









Convolutional Neural Networks 卷积神经网络(CNN, convnets)
图像分类:计算机视觉的核心任务
难题:
-
语义鸿沟(我们赋予图像的标签与计算机实际看到的像素值之间有着巨大的差距)
-
视角变换
-
光线问题
-
形变illumination
-
遮挡occlusion

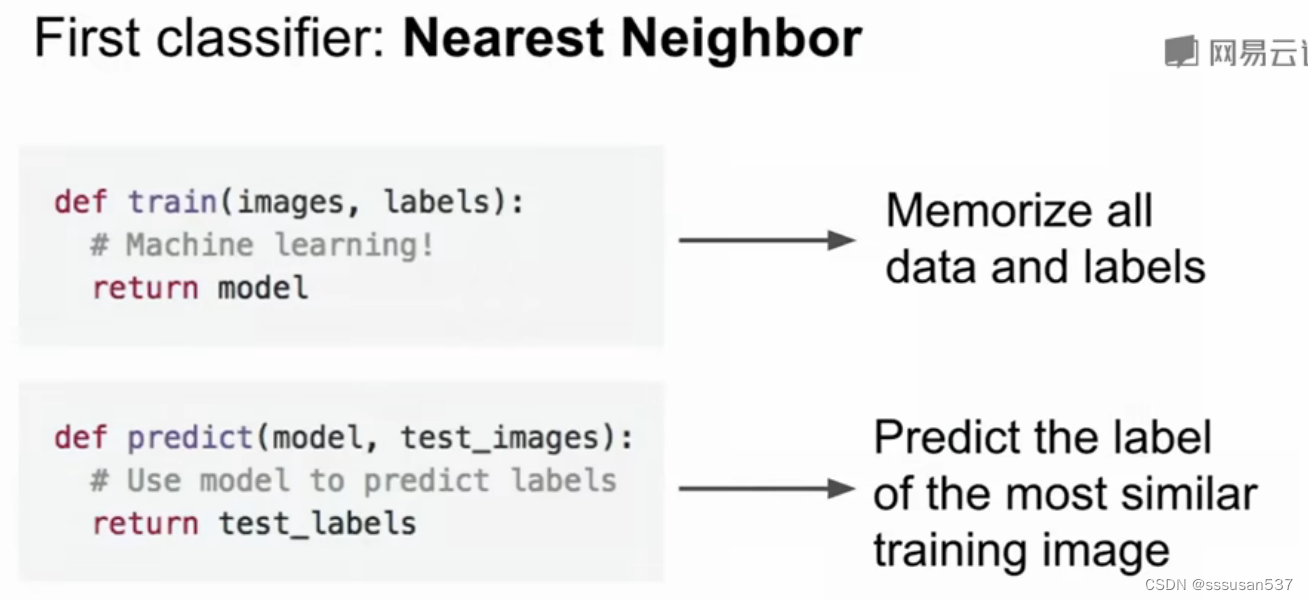
最近邻分类器
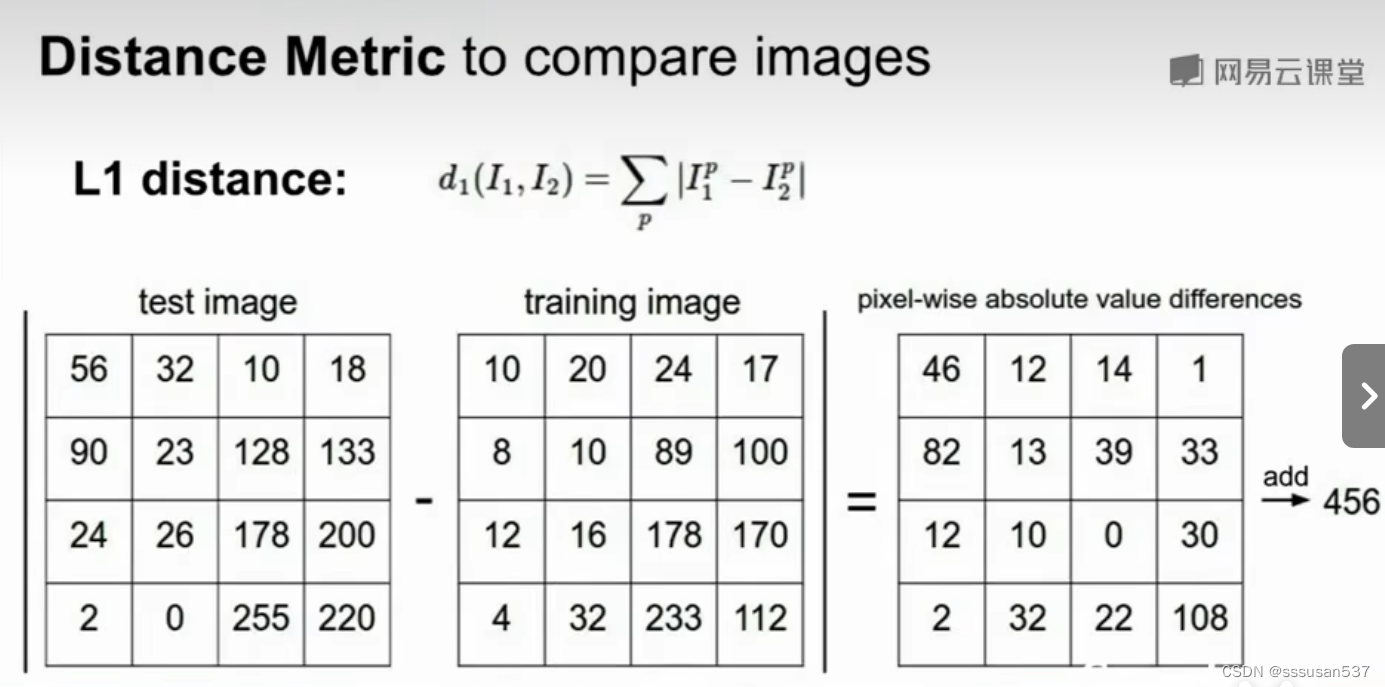
L1距离(曼哈顿距离):
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N"""
# the nearest neighbor classifier simply remembers all the training date
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for"""
num_text = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_text, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
train方法用于训练分类器。它接受两个参数:X是一个N x D的数组,其中每行代表一个训练样本,y是一个长度为N的一维数组,包含每个样本的类别标签。在方法内部,它简单地将训练数据X和类别标签y存储在类的实例变量self.Xtr和self.ytr中,以便在测试阶段使用。
predict方法用于对新的输入数据进行分类。它接受一个N x D的数组X,其中每行代表一个待预测的样本。在方法内部,首先确定输入数据的数量,并创建一个与输入数据数量相同的零数组Ypred,该数组将用于存储预测的类别标签。
然后,代码使用np.argmin找到距离数组distances中最小距离对应的索引,即找到了最近的训练样本。最后,将该最近训练样本的类别标签self.ytr[min_index]赋值给Ypred[i],完成对当前测试样本的分类预测。
这种算法时间复杂度:
Train O(1) => Predict O(n)
训练时是一个恒定的时间,但测试一个图像就需要与数据集中n个训练实例进行比较
卷积神经网络则相反,训练时间长,测试时间短
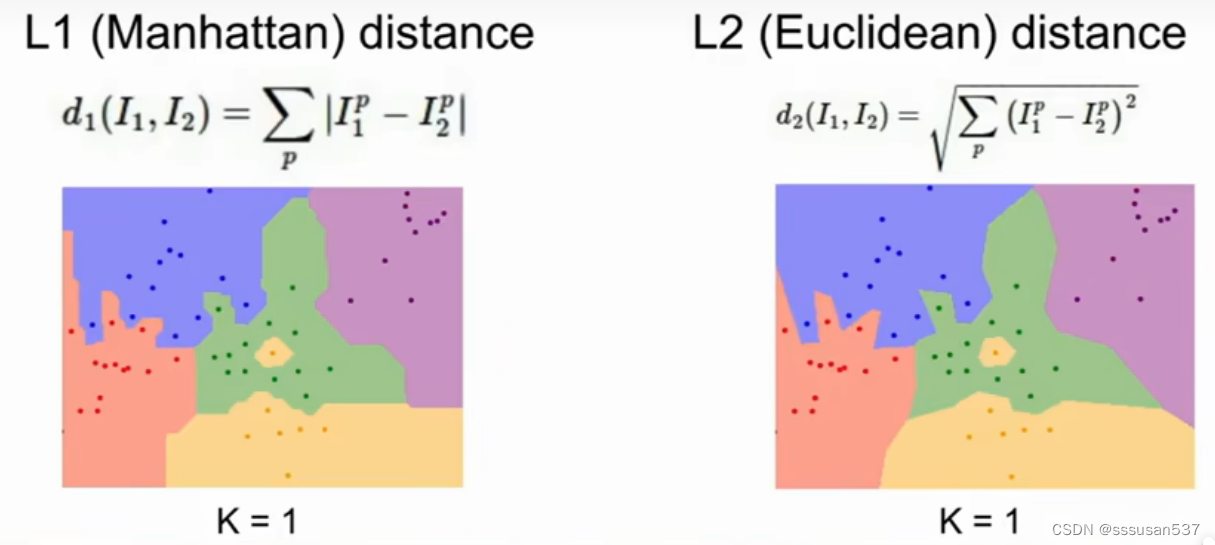
最近邻算法表示图:
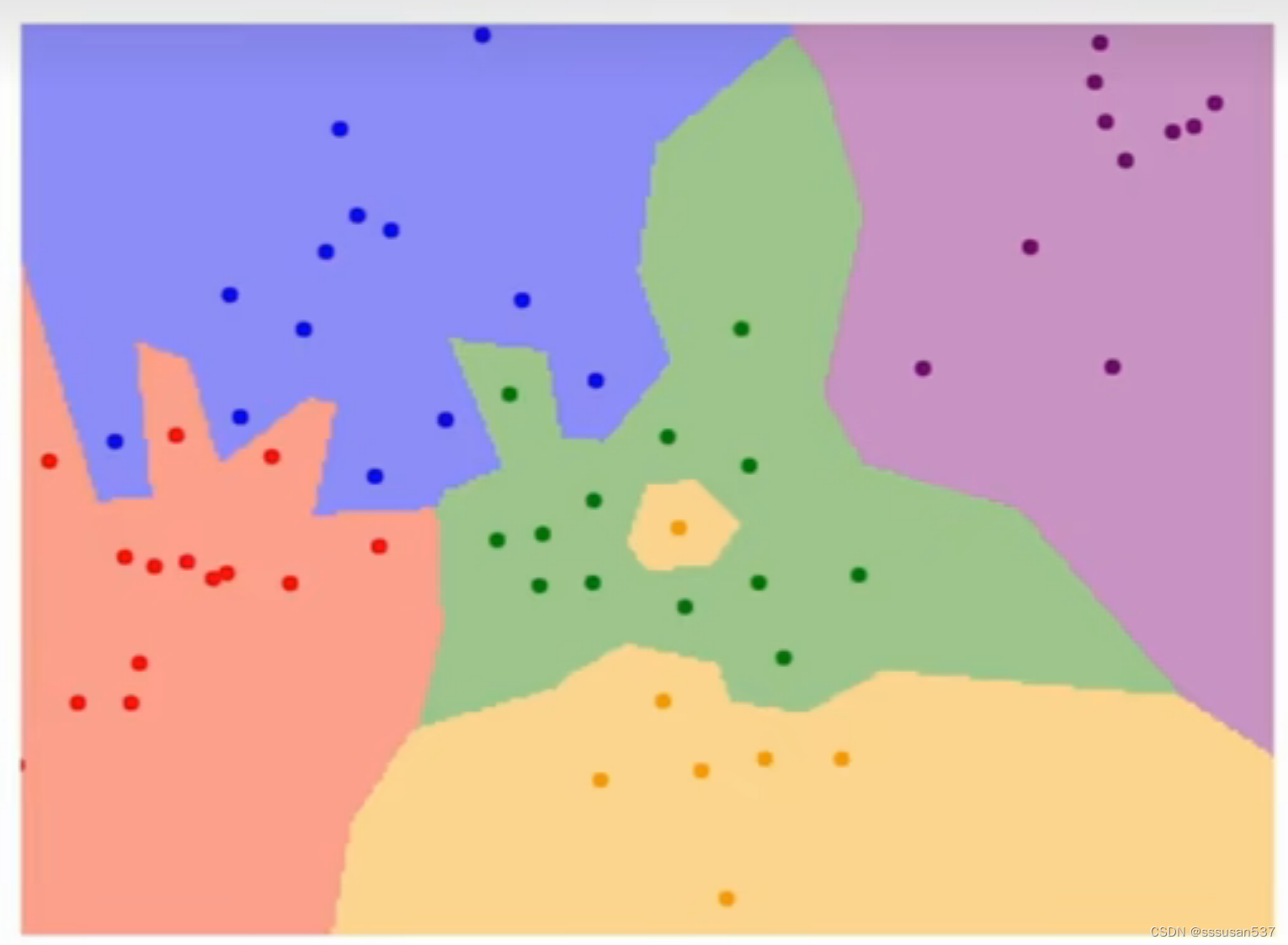
点代表测试点,区域代表标签
缺点:噪音干扰,在绿色区域的中间却出现了黄色区域
例子:一维的例子,120cm一下的一般是孩子(8岁以下),150cm以上成人(18以上)如果是nn算法,给一个身高110的数据,一般是分成孩子类,但是数据集就有个噪音,有个残疾人双腿截肢了一截,身高恰好110,然后110cm想要分类的数据就会被到截肢的这个人一个类,小孩就被分成成人了
K最近邻算法(K-Nearest Neighbors,KNN)
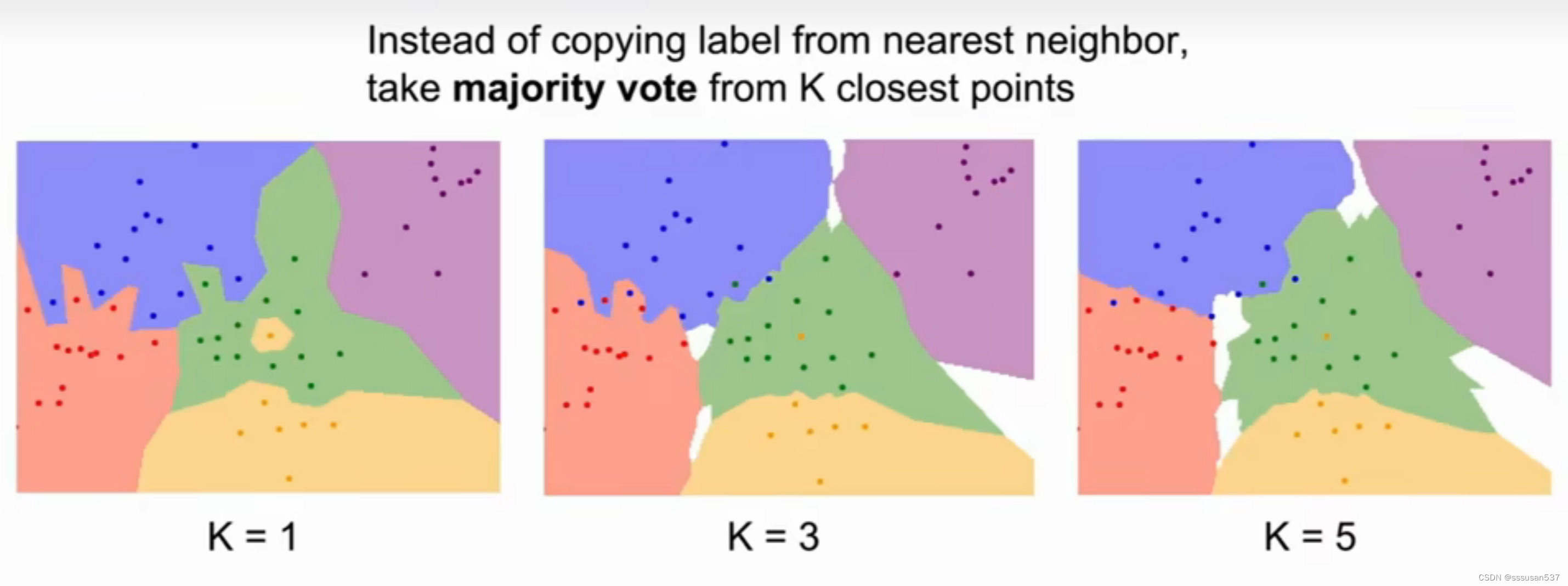
白色区域代表没有获得K最近邻的投票,可以大胆将它归为随机周围的类
L2距离(欧式距离)
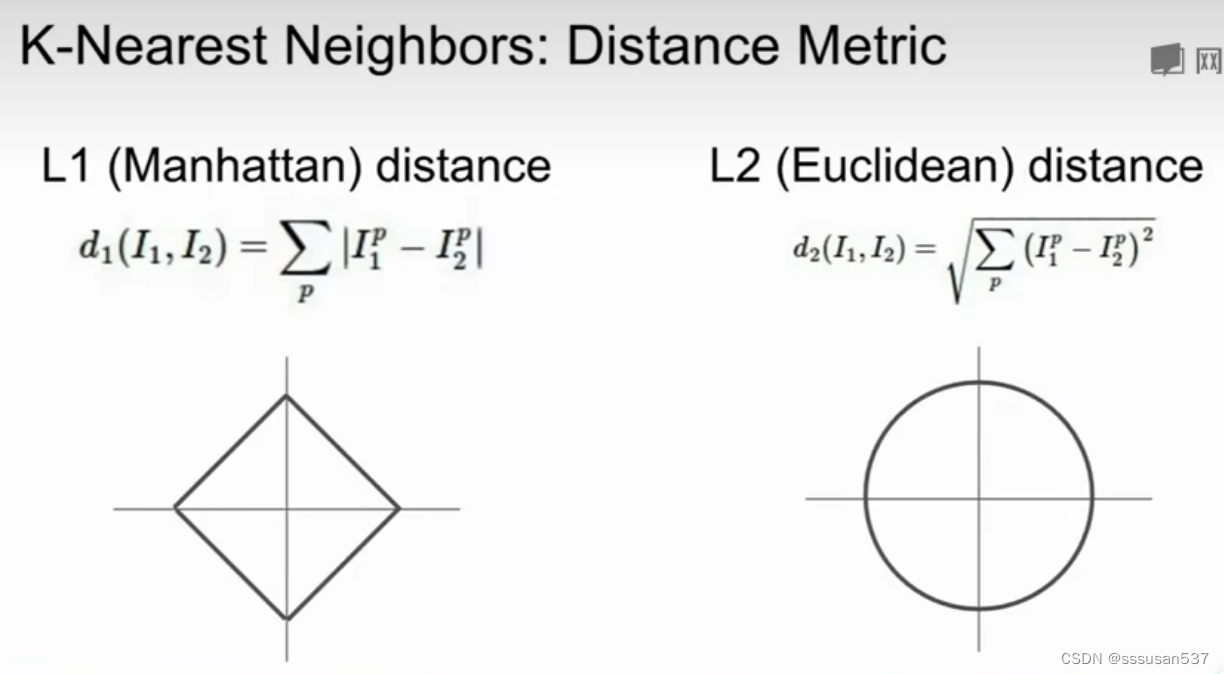
坐标轴改变时,L1距离会改变,L2距离不会改变
当输入特征向量的某些个值含有特殊含义的时候,L1更合适;当是通用向量时,L2更合适
超参数(Hyperparameters):如K值、距离度量(distance metric)
不能直接从数据训练集中获得,需要人为提前设置的参数

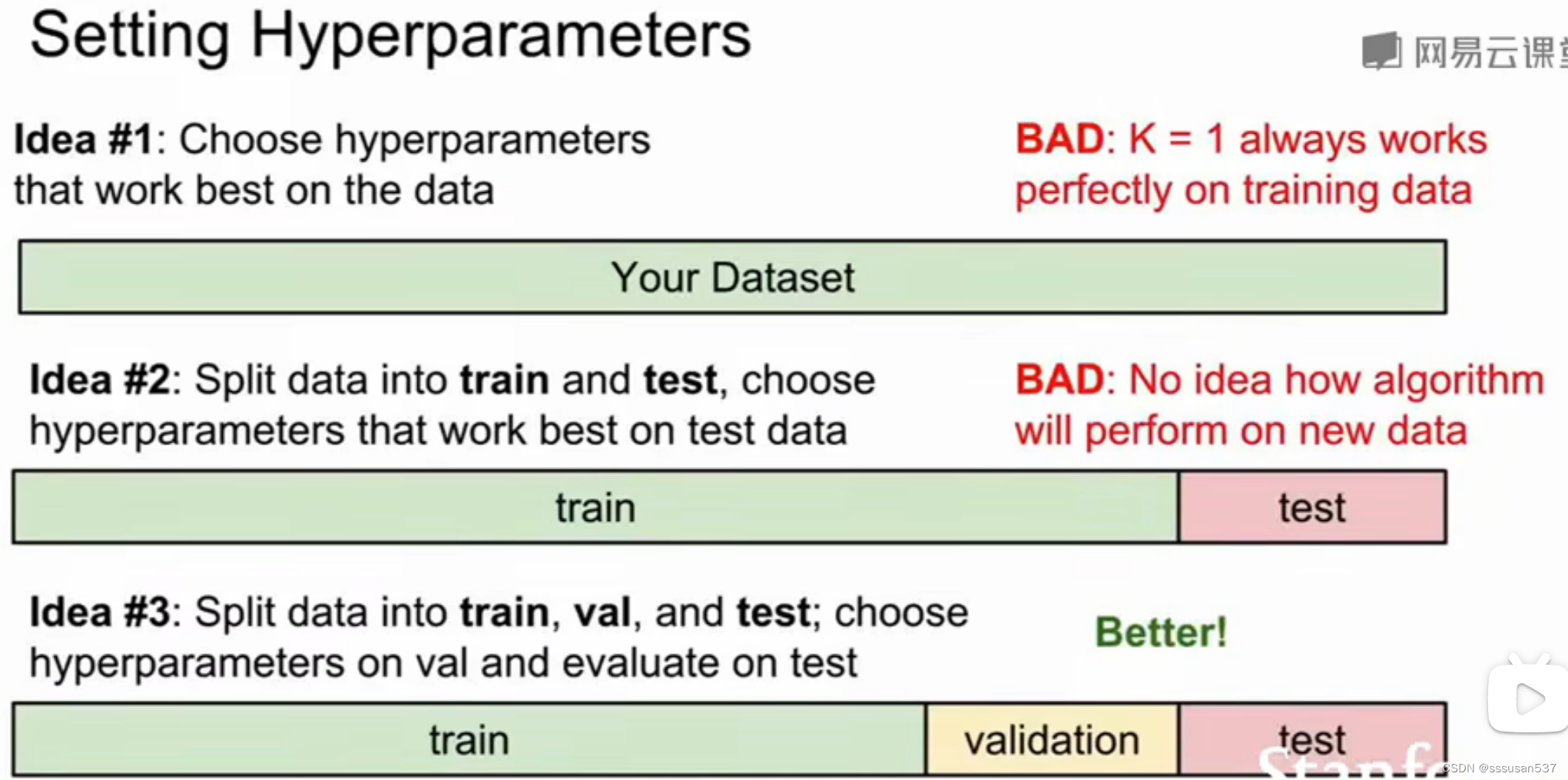
获得最优超参数:将数据分为训练集、验证集、测试集(将现有数据集随机划分为训练集、验证集和测试集,即验证集和测试集也都是使用现有的有标签的数据,但算法并不知道标签),在训练集上用不同超参来训练算法,在验证集上进行评估,最后再把表现最好的一组超参在测试集上运行一次
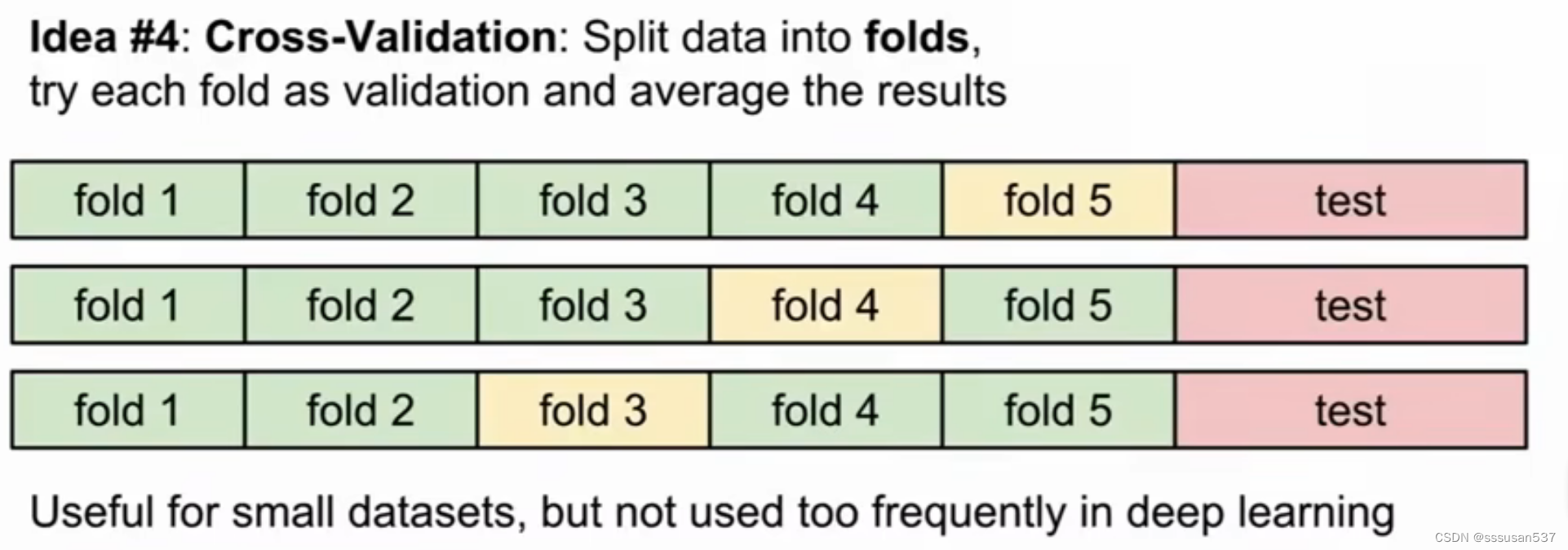
交叉算法:更多在小数据集上使用,因为在大数据集上训练本身就很消耗计算能力
K折交叉验证(k次在不同测试集上的方差)
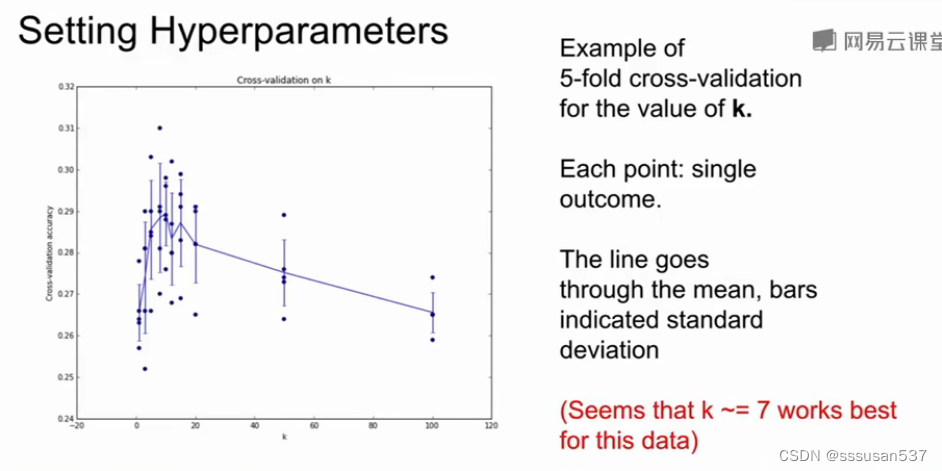
KNN也不是很好的算法:

- L2距离不能很好地测量图片的相似性:尽管这四幅图片是不同的,但都拥有相同的L2距离

- 维度灾难:如果要使分类器有更好的效果,需要训练数据能密集地分布在空间中(减少空白区域),需要指数倍增加的训练数据量
线性分类
线性分类是在不同类型的深度学习应用中最基本的构建块之一
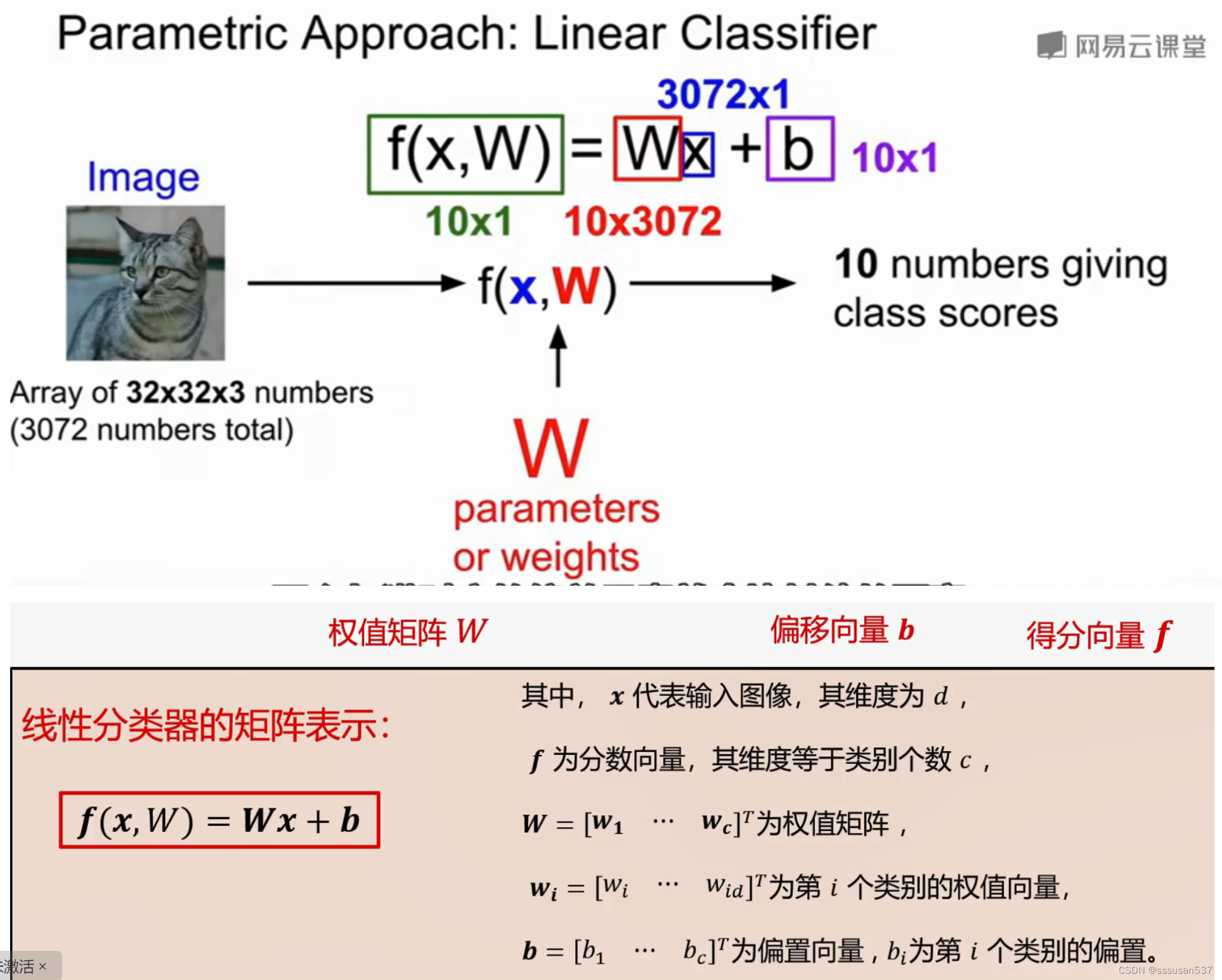
偏移值b:例如在猫多于狗的训练集中,猫的偏移值b要更大一些
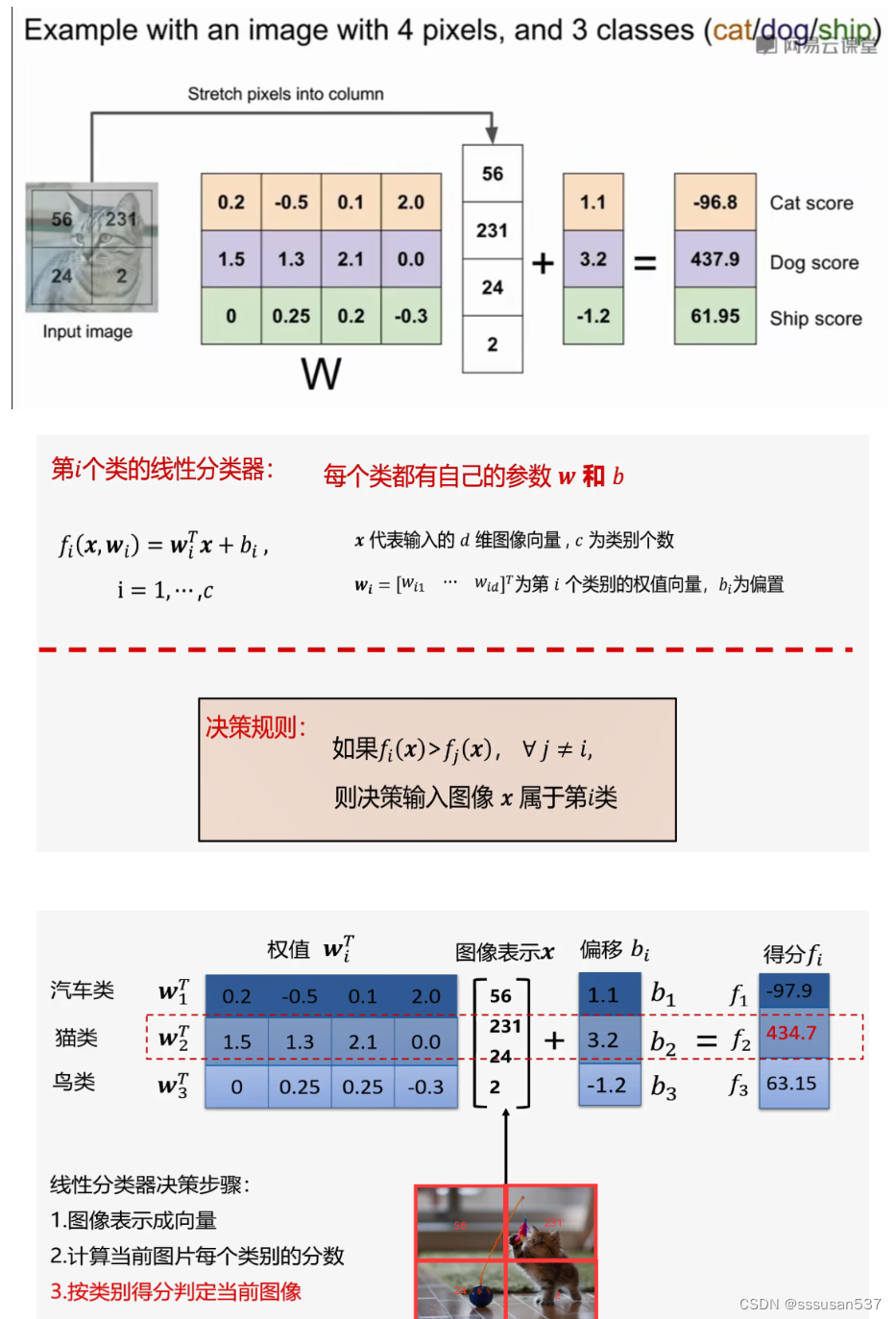
矩阵乘法

图片的下方是线性分类器系数矩阵(权重矩阵)的可视化结果,每一个类别只有一个线性分析器,即只有一个单独的模板
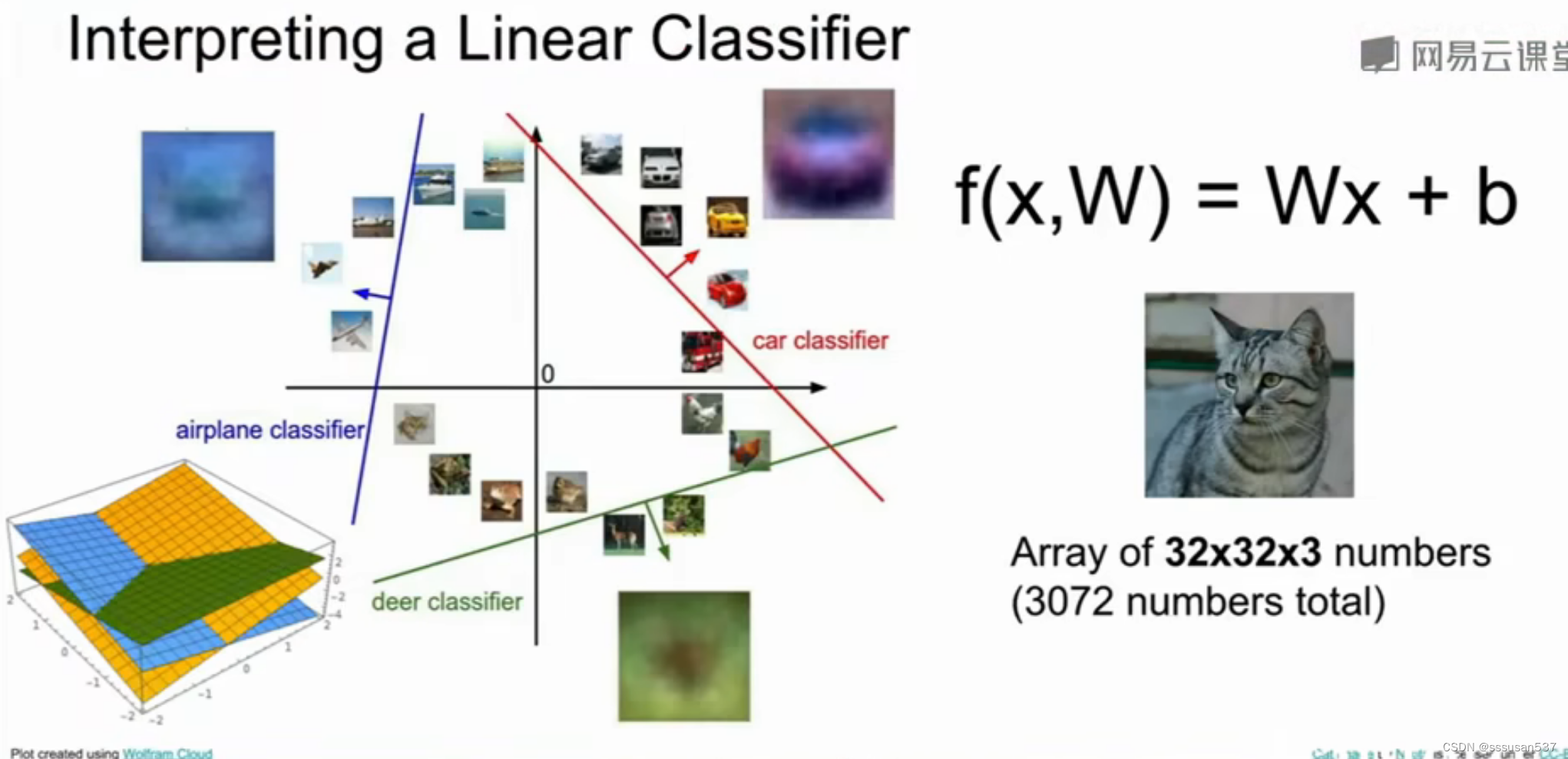
图像在象限中的划分:二维坐标系中(1,1)是一个点,三维坐标系中(1,1,1)则是一个点,以此类推,PPT上猫的图片则是在3072维坐标系上的一个点,然后找到合适的划分线即可
线性模型无法解决异或问题,直观上表示为无法找到一条直线分割异或点:
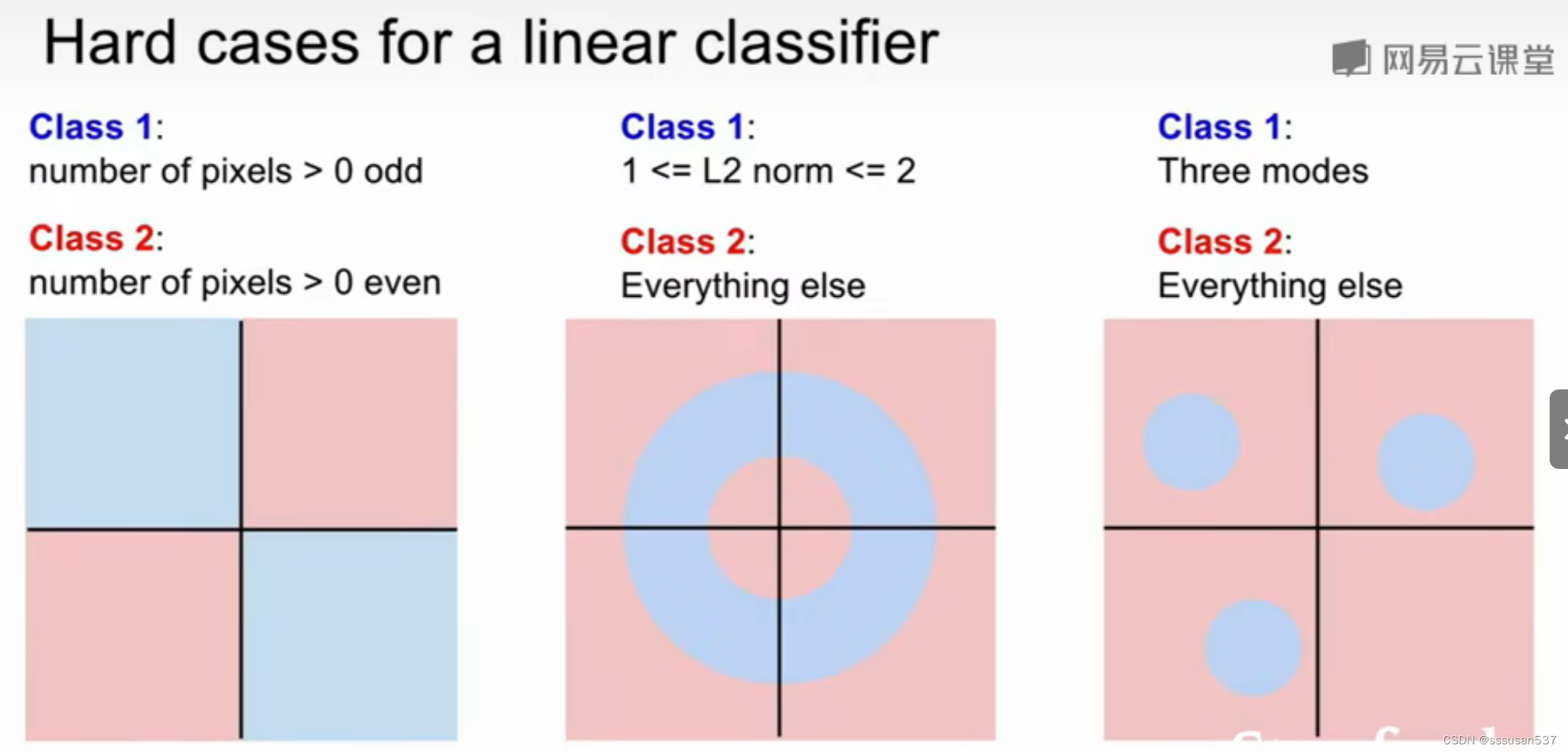















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









