







1.边界检测示例
假如你有一张如下的图像,你想让计算机搞清楚图像上有什么物体,你可以做的事情是检测图像的垂直边缘和水平边缘。
如下是一个6*6的灰度图像,构造一个3*3的矩阵,在卷积神经网络中通常称之为filter,对这个6*6的图像进行卷积运算,以左上角的-5计算为例
3*1+0*0+1*-1+1*1+5*0+8*-1+2*1+7*0+2*-1 = -5
其它的以此类推,让过滤器在图像上逐步滑动,对整个图像进行卷积计算得到一幅4*4的图像。
为什么这种卷积计算可以得到图像的边缘,下图0表示图像暗色区域,10为图像比较亮的区域,同样用一个3*3过滤器,对图像进行卷积,得到的图像中间亮,两边暗,亮色区域就对应图像边缘。
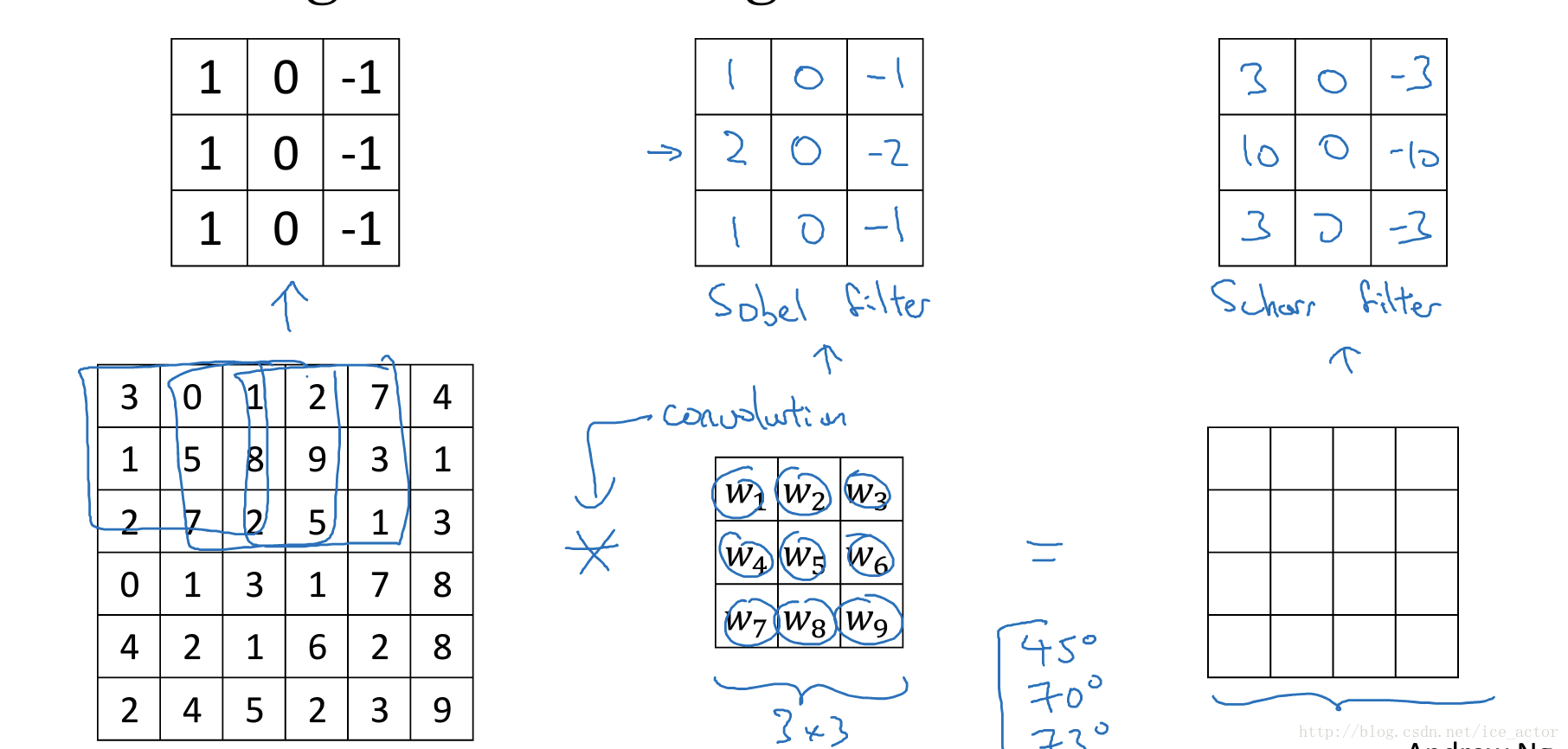
通过以下的水平过滤器和垂直过滤器,可以实现图像水平和垂直边缘检测。
以下列出了一些常用的过滤器,对于不同的过滤器也有着不同的争论,在卷积神经网络中把这些过滤器当成我们要学习的参数,卷积神经网络训练的目标就是去理解过滤器的参数。
2. padding
在上部分中,通过一个3*3的过滤器来对6*6的图像进行卷积,得到了一幅4*4的图像,假设输出图像大小为n*n与过滤器大小为f*f,输出图像大小则为
(n−f+1)∗(n−f+1)
(
n
−
f
+
1
)
∗
(
n
−
f
+
1
)
。
这样做卷积运算的缺点是,卷积图像的大小会不断缩小,另外图像的左上角的元素只被一个输出所使用,所以在图像边缘的像素在输出中采用较少,也就意味着你丢掉了很多图像边缘的信息,为了解决这两个问题,就引入了padding操作,也就是在图像卷积操作之前,沿着图像边缘用0进行图像填充。对于3*3的过滤器,我们填充宽度为1时,就可以保证输出图像和输入图像一样大。
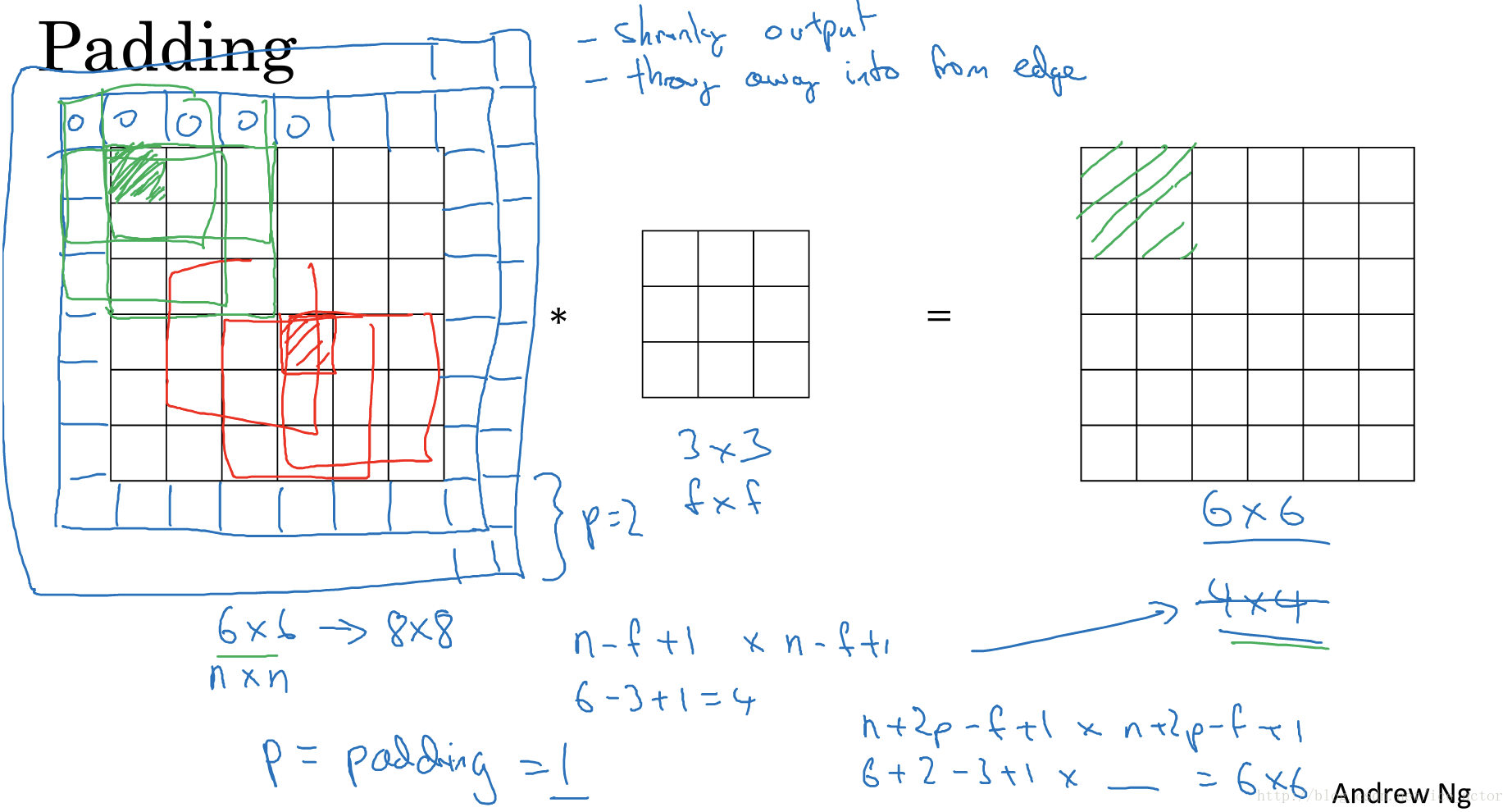
padding的两种模式:
Valid:no padding
输入图像n*n,过滤器f*f,输出图像大小为:
(n−f+1)∗(n−f+1)
(
n
−
f
+
1
)
∗
(
n
−
f
+
1
)
Same:输出图像和输入图像一样大
3.卷积步长
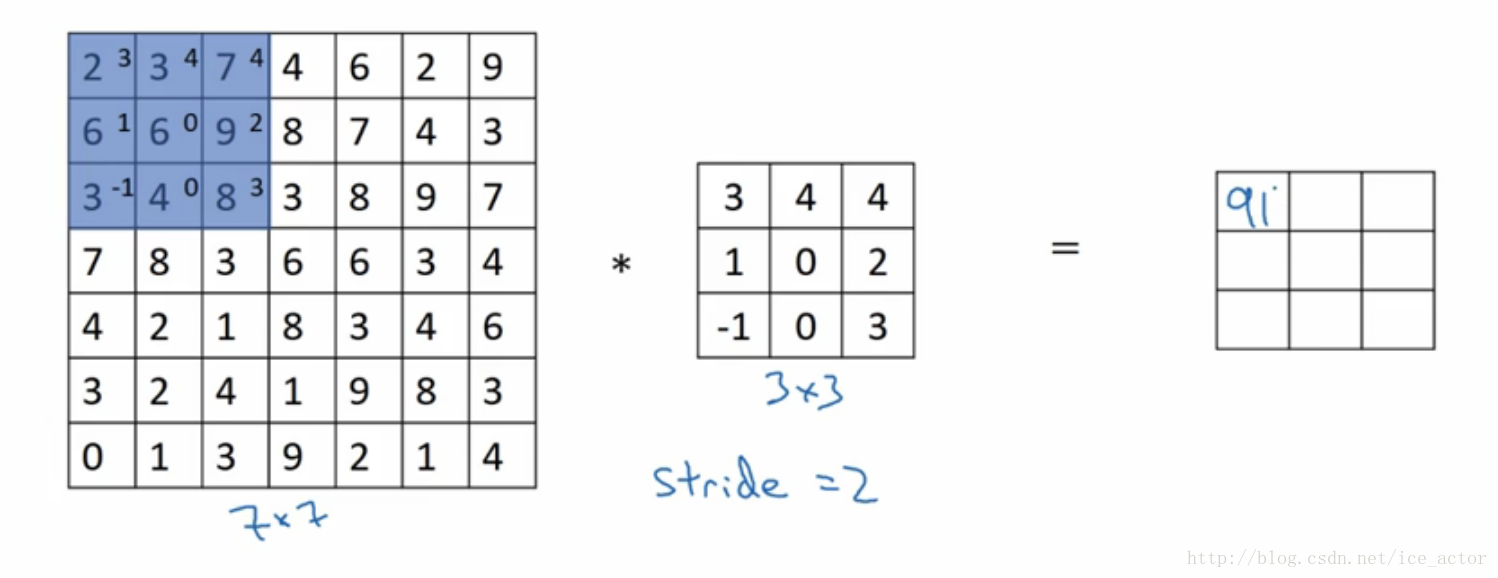
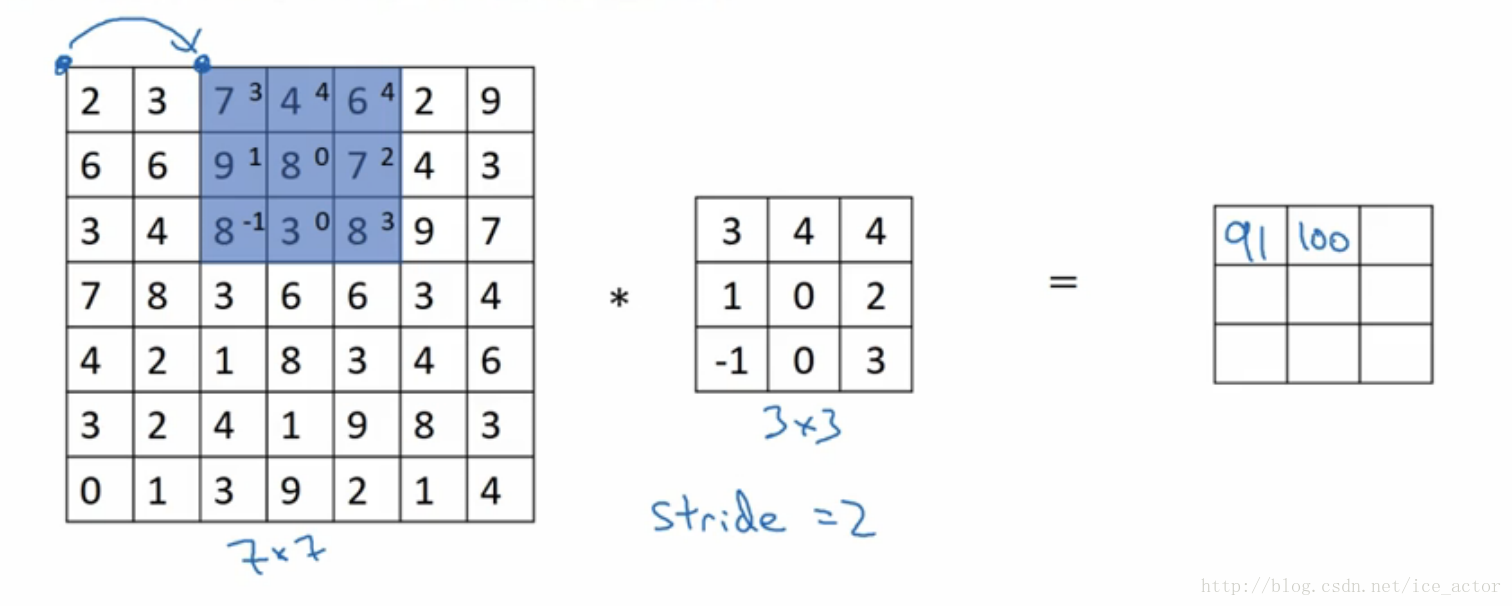
卷积步长是指过滤器在图像上滑动的距离,前两部分步长都默认为1,如果卷积步长为2,卷积运算过程为:
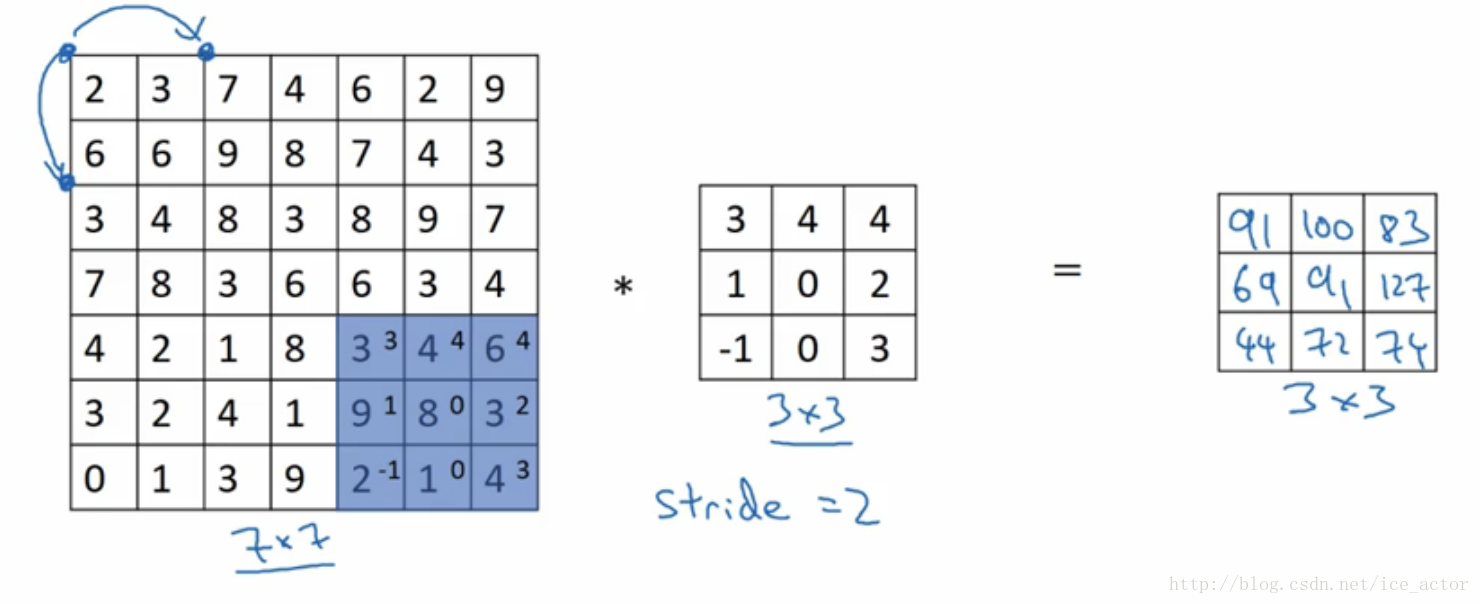
加入stride后卷积图像大小的通用计算公式为:
输入图像:n*n,过滤器:f*f步长:s,padding:p
输出图像大小为:
⌊(n+2p−fs+1))⌋∗⌊(n+2p−fs+1)⌋
⌊
(
n
+
2
p
−
f
s
+
1
)
)
⌋
∗
⌊
(
n
+
2
p
−
f
s
+
1
)
⌋
,
⌊⌋
⌊
⌋
表示向下取整
以输入图像7*7,过滤器3*3,步长为2,padding模式为valid为例输出图像大小为: ⌊(7+2∗0−32+1)⌋∗⌊7+2∗0−32+1)⌋=3∗3 ⌊ ( 7 + 2 ∗ 0 − 3 2 + 1 ) ⌋ ∗ ⌊ 7 + 2 ∗ 0 − 3 2 + 1 ) ⌋ = 3 ∗ 3
4.彩色图像的卷积
以上讲述的卷积都是灰度图像的,如果想要在RGB图像上进行卷积,过滤器的大小不在是3*3而是有3*3*3,最后的3对应为通道数(channels),卷积生成图像中每个像素值为3*3*3过滤器对应位置和图像对应位置相乘累加,过滤器依次在RGB图像上滑动,最终生成图像大小为4*4。
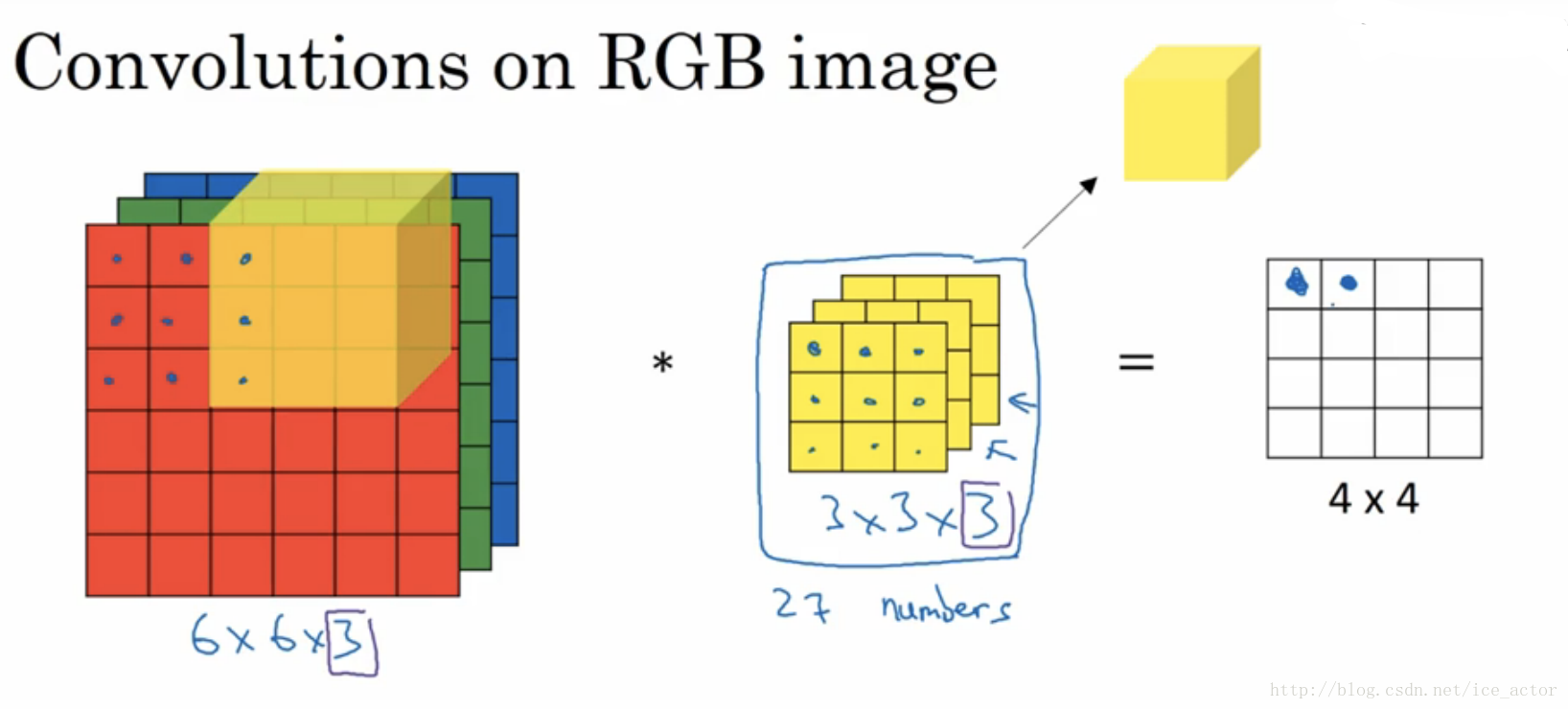
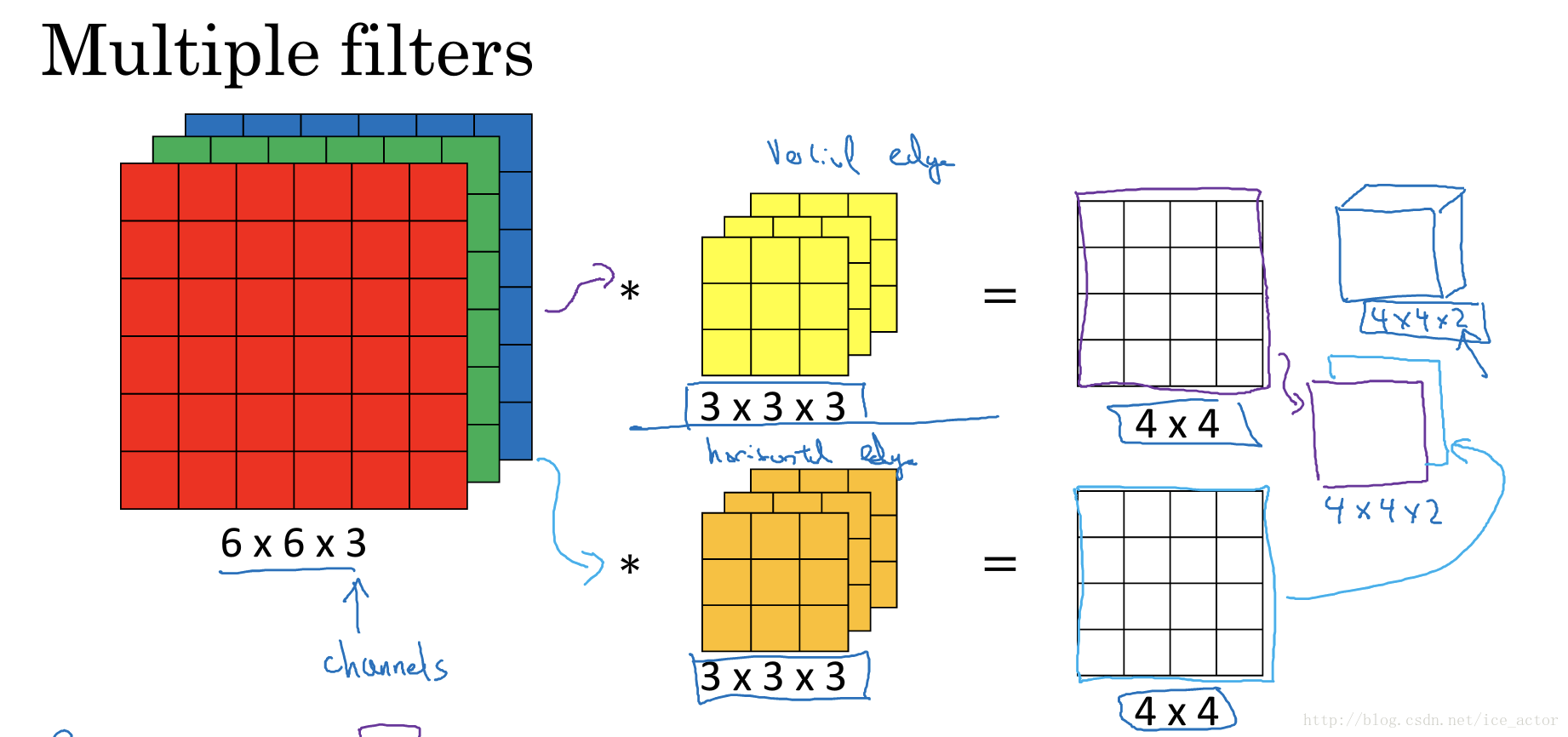
另外一个问题是,如果我们在不仅仅在图像总检测一种类型的特征,而是要同时检测垂直边缘、水平边缘、45度边缘等等,也就是多个过滤器的问题。如果有两个过滤器,最终生成图像为4*4*2的立方体,这里的2来源于我们采用了两个过滤器。如果有10个过滤器那么输出图像就是4*4*10的立方体。
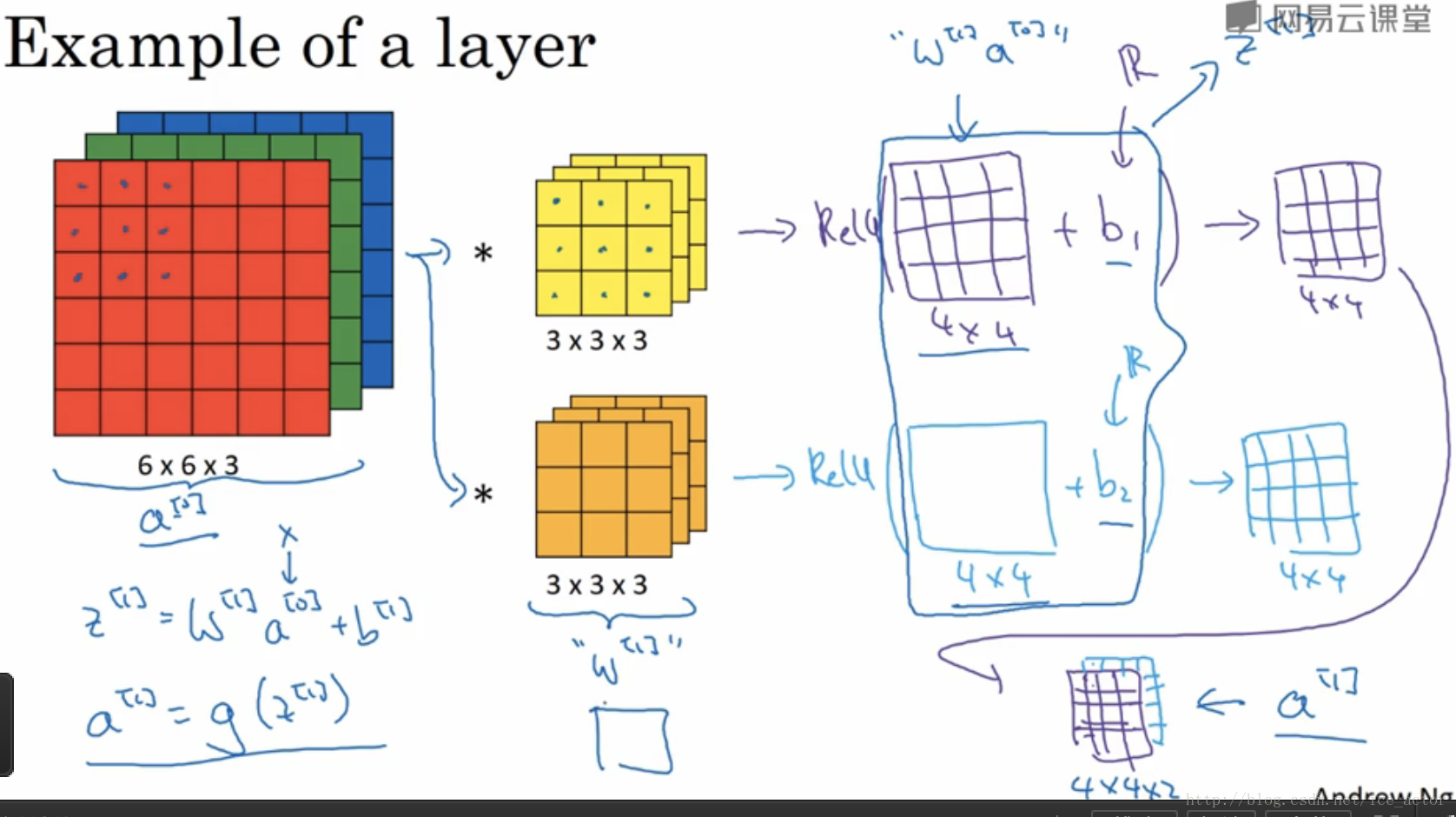
5.单层卷积网络
通过上一节的讲述,图像通过两个过滤器得到了两个4*4的矩阵,在两个矩阵上分别加入偏差
b1
b
1
和
b2
b
2
,然后对加入偏差的矩阵做非线性的Relu变换,得到一个新的4*4矩阵,这就是单层卷积网络的完整计算过程。用公式表示:
其中输入图像为 a[0] a [ 0 ] ,过滤器用 w[1] w [ 1 ] 表示,对图像进行线性变化并加入偏差得到矩阵 z[1] z [ 1 ] , a[1] a [ 1 ] 是应用Relu激活后的结果。
- 如果有10个过滤器参数个数有多少个呢?
每个过滤器都有3*3*3+1=28个参数,3*3*3为过滤器大小,1是偏差系数,10个过滤器参数个数就是28*10=280个。不论输入图像大小参数个数是不会发生改变的。 - 描述卷积神经网络的一些符号标识:
l l 为一个卷积层:
:第 l l 层过滤器的大小
:第 l l 层padding的数量
:第 l l 层步长大小
:过滤器的个数
Input:
nl−1H×nl−1W×nl−1C n H l − 1 × n W l − 1 × n C l − 1 : l−1 l − 1 层输入图像的高、宽以及通道数。
Output:
nlH×nlW×nlC n H l × n W l × n C l :输出图像的高、宽以及通道数
输出图像的大小:
nlH=⌊nl−1H+2∗pl−f[l]sl+1⌋ n H l = ⌊ n H l − 1 + 2 ∗ p l − f [ l ] s l + 1 ⌋
nlW=⌊nl−1W+2∗pl−f[l]sl+1⌋ n W l = ⌊ n W l − 1 + 2 ∗ p l − f [ l ] s l + 1 ⌋
输出图像的通道数就是过滤器的个数

6.简单卷积网络示例
- 输入图像:39*39*3,符号表示: n[0]H=n[0]W=39 n H [ 0 ] = n W [ 0 ] = 39 ;n[0]c=3 ; n c [ 0 ] = 3
- 第1层超参数: f[l]=3 f [ l ] = 3 (过滤器大小); s[l]=1 s [ l ] = 1 (步长); p[l]=0 p [ l ] = 0 (padding大小); n[l]C=10 n C [ l ] = 10 (过滤器个数)
- 第1层输出图像:37*37*10,符号表示: n[1]H=n[1]W=37 n H [ 1 ] = n W [ 1 ] = 37 ;n[1]c=10 ; n c [ 1 ] = 10
- 第2层超参数: f[2]=5 f [ 2 ] = 5 ; s[2]=2 s [ 2 ] = 2 ; p[2]=0 p [ 2 ] = 0 ; n[2]C=20 n C [ 2 ] = 20
- 第2层输出图像:17*17*20,符号表示: n[2]H=n[2]W=17 n H [ 2 ] = n W [ 2 ] = 17 ;n[2]c=20 ; n c [ 2 ] = 20
- 第3层超参数: f[3]=5 f [ 3 ] = 5 ; s[3]=2 s [ 3 ] = 2 ; p[2]=0 p [ 2 ] = 0 ; n[3]C=40 n C [ 3 ] = 40
- 第3层输出图像:7*7*40,符号表示: n[3]H=n[3]W=17 n H [ 3 ] = n W [ 3 ] = 17 ;n[3]c=40 ; n c [ 3 ] = 40
- 将第三层的输出展开成1960个元素
- 然后将其输出到logistic或softmax来决定是判断图片中有没有猫,还是想识别图像中K中不同的对象
卷积神经网络层的类型: - 卷积层(convolution,conv)
- 池化层(pooling,pool)
- 全连接层(Fully connected,FC)

7.池化层
最大池化(Max pooling)
最大池化思想很简单,以下图为例,把4*4的图像分割成4个不同的区域,然后输出每个区域的最大值,这就是最大池化所做的事情。其实这里我们选择了2*2的过滤器,步长为2。在一幅真正的图像中提取最大值可能意味着提取了某些特定特征,比如垂直边缘、一只眼睛等等。
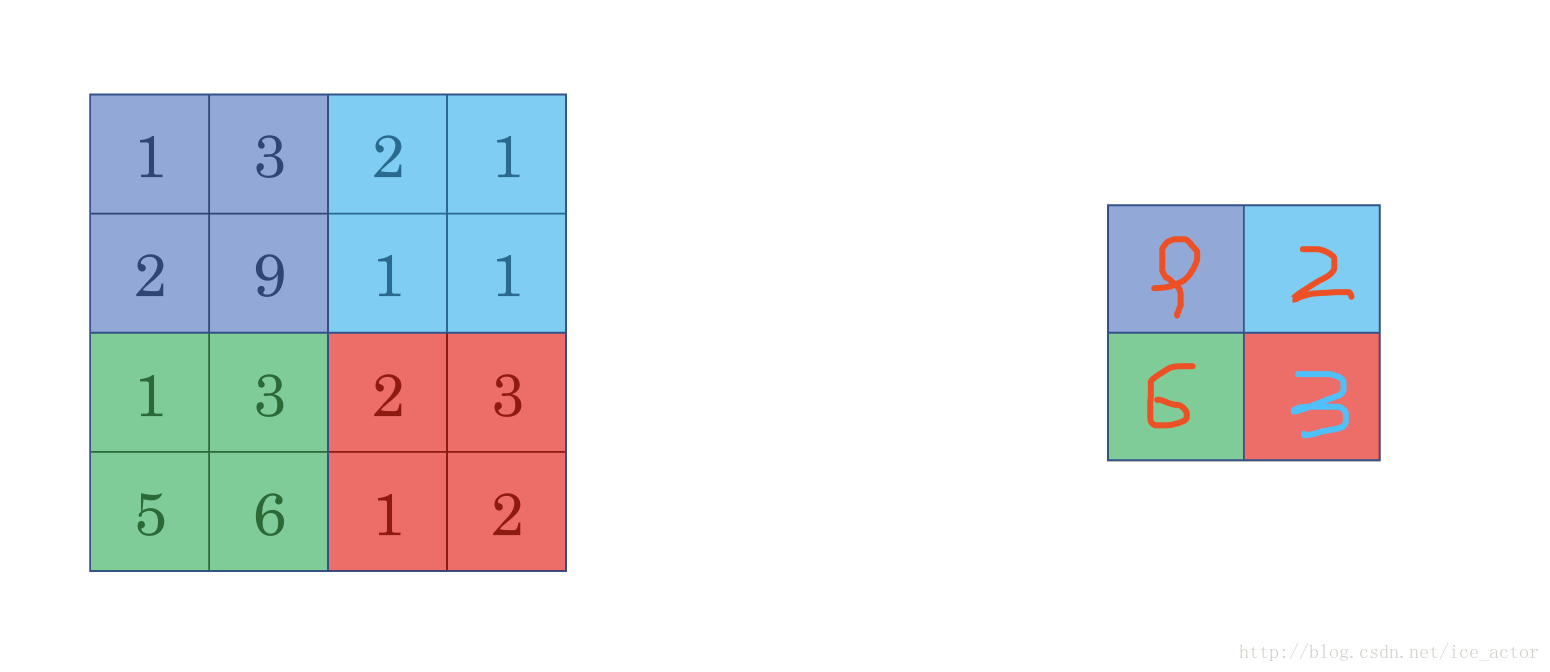
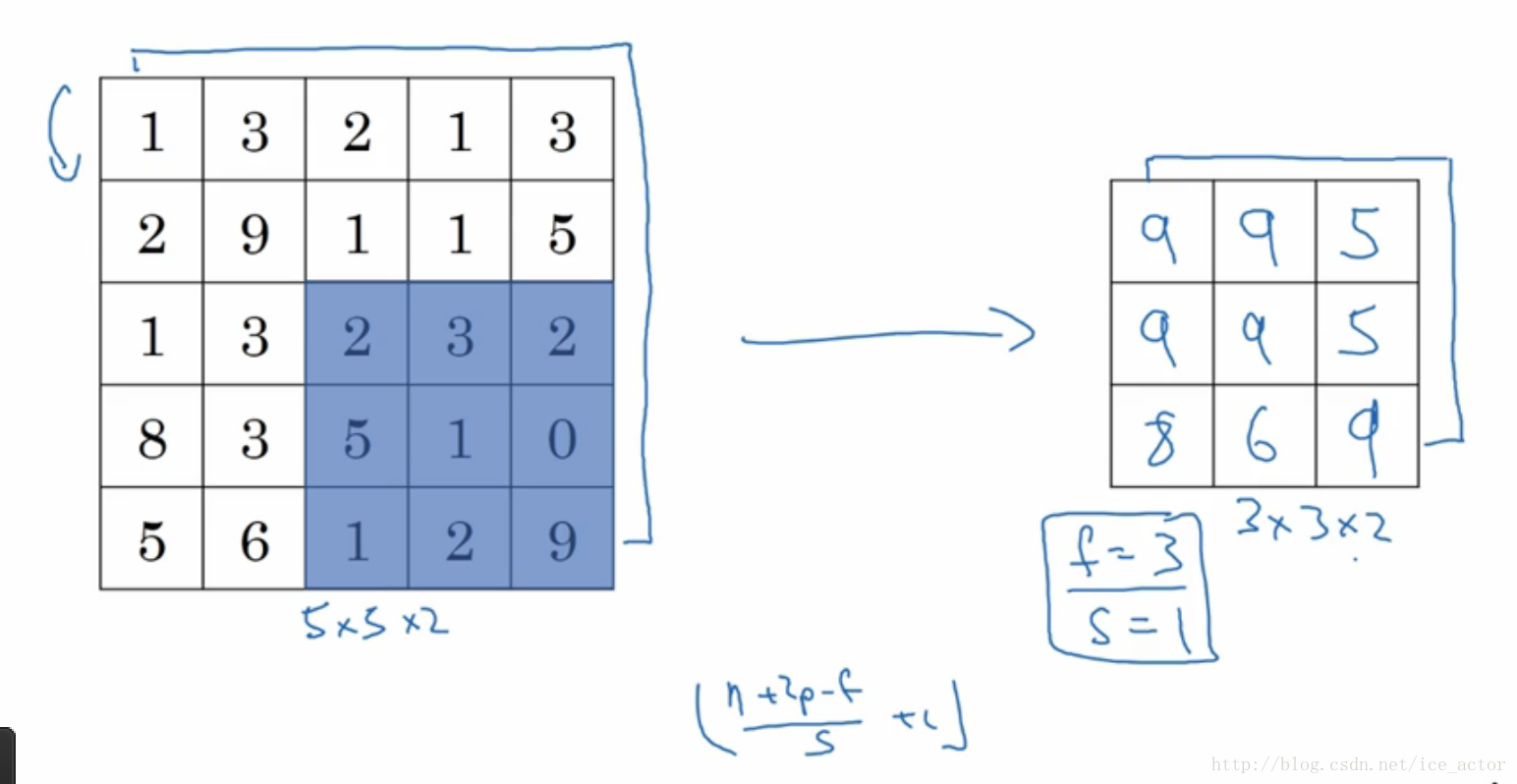
以下是一个过滤器大小为3*3,步长为1的池化过程,具体计算和上面相同,最大池化中输出图像的大小计算方式和卷积网络中计算方法一致,如果有多个通道需要做池化操作,那么就分通道计算池化操作。
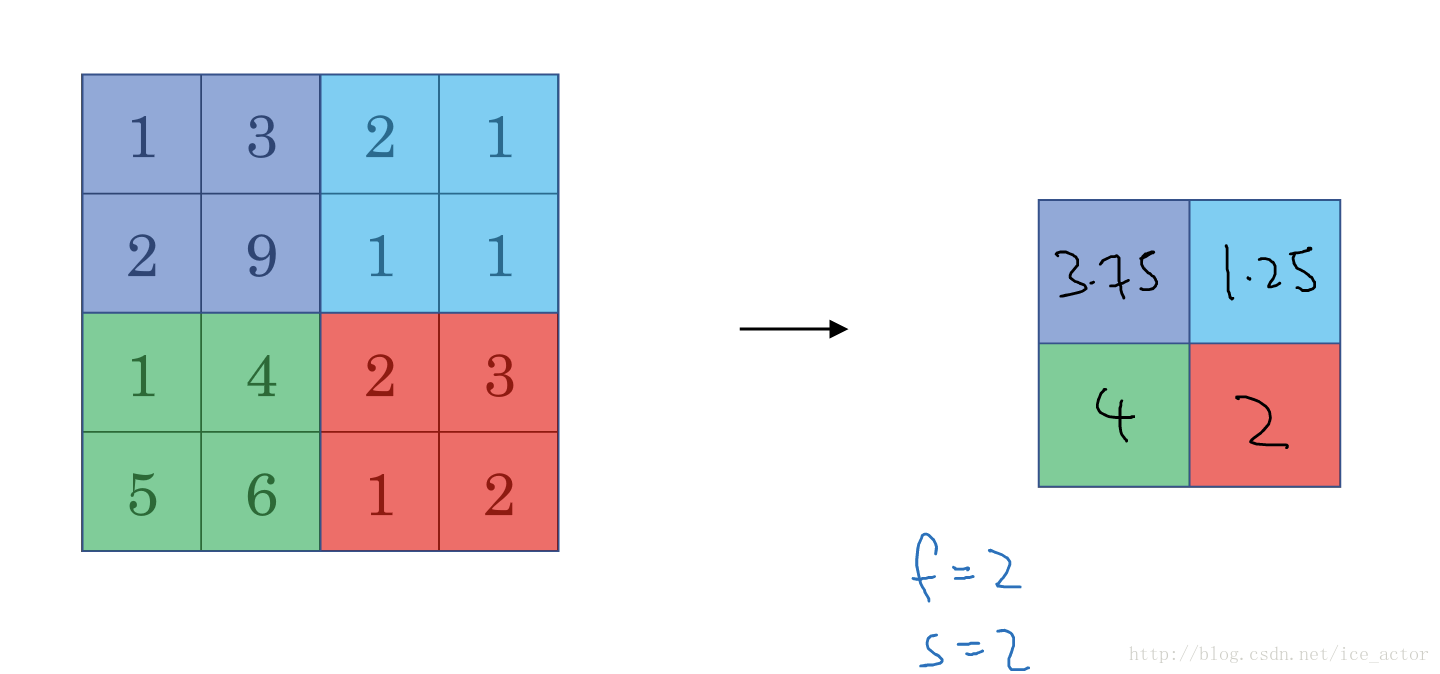
平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化。
池化的超参数:步长、过滤器大小、池化类型最大池化or平均池化
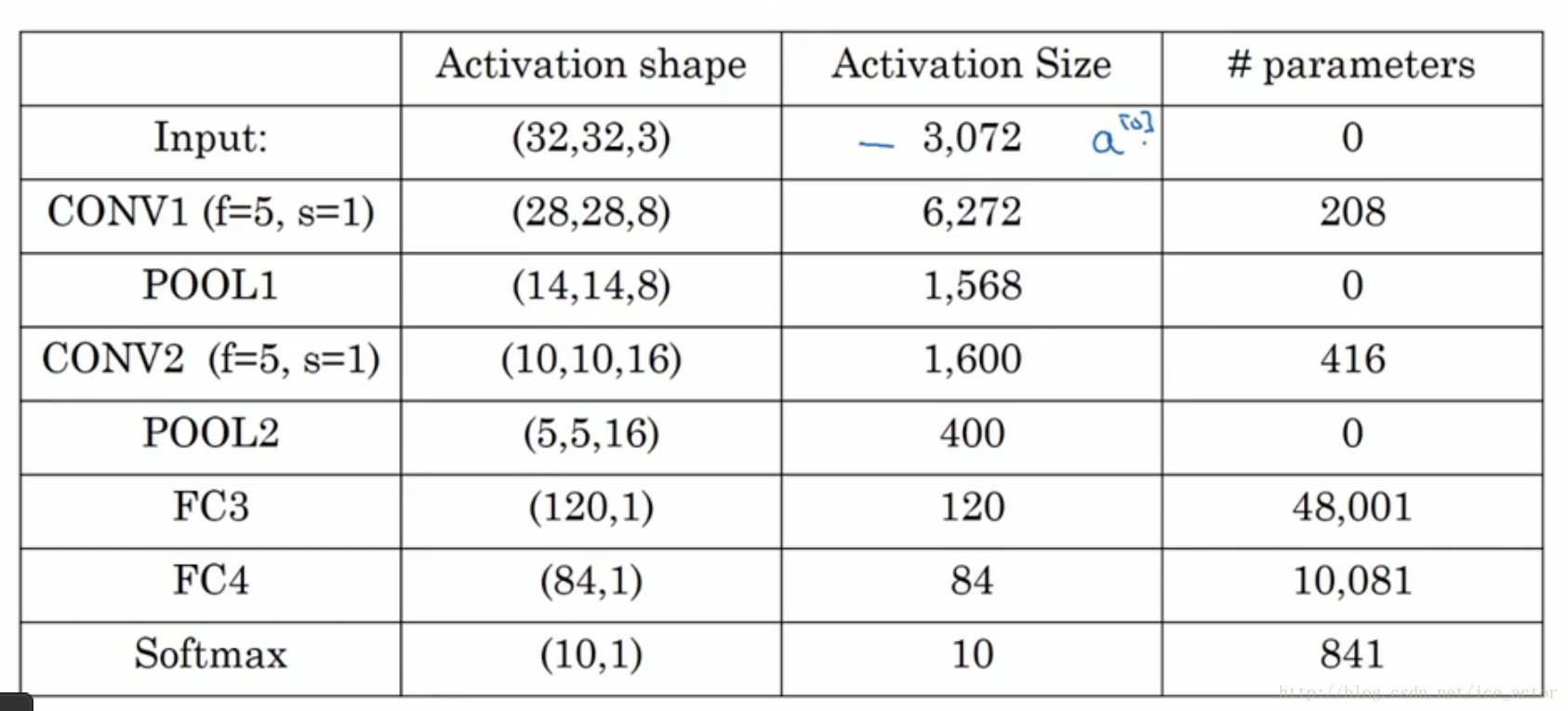
8.卷积神经网络示例
以下是一个完整的卷积神经网络,用于手写字识别,这并不是一个LeNet-5网络,但是设计令该来自于LeNet-5。
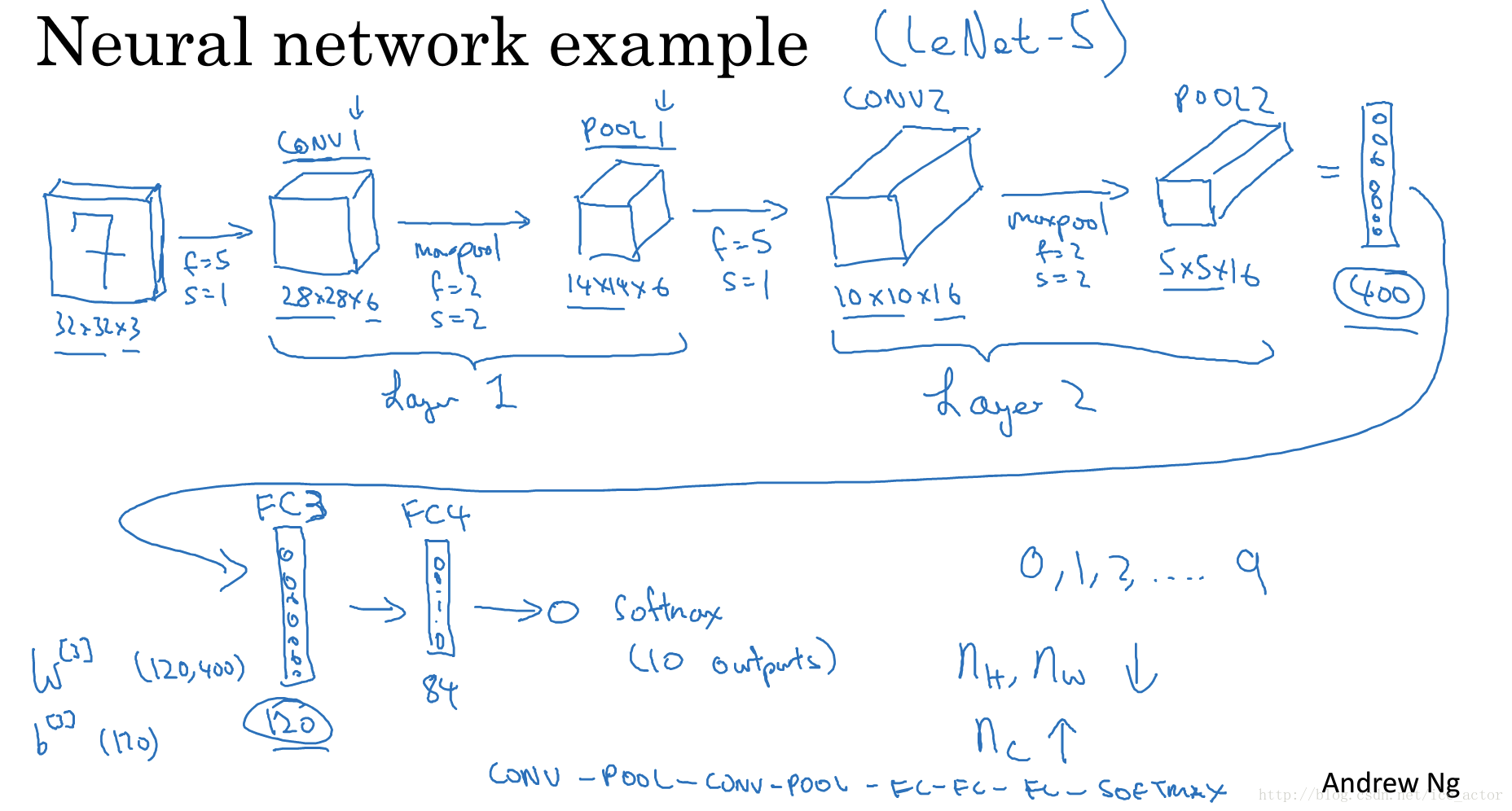
网络各层参数个数表:

















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









