






我们将会用到Stable Diffusion WebUI 中安装的 Inpaint Anything 扩展,如何你还没有SD本地环境,可以先查看其他配置本地SD环境(安装实在是太复杂了,对Mac用户也不友好)或者使用一些在线的Stable Diffusion WebUI工具。
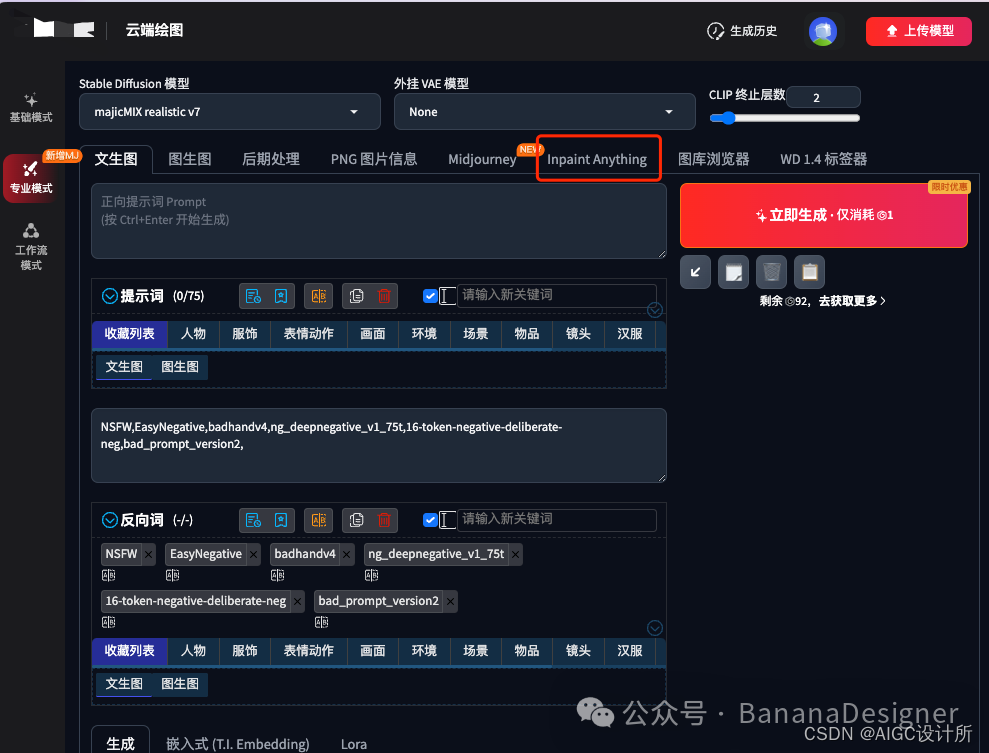
第1步:上传图片到Inpaint Anything 中

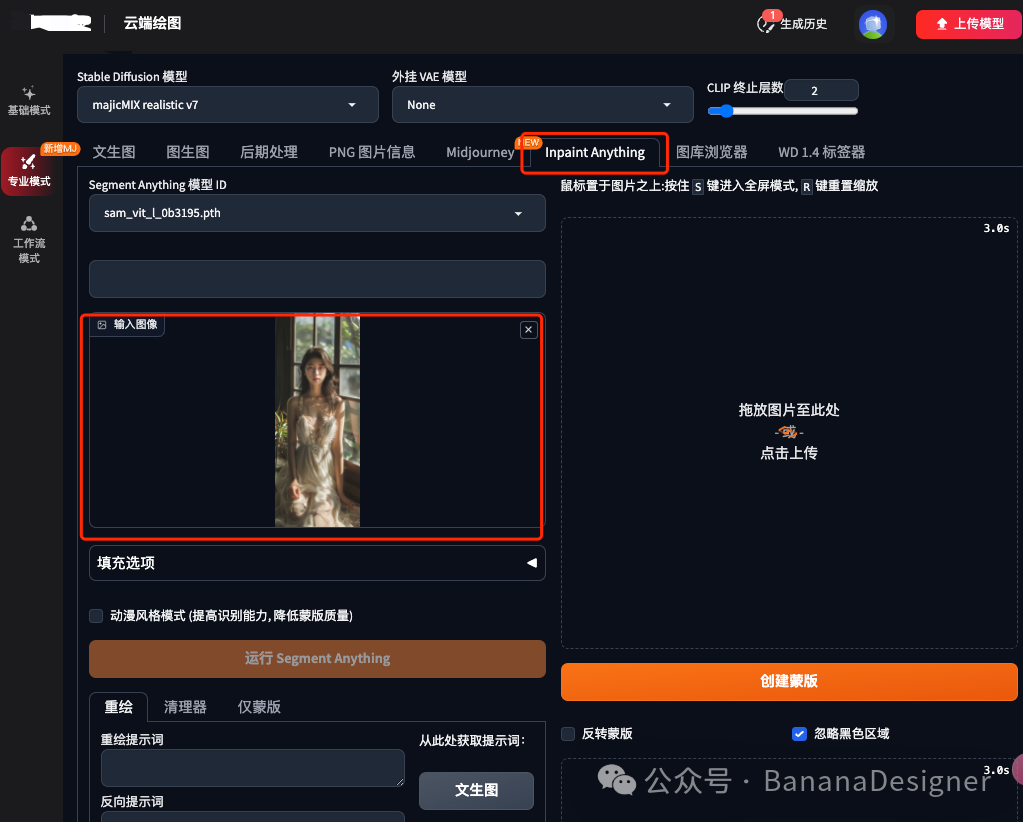
点击Inpaint Anything 标签页下,将图片拖动到输入图像框中。
第2步:运行分割模型
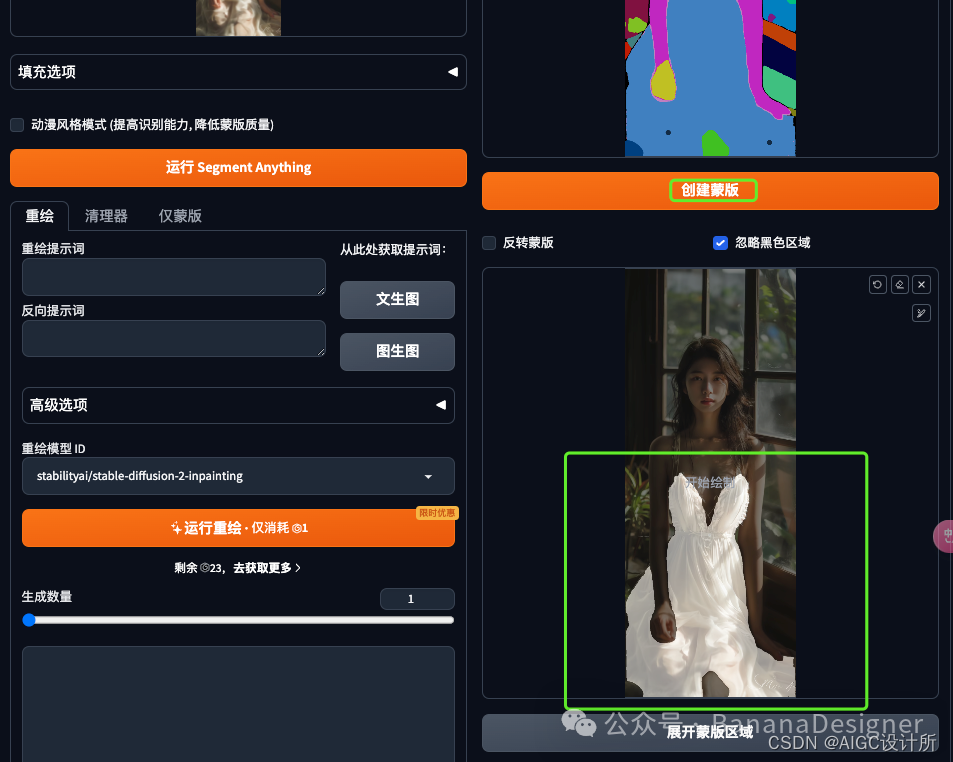
等待图片上传完成后,点击“运行Segment Anything”按钮,然后等待,你就能看到这样的语义分割图,不同的颜色代表了图片中识别出的不同对象。
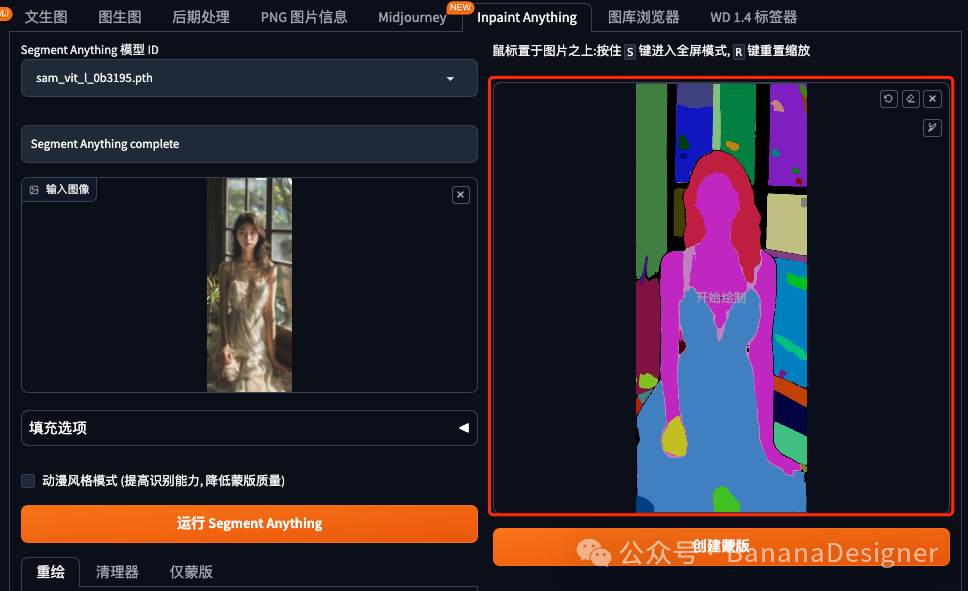
第 3 步:创建蒙版
使用画笔在分割图中标识出想要重绘的裙子区域,不需要整件衣服涂黑,每件衣服每个部分点一个点就可以了,鼠标放在图片上时按键盘S键可以放大图片,按R复原。
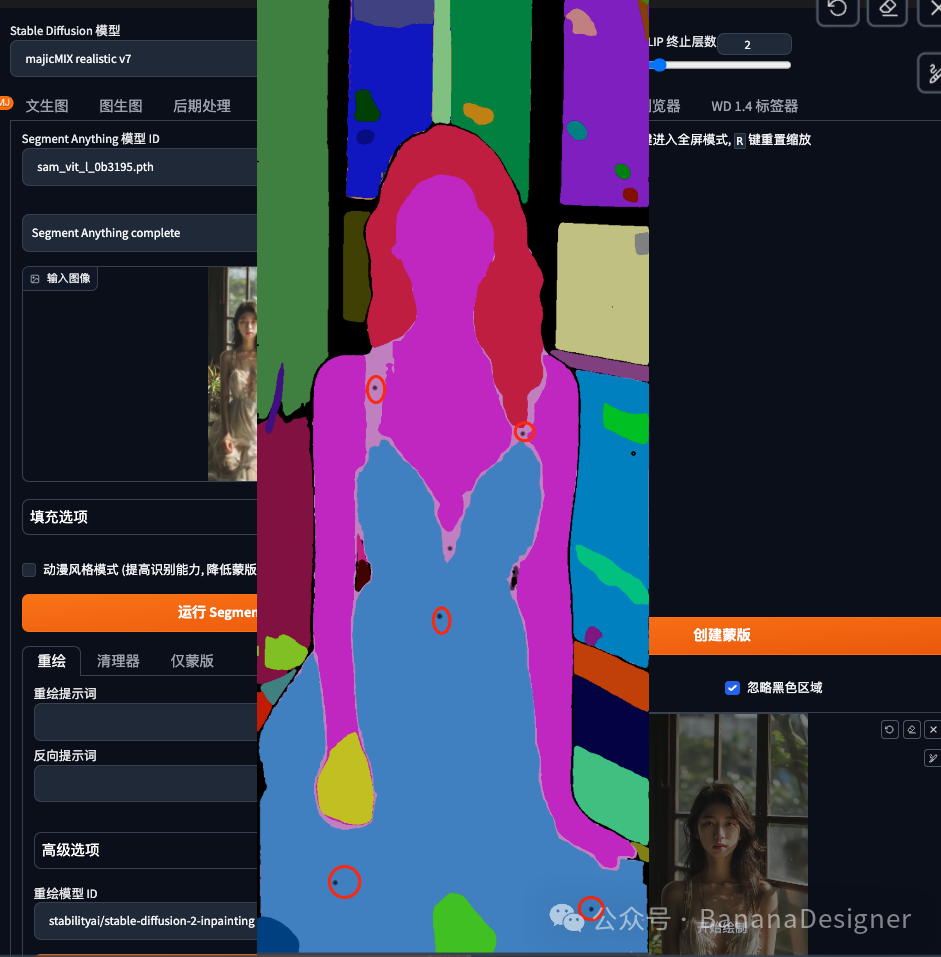
然后点击“创建蒙版”按钮。
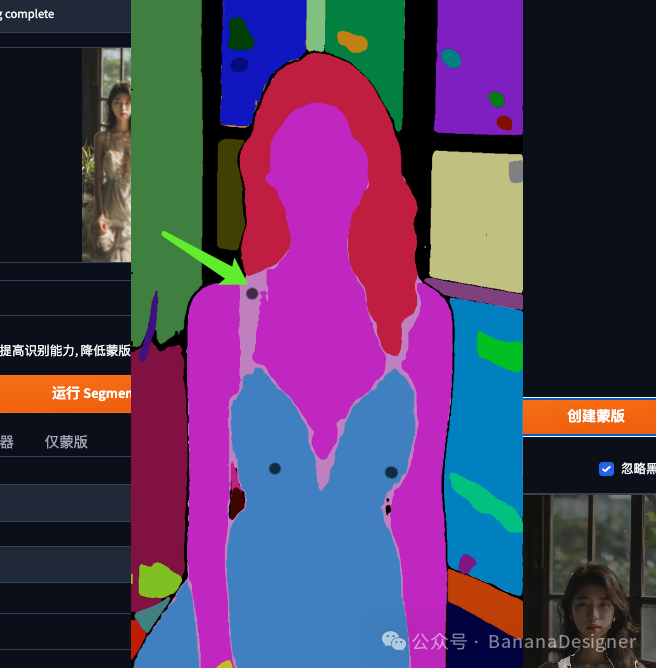
如果发现蒙版未覆盖您想要的所有区域,请返回分割图并绘制更多区域。
我发现裙子的肩带没有被选中,返回分割图增了一个点。得到如下图:
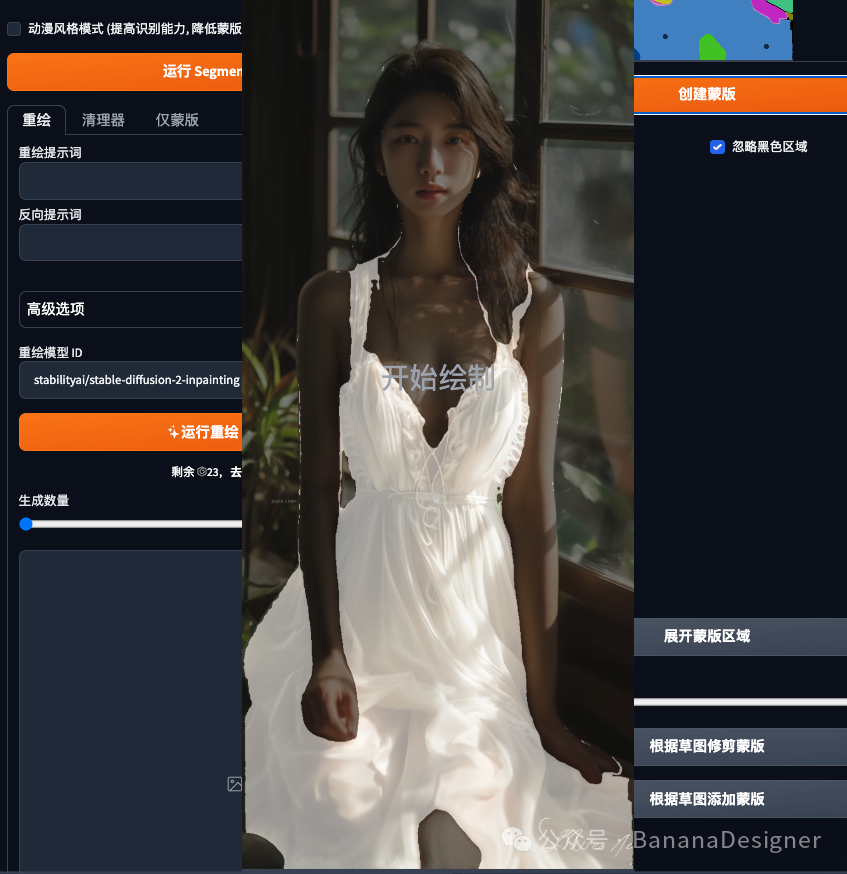
“展开蒙版区域”这个是翻译的问题,英文为“Expand mask region”,意思是向外圈稍微扩展一下遮罩的大小。
“根据草图修剪蒙版”是指:从蒙版中减去绘制的新区域。
“根据草图添加蒙版”是指:将绘制的新区域添加到蒙版中。
这里就不展开详述了。现在蒙版已经很满意了。
第 4 步:将蒙版发送至重绘
可以在Inpaint Anything扩展中重绘,但更推荐将蒙版发送到图生图页面进行重绘。
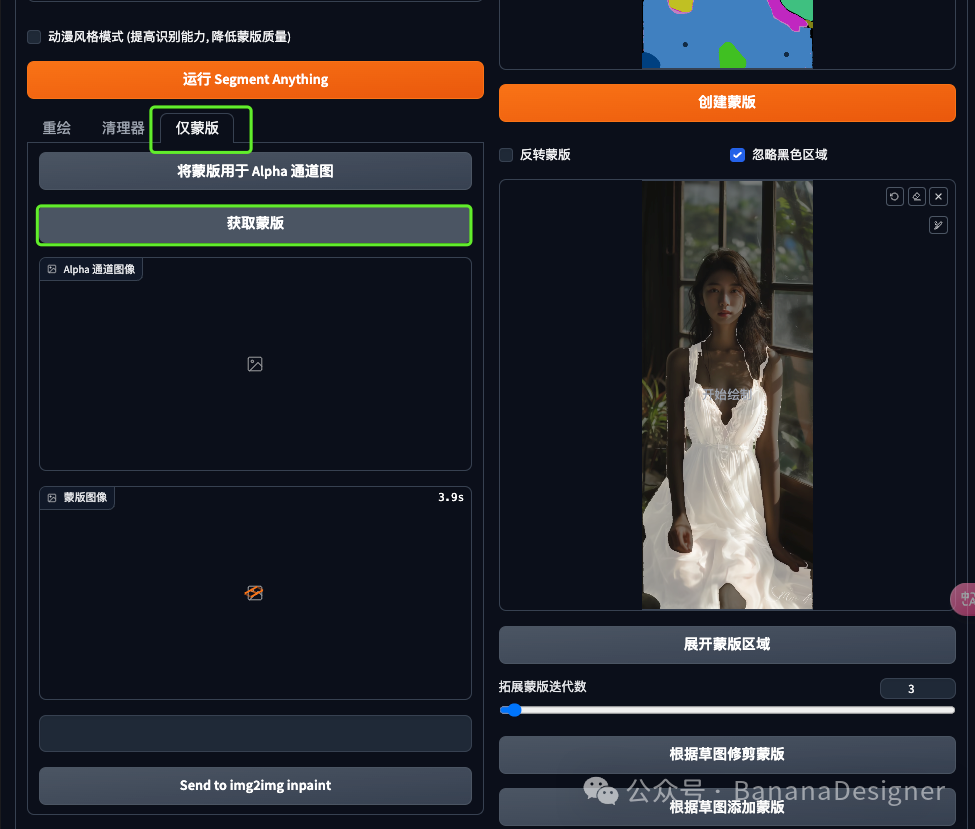
点击“仅蒙版”这个标签页,然后点击获取蒙版,就会获得如下一张黑白的蒙版页面,如果你有Photoshop使用经验的话,这个蒙版和PS中的蒙版是一样的。
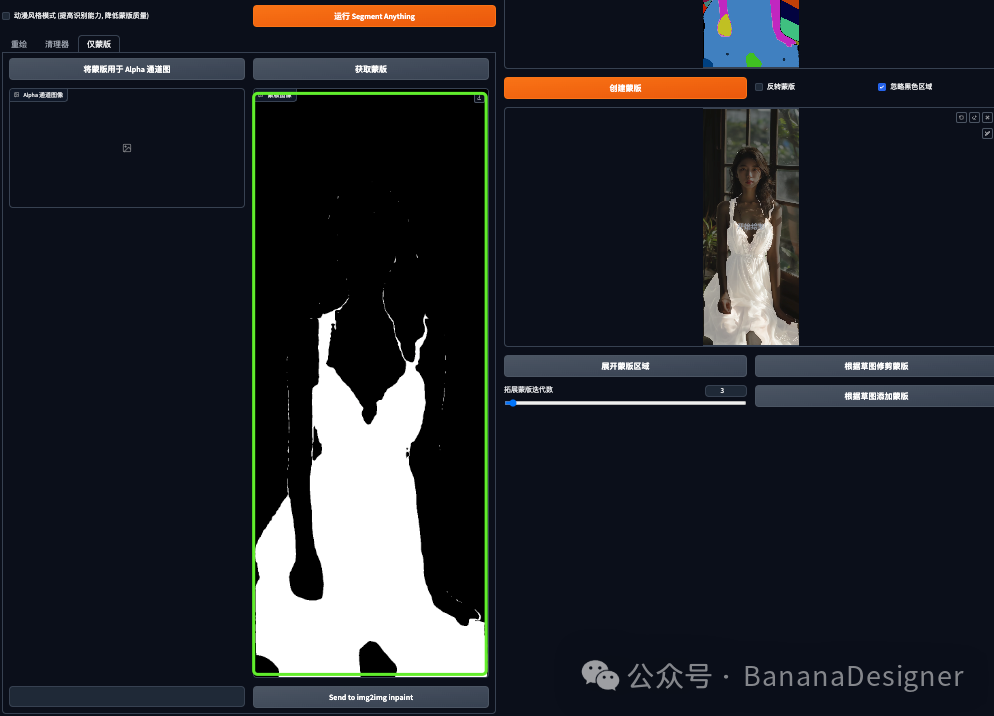
点击“发送到图生图”按钮

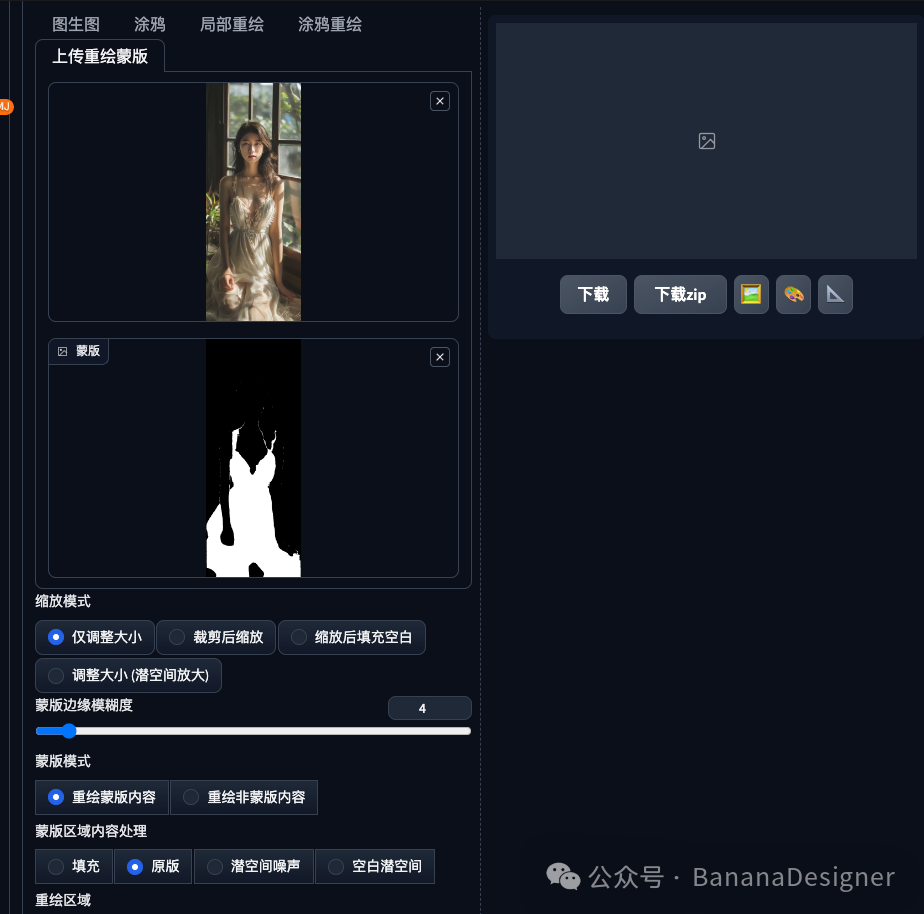
返回到图生图的标签页下,我们就能看到如下的图片和蒙版出现在“上传重绘模版”的标签下。
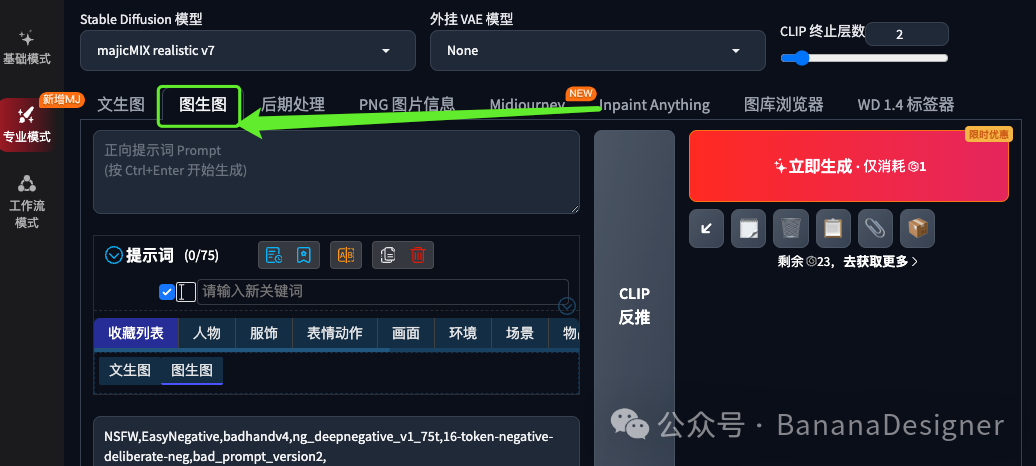
点击“自动检测尺寸”的按钮,将重绘的图片尺寸自动改为输入蒙版的尺寸:
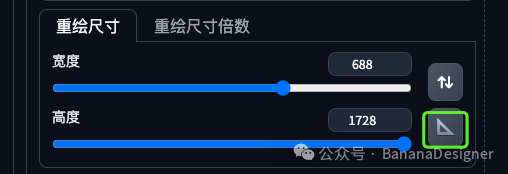
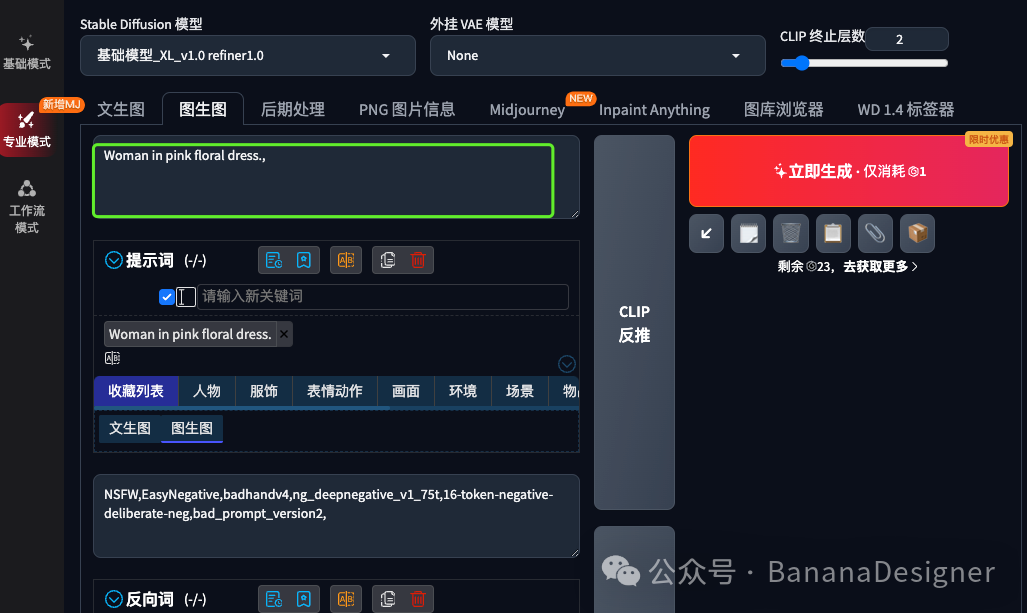
然后选择你喜欢的大模型,最好是真实系的大模型,我这里以<基础模型_ XL_v1.0 refiner 1.0>为例。
在提示词中输入:
Woman in pink floral dress.
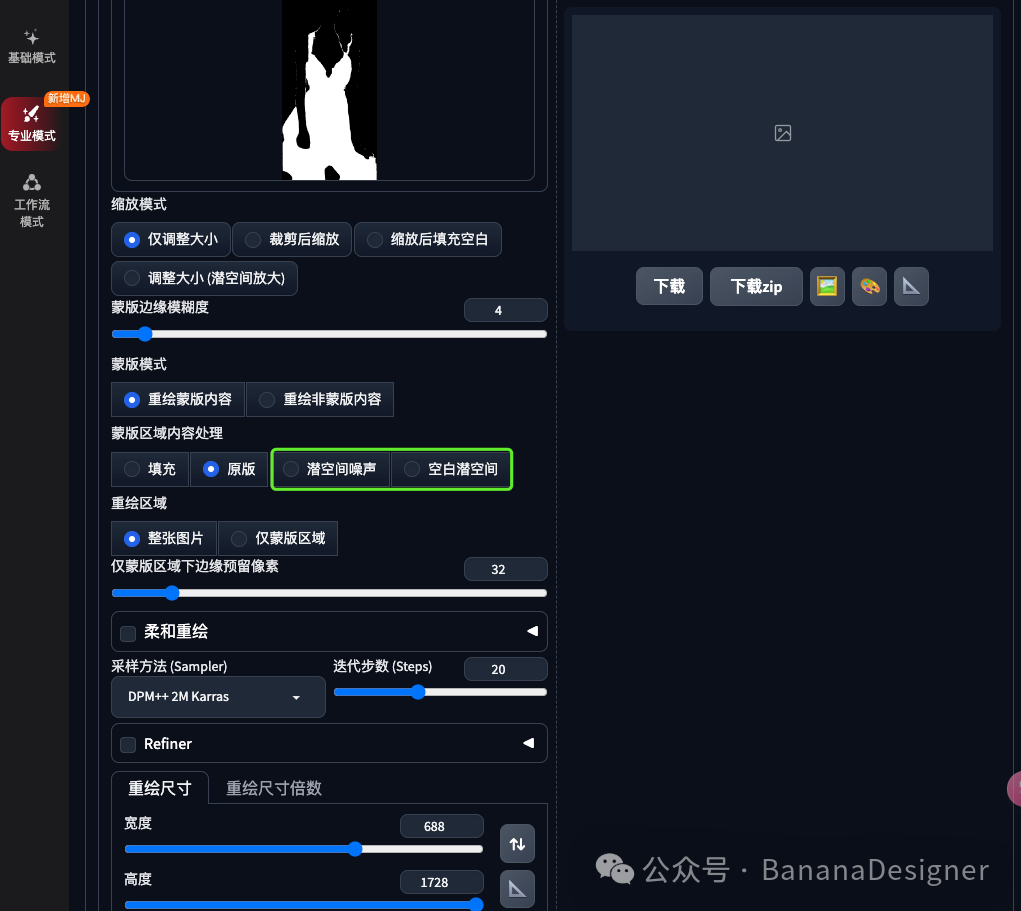
蒙版内容处理选择:潜空间噪声或者空白潜空间,其他项保持默认即可。
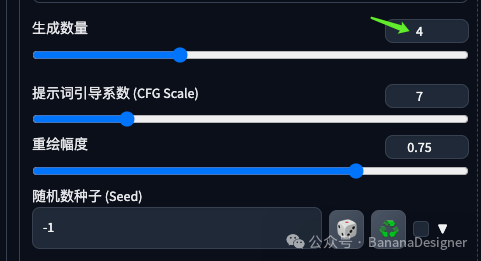
生成数量可以改为一次生成4张。

看一下重绘后的效果,呃。。。。。。虽然是换装了但是也没有全换,别着急,我们可以使用下面的技巧进一步提升图片的质量。
Advanced inpainting techniques
进一步绘制照片
-
方法一 调整重绘照片的尺寸
如果你清楚潜空间扩散原理的话,就会知道我们图像都是缩小到512x512px的更小图去进行加噪和去噪的,如果我们的原图比例很特殊就可能导致画面会出现一些畸变,没关系 我们也不用了解具体的原理,只要尽量让宽或高是512、768、1024 这样的尺寸就好。

重复上面的操作,再来看我们重绘后的照片。


2.方法二 替换大模型
如果图片重绘效果不理想,可以替换掉大模型,使用真实视觉修复模型。
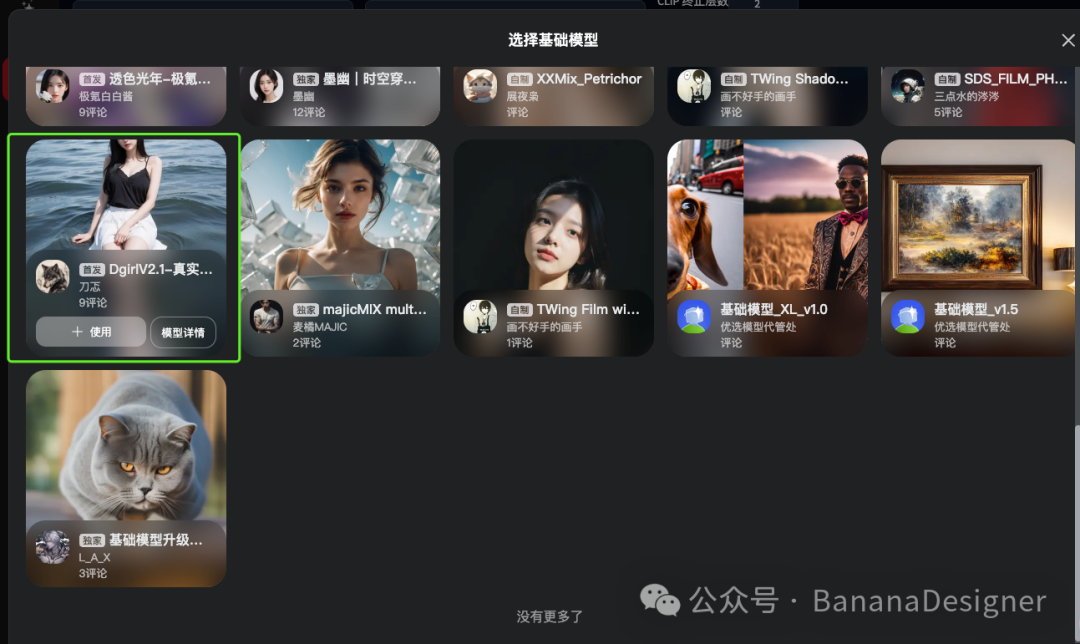
我们将基础大模型换成了其他的真实系模型。比如:麦橘、DreamShaper等。



3.方法三 自定义服装的图案
使用ControlNet IP-Adapter 换上你喜欢的图案。

我需要用到两个控制网络,
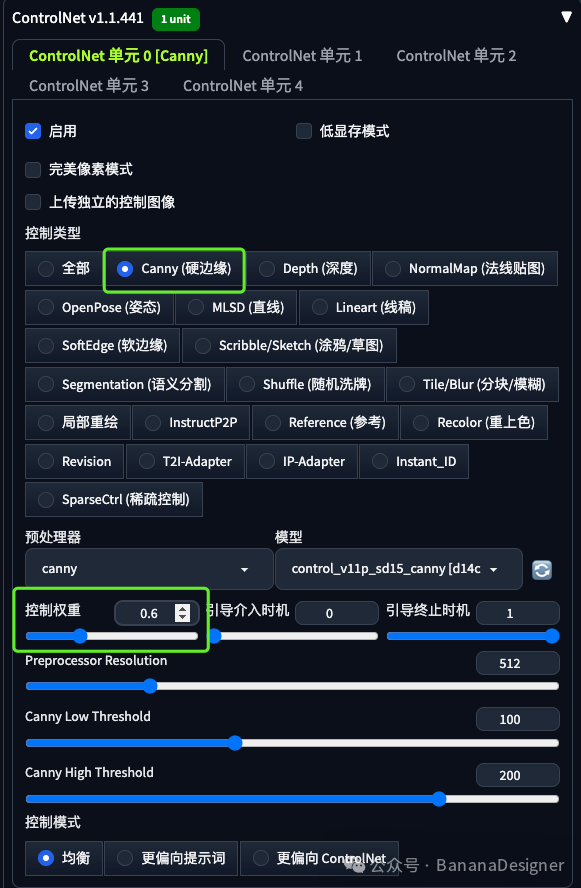
第一个使用Canny
启用:✅
预处理器:Canny 硬边缘
模型:control_v11p_sd15_canny [d14c016b]
控制权重:0.6
第二个使用IP-adapter
启用:✅
预处理器:ip-adapter
模型:ip-adapter_sd15_plus [32cd8f7f]
控制权重:0.9
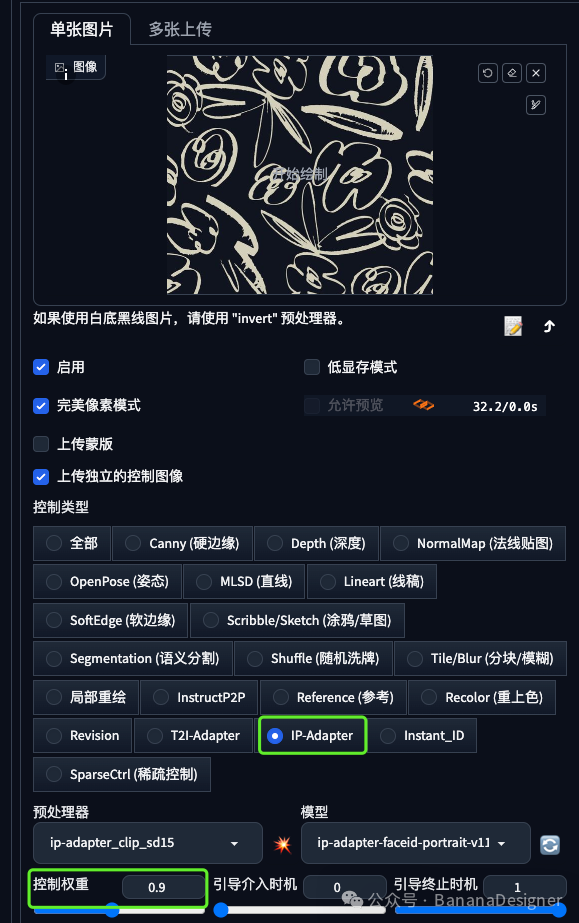
然后点击生成按钮。

还可以将您想要的衣服的精确图像放入 IP adapter 的图像控制窗中,如图

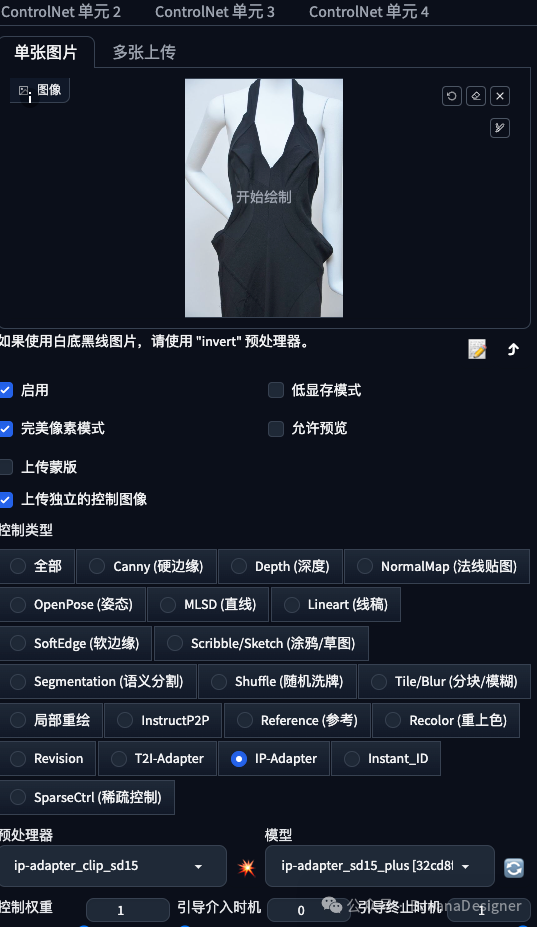

如有侵权,请联系删除。
写在最后
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2405
2405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









