







DiffCR: A Fast Conditional Diffusion Framework for Cloud Removal from Optical Satellite Images
Abstract
光学卫星图像是一个重要的数据来源。然而,云层往往会影响图像的质量,阻碍图像的应用和分析。因此,从光学卫星图像中有效去除云已成为一个突出的研究方向。虽然云移除的最新进展主要依赖于生成对抗网络,这可能会产生次优的图像质量,但扩散模型已经在各种图像生成任务中取得了显着的成功,展示了它们在解决这一挑战方面的潜力。本文提出了一个名为DiffCR的新框架,该框架利用条件引导扩散和深度卷积网络对光学卫星图像进行高性能的云去除。具体来说,我们为条件图像特征提取引入了解耦编码器,提供了鲁棒的颜色表示,以确保条件输入和合成输出之间的外观信息非常相似。此外,我们在云去除模型中提出了一种新颖高效的时间和条件融合块,以较低的计算成本准确模拟条件图像中外观与目标图像之间的对应关系。对两种常用基准数据集的广泛实验评估表明,DiffCR在所有指标上都能达到最先进的性能,参数和计算复杂性分别仅为之前最佳方法的5.1%和5.4%。
1 Introduction
近年来,随着遥感技术的飞速发展,卫星图像特别是光学卫星图像在农业监测、地面目标探测、土地覆盖分类等领域得到了广泛的应用。然而,在成像过程中,云的干扰是一个重大的挑战。根据国际卫星云气候学项目(ISCCP)的数据,全球平均云层覆盖率达到了惊人的66%。通过分析Terra和Aqua卫星上的中分辨率成像光谱仪(MODIS) 12年的观测数据,发现地球表面平均有67%被云覆盖。厚云的不透明性阻碍了底层目标信息,大大降低了它们的效用和有效性,严重阻碍了卫星图像的进一步分析和应用。因此,开发一种有效的去除光学遥感图像中的云的方法已成为一个必要而紧迫的研究问题,因为一种成功的去云算法将显著增强数据的可用性,提高依赖光学卫星图像的下游任务的精度。
随着深度学习技术的发展,生成对抗网络(GANs)已成为图像处理领域的一个重要研究方向。基于gan的方法可以学习数据分布并生成高质量的样本,在图像超分辨率、图像修复和风格转移等任务中找到了成功的应用。在云移除的背景下,基于GAN的方法也得到了广泛的应用,并取得了可喜的成果。具体来说,它们由两个关键组件组成:
- 生成器负责从被云污染的图像中生成无云的表面图像
- 鉴别器负责确定生成图像的真实性
生成器和鉴别器通过迭代训练逐渐提高性能,生成更加真实清晰的表面图像。
尽管基于GAN的方法在去云方面表现出色,但仍然存在一些挑战。例如,它们天生难以训练,并且可能遭受模式崩溃等问题,导致扭曲或重复生成图像。此外,云的形态和分布表现出多样性和复杂性,对基于GAN的方法的训练和应用提出了复杂的要求。因此,设计更加稳健和高效的深度生成模型仍然是云移除研究的关键。
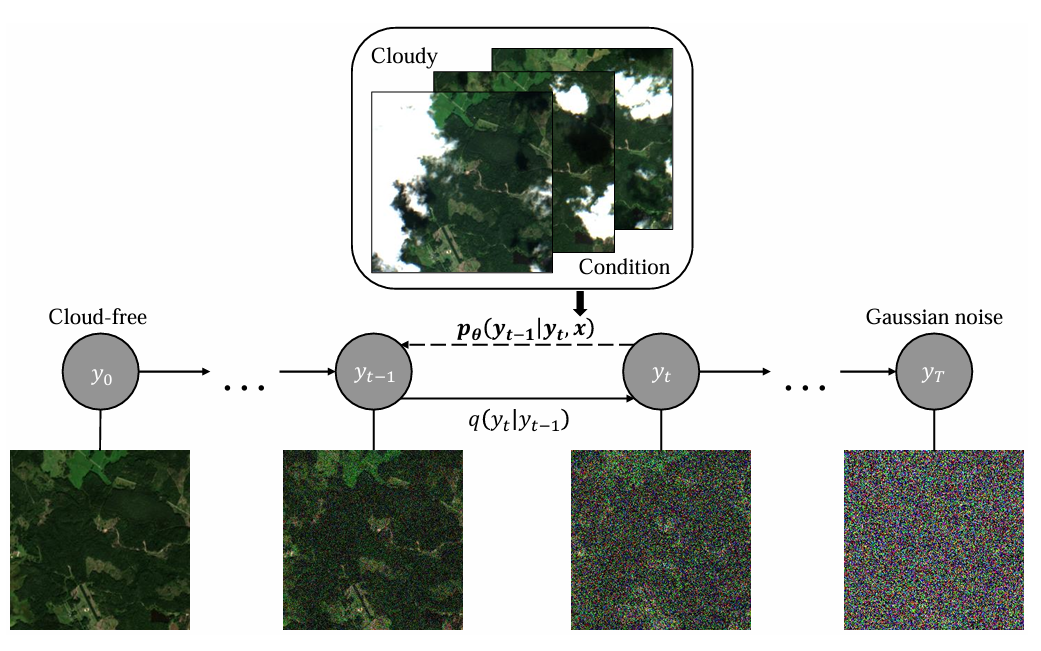
图1 提出的去云框架DiffCR的整体管道。(1)训练:这个阶段包括正向过程(从左到右)和反向过程(从右到左)。前向过程又称为扩散过程,通过中间过渡分布,加入高斯噪声,逐步扰动地面真值,控制参数化神经网络
的训练。反向过程,也称为去噪过程,将噪声图像
作为
的输入,并迭代地细化
。另外,将多云图像
和噪声等级
有条件地注入到
中,以指导无云图像的生成。(2)推断:该阶段将高斯噪声
、有云图像
和步骤
作为预训练
的输入,迭代重建无云图像
。
为了在保持高图像保真度的同时实现云去除,我们建议探索扩散模型在光学卫星图像中云去除的适用性。基于扩散的方法通过添加噪声的扩散过程来构建数据标签。迭代细化过程通过逆去噪来产生更精细的样本。通过这种方式,我们提出的去云框架DiffCR(见图1)并不是一次性对复杂的无云特征进行建模,而是将问题分解为一系列向前向后的扩散步骤,以学习合理的无云细节。此外,为了进一步提高真实感和图像质量,我们设计了一种新的条件去噪模型,该模型由三个部分组成:
- 条件编码器-用于学习条件图像的特征,提供鲁棒的颜色表示,以确保条件输入和合成输出之间的外观信息非常相似。
- 时间编码器-将反映噪声电平的时间t转换为隐式时间嵌入。
- 去噪自编码器-从有噪声的无云图像中提取特征,并将其与条件嵌入和时间嵌入融合,生成高保真的无云图像。
随后,我们进一步在条件去噪模型中提出了一种高效且新颖的时间和条件融合块(TCFBlock),该模型将噪声图像的空间相关性、多尺度条件嵌入和隐式时间嵌入显式集成到扩散框架中。通过上述优化和创新,DiffCR只需一步就能生成高质量的样本,并在3到5步内完成收敛。
综上所述,我们的工作贡献可以总结如下:
- 我们提出了一种新的、快速的条件扩散框架DiffCR,用于从光学卫星图像中去除云。该框架解耦了条件信息的处理,使得在一个采样步骤中生成高保真图像成为可能。
- 设计了一种新的条件去噪模型,该模型由条件编码器、时间编码器和去噪自编码器三部分组成。该模型保证了输入图像与合成输出图像在外观信息上的高度相似,可以有效提高图像的真实感和质量。
- 提出了一种高效、新颖的时间与条件融合块(TCFBlock)作为条件去噪模型的基本单元,可以显式集成噪声图像的多尺度特征、多尺度条件嵌入和隐式时间嵌入。
通过将DiffCR与各种竞争性GAN、回归和基于扩散的方法在两个常用基准数据集上进行比较,我们证明了DiffCR的经验有效性,这些数据集显示了SOTA结果。此外,我们进行了广泛的消融实验(见表5),以研究各种结构设计对去噪自编码器的影响。我们相信我们的工作将有助于高效的实时云移除研究,即使在有限的计算资源下也能实现高保真度和鲁棒性,并为在其他计算机视觉领域和生成式人工智能(如文本到图像和图像到图像合成)中应用条件扩散模型提供有价值的见解。
2 相关工作
2.1 去云任务
去云是一个重要且具有挑战性的研究领域。由于天气条件的影响,云层往往会对光学卫星成像造成阻碍,使得一些地理特征无法显现,阻碍了遥感图像在下游任务中的应用。去云旨在恢复被遮挡的地理信息,释放遥感影像的充分利用潜力。
根据输入的数据,云去除方法可以分为单时相和多时相两种。由于技术限制,早期基于光学卫星图像的去云方法主要集中在单时相方法,旨在从特定地理位置的单幅被云污染的图像中去云并恢复地物。然而,当云覆盖范围很广时,从单帧图像中获得无云图像是一个重大挑战,因为没有足够的信息来促进图像重建。
随着遥感技术的进步,卫星可以以更短的间隔拍摄同一地点的图像。这一进步使我们能够轻松获取同时捕获的多个卫星图像,为设计有效的除云方法提供充足的数据支持。一般来说,云的位置随时间而变化,在同一地理位置被云遮挡的区域在不同时刻并不完全重叠。现有的多时相去云方法]利用光谱和时间信息,融合多幅多云图像,生成细节丰富的无云图像。
现有的云去除方法主要依赖于GAN,通过在训练过程中引入对抗损失来增强图像重建。MCGAN将CGANs从RGB图像扩展到多光谱图像进行去云。Spa-GAN在GAN中引入了空间注意机制,以提高云区域的信息恢复,从而获得更高质量的无云图像。AE采用多时相遥感数据集训练的卷积自编码器进行云去除。STNet集成了云检测技术,融合了多幅云图的时空特征进行去云。STGAN将去云作为一个条件图像合成问题,提出了一种时空生成网络。CTGAN引入了一种基于transformer的GAN来去除云。PMAA使用渐进式自编码器实现了高效的云去除。此外,也有一些文献利用雷达图像辅助除云,以及少数文献采用扩散模型。然而,由于GAN框架和对抗性学习机制的限制,现有的基于GAN的方法难以获得令人满意的图像保真度。此外,尽管一些基于扩散的方法表现良好,但它们通常效率很低,通常需要数千个采样步骤。因此,这项工作探索了一个新的、快速的云移除框架,使用条件扩散模型,实现了更高的保真度,而没有花里胡哨的东西(without bells and whistles,就是没用深度神经网络的trick,任何人都可以无痛各种精调,各种扩大训练集,各种hard online 各种学习率啊,参数啊什么的来回试,就可以达到比较好的效果。所以方法本质就是好的,是必然,而不是偶然)。
2.2 扩散模型
图像生成一直是计算机视觉的一个热门研究方向,各种图像生成范式被提出并应用于该任务。近年来,许多基于GAN的模型占据了最先进的地位。然而,这种范式已经被扩散模型的出现所打破。
受热力学的启发,扩散模型通过迭代逐渐引入噪声,目的是学习噪声引起的信息衰减,并根据学习到的模式生成图像。扩散模型在高分辨率图像生成中取得了优异的表现,在图像合成质量和多样性方面超过了gan。扩散模型的成功引起了研究人员的极大关注,从而进一步提高了生成质量和采样速度。
最近,条件扩散模型已经发展并应用于各种下游任务。已经提出了许多基于扩散的图像到图像转换方法,针对低级视觉任务,如着色,去噪,修复和超分辨率。跨模态研究也证明了扩散模型在文本到图像生成中的卓越表现。此外,扩散模型在语义图像合成、图像分割、视频生成和姿态估计等具体任务中显示出显著的效果。受这些工作的启发,我们率先探索使用扩散模型来解决云移除任务,提出了各种改进策略来解决云移除的复杂性,并实现高保真的无云图像。
3 方法
3.1 问题定义
去云的目的是从多云光学卫星图像中生成无云图像。我们将云图定义为,其中C、H、W分别表示卫星图像的通道数、高度和宽度,N表示图像数。具体来说,当N = 1,表示只输入一张云图时,我们称之为单时间去云;当N > 1时,输入由不同时间同一地理位置的多幅云图组成,我们称之为多时相去云。每个区域对应的无云图像记为
。
3.2 总体框架
在本文中,提出一个新框架,称为DiffCR,将条件扩散模型和深度卷积网络相结合用于去云研究。如图1所示,由两部分组成:从左向右的噪声注入过程和从右向左的去噪过程。以多幅多云图像为条件,将具有一定噪声水平
的退化图像
加入到ground truth图像
中,我们的框架可以迭代细化并生成具有细粒度细节的高质量无云图像。

3.2.1 前向扩散
正向扩散是一个不需要学习的确定性过程。它遵循马尔可夫假设,并在T次迭代中逐步向无云图像添加噪声:
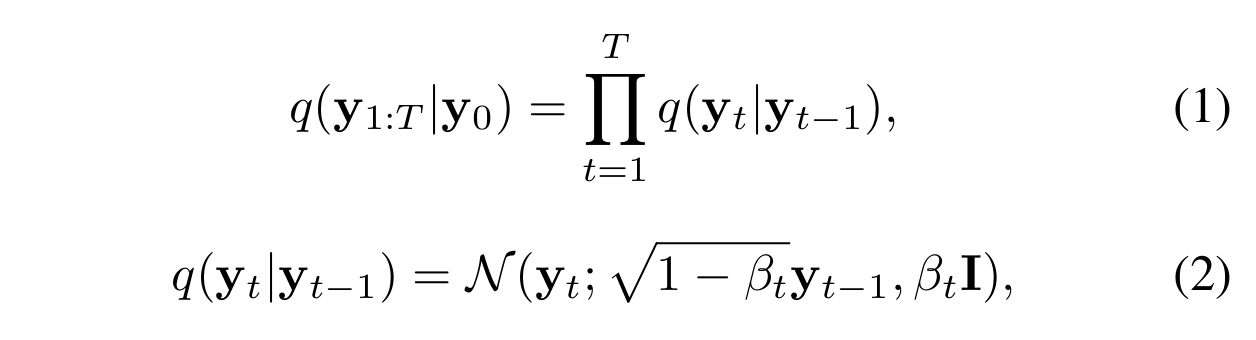
其中是表示噪声方差的预定义超参数。通常,
的取值范围为
,且满足
。随着T的增大,
逐渐失去其原有的数据特征。当
时,
成为服从高斯分布的随机噪声。把不同迭代的方差称为噪声调度。
实际上,通过数学推导,可以直接根据原始数据在任意步 t 处对
进行采样:
![]()
式中,
。这是一个至关重要的性质,从公式(3)中,可以看到
实际上是
和高斯噪声的线性组合。此外,可以根据
而不是
来定义噪声调度。有效的噪声调度可以使扩散过程更加自然,加速模型收敛,提高性能。图2显示了不同噪声调度策略在扩散过程中的视觉效果。

图2 不同噪声调度下扩散过程产生的样本。线性时间表最终产生的样本几乎是纯噪声,差异很小。相比之下,余弦Cosine和Sigmoid调度缓慢地添加噪声并生成高质量的样本。
3.2.2 反向去噪
如果可以逆转扩散过程,即的样本,可以从随机高斯分布
重建一个准确的无云样本。然而,由于无法从完整数据集中直接预测
,因此通常使用参数化神经网络模型
来近似条件概率分布并进行反向去噪处理(Algorithm 1)。
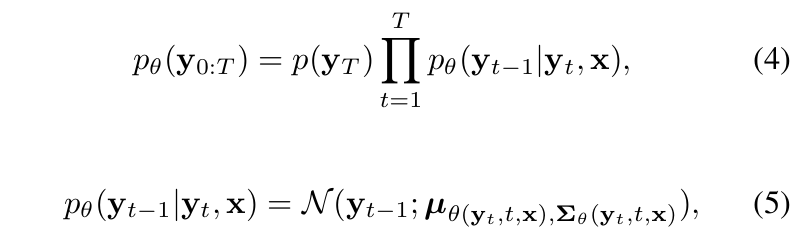
其中,,
,x为模型的输入,
,
为模型预测的先验分布的均值和方差。
值得注意的是,推理过程(算法2)也是一个反向马尔可夫过程,但它是从高斯噪声开始,逐步向前采样,即通过迭代细化生成高保真的无云图像。理论上,加入噪声的时间步长T越大,最终生成的推断图像质量越高。现有的扩散模型通常需要数千步才能生成高质量的图像,这严重影响了模型的实际应用,特别是在资源较少的设备上。为了解决这个问题,我们引入了一个快速ODE求解器,它可以在大约10个步骤中生成高质量的图像。在消融研究中,我们对不同采样器不同采样步骤的结果进行了定量和定性比较。
3.2.3 条件扩散模型
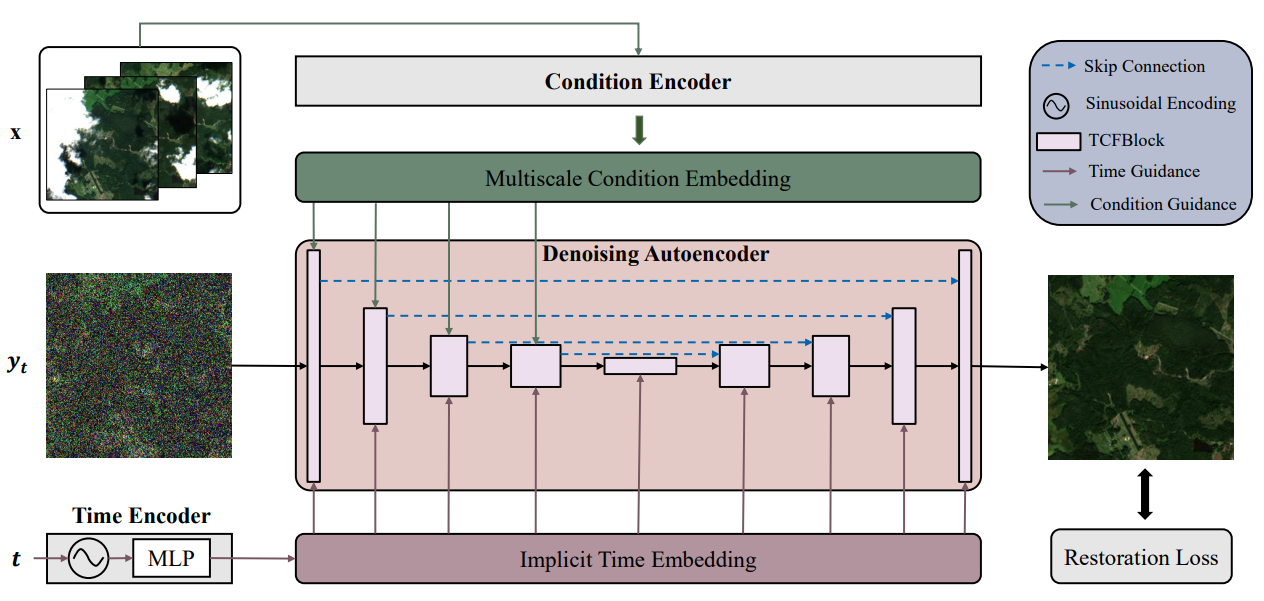
图3 DiffCR条件去噪模型的总体结构。该模型由三部分组成:1)条件编码器,2)时间编码器,3)去噪自编码器。条件编码器和时间编码器分别负责提取云图x的空间特征和噪声水平t的时间特征,然后将其送入去噪自编码器,指导整个去噪过程。条件编码器和去噪自编码器由我们开发的几个TCFBlock组成(参见图4)。时间编码器由正弦编码函数和多层感知器(MLP)组成。最后,在恢复损失的监督下,估计无云图像的数据分布。
我们提出了一个新的条件去噪模型,该模型基于我们精心设计的时间和条件融合块(TCF-Block)作为基本组件,如图3所示。该模型由三部分组成:
- 条件编码器
- 时间编码器
- 去噪自编码器
条件编码器和时间编码器分别负责提取多云图像x的多尺度空间特征和噪声水平t的时间特征,然后将其输入去噪自编码器,指导整个重建过程。在恢复损失的监督下,模型输出高保真的无云图像。
1)时间和条件融合块(Time and Condition Fusion Block,TCFBlock)
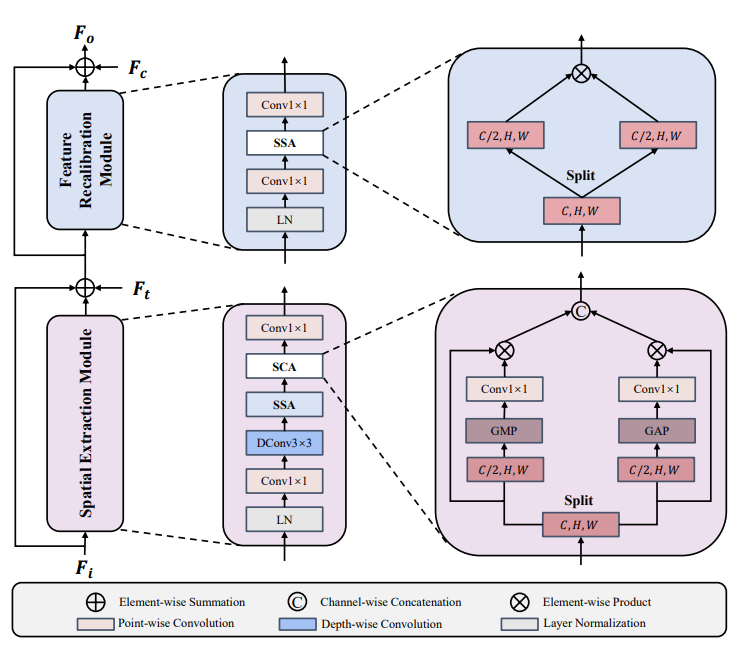
图4 提出的时间和条件融合块(TCFBlock)示意图
众所周知,扩散模型的训练通常涉及许多迭代步骤。这些都需要大量的计算资源。受此启发,并受到文献中网络结构的启发,我们设计了一个高效的时间与条件融合块(TCFBlock)作为条件去噪模型的基本单元。它在实现SOTA性能的同时显著降低了计算复杂度。如图4所示,TCFBlock包括空间提取模块(SEM)和特征再校准模块(FRM)。
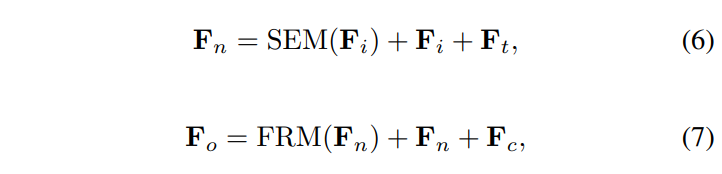
其中,表示输入特征,
表示特征通过SEM输出,
表示多云图像的空间特征,
表示噪声水平的时间特征,
是通过FRM最终输出的特征。
a)空间提取模块(Spatial Extraction Module,SEM)
SEM用于提取细粒度的空间特征,构造为倒置的瓶颈结构。首先,采用Transformer中常用的层归一化(Layer Normalization)代替批归一化(Batch Normalization)来对输入特征进行归一化,以达到稳定训练的目的。然后,利用带通道展开的1x1卷积和带3x3卷积的深度可分离卷积(Depthwise Conv)提取详细的空间特征。随后,引入分裂自激活(Split Self-activation)机制来取代传统激活函数的作用,从而增强了模型的非线性表达能力。
![]()
其中表示归一化。Conv和DConv分别表示标准卷积和深度可分离卷积。
近年来,通道注意机制在各种计算机视觉任务中取得了巨大的成功。因此,我们在SEM中引入了一种新颖高效的分割通道注意(Split Channel Attention,SCA),以增强提取特征的鲁棒性。如图4所示,SCA包括两个通道注意分支:全局通道注意分支和局部通道注意分支。首先,在通道维度上将输入特征分成两部分,然后在每一部分中分别进行全局平均池化(Global Average Pooling,GAP)和全局最大池化(Global Maximum Pooling,GMP)。随后,使用1×1卷积来建立每个部分中通道之间的显式相关性。最后,从两个分支中选择的特征沿着通道维度进行连接,以生成同时考虑全局和局部信息的鲁棒特征。由于平均池化强调提取特征的平均信息,可以保留图像的一些复杂细节,我们将其所在的分支称为全局通道关注分支。相反,由于最大池化更侧重于提取图像中最显著的特征,因此我们将其所在的分支表示为局部通道注意分支。最后,引入1 × 1卷积来进一步调制连接的特征。
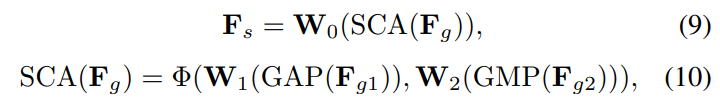
其中,和
是在通道维度上将
拆分的结果。
,
和
分别表示点向卷积的权值矩阵。
表示通道级连接操作。
b)特征重新校准模块(Feature Recalibration Module,FRM)
FRM旨在重新校准条件和噪声图像的空间特征,即噪声水平的时间特征,由两个点向卷积层,一个激活层和一个归一化层组成(式(11))。为了降低计算复杂度,我们采用分裂自激活(Split Self-activation)机制代替深度模型中常用的ReLU或SiLU激活函数。有文献发现激活函数越少,性能越好。因此,我们只使用单个SSA来增强模型的非线性。此外,中端较大、端较小的倒置瓶颈结构已被证明可以有效防止信息丢失。因此,我们在两个点向卷积中使用它来代替瓶颈结构。
![]()
其中表示FRM重新校准的特征,
表示激活函数,
表示层归一化。
和
分别表示倒置瓶颈结构中两个点向卷积的权值矩阵。
2)条件编码器(Condition Encoder,CE)
现有的条件扩散模型直接将条件输入和有噪声输入沿通道维度进行拼接,并将其输入到去噪模型中,这增加了模型训练的难度。基于此,我们开发了一种轻量级的解耦CNN条件编码器,该编码器由多个TCFBlock(没有和
注入)和下采样层组成,明确地提取条件图像x的多尺度特征。具体来说,对于条件输入x,我们首先利用TCFBlock来细化空间关系,然后进行尺度约简。接下来,我们引入了核和步长为2 × 2的卷积层进行下采样,为了减轻下采样过程中固有的信息损失,我们增加了通道的数量。
![]()
其中DownSample(·)为上述卷积,x和分别为输入条件图像和缩减比例后的输出特征。
3)时间编码器(Time Encoder,TE)
为了防止去噪自编码器学习固定的范式,我们选择在输入期间添加具有不同水平随机噪声的图像。相应地,我们需要包括反映噪声水平的时间步长t,作为去噪自编码器的额外输入,以指导整个学习过程。具体来说,对于时间步长t,我们采用与相关工作相同的时间编码器(公式13)。首先,我们执行正弦编码并将其馈送到多层感知器以获得隐式时间嵌入。最后,传播其维度后,将时间编码注入到去噪自编码器的每个TCFBlock中。由于时间步长t不包含空间信息,所以不需要进行类似于图像的卷积操作。这些操作不能带来额外的性能提升,而且会增加计算开销。
![]()
其中 t 表示时间步长,sin(·)表示正弦编码,MLP表示多层感知器,由两个具有倒置瓶颈结构的线性层和一个SiLU激活函数组成。Reshape(·)表示传播时间嵌入来调制图像特征的权重,表示隐式时间嵌入。
4)噪声自编码器(Denoising Autoencoder,DA)
利用第III-C1部分中提到的TCFBlock作为基本模块,设计了一个UNet结构的自编码器,用于DiffCR的去噪处理。
a)编码器(Encoder)
编码器由连续堆叠的TCFBlock阵列和几个下采样层组成。本设计旨在提取不同分辨率下的多种多尺度特征,由式(14)封装。根据相关文献的信息,我们采用了一种使用卷积层的下采样方案,该卷积层的特征是2 × 2的核大小和步幅。为了减轻降采样过程中固有的信息损失,我们同时扩大了通道的数量,这从本质上增强了每层的特征表示能力。
![]()
其中,和
分别表示从第e层和第(e+1)层提取的特征映射。DownSample()运算体现了卷积下采样方法,进一步增强了模型的层次表示。通过逐层逐步积累抽象特征,编码器提供了一个健壮而丰富的特征集,从而提高了下游任务的性能。
b)中间层
中间块的目的是在最小空间尺度上对编码器提取的特征进行调制,在大感受野的引导下进一步细化特征或建立特征之间的空间位置相关性。因此,我们可以通过连续堆叠多个TCFBlock来继承编码器的设计。
![]()
c)解码器
解码器的设计类似于编码器,将多个TCFBlock堆叠,利用上采样层逐渐将潜在特征恢复到原始输入图像的空间尺度。为了减轻信息损失,我们利用PixelShuffle作为上采样插值或转置卷积的替代品。与UNet类似,我们也引入了跳过连接。但是,我们没有使用标准的通道级连接操作,而是直接使用元素级加法。直接添加的跳过连接不引入额外的参数,而通道级连接需要学习额外的参数来调整特征通道的维度。当将低级特征直接添加到高级特征时,低级特征可以更直接地与高级特征融合,而通道级连接可能需要更复杂的转换来实现特征融合。
![]()
3.2.4 回归目标与损失函数
现有的无条件扩散模型和条件扩散模型通常采用将的输出回归到
的噪声预测方法,训练神经网络模型学习前向过程中每一步加入的高斯噪声。
![]()
其中,表示参数化去噪模型,
表示来自高斯分布的随机采样噪声,x和y表示来自数据集的样本。
然而,我们观察到噪声预测方法增加了训练难度,当有大量的条件输入信息时,甚至可能导致模式崩溃。出于这种考虑,我们提出了一种新的更直接的预测方法,通过将的输出回归到
,称为“数据预测”,作为噪声预测的替代品。
![]()
虽然 和
的值可以相互确定,但是改变回归目标会影响损失函数的尺度,从而影响模型训练。由于条件输入图像与无云地面真值图像具有更相似的数据分布,因此数据预测明显比噪声预测容易,从而提高了模型收敛性和去云性能。在Section IV-C2中通过消融实验进一步验证了这一点。我们比较了这两种不同的回归方法,发现直接预测
(我们提出的数据预测)更容易收敛,特别是当条件x的数量增加时。值得注意的是,OpenAI开发的DALL·E2在他们的工作中也报告了类似的发现。
4 实现
4.1 数据集
我们在光学卫星图像的Sen2_MTC_Old和Sen2_MTC_New这两组大尺度多时序去云数据集上进行了所有实验。
1)Sen2_MTC_Old
该数据集是第一个解决去云挑战的数据集,由多时相光学卫星(Sentinel-2)图像组成。它包含来自世界各地的945个tiles,每个tiles为10980 × 10980像素,地面分辨率为10米每像素。平均而言,在同一地点每六天拍摄一次新图像。随后,每个tiles被裁剪成大小为256 × 256像素的多个patch。云层覆盖率在1%以下的区域被标记为“晴朗”,云层覆盖率在10%到30%之间的区域被标记为“多云”,云层覆盖率超过30%的区域被丢弃。对于同一位置,选取三张相邻的多云图像作为输入,选取云层覆盖最少的清晰图像作为标签。多时相去云任务共获得3130对图像。
2)Sen2_MTC_New
为了解决Sen2_MTC_Old中标注质量差和样本分辨率低的问题,Huang等人构建了一个新的Sentinel-2卫星图像数据集,用于训练多时相去云模型。该数据集包含大约50个不重叠的块,每个块由大约70对裁剪的256×256像素块组成。与Sen2_MTC_Old类似,Sen2_MTC_New遵循相同的过程构建多时相图像对,其中同一位置的三张多云图像对应一张无云图像。具体来说,Sen2_MTC_Old对图像进行了压缩,像素值范围为0 ~ 255,而Sen2_MTC_New将图像保留为原始TIFF格式,像素值范围为0 ~ 10000。
4.2 实现细节
为了促进实验的可重复性,本节详细介绍了训练过程中使用的超参数配置和用于评估实验结果的指标。
1)训练设置
我们进行了大量的实验来验证DiffCR的有效性。对于优化算法,我们选择AdamW作为优化器,初始学习率为5e-5,权衰减为0。在训练阶段,我们使用的批量大小为8。培训过程共进行了约7个步骤。本文的权值初始化采用了Kaiming正态分布,使网络在训练过程中收敛更快,性能更好。模型参数采用指数移动平均(EMA),从训练的第一次迭代开始,每次训练迭代后更新,衰减率为0.9999,有助于稳定训练过程,防止过拟合。在扩散过程中,我们将最大噪声步长设置为2000。实验在安装了2颗AMD EPYC 7402 24核处理器、128 GB内存和4颗NVIDIA GeForce RTX 3090 gpu、24 GB内存的工作站上进行。使用的操作系统是Ubuntu 22.04,所有网络都是在PyTorch 1.10.1与CUDA 11.1和Python 3.8中实现的。
2)评价指标
在所有实验中,我们报告了测试集的峰值信噪比(PSNR, dB)、结构相似指数度量(SSIM)、学习感知图像斑块相似度(LPIPS)和Frechet Inception距离(FID)来评估生成的无云图像的质量。值得注意的是,PSNR和SSIM是基于像素来衡量图像之间的差异,而FID和LPIPS是基于深度特征向量来衡量图像之间的差异。与传统的图像质量评估指标(PSNR和SSIM)相比,FID和LPIPS更符合人类的视觉感知。此外,LPIPS几乎可以被认为是一个区域性的FID指标,因为即使FID变化很大,LPIPS分数也显示出最小的变化。因此,当LPIPS接近接近时,我们优先考虑FID。为了评估模型效率,我们报告了所有模型的参数数量(Params, M)和乘法累积操作(MACs, G),这些都是通过开源工具计算的。
4.3 消融实验
在本节中,我们提出了广泛的消融研究,以验证所提出的DiffCR及其组成部分的有效性。具体来说,我们研究了以下因素的影响:
- 前向扩散中的噪声调度
- 去噪模型的回归目标
- 条件浑浊图像的处理方法
- 推理阶段的采样步骤
- 去噪模型结构的变化
所有消融实验均在Sen2_MTC_New数据集上进行,因为与Sen2_MTC_Old数据集相比,新数据集具有更高的注释质量和更高的图像分辨率。
1)噪声调度类别是否重要
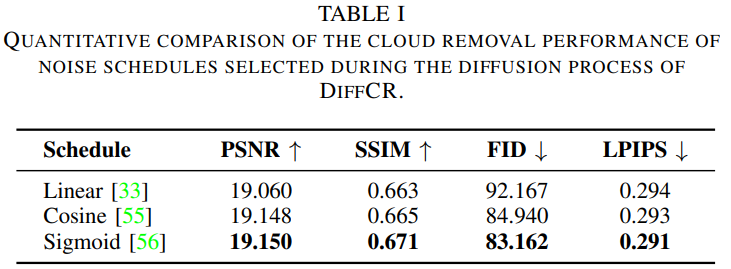
表1 对DiffCR扩散过程中选择的噪声调度的去云性能进行了定量比较
表1中的结果显示了在扩散过程中不同噪音调度的影响。可以看出,Sigmoid调度的去云性能最好,Cosine调度的性能略有下降,Linear调度的性能最差,这与III-B1节的理论预期一致。因此,我们建议在基于扩散的云移除或其他生成任务中使用Sigmoid调度,因为它有助于模型收敛和性能改进。
2)数据预测或噪声预测
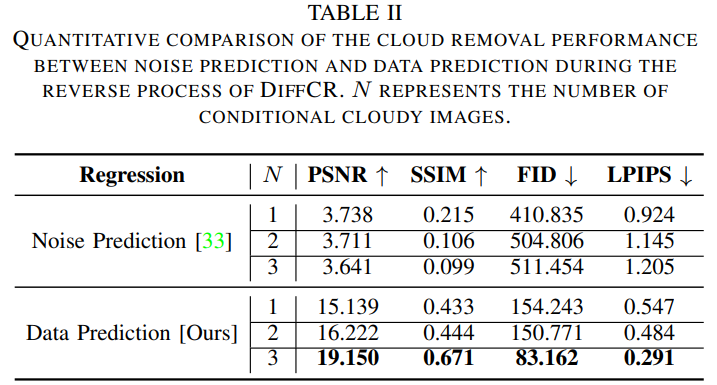
表2 DiffCR逆过程中噪声预测与数据预测去云性能的定量比较。N表示条件浑浊图像的个数。
我们通过实验验证了所提出的数据预测和原生噪声预测对去云性能的影响,如表2所示。如所料(如第III-D节所述),对于{1,2,3}中的任意N值,数据预测优于噪声预测,其中N表示多云图像的序列长度。特别是,随着N的增加,数据预测的性能越来越好,而噪声预测的性能越来越差。这是因为,在数据预测中,模型试图预测与输入(噪声无云图像和多云图像)分布更相似的目标(即去噪后的无云图像),特别是随着N的增加,分布的相似性增加。相反,噪声通常具有完全不同的分布(例如,高斯噪声)。因此,对于试图从输入中提取有用信息的模型,预测与输入相似的目标可能更容易获得,而噪声预测通常会导致模式崩溃。
3)条件多云图像的处理
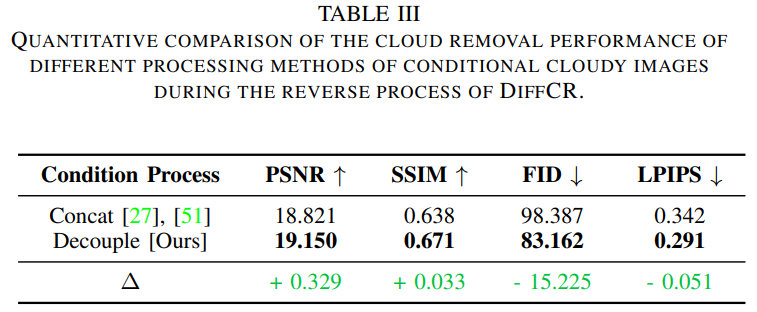
表3 定量比较不同处理方法对条件多云图像在DiffCR反求过程中的去云性能。
为了解决DiffCR中有条件的多云图像处理问题,我们定量验证了两种不同的特征提取和融合策略:
- Concat:将有噪声的无云图像沿通道维度与所有多云图像进行拼接,然后送入去噪模型进行处理,这是前人采用的最直接的方法;
- 解耦:是用于DiffCR的解耦条件编码器。
表III的实验结果表明,“解耦”是更好的条件图像处理方法,可以获得更高的去云性能,PSNR提高0.329,FID提高15.225。
4)使用不同采样步骤的推理
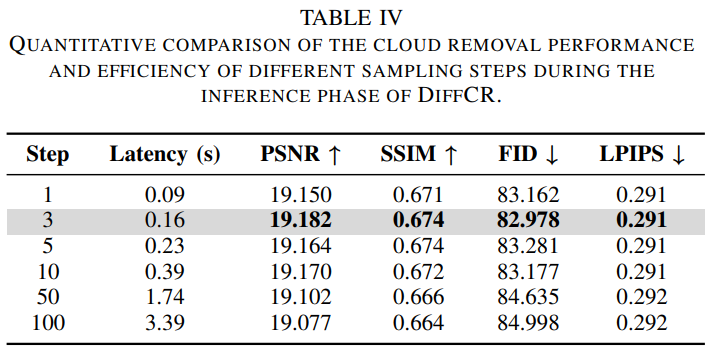
表4 定量比较了DiffCR推理阶段不同采样步骤的去云性能和效率。
普通扩散模型的推理速度慢得令人无法接受,需要数千次迭代才能提炼出高质量的图像。即使在合适的GPU设备上,其对单个样本的推理速度也可能比对单个epoch的训练速度慢,严重阻碍了扩散模型在计算机视觉中的应用。现有的基于扩散的云去除模型没有考虑这种现实世界的约束,在推理过程中需要许多采样步骤。相比之下,由于其利用数据预测和条件解耦的框架设计,DiffCR只需一步就可以生成高质量的样本,并在3到5步内实现绝对收敛。我们比较了不同采样步骤下样本质量和推理延迟的定量结果。结果总结在表4中。可以看出,推理延迟随着采样步数的增加而增加。值得注意的是,只需一个采样步骤就可以获得出色的结果,从1到3个采样步骤可以获得边际性能改进,而在3到5个采样步骤之间可以实现收敛。然而,当采样步数超过25步时,通过LPIPS等指标衡量的云移除性能会因过度采样而逐渐下降。因此,我们最终将一个采样步骤获得的结果与其他方法进行比较,这些方法仅以0.09秒的推理延迟实现SOTA性能。
5)去噪模型中的架构变化
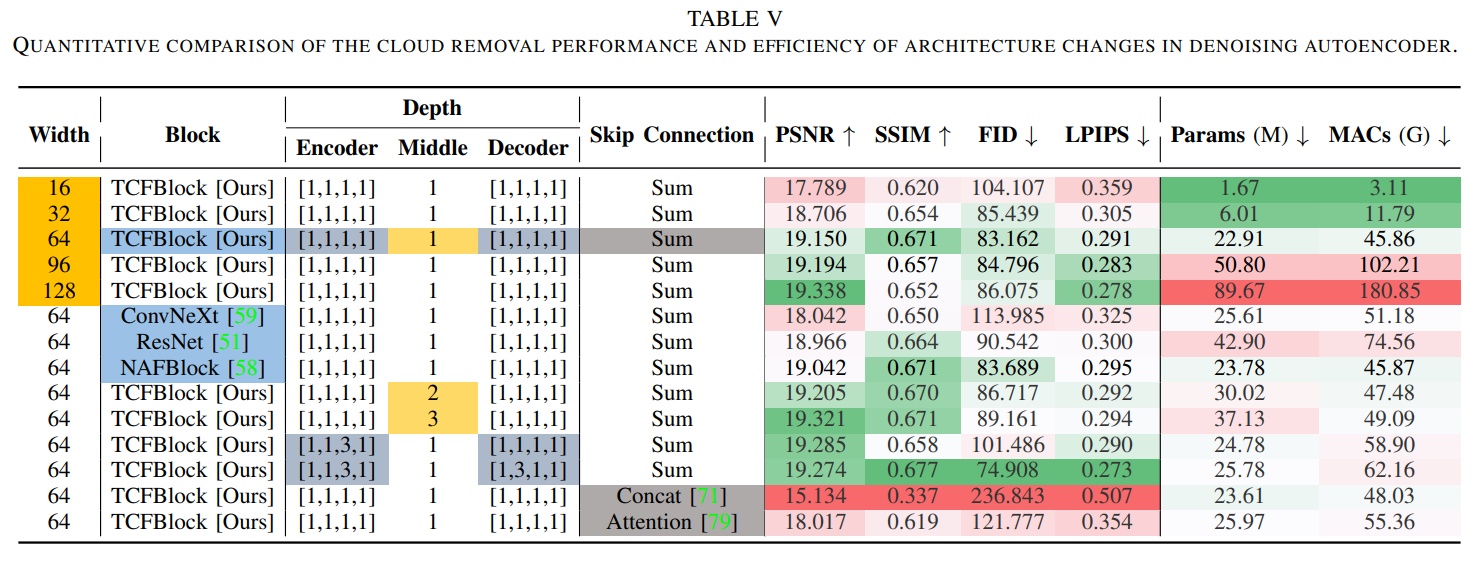
表5 去噪自编码器结构变化的去云性能和效率的定量比较
自引入扩散模型以来,大多数研究都集中在改进其内部扩散机制,以获得高质量的样本或更快的推理速度。然而,对于扩散框架下哪种去噪神经模型更有效的研究却很少。基于此,我们提出了一种具有类似UNet架构的去噪模型基线。它由我们设计的几个TCFBlock组成。通过综合消融实验,我们探讨了去噪模型的架构变化对去云性能的影响,定量结果如表5所示。具体来说,我们将探讨以下架构变化:
- 去噪模型的宽度(通道数)
- 去噪模型的块类型
- 多个块的堆叠深度
- 跳跃连接的融合类型
如表V所示,我们发现增加深度和宽度可以显著提高去云性能。在各种块类型(如ResNet, ConvNeXt和NAFBlock)中,我们提出的TCFBlock达到了最好的性能,并且在编码器,中间层或解码器的任何部分添加更多的块都会导致一些性能提高。值得注意的是,当编码器和解码器在深度方面采用对称结构(如从底部开始的第三行)时,性能改进最为显著。此外,最直接的跳跃连接(Sum,即直接添加相同分辨率的编码器和解码器特征)可以获得最佳性能,而更复杂的跳跃连接(如Concat,它将通道维度上的特征进行连接)可能会导致训练不稳定,这可能是由于学习复杂性的增加。使用注意机制选择性地连接编码器和解码器的特征可能会降低性能,可能是由于这种连接导致的信息丢失,从而影响生成图像的质量。最后,为了在性能和效率之间取得平衡,我们选择表的第三行表示的数据作为去噪模型的架构配置,因为它优于所有现有的参数数量和计算复杂性较低的方法。
4.4 与最先进方法的比较
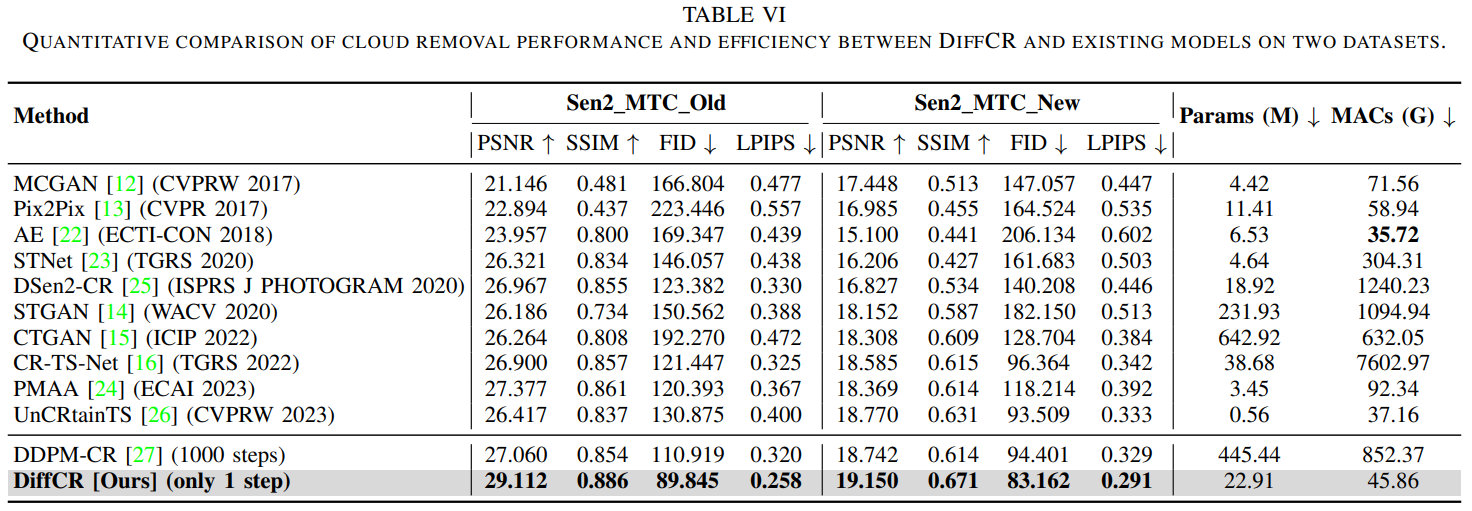
表6 不同模型和现有模型在两个数据集上的云去除性能和效率的定量比较。
表VI给出了我们提出的DiffCR与现有模型MCGAN、Pix2Pix、AE、STNet、DSen2-CR、STGAN、CTGAN、CR-TS-Net、PMAA、UnCRtainTS和DDPM-CR之间的去云性能和效率的定量比较。除了基于扩散方法的DDPM-CR和DiffCR之外,所有其他方法都是基于GAN或回归(没有对抗损失)。术语“1 step”是指在反向推理阶段使用的采样步长。
1)去云性能
在两个基准数据集上,DiffCR在云移除的所有评估指标上取得了一致的SOTA性能,展示了我们提出的方法的全部潜力。具体而言,DiffCR在Sen2_MTC_OLd和Sen2_MTC_New数据集上的SSIM分别为0.886和0.671,LPIPS分别为0.258和0.291。相比之下,现有模型的性能值要低得多。总体而言,基于扩散的云去除方法,如所提出的DiffCR模型所示,优于所有现有的基于GAN或回归技术的云去除模型。与现有的基于扩散的模型DDPM-CR相比,DiffCR在两个数据集上都取得了显著的性能提升。具体而言,在Sen2_MTC_Old数据集上,DiffCR的PSNR为29.112,比DDPM-CR的PSNR(27.060)高2.052;LPIPS为0.258,比DDPM-CR的LPIPS(0.320)低0.062。在Sen2_MTC_New数据集上,DiffCR的PSNR为19.150,比DDPM-CR的PSNR(18.742)高0.408;LPIPS为0.291,比DDPM-CR的LPIPS(0.329)低0.038。结果表明,DiffCR在精度和效率方面都优于现有的基于扩散的模型DDPM-CR。
2)去云效率
值得注意的是,在获得上述优异结果的同时,模型的参数(22.91M)与MACs (45.86G)保持了合理的平衡,这是模型实际应用的一个关键方面。与基于GAN或回归的模型相比,DiffCR在参数数量和计算复杂度方面优于大多数模型。与之前基于SOTA扩散的模型DDPM-CR相比,DiffCR在参数数和计算复杂度分别仅为5.1%和5.4%的情况下取得了更高的性能。因此,我们的工作使扩散模型首次应用于实际的云去除任务,为该领域的未来研究奠定了基础。

图5 本文提出的DIffCR方法与其他现有方法在Sen2_MTC_Old数据集上的可视化结果进行了定性比较。

图6 本文提出的DiffCR方法与其他现有方法在Sen2_MTC_New数据集上的可视化结果进行了定性比较。
如图5和图6所示,我们还对DiffCR和所有其他现有方法进行了定性比较。所有样本都是从测试集中随机抽取的。第一行显示输入的云雾图像(序列长度N = 3),最后一列表示参考云雾图像。其余行显示不同算法的重建结果。可以看出,DiffCR在局部结构生成(如图a所示)和全局亮度恢复(如图b所示)方面都优于所有其他方法,实现了最高的图像保真度。
总的来说,这些实验结果表明DiffCR优于现有的SOTA方法,特别是在图像保真度和计算效率方面。这强调了我们提出的方法的有效性,该方法利用数据预测和一个条件解耦扩散模型来去除光学卫星图像中的云。
4.5 失败案例及限制
尽管我们的方法表现出示范性的性能,但它仍然显示出一定的局限性。首先,当输入的云雾图像中含有类似黑洞形状的湖泊区域时,我们的方法在准确重建湖泊区域方面遇到了挑战(如图7所示)。这是由于不规则的、黑暗的湖泊区域与云层阴影的内在相似性。其次,尽管我们的方法通过使用轻量级和高效的模块来努力在性能和效率之间取得平衡,但扩散模型的固有机制需要在模型训练阶段进行相当多的迭代步骤才能实现收敛。最后,虽然我们的方法是专门为云移除任务而设计的,并且尚未经过跨多个任务的全面验证,但其固有的通用性使其在不同领域的潜在应用,例如与从文本到图像和从图像到图像合成的生成式人工智能相关的研究。
5 结论
在这项工作中,我们提出了DiffCR,一个快速条件扩散框架,用于高质量的云去除。现有的基于gan和回归的去云模型无法生成高保真图像,而基于扩散的去云模型需要数千次迭代才能保证高采样质量。因此,如何平衡采样速度和采样质量已成为云去除的主要挑战。相比之下,DiffCR重新定义了云去除的条件扩散框架,设计了一种新的条件解耦神经模型,并通过直接预测干净数据来参数化去噪模型。我们还在模型中开发了一种新颖高效的时间和条件融合块。因此,DiffCR生成高保真度和细节丰富的无云图像在一个采样步骤。通过对两个基准数据集的综合实验,我们证明了DiffCR在合成质量方面优于公开可用的最佳模型。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











