:项目,亲和力得分,项目受欢迎程度,Y:软标签,𝑆:学生。偏差源于𝑍对𝑌的因果影响。我们的 UnKD 旨在切断𝑍 → 𝑌。诚然,从𝑈、𝐼到𝑆可能存在其他因果路径,但在这里我们只关注通过蒸馏(即通过𝑌)的因果影响。
5 VRKG4Rec-Virtual Relational Knowledge Graph for Recommendation【VRKG4Rec:用于推荐的虚拟关系知识图,华科】
将知识图谱作为辅助信息纳入推荐系统已成为新趋势。最近的研究将项目视为知识图谱的实体,并利用图神经网络来辅助项目编码,但会独立考虑每种关系类型。然而,关系类型往往太多,有时一种关系类型涉及的实体太少。我们认为知识图谱中的关系之间可能存在一些潜在的相关性。对于项目编码,考虑所有关系类型可能没有必要,也不会有效。在本文中,我们提出了一个 VRKG4Rec 模型用于推荐的虚拟关系知识图谱,该模型对具有潜在相关性的关系进行聚类以生成虚拟关系。具体而言,我们首先通过无监督学习方案构建虚拟关系图(VRKG)。我们还设计了一种用于 VRKG 上节点编码的局部加权平滑(LWS)机制,该机制仅根据节点本身及其邻居迭代更新节点嵌入,但不涉及任何额外的训练参数。LWS 机制也用于用户-项目二分图进行用户表征学习,利用具有虚拟关系知识的项目编码来帮助训练用户表征。在两个公共数据集上的实验结果验证了我们的 VRKG4Rec 模型优于最先进的方法。实现可在以下位置获得:
https://github.com/lulu0913/VRKG4Rec
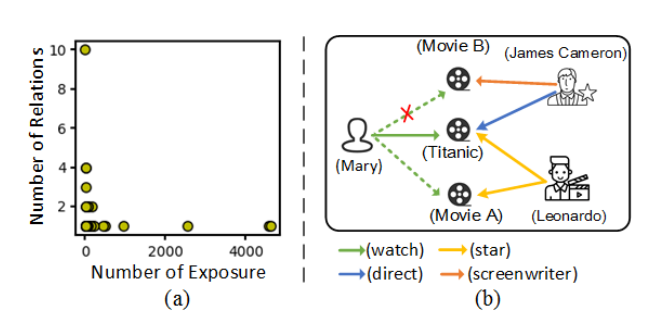
图 1:两种动机的说明。(a)Last.FM 数据集的长尾关系分布。(b)考虑不同关系相关性的必要性的说明示例
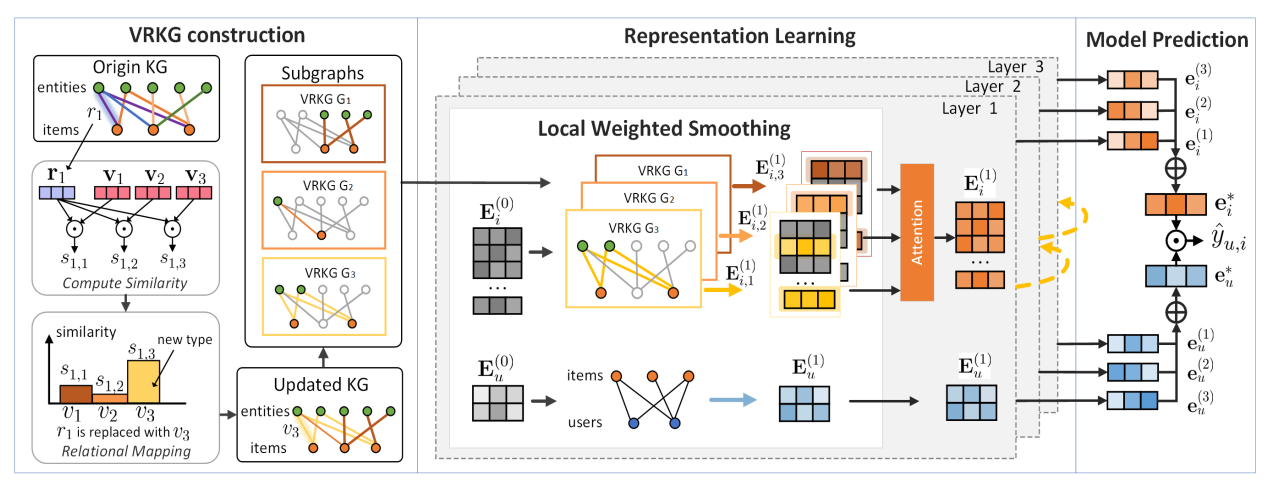
图 2:提出的 VRKG4Rec 模型概述
6 Knowledge-Adaptive Contrastive Learning for Recommendation【知识自适应对比学习推荐系统,阿里,北邮】
通过联合建模用户-商品交互和知识图谱 (KG) 信息,基于 KG 的推荐系统在缓解数据稀疏和冷启动问题方面显示出了优势。最近,图神经网络 (GNN) 因其强大的捕获高阶结构信息的能力而被广泛应用于基于 KG 的推荐系统。然而,我们认为现有的基于 GNN 的方法存在以下两个局限性。交互主导:用户-商品交互的监督信号将主导模型训练,因此 KG 的信息几乎没有被编码在学习到的商品表示中;知识过载:KG 包含大量与推荐无关的信息,这些噪音会在 GNN 的消息聚合过程中被放大。上述限制使得现有方法无法充分利用 KG 中的宝贵信息。在本文中,我们提出了一种名为知识自适应对比学习 (KACL) 的新算法来应对这些挑战。具体而言,我们首先分别从用户-商品交互视图和 KG 视图生成数据增强,并在两个视图之间进行对比学习。我们对对比损失的设计将迫使项目表示对两个视图共享的信息进行编码,从而缓解交互支配问题。此外,我们引入了两个可学习的视图生成器,以在数据增强过程中自适应地删除与任务无关的边缘,并帮助容忍知识过载带来的噪音。在三个公共基准上的实验结果表明,与最先进的方法相比,KACL 可以显著提高 top-K 推荐的性能。
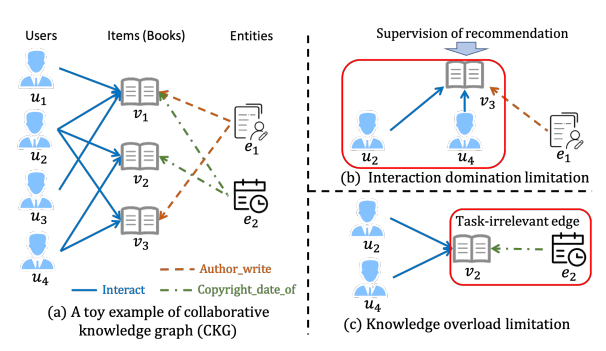
图 1:基于 KG 的推荐的最先进范式(即基于 CKG 建模的 GNN 方法)中的两个局限性的说明。
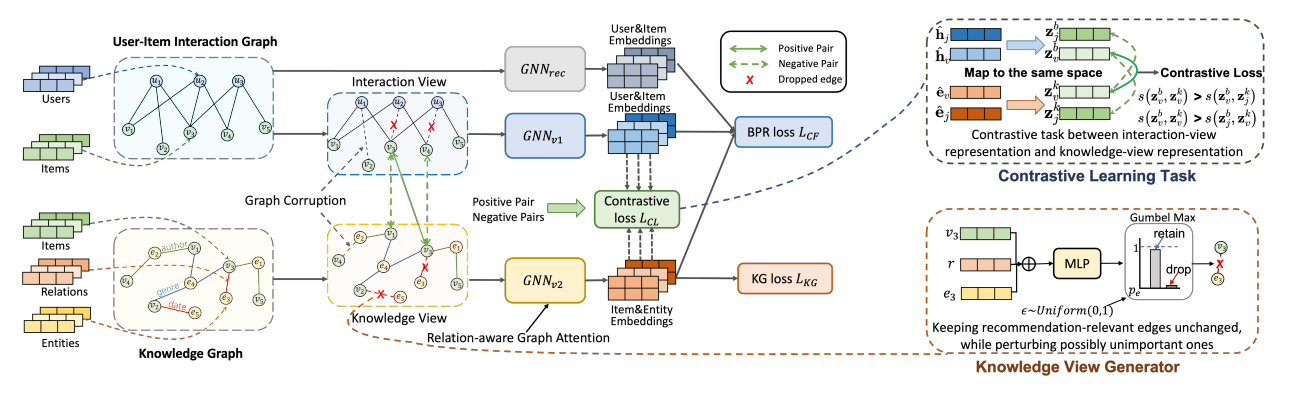
图 2:我们提出的知识自适应对比学习(KACL)的模型架构。
7 Heterogeneous Graph Contrastive Learning for Recommendation【面向推荐的异构图对比学习,华南理工】
图神经网络 (GNN) 已成为推荐系统中建模图结构数据的有力工具。然而,现实生活中的推荐场景通常涉及异构关系(例如,社交感知用户影响、知识感知项目依赖性),其中包含有用的信息以增强用户偏好学习。在本文中,我们研究了用于推荐的异构图增强关系学习问题。最近,对比自监督学习在推荐领域取得了成功。鉴于此,我们提出了一种异构图对比学习(HGCL),它能够将异构关系语义合并到用户-项目交互建模中,并通过对比学习增强跨不同视图的知识转移。然而,异构边信息对交互的影响可能因用户和项目而异。为了推动这个想法的发展,我们用元网络增强了我们的异构图对比学习,以允许具有自适应对比增强的个性化知识转换器。在三个真实数据集上的实验结果证明了 HGCL 优于最先进的推荐方法。通过消融研究,验证了 HGCL 方法中的关键组件,以有利于提高推荐性能。模型实现的源代码可在链接上找到:
https://github.com/HKUDS/HGCL
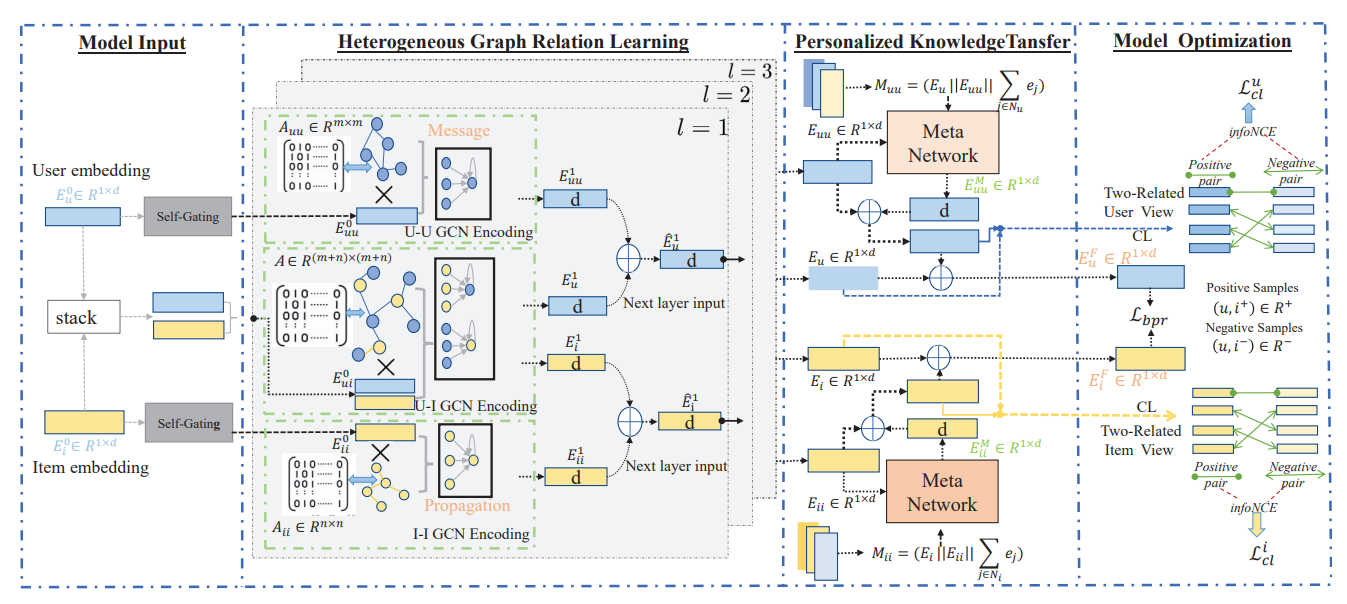
图 1:所提出的 HGCL 框架的模型流程。HGCL 包括三个关键组件:(1)通过异构图神经网络在用户-用户图、用户-项目图和项目-项目图上提取和融合异构图表示。(2)用于辅助视图和交互视图之间个性化跨视图依赖关系建模的元网络。(3)异构关系视图之间的联合参数优化与自适应对比学习。
8 An F-shape Click Model for Information Retrieval on Multi-block Mobile Pages【多块移动页面信息检索的F形点击模型,上交,华为】
大多数点击模型都关注用户对单个列表的行为。然而,随着用户界面(UI)设计的发展,结果页面上显示项目的布局趋向于多块样式而不是单个列表,这需要不同的假设才能更准确地建模用户行为。在桌面环境中存在针对多块页面的点击模型,但由于交互方式、结果类型以及特别是多块呈现样式的不同,它们不能直接应用于移动场景。具体来说,多块移动页面通常可以分解为基本垂直块和水平块的交错,从而产生典型的 F 形形式。为了弥合多块页面在桌面和移动环境中的差距,我们进行了用户眼动追踪研究,并识别了用户在 F 形页面上的顺序浏览、块跳过和比较模式。这些发现导致设计了一种新颖的 F 形点击模型(FSCM),作为多块移动页面的通用解决方案。首先,我们为每个页面构建一个有向无环图 (DAG),其中每个项目被视为一个顶点,每条边表示用户可能的检查流程。其次,我们提出 DAG 结构的 GRU 和比较模块,分别对用户的顺序(顺序浏览、块跳过)和非顺序(比较)行为进行建模。最后,我们结合 GRU 状态和比较模式来执行用户点击预测。实验表明,FSCM 优于基线模型。
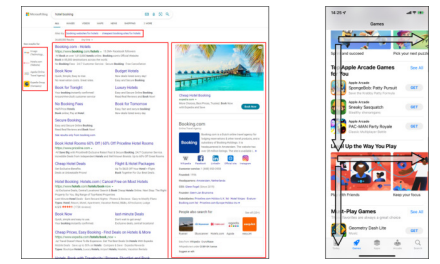
图 1:桌面(左)和移动(右)环境下的多块页面。左:Bing 搜索的结果页面,其中每个块都用红色框表示。右:App Store 的结果页面,可分解为基本的垂直和水平块,从而形成 F 形。
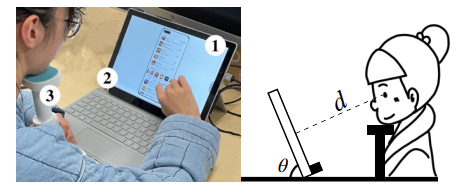
图 2:左图:眼动追踪实验装置,描绘了 (1) 显示伪移动 UI 的屏幕、(2) 眼动追踪器和 (3) 用于限制头部运动的下巴托。右图:说明我们的设置如何在移动场景中保持自然的观看距离和视角。
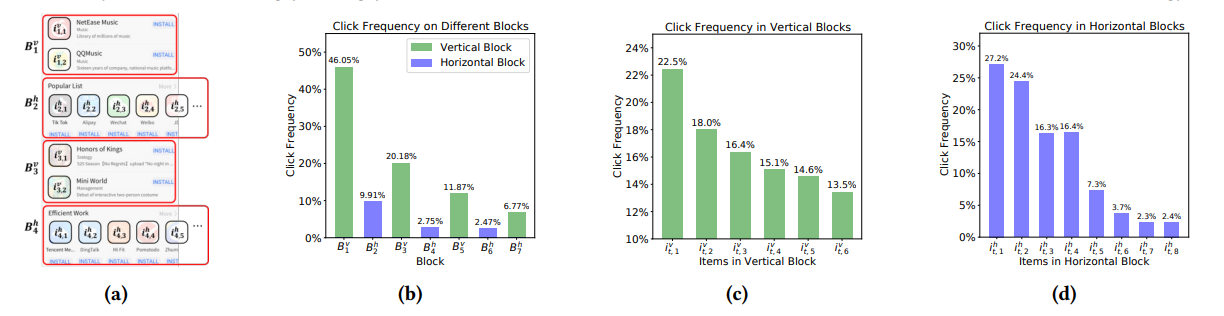
图 3:(a) F 形页面的分解。由于页面限制,我们缩短了垂直块的长度。(b) 不同块上的点击频率。© 垂直块中项目的点击频率。(d) 水平块中项目的点击频率。
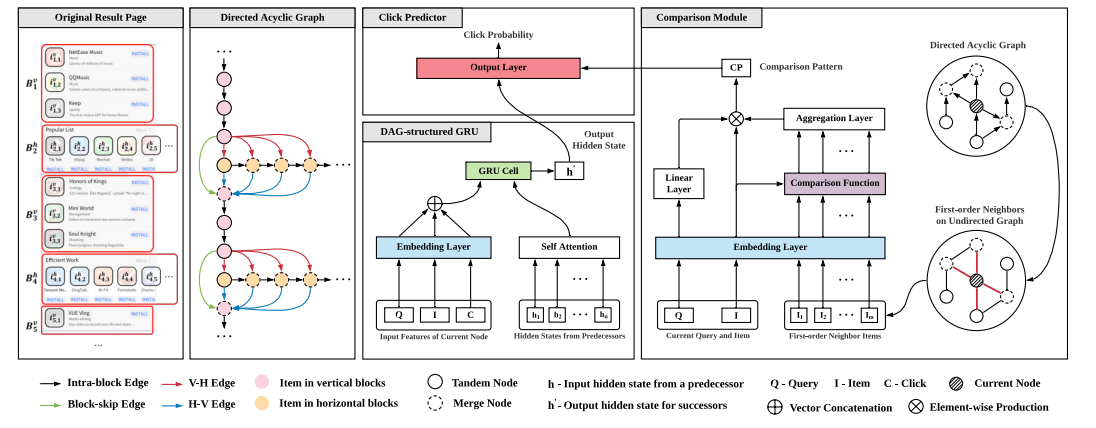
图4:FSCM的框架。
9 Separating Examination and Trust Bias from Click Predictions for Unbiased Relevance Ranking【从点击预测中分离检查和信任偏差,进行无偏关联排序,人大,华为】
减轻排名系统中的检查和信任偏差是无偏排名学习 (ULTR) 中的一个重要研究方向。当前的方法通常使用倾向来纠正有偏见的用户点击,然后根据纠正后的点击学习排名模型。虽然已经取得了成功,但直接修改点击会受到固有的高方差的影响,因为倾向通常涉及纠正点击的分母。在混合检查和信任偏差的情况下,问题会变得更加严重。为了解决这个问题,本文提出了一种称为分解排名去偏 (DRD) 的新型 ULTR 方法。DRD 专门用于在存在检查和信任偏差的情况下学习具有低方差的无偏相关性模型。与直接修改原始用户点击的现有方法不同,DRD 建议将每个点击预测分解为排名模型输出的相关性项和其他偏见项的组合。因此,可以通过将整体点击预测拟合到有偏见的用户点击来学习无偏相关性模型。开发了一种联合学习算法来交替学习相关性和偏差模型的参数。理论分析表明,与现有方法相比,DRD 具有更低的方差,同时保持了无偏性。实证研究表明,DRD 可以有效降低方差并超越最先进的 ULTR 基线。
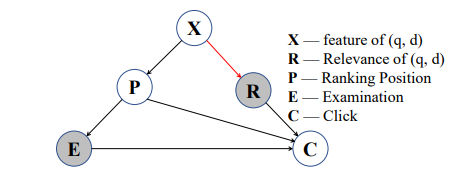
图 1:用户点击在搜索排名中的因果图。灰色节点表示未观察到的变量。红色箭头表示无偏相关性模型需要估计的效应。

算法 1:DRD 的联合学习算法。
10 CL4CTR: A Contrastive Learning Framework for CTR Prediction【CL4CTR:CTR预测的对比学习框架,复旦,微软】
许多点击率 (CTR) 预估工作侧重于设计先进的架构来模拟复杂的特征交互,但忽略了特征表示学习的重要性,例如,对每个特征采用一个简单的嵌入层,这会导致特征表示不尽优,从而导致 CTR 预测性能较差。例如,在许多 CTR 任务中占大多数特征的低频特征在标准监督学习设置中较少得到考虑,导致特征表示不尽优。在本文中,我们引入自监督学习来直接生成高质量的特征表示,并提出了一个与模型无关的 CTR 对比学习 (CL4CTR) 框架,该框架由三个自监督学习信号组成,以规范特征表示学习:对比损失、特征对齐和场均匀性。对比模块首先通过数据增强构建正特征对,然后通过对比损失最小化每个正特征对的表示之间的距离。特征对齐约束强制同一领域的特征表示接近,而领域均匀性约束强制不同领域的特征表示远离。大量实验验证了CL4CTR在四个数据集上取得了最优性能,并且具有良好的有效性和与各种代表性基线的兼容性。
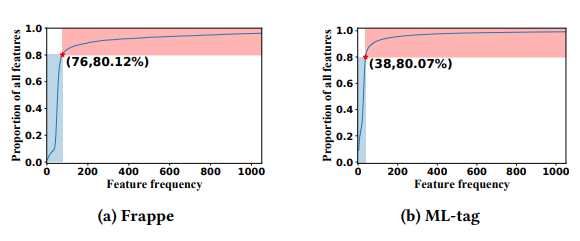
图1:特征频率的累积分布,(38,80.07%)表示特征频率小于或等于38次的特征占所有特征的80.07%。
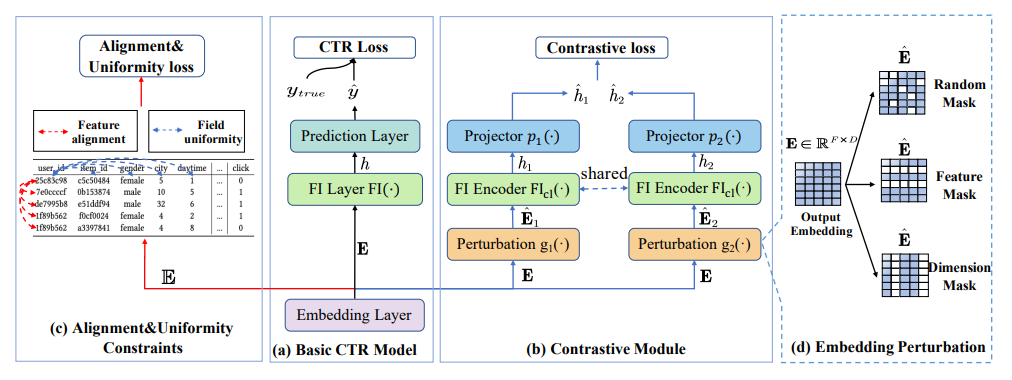
图 2:CL4CTR 框架的架构。CL4CTR 包括三个组件:(a)基本 CTR 模型;(b)对比模块;(c)对齐和均匀性约束。在对比模块中,我们设计了(d)三种嵌入扰动方法。
11 Directed Acyclic Graph Factorization Machines for CTR Prediction via Knowledge Distillation【基于知识提取的CTR预测的有向非循环图分解机,人大,腾讯】
随着网络规模推荐系统中高维稀疏数据的增长,在 CTR 预测任务中学习高阶特征交互的计算成本大幅增加,这限制了高阶交互模型在实际工业应用中的使用。一些最近基于知识蒸馏的方法将知识从复杂的教师模型转移到浅层学生模型,以加速在线模型推理。然而,它们在知识蒸馏过程中遭受模型准确性的下降。平衡浅层学生模型的效率和有效性是一项挑战。为了解决这个问题,我们提出了一种有向无环图分解机 (KD-DAGFM),通过知识蒸馏从现有的复杂交互模型中学习高阶特征交互,以进行 CTR 预测。所提出的轻量级学生模型 DAGFM 可以从教师网络中学习任意显式特征交互,这实现了几乎无损的性能,并通过动态规划算法得到了证明。此外,改进的通用模型 KD-DAGFM+ 被证明可以有效地从任何复杂的教师模型中提取显式和隐式特征交互。在包括微信平台数十亿特征维度的大规模工业数据集在内的四个真实数据集上进行了大量的实验,KD-DAGFM 在线和离线实验中均取得了最佳性能,FLOPs 低于当前最佳方法的 21.5%,展现了 DAGFM 在 CTR 预估任务中处理工业规模数据的优势。
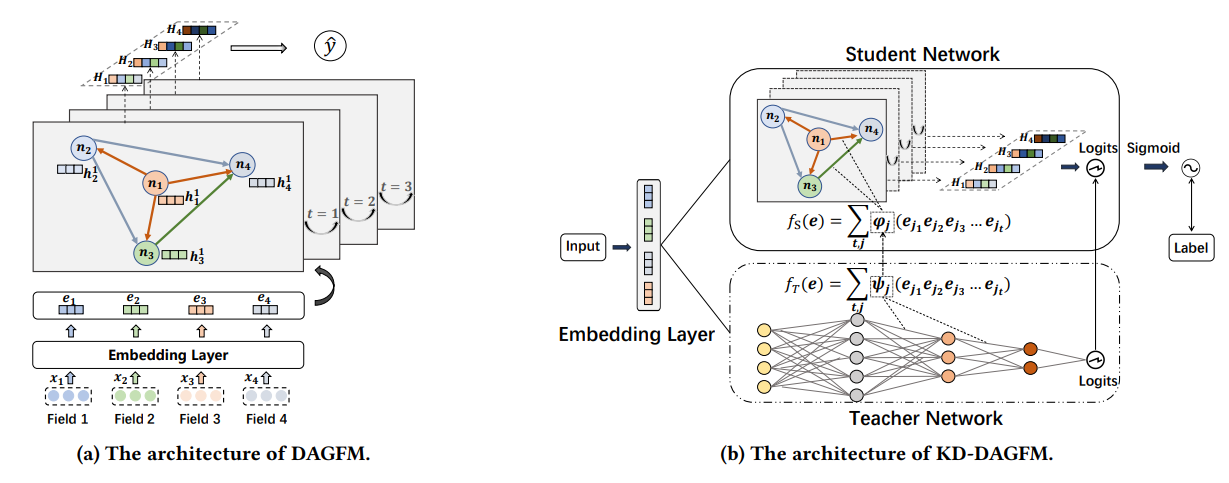
图 1:我们提出的 KD-DAGFM 的组件和架构。
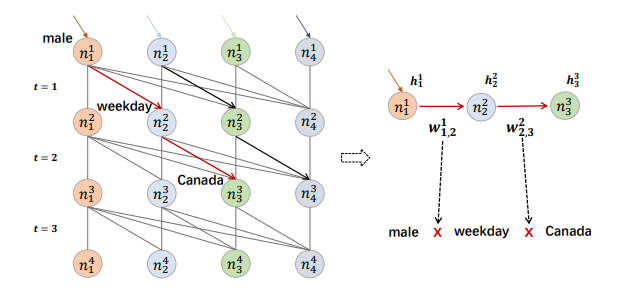
图 2:DAGFM 的传播图。每个 𝑘 阶特征交互都对应于动态规划算法中长度为 𝑘 − 1 的唯一路径。



















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











