







PRML_Exercises
Pattern Recognition and Machine Learning习题中文详解
欢迎讨论题目(我把自己做的过程贴出来也是为了更方便讨论),禁止一切形式的转载。
关于排版,实话说我也想把公式排得舒服好看一些,奈何着实费力,这着实不太讨喜,见谅。
Chapter 1
1.1
能够使得式(1.2)给出的误差函数最小的参数
w
=
{
w
i
}
\mathbf{w}=\{w_i\}
w={wi}就是使得误差为
0
0
0的参数,那么就满足
∑
j
=
0
M
w
j
x
n
j
=
t
n
\sum_{j=0}^{M}w_jx_n^j=t_n
j=0∑Mwjxnj=tn
而我们要做的这道证明题的右式
T
i
=
∑
n
=
1
N
(
x
n
)
i
t
n
T_i=\sum_{n=1}^{N}(x_n)^it_n
Ti=n=1∑N(xn)itn
直接将上述我们已知的
t
n
t_n
tn代入,得
T
i
=
∑
n
=
1
N
[
(
x
n
)
i
∑
j
=
0
M
w
j
(
x
n
)
j
]
T_i=\sum_{n=1}^N[(x_n)^i\sum_{j=0}^{M}w_j(x_n)^j]
Ti=n=1∑N[(xn)ij=0∑Mwj(xn)j]
又由于
(
x
n
)
i
(x_n)^i
(xn)i不含有与
j
j
j相关的系数,所以可以将其放入后面的求和项,即
T
i
=
∑
n
=
1
N
∑
j
=
0
M
(
x
n
)
i
w
j
(
x
n
)
j
T_i=\sum_{n=1}^N\sum_{j=0}^{M}(x_n)^iw_j(x_n)^j
Ti=n=1∑Nj=0∑M(xn)iwj(xn)j
再互换一下求和顺序
T
i
=
∑
j
=
0
M
∑
n
=
1
N
(
x
n
)
i
w
j
x
n
j
=
∑
j
=
0
M
∑
n
=
1
N
(
x
n
)
i
+
j
w
j
T_i=\sum_{j=0}^{M}\sum_{n=1}^N(x_n)^iw_jx_n^j=\sum_{j=0}^{M}\sum_{n=1}^N(x_n)^{i+j}w_j
Ti=j=0∑Mn=1∑N(xn)iwjxnj=j=0∑Mn=1∑N(xn)i+jwj
其中就可以看到
∑
n
=
1
N
(
x
n
)
i
+
j
\sum_{n=1}^N(x_n)^{i+j}
∑n=1N(xn)i+j就是题目中的
A
i
j
A_{ij}
Aij了,从而得证。
1.2
已知
E
~
(
w
)
=
1
2
∑
n
=
1
N
{
y
(
x
n
,
w
)
−
t
n
}
2
+
λ
2
∥
w
∥
2
\widetilde{E}(\mathbf{w})=\frac{1}{2} \sum_{n=1}^{N}\left\{y\left(x_{n}, \mathbf{w}\right)-t_{n}\right\}^{2}+\frac{\lambda}{2}\|\mathbf{w}\|^{2}
E
(w)=21n=1∑N{y(xn,w)−tn}2+2λ∥w∥2
其中
∥
w
∥
2
≡
w
T
w
=
w
0
2
+
w
1
2
+
…
+
w
M
2
\|\mathbf{w}\|^{2} \equiv \mathbf{w}^{\mathrm{T}} \mathbf{w}=w_{0}^{2}+w_{1}^{2}+\ldots+w_{M}^{2}
∥w∥2≡wTw=w02+w12+…+wM2,这里提一下正则项里面的
w
0
2
w_0^2
w02,作者说通常来讲这一项要么不放正则项中,要么使用另一个
λ
\lambda
λ对其进行大小控制,不过咱们这里为了公式的推导方便就不做特殊处理,且让它在这个正则项中。既然题目中要求这个误差函数
E
~
(
w
)
\widetilde{E}(\mathbf{w})
E
(w)最小化,也就意味着该式对各个参数
w
w
w的导数均为
0
0
0,由此可得:
d
E
~
(
w
)
d
w
i
=
1
2
∑
n
=
1
N
{
2
[
∑
j
=
0
M
w
j
(
x
n
)
j
−
t
n
]
(
x
n
)
i
}
+
λ
w
i
=
0
\frac{\mathrm{d}\widetilde{E}(\mathbf{w})}{\mathrm{d}w_i}=\frac{1}{2}\sum_{n=1}^{N}\{2[\sum_{j=0}^{M}w_j(x_n)^j-t_n](x_n)^i\}+\lambda w_i=0
dwidE
(w)=21n=1∑N{2[j=0∑Mwj(xn)j−tn](xn)i}+λwi=0
所以
∑
n
=
1
N
{
∑
j
=
0
M
[
(
x
n
)
i
+
j
w
j
]
−
(
x
n
)
i
t
n
]
}
+
λ
w
i
=
∑
n
=
1
N
∑
j
=
0
M
{
(
x
n
)
i
+
j
w
j
}
−
∑
n
=
1
N
{
(
x
n
)
i
t
n
+
λ
w
i
N
}
=
0
\sum_{n=1}^{N}\{\sum_{j=0}^{M}[(x_n)^{i+j}w_j]-(x_n)^it_n]\}+\lambda w_i=\sum_{n=1}^{N}\sum_{j=0}^{M}\{(x_n)^{i+j}w_j\}-\sum_{n=1}^{N}\{(x_n)^{i}t_n+\frac{\lambda w_i}{N}\}=0
n=1∑N{j=0∑M[(xn)i+jwj]−(xn)itn]}+λwi=n=1∑Nj=0∑M{(xn)i+jwj}−n=1∑N{(xn)itn+Nλwi}=0
所以可以看到,题目1.1中的式子基本都可以保持不变,只需将
T
i
T_i
Ti修改为
T
i
=
∑
n
=
1
N
{
(
x
n
)
i
t
n
+
λ
w
i
N
}
T_i=\sum_{n=1}^{N}\{(x_n)^{i}t_n+\frac{\lambda w_i}{N}\}
Ti=∑n=1N{(xn)itn+Nλwi}。
Tips:上面求导的过程使用了复合函数的求导。
1.3
已知
p
(
B
=
r
)
=
0.2
p(B=r)=0.2
p(B=r)=0.2,
p
(
B
=
b
)
=
0.2
p(B=b)=0.2
p(B=b)=0.2,
p
(
B
=
g
)
=
0.6
p(B=g)=0.6
p(B=g)=0.6,同时,
p
(
F
=
a
∣
B
=
r
)
=
0.3
p(F=a|B=r)=0.3
p(F=a∣B=r)=0.3,
p
(
F
=
o
∣
B
=
r
)
=
0.4
p(F=o|B=r)=0.4
p(F=o∣B=r)=0.4,
p
(
F
=
l
∣
B
=
r
)
=
0.3
p(F=l|B=r)=0.3
p(F=l∣B=r)=0.3,
p
(
F
=
a
∣
B
=
b
)
=
0.5
p(F=a|B=b)=0.5
p(F=a∣B=b)=0.5,
p
(
F
=
o
∣
B
=
b
)
=
0.5
p(F=o|B=b)=0.5
p(F=o∣B=b)=0.5,
p
(
F
=
l
∣
B
=
b
)
=
0
p(F=l|B=b)=0
p(F=l∣B=b)=0,
p
(
F
=
a
∣
B
=
g
)
=
0.3
p(F=a|B=g)=0.3
p(F=a∣B=g)=0.3,
p
(
F
=
o
∣
B
=
g
)
=
0.3
p(F=o|B=g)=0.3
p(F=o∣B=g)=0.3,
p
(
F
=
l
∣
B
=
g
)
=
0.4
p(F=l|B=g)=0.4
p(F=l∣B=g)=0.4。第一小问说,抽一次抽出苹果的概率是多少,可通过sum rule和product rule求出,即:
p
(
a
)
=
p
(
a
,
r
)
+
p
(
a
,
b
)
+
p
(
a
,
g
)
=
p
(
a
∣
r
)
p
(
r
)
+
p
(
a
∣
b
)
p
(
b
)
+
p
(
a
∣
g
)
p
(
g
)
=
0.34
p(a)=p(a,r)+p(a,b)+p(a,g)=p(a|r)p(r)+p(a|b)p(b)+p(a|g)p(g)=0.34
p(a)=p(a,r)+p(a,b)+p(a,g)=p(a∣r)p(r)+p(a∣b)p(b)+p(a∣g)p(g)=0.34
第二小问说,在已知抽出的结果是橘子(orange)的情况下,从绿色(green)盒子中抽出这个橘子的概率是多大。这就是一个很典型的由果推因的贝叶斯公式题,相当于求
p
(
B
=
g
∣
F
=
o
)
p(B=g|F=o)
p(B=g∣F=o),根据贝叶斯公式,可得
p
(
g
∣
o
)
=
p
(
o
∣
g
)
p
(
g
)
p
(
o
)
p(g|o)=\frac{p(o|g)p(g)}{p(o)}
p(g∣o)=p(o)p(o∣g)p(g),其中分母可以按照第一小问的方式求出,分子中各项均为已知条件,求得
p
(
B
=
g
∣
F
=
o
)
=
0.5
p(B=g|F=o)=0.5
p(B=g∣F=o)=0.5。
1.4
已知 x = g ( y ) x=g(y) x=g(y), p y ( y ) = p x ( x ) ∣ d x d y ∣ = p x ( x ) ∣ g ′ ( y ) ∣ p_y(y)=p_x(x)|\frac{\mathrm{d}x}{\mathrm{d}y}|=p_x(x)|g^{\prime}(y)| py(y)=px(x)∣dydx∣=px(x)∣g′(y)∣,对于两个概率分布而言,能够取到最大值的位置满足导数为 0 0 0,因此 ∂ p y ( y ) ∂ y = ∂ p x ( x ) ∣ g ′ ( y ) ∣ ∂ y = 0 \frac{\partial p_y(y)}{\partial y}=\frac{\partial p_x(x)|g^{\prime}(y)|}{\partial y}=0 ∂y∂py(y)=∂y∂px(x)∣g′(y)∣=0,题目中假设 x = g ( y ) x=g(y) x=g(y)为线性函数,因此我们假设 x = g ( y ) = a y + b x=g(y)=ay+b x=g(y)=ay+b,所以可以得到 ∂ p y ( y ) ∂ y = ∂ p x ( x ) ∣ a ∣ ∂ x ∂ x ∂ y = ∂ p x ( x ) ∂ x ∣ a ∣ 2 = 0 \frac{\partial p_y(y)}{\partial y}=\frac{\partial p_x(x)|a|}{\partial x}\frac{\partial x}{\partial y}=\frac{\partial p_x(x)}{\partial x}|a|^2=0 ∂y∂py(y)=∂x∂px(x)∣a∣∂y∂x=∂x∂px(x)∣a∣2=0,由于 ∣ a ∣ 2 > 0 |a|^2 > 0 ∣a∣2>0,( a a a的绝对值不应该为 0 0 0,否则并不能称其为变换了),所以使得 ∂ p x ( x ) ∂ x = 0 \frac{\partial p_x(x)}{\partial x}=0 ∂x∂px(x)=0的情况下, ∂ p y ( y ) ∂ y \frac{\partial p_y(y)}{\partial y} ∂y∂py(y)也等于 0 0 0,也就是说在 x x x取值使得 p x ( x ) p_x(x) px(x)最大的位置,这个 x x x对应的 y y y也是使得 p y ( y ) p_y(y) py(y)最大的位置,而 x = g ( y ) = a y + b x=g(y)=ay+b x=g(y)=ay+b同样满足两变量之间的线性关系。
1.5
式(1.38)为 var [ f ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] \operatorname{var}[f]=\mathbb{E}\left[(f(x)-\mathbb{E}[f(x)])^{2}\right] var[f]=E[(f(x)−E[f(x)])2],因此 var [ f ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] = E [ f ( x ) 2 − 2 f ( x ) E [ f ( x ) ] + ( E [ f ( x ) ] ) 2 ] \operatorname{var}[f]=\mathbb{E}\left[(f(x)-\mathbb{E}[f(x)])^{2}\right]=\mathbb{E}[f(x)^2-2f(x)\mathbb{E}[f(x)]+(\mathbb{E}[f(x)])^2] var[f]=E[(f(x)−E[f(x)])2]=E[f(x)2−2f(x)E[f(x)]+(E[f(x)])2],所以 var [ f ] = E [ f ( x ) 2 ] − 2 ( E [ f ( x ) ] ) 2 + ( E [ f ( x ) ] ) 2 ] = E [ f ( x ) 2 ] − E [ f ( x ) ] 2 \operatorname{var}[f]=\mathbb{E}[f(x)^2]-2(\mathbb{E}[f(x)])^2+(\mathbb{E}[f(x)])^2]=\mathbb{E}\left[f(x)^{2}\right]-\mathbb{E}[f(x)]^{2} var[f]=E[f(x)2]−2(E[f(x)])2+(E[f(x)])2]=E[f(x)2]−E[f(x)]2。
1.6
根据式(1.41)可知, cov [ x , y ] = E x , y [ x y ] − E [ x ] E [ y ] \begin{aligned} \operatorname{cov}[x, y] &=\mathbb{E}_{x, y}[x y]-\mathbb{E}[x] \mathbb{E}[y] \end{aligned} cov[x,y]=Ex,y[xy]−E[x]E[y]。设变量 x x x, y y y独立同分布,对应的分布分别为 p ( x ) p(x) p(x)与 p ( y ) p(y) p(y),则 E x , y [ x y ] = ∬ x y p ( x y ) d x d y = ∬ x y p ( x ) p ( y ) d x d y = ∫ y q ( y ) ∫ x p ( x ) d x d y \mathbb{E}_{x, y}[x y]=\iint xyp(xy)\mathrm{d}x\mathrm{d}y=\iint xyp(x)p(y)\mathrm{d}x\mathrm{d}y= \int yq(y)\int xp(x)\mathrm{d}x\mathrm{d}y Ex,y[xy]=∬xyp(xy)dxdy=∬xyp(x)p(y)dxdy=∫yq(y)∫xp(x)dxdy,由于第二个积分与第一个积分项无关(相互独立,两者之间没有函数关系),因此可以拎出来,得 E x , y [ x y ] = ∫ x p ( x ) d x ∫ y q ( y ) d y = E [ x ] E [ y ] \mathbb{E}_{x, y}[x y]=\int xp(x)\mathrm{d}x\int yq(y)\mathrm{d}y=\mathbb{E}[x]\mathbb{E}[y] Ex,y[xy]=∫xp(x)dx∫yq(y)dy=E[x]E[y],所以在两变量互相独立的情况下, cov [ x , y ] = E x , y [ x y ] − E [ x ] E [ y ] = 0 \begin{aligned} \operatorname{cov}[x, y] &=\mathbb{E}_{x, y}[x y]-\mathbb{E}[x] \mathbb{E}[y] \end{aligned}=0 cov[x,y]=Ex,y[xy]−E[x]E[y]=0。
1.7
令 x = r cos θ x=r \cos \theta x=rcosθ, y = r sin θ y=r\sin \theta y=rsinθ,满足 x 2 + y 2 = r 2 x^2+y^2=r^2 x2+y2=r2且 r ≥ 0 r\ge 0 r≥0,则原来的积分式可以写成 I 2 = ∫ − ∞ ∞ ∫ − ∞ ∞ exp ( − 1 2 σ 2 x 2 − 1 2 σ 2 y 2 ) d x d y = ∫ o 2 π ∫ 0 ∞ exp ( − 1 2 σ 2 r 2 ) r d r d θ I^{2}=\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} \exp \left(-\frac{1}{2 \sigma^{2}} x^{2}-\frac{1}{2 \sigma^{2}} y^{2}\right) \mathrm{d} x \mathrm{d} y=\int_o^{2 \pi}\int_0^{\infty}\exp(-\frac{1}{2\sigma^2}r^2)r\mathrm{d}r\mathrm{d}\theta I2=∫−∞∞∫−∞∞exp(−2σ21x2−2σ21y2)dxdy=∫o2π∫0∞exp(−2σ21r2)rdrdθ,使用 u = r 2 u=r^2 u=r2代换,
所以 I 2 = 1 2 ∫ o 2 π ∫ 0 ∞ exp ( − 1 2 σ 2 u ) d u d θ = 1 2 ∫ 0 2 π ( − 2 σ 2 ) exp ( − 1 2 σ 2 u ) ∣ 0 ∞ d θ = 2 π σ 2 I^{2}=\frac{1}{2}\int_o^{2 \pi}\int_0^{\infty}\exp(-\frac{1}{2\sigma^2}u)\mathrm{d}u\mathrm{d}\theta=\frac{1}{2}\int_{0}^{2\pi}(-2\sigma^2)\exp(-\frac{1}{2\sigma^2}u)|_0^{\infty}\mathrm{d}\theta=2\pi\sigma^2 I2=21∫o2π∫0∞exp(−2σ21u)dudθ=21∫02π(−2σ2)exp(−2σ21u)∣0∞dθ=2πσ2,所以 I = ( 2 π σ 2 ) 1 / 2 I=\left(2 \pi \sigma^{2}\right)^{1 / 2} I=(2πσ2)1/2。
1.8
式(1.46)为 N ( x ∣ μ , σ 2 ) = 1 ( 2 π σ 2 ) 1 / 2 exp { − 1 2 σ 2 ( x − μ ) 2 } = p ( x − μ ) \mathcal{N}\left(x | \mu, \sigma^{2}\right)=\frac{1}{\left(2 \pi \sigma^{2}\right)^{1 / 2}} \exp \left\{-\frac{1}{2 \sigma^{2}}(x-\mu)^{2}\right\}=p(x-\mu) N(x∣μ,σ2)=(2πσ2)1/21exp{−2σ21(x−μ)2}=p(x−μ),即要证明 ∫ − ∞ + ∞ x 1 ( 2 π σ 2 ) 1 / 2 exp { − 1 2 σ 2 ( x − μ ) 2 } d x = ∫ − ∞ ∞ x p ( x − μ ) d x = μ \int_{-\infty}^{+\infty}x\frac{1}{\left(2 \pi \sigma^{2}\right)^{1 / 2}} \exp \left\{-\frac{1}{2 \sigma^{2}}(x-\mu)^{2}\right\}\mathrm{d}x=\int_{-\infty}^{\infty}xp(x-\mu)\mathrm{d}x=\mu ∫−∞+∞x(2πσ2)1/21exp{−2σ21(x−μ)2}dx=∫−∞∞xp(x−μ)dx=μ。先抛开该式不谈,我们需要换元,且必须手头拿到一个已知的东西,那么我们首先有 ∫ − ∞ + ∞ ( x − μ ) 1 ( 2 π σ 2 ) 1 / 2 exp { − 1 2 σ 2 ( x − μ ) 2 } d ( x − μ ) = 0 \int_{-\infty}^{+\infty}(x-\mu)\frac{1}{\left(2 \pi \sigma^{2}\right)^{1 / 2}} \exp \left\{-\frac{1}{2 \sigma^{2}}(x-\mu)^{2}\right\}\mathrm{d}(x-\mu)=0 ∫−∞+∞(x−μ)(2πσ2)1/21exp{−2σ21(x−μ)2}d(x−μ)=0,这个比较简单,根据奇函数积分为 0 0 0可得,然后我们把这个式子在 ( x − μ ) (x-\mu) (x−μ)这里展开,可以看到即 ∫ − ∞ ∞ x p ( x − μ ) d ( x − μ ) − μ ∫ − ∞ ∞ p ( x − μ ) d ( x − μ ) = ∫ − ∞ ∞ x p ( x − μ ) d x − μ = 0 \int_{-\infty}^{\infty}xp(x-\mu)\mathrm{d}(x-\mu)-\mu\int_{-\infty}^{\infty}p(x-\mu)\mathrm{d}(x-\mu)=\int_{-\infty}^{\infty}xp(x-\mu)\mathrm{d}x-\mu=0 ∫−∞∞xp(x−μ)d(x−μ)−μ∫−∞∞p(x−μ)d(x−μ)=∫−∞∞xp(x−μ)dx−μ=0,所以 ∫ − ∞ ∞ x p ( x − μ ) d x = μ \int_{-\infty}^{\infty}xp(x-\mu)\mathrm{d}x=\mu ∫−∞∞xp(x−μ)dx=μ,亦即 E [ x ] = ∫ − ∞ ∞ N ( x ∣ μ , σ 2 ) x d x = μ \mathbb{E}[x]=\int_{-\infty}^{\infty} \mathcal{N}\left(x | \mu, \sigma^{2}\right) x \mathrm{d} x=\mu E[x]=∫−∞∞N(x∣μ,σ2)xdx=μ。
第二小问要求验证式(1.50)的正确性。在题目1.7中我们得到 ∫ − ∞ ∞ exp ( − 1 2 σ 2 ( x − μ ) 2 ) d x = ( 2 π σ 2 ) 1 / 2 \int_{-\infty}^{\infty} \exp \left(-\frac{1}{2 \sigma^{2}} (x-\mu)^{2}\right) \mathrm{d} x = \left(2 \pi \sigma^{2}\right)^{1 / 2} ∫−∞∞exp(−2σ21(x−μ)2)dx=(2πσ2)1/2,在等式两边对 σ 2 \sigma^2 σ2求导可得 ∫ − ∞ ∞ exp { − ( x − μ ) 2 2 σ 2 } 2 ( x − μ ) 2 ( 2 σ 2 ) 2 d x = π ( 2 π σ ) 1 / 2 \int_{-\infty}^{\infty}\exp\{-\frac{(x-\mu)^2}{2\sigma^2}\}\frac{2(x-\mu)^2}{(2\sigma^2)^2}\mathrm{d}x=\frac{\pi}{(2\pi \sigma)^{1/2}} ∫−∞∞exp{−2σ2(x−μ)2}(2σ2)22(x−μ)2dx=(2πσ)1/2π,将式子整理后为: ∫ − ∞ ∞ 1 ( 2 π σ 2 ) 1 / 2 exp { − ( x − μ ) 2 2 σ 2 } ( x − μ ) 2 d x = σ 2 = E [ ( x − μ ) 2 ] \int_{-\infty}^{\infty}\frac{1}{(2\pi\sigma^2)^{1/2}}\exp\{-\frac{(x-\mu)^2}{2\sigma^2}\}(x-\mu)^2\mathrm{d}x= \sigma^{2}=\mathbb{E}[(x-\mu)^2] ∫−∞∞(2πσ2)1/21exp{−2σ2(x−μ)2}(x−μ)2dx=σ2=E[(x−μ)2],又因为 E [ ( x − μ ) 2 ] = E [ x 2 − 2 μ x + μ 2 ] = E [ x 2 ] − 2 μ E [ x ] + μ 2 \mathbb{E}[(x-\mu)^2]=\mathbb{E}[x^2-2\mu x+\mu^2]=\mathbb{E}[x^2]-2\mu\mathbb{E}[x]+\mu^2 E[(x−μ)2]=E[x2−2μx+μ2]=E[x2]−2μE[x]+μ2,而我们在上一小问已经知道 E [ x ] = μ \mathbb{E}[x]=\mu E[x]=μ,所以全部带进去可得, σ 2 = E [ x 2 ] − μ 2 \sigma^2=\mathbb{E}[x^2]-\mu^2 σ2=E[x2]−μ2,所以 E [ x 2 ] = σ 2 + μ 2 \mathbb{E}[x^2]=\sigma^2+\mu^2 E[x2]=σ2+μ2,从而证得式(1.50)。这样一来,式(1.51)也就顺理成章地成立了。
1.9
单元高斯分布的极大值可以通过对其概率分布函数求导得到极值对应的坐标 x = μ x=\mu x=μ,不做赘述。
多元高斯分布函数为 N ( x ∣ μ , Σ ) = 1 ( 2 π ) D / 2 1 ∣ Σ ∣ 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } \mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma})=\frac{1}{(2 \pi)^{D / 2}} \frac{1}{|\mathbf{\Sigma}|^{1 / 2}} \exp \left\{-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^{\mathrm{T}} \mathbf{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\} N(x∣μ,Σ)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)},同样进行求导,这里要用到矩阵的求导法则,得 ∂ N ( x ∣ μ , Σ ) ∂ x = − 1 2 N ( x ∣ μ , Σ ) ∇ x { ( x − μ ) T Σ − 1 ( x − μ ) } = − 1 2 N ( x ∣ μ , Σ ) ∇ x − μ { ( x − μ ) T Σ − 1 ( x − μ ) } \frac{\partial\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma})}{\partial \mathbf{x}}=-\frac{1}{2}\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma})\nabla_{\mathbf{x}}\left\{(\mathbf{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\}=-\frac{1}{2}\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma})\nabla_{\mathbf{x}-\boldsymbol{\mu}}\left\{(\mathbf{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\} ∂x∂N(x∣μ,Σ)=−21N(x∣μ,Σ)∇x{(x−μ)TΣ−1(x−μ)}=−21N(x∣μ,Σ)∇x−μ{(x−μ)TΣ−1(x−μ)},利用PRML(C.19)和(C.20)公式,令 A = ( x − μ ) T Σ − 1 \mathbf{A}=(\mathbf{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1} A=(x−μ)TΣ−1, B = x − μ \mathbf{B}=\mathbf{x}-\boldsymbol{\mu} B=x−μ,则很容易得到 ∂ N ( x ∣ μ , Σ ) ∂ x = − N ( x ∣ μ , Σ ) Σ − 1 ( x − μ ) \frac{\partial\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma})}{\partial \mathbf{x}}=-\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \mathbf{\Sigma}) \boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu}) ∂x∂N(x∣μ,Σ)=−N(x∣μ,Σ)Σ−1(x−μ),在推导过程中需要注意的是 Σ − 1 ( x − μ ) = ( x − μ ) T Σ − 1 {\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})=(\mathbf{x}-\boldsymbol{\mu})^{\mathrm{T}}{\Sigma}^{-1} Σ−1(x−μ)=(x−μ)TΣ−1,这是由于 x − μ \mathbf{x}-\boldsymbol{\mu} x−μ是向量所导致的。那么根据求得的导数,同样在 x = μ \mathbf{x}=\boldsymbol{\mu} x=μ时取得极值。
1.10
E [ x + z ] = ∬ ( x + z ) p ( x , z ) d x d z = ∬ ( x + z ) p ( x ) p ( z ) d x d z = ∬ x p ( x ) p ( z ) d x d z + ∬ z p ( z ) p ( x ) d x d z \mathbb{E}[x+z]=\iint (x+z)p(x,z)\mathrm{d}x\mathrm{d}z=\iint (x+z)p(x)p(z)\mathrm{d}x\mathrm{d}z=\iint xp(x)p(z)\mathrm{d}x\mathrm{d}z+\iint zp(z)p(x)\mathrm{d}x\mathrm{d}z E[x+z]=∬(x+z)p(x,z)dxdz=∬(x+z)p(x)p(z)dxdz=∬xp(x)p(z)dxdz+∬zp(z)p(x)dxdz
对于右侧的式子,由于 x x x与 z z z相互独立, p ( z ) p(z) p(z)的积分为1,因此第一项即为 ∫ x p ( x ) d x = E [ x ] \int xp(x)\mathrm{d}x=\mathbb{E}[x] ∫xp(x)dx=E[x],同理第二项为 E [ z ] \mathbb{E}[z] E[z],所以 E [ x + z ] = E [ x ] + E [ z ] \mathbb{E}[x+z]=\mathbb{E}[x]+\mathbb{E}[z] E[x+z]=E[x]+E[z]。
var [ x + z ] = E [ ( x + z ) 2 ] − ( E [ x + z ] ) 2 \operatorname{var}[x+z]=\mathbb{E}[(x+z)^2]-(\mathbb{E}[x+z])^2 var[x+z]=E[(x+z)2]−(E[x+z])2,代入第一小问的结果,得到所求方差为 E [ x 2 + z 2 + 2 x z ] − ( E [ x ] + E [ x ] ) 2 = E [ x 2 ] + E [ z 2 ] + 2 E [ x z ] − ( E [ x ] ) 2 − ( E [ z ] ) 2 − 2 E [ x ] E [ z ] \mathbb{E}[x^2+z^2+2xz]-(\mathbb{E}[x]+\mathbb{E}[x])^2=\mathbb{E}[x^2]+\mathbb{E}[z^2]+2\mathbb{E}[xz]-(\mathbb{E}[x])^2-(\mathbb{E}[z])^2-2\mathbb{E}[x]\mathbb{E}[z] E[x2+z2+2xz]−(E[x]+E[x])2=E[x2]+E[z2]+2E[xz]−(E[x])2−(E[z])2−2E[x]E[z],
又根据题目1.6的结论,化简得到 var [ x + z ] = E [ x 2 ] + E [ z 2 ] − ( E [ x ] ) 2 − ( E [ z ] ) 2 = var [ x ] + var [ z ] \operatorname{var}[x+z]=\mathbb{E}[x^2]+\mathbb{E}[z^2]-(\mathbb{E}[x])^2-(\mathbb{E}[z])^2=\operatorname{var}[x]+\operatorname{var}[z] var[x+z]=E[x2]+E[z2]−(E[x])2−(E[z])2=var[x]+var[z]。
1.11
令 y = ln p ( x ∣ μ , σ 2 ) = − 1 2 σ 2 ∑ n = 1 N ( x n − μ ) 2 − N 2 ln σ 2 − N 2 ln ( 2 π ) y=\ln p\left(\mathbf{x} | \mu, \sigma^{2}\right)=-\frac{1}{2 \sigma^{2}} \sum_{n=1}^{N}\left(x_{n}-\mu\right)^{2}-\frac{N}{2} \ln \sigma^{2}-\frac{N}{2} \ln (2 \pi) y=lnp(x∣μ,σ2)=−2σ21∑n=1N(xn−μ)2−2Nlnσ2−2Nln(2π),可以得到 ∂ y ∂ μ = − 1 σ 2 ∑ n = 1 N ( μ − x n ) = 0 \frac{\partial y}{\partial \mu}=-\frac{1}{\sigma^2}\sum_{n=1}^{N}(\mu-x_n)=0 ∂μ∂y=−σ21∑n=1N(μ−xn)=0,所以 ∑ n = 1 N ( μ − x n ) = 0 \sum_{n=1}^{N}(\mu-x_n)=0 ∑n=1N(μ−xn)=0,所以 ∑ n = 1 N μ − ∑ n = 1 N x n = N μ − ∑ n = 1 N x n = 0 \sum_{n=1}^{N}\mu-\sum_{n=1}^{N}x_n=N\mu-\sum_{n=1}^{N}x_n=0 ∑n=1Nμ−∑n=1Nxn=Nμ−∑n=1Nxn=0,所以 μ M L = 1 N ∑ n = 1 N x n \mu_{\mathrm{ML}}=\frac{1}{N} \sum_{n=1}^{N} x_{n} μML=N1∑n=1Nxn。
∂ y ∂ σ 2 = − 2 ( 2 σ 2 ) 2 ∑ n = 1 N ( x n − μ M L ) 2 − N 2 σ 2 = 0 \frac{\partial y}{\partial \sigma^2}=-\frac{2}{(2\sigma^2)^2}\sum_{n=1}^{N}(x_n-\mu_{\mathrm{ML}})^2-\frac{N}{2\sigma^2}=0 ∂σ2∂y=−(2σ2)22∑n=1N(xn−μML)2−2σ2N=0,很容易得到 σ M L 2 = 1 N ∑ n = 1 N ( x n − μ M L ) 2 \sigma_{\mathrm{ML}}^{2}=\frac{1}{N} \sum_{n=1}^{N}\left(x_{n}-\mu_{\mathrm{ML}}\right)^{2} σML2=N1∑n=1N(xn−μML)2。
1.12
这题其实第一小问挺迷的,主要问题在于为什么作者要使用不同的下标来表示是否独立,或者说,如果作者你想表达这个意思,那你就应该明说啊我透。这样子一来就比较简单明了了,若 n = m n=m n=m,则 E [ x n 2 ] \mathbb{E}[x_n^2] E[xn2]根据式(1.50)很容易得到 E [ x n 2 ] = μ 2 + σ 2 \mathbb{E}[x_n^2]=\mu^2+\sigma^2 E[xn2]=μ2+σ2,下标为 m m m时相同。若 n ≠ m n\ne m n̸=m,那么按照作者的意思,就是说这俩变量相互独立,所以 E [ x n x m ] = E [ x n ] E [ x m ] = μ 2 \mathbb{E}[x_nx_m]=\mathbb{E}[x_n]\mathbb{E}[x_m]=\mu^2 E[xnxm]=E[xn]E[xm]=μ2。
其实作者是想用第一小问作为引子来帮助我们证明式(1.57)和式(1.58),那么实际上我是觉得没必要这么麻烦,我们直接证明这两个式子即可,无需绕他给的这条弯路。
对于第一个式子,求取最大似然分布的均值的期望,我们这里假设总共取了 K K K次数据,每一次都取 N N N个数据来进行极大似然估计, x k n x_{kn} xkn表示第 k k k次取的第 n n n个数据,那么 E [ μ M L ] = 1 K ∑ k = 1 K [ 1 N ∑ n = 1 N x k n ] = 1 K N ∑ k = 1 K ∑ n = 1 N x k n \mathbb{E}[\mu_{\mathrm{ML}}]=\frac{1}{K}\sum_{k=1}^K[\frac{1}{N}\sum_{n=1}^Nx_{kn}]=\frac{1}{KN}\sum_{k=1}^{K}\sum_{n=1}^Nx_{kn} E[μML]=K1∑k=1K[N1∑n=1Nxkn]=KN1∑k=1K∑n=1Nxkn,到这里,我们先停一下,假设我们每次取的数据有限,也就是 N N N有限,但是我们一直取一直取,也就是说 K K K无限,那么这里就可以看做我对整个分布上所有的 x x x都取到了,从而推得 x k n x_{kn} xkn的均值就是正态分布 N ( x ∣ μ , σ 2 ) \mathcal{N}\left(x | \mu, \sigma^{2}\right) N(x∣μ,σ2)的均值 μ \mu μ,所以 E [ μ M L ] = μ \mathbb{E}[\mu_{\mathrm{ML}}]=\mu E[μML]=μ,这就证明了式(1.57)。
对于式(1.58),首先依旧采取我们之前的取数据规定,同时将方差的计算公式展开, μ k M L \mu_{k\mathrm{ML}} μkML为第 k k k次取得的数据的均值,则 E [ σ M L 2 ] = 1 K ∑ k = 1 K [ 1 N ∑ n = 1 N ( x k n − μ k M L ) 2 ] = 1 K ∑ k = 1 K [ 1 N ∑ n = 1 N ( x k n 2 − 2 x k n μ k M L + μ k M L 2 ) ] \mathbb{E}[\sigma_{\mathrm{ML}}^2]=\frac{1}{K}\sum_{k=1}^K[\frac{1}{N}\sum_{n=1}^N(x_{kn}-\mu_{k\mathrm{ML}})^2]=\frac{1}{K}\sum_{k=1}^K[\frac{1}{N}\sum_{n=1}^N(x_{kn}^2-2x_{kn}\mu_{k\mathrm{ML}}+ \mu_{k\mathrm{ML}}^2)] E[σML2]=K1∑k=1K[N1∑n=1N(xkn−μkML)2]=K1∑k=1K[N1∑n=1N(xkn2−2xknμkML+μkML2)],这就可以拆分为三项,其中第一项与 x k n 2 x_{kn}^2 xkn2相关,沿用上面的思路,相当于取遍了所有的 x k n x_{kn} xkn,所以 1 K ∑ k = 1 K [ 1 N ∑ n = 1 N x k n 2 ] = E [ x 2 ] = μ 2 + σ 2 \frac{1}{K}\sum_{k=1}^K[\frac{1}{N}\sum_{n=1}^Nx_{kn}^2]=\mathbb{E}[x^2]=\mu^2+\sigma^2 K1∑k=1K[N1∑n=1Nxkn2]=E[x2]=μ2+σ2,后面两项可以写成 1 K ∑ k = 1 K [ − 2 μ k M L 1 N ∑ n = 1 N x k n ] + 1 K ∑ k = 1 K [ 1 N ∑ n = 1 N ( μ k M L 2 ) ] \frac{1}{K}\sum_{k=1}^K[-2\mu_{k\mathrm{ML}}\frac{1}{N}\sum_{n=1}^Nx_{kn}]+\frac{1}{K}\sum_{k=1}^K[\frac{1}{N}\sum_{n=1}^N( \mu_{k\mathrm{ML}}^2)] K1∑k=1K[−2μkMLN1∑n=1Nxkn]+K1∑k=1K[N1∑n=1N(μkML2)],也就是 1 K ∑ k = 1 K [ − 2 μ k M L 2 ] + 1 K ∑ k = 1 K [ μ k M L 2 ] = − 1 K ∑ k = 1 K [ μ k M L 2 ] \frac{1}{K}\sum_{k=1}^K[-2\mu_{k\mathrm{ML}}^2]+\frac{1}{K}\sum_{k=1}^K[\mu_{k\mathrm{ML}}^2]=-\frac{1}{K}\sum_{k=1}^K[\mu_{k\mathrm{ML}}^2] K1∑k=1K[−2μkML2]+K1∑k=1K[μkML2]=−K1∑k=1K[μkML2],这就比较明白了,后面两项就是 − E [ μ M L 2 ] -\mathbb{E}[\mu_{\mathrm{ML}}^2] −E[μML2],因此 E [ σ M L 2 ] = μ 2 + σ 2 − E [ μ M L 2 ] \mathbb{E}[\sigma_{\mathrm{ML}}^2]=\mu^2+\sigma^2-\mathbb{E}[\mu_{\mathrm{ML}}^2] E[σML2]=μ2+σ2−E[μML2],所以我们就要求这个 E [ μ M L 2 ] \mathbb{E}[\mu_{\mathrm{ML}}^2] E[μML2],这个表达式的含义就是每一次取得的数据的均值的平方的平均值(期望),那么就有 E [ μ M L 2 ] = σ μ M L 2 + ( E [ μ M L ] ) 2 \mathbb{E}[\mu_{\mathrm{ML}}^2]=\sigma_{\mu_{\mathrm{ML}}}^2+(\mathbb{E}[\mu_{\mathrm{ML}}])^2 E[μML2]=σμML2+(E[μML])2,根据公式(1.57),我们进一步得到 E [ μ M L 2 ] = σ μ M L 2 + μ 2 \mathbb{E}[\mu_{\mathrm{ML}}^2]=\sigma_{\mu_{\mathrm{ML}}}^2+\mu^2 E[μML2]=σμML2+μ2,所以 E [ σ M L 2 ] = μ 2 + σ 2 − E [ μ M L 2 ] = σ 2 − σ μ M L 2 \mathbb{E}[\sigma_{\mathrm{ML}}^2]=\mu^2+\sigma^2-\mathbb{E}[\mu_{\mathrm{ML}}^2]=\sigma^2-\sigma_{\mu_{\mathrm{ML}}}^2 E[σML2]=μ2+σ2−E[μML2]=σ2−σμML2,所以任务又进一步变为求这个 σ μ M L 2 = var [ μ M L ] \sigma_{\mu_{\mathrm{ML}}}^2=\operatorname{var}[\mu_{\mathrm{ML}}] σμML2=var[μML],而 var [ μ M L ] = var [ 1 N ∑ n = 1 N x n ] = 1 N 2 ∑ n = 1 N var [ x n ] = 1 N 2 ∑ n = 1 N σ 2 = σ 2 N \operatorname{var}[\mu_{\mathrm{ML}}]=\operatorname{var}[\frac{1}{N}\sum_{n=1}^N x_n]=\frac{1}{N^2}\sum_{n=1}^N \operatorname{var}[x_n]=\frac{1}{N^2}\sum_{n=1}^N \sigma^2=\frac{\sigma^2}{N} var[μML]=var[N1∑n=1Nxn]=N21∑n=1Nvar[xn]=N21∑n=1Nσ2=Nσ2。
所以就有 E [ σ M L 2 ] = μ 2 + σ 2 − E [ μ M L 2 ] = σ 2 − σ 2 N = N − 1 N σ 2 \mathbb{E}[\sigma_{\mathrm{ML}}^2]=\mu^2+\sigma^2-\mathbb{E}[\mu_{\mathrm{ML}}^2]=\sigma^2-\frac{\sigma^2}{N}=\frac{N-1}{N}\sigma^2 E[σML2]=μ2+σ2−E[μML2]=σ2−Nσ2=NN−1σ2。
PS:我用MATLAB做了一下实验,与理论完全相符,式(1.57)和式(1.58)实际上也可以从直观上进行理解,这里就不详细说了。
1.13
根据题目(1.12)的推导,这题就很简单了,将 E [ μ M L 2 ] \mathbb{E}[\mu_{\mathrm{ML}}^2] E[μML2]代换为 E [ μ 2 ] = μ 2 \mathbb{E}[\mu^2]=\mu^2 E[μ2]=μ2即可,那很显然 E [ σ M L 2 ] = μ 2 + σ 2 − μ 2 = σ 2 \mathbb{E}[\sigma_{\mathrm{ML}}^2]=\mu^2+\sigma^2-\mu^2=\sigma^2 E[σML2]=μ2+σ2−μ2=σ2。此时,方差的期望也就是无偏的了。
1.14
如果可以写成题目要求的形式(设原矩阵为 W \mathrm{W} W,要写成 W = S + A \mathrm{W}=\mathrm{S}+\mathrm{A} W=S+A),那首先可以很容易推断出 A \mathrm{A} A的对角线上的元素都是 0 0 0,所以 S \mathrm{S} S对角线上的元素就是 W \mathrm{W} W对角线上的元素。接着就是要证明 S \mathrm{S} S和 A \mathrm{A} A的其余元素也是可解出来的,因为 w i j = w i j S + w i j A w_{ij}=w_{ij}^{\mathrm{S}}+w_{ij}^{\mathrm{A}} wij=wijS+wijA,同时 w j i = w j i S + w j i A = w i j S − w i j A w_{ji}=w_{ji}^{\mathrm{S}}+w_{ji}^{\mathrm{A}}=w_{ij}^{\mathrm{S}}-w_{ij}^{\mathrm{A}} wji=wjiS+wjiA=wijS−wijA,这就可以得到构成一个二元一次方程组,由于参数对应的矩阵的秩为 2 2 2,因此方程组必然有解,所以可以写成题目要求的形式。
∑ i = 1 D ∑ j = 1 D x i w i j x j = x T W x = x T ( S + A ) x = x T S x + x T A x \sum_{i=1}^{D}\sum_{j=1}^{D}x_i w_{ij}x_j=\mathrm{x^T W x}=\mathrm{x^T (S+A) x}=\mathrm{x^T S x +x^T A x} ∑i=1D∑j=1Dxiwijxj=xTWx=xT(S+A)x=xTSx+xTAx,现在重点关注一下 x T A x \mathrm{x^T A x} xTAx这一项,因为 x T A x = ∑ i = 1 D ∑ j = 1 D x i w i j A x j \mathrm{x^T A x}=\sum_{i=1}^{D}\sum_{j=1}^{D}x_i w_{ij}^{\mathrm{A}}x_j xTAx=∑i=1D∑j=1DxiwijAxj,那么 A \mathrm{A} A的对角线元素皆为 0 0 0,同时对称元素互为相反数,(注意, A \mathrm{A} A和另外两个矩阵都是方阵,这是前提条件),相当于 x i w i j A x j + x j w j i A x i = 0 x_i w_{ij}^{\mathrm{A}}x_j+x_j w_{ji}^{\mathrm{A}}x_i=0 xiwijAxj+xjwjiAxi=0,所以 x T A x = 0 \mathrm{x^T A x}=0 xTAx=0,所以 ∑ i = 1 D ∑ j = 1 D x i w i j x j = x T W x = x T S x + x T A x = x T S x = ∑ i = 1 D ∑ j = 1 D x i w i j S x j \sum_{i=1}^{D}\sum_{j=1}^{D}x_i w_{ij}x_j=\mathrm{x^T W x}=\mathrm{x^T S x +x^T A x}=\mathrm{x^T S x}=\sum_{i=1}^{D}\sum_{j=1}^{D}x_i w_{ij}^{\mathrm{S}}x_j ∑i=1D∑j=1Dxiwijxj=xTWx=xTSx+xTAx=xTSx=∑i=1D∑j=1DxiwijSxj。
最后一小问就相当于问我们矩阵 S \mathrm{S} S的对角线以及上(或下)三角部分一共有几个元素,使用数列求和的方式,我们得到 1 + 2 + 3 + ⋯ + D = D ( D + 1 ) / 2 1+2+3+\dots+D=D(D+1)/2 1+2+3+⋯+D=D(D+1)/2,因此独立的元素数量就是这么多。
1.15
根据题目1.14可知,由所有 w i 1 i 2 … i M w_{i_{1}i_{2}\dots i _{M}} wi1i2…iM构成的高维张量也是一个高维对称张量,其中的独立元素使用 w ~ i 1 i 2 … i M \tilde{w}_{i_{1}i_{2}\dots i _{M}} w~i1i2…iM表示,此时要证明的式子就比较好理解了,由于张量的对称性质,其余元素都是非独立的,因此均可不做考虑,在根据 i 1 i_{1} i1至 i M i_{M} iM确定了张量的维度顺序后,假设 i 1 = 1 i_1 = 1 i1=1,那么由于剩下的维度中非独立元素所处的维度小于等于第一维的维度,因此 i 2 i_2 i2的上限是 i 1 i_1 i1,同理,剩下的和式也是可以推出来的。由此我们可以得到形式为 ∑ i 1 = 1 D ∑ i 2 = 1 i 1 ⋯ ∑ i M = 1 i M − 1 w ~ i 1 i 2 ⋯ i M x i 1 x i 2 ⋯ x i M \sum_{i_{1}=1}^{D} \sum_{i_{2}=1}^{i_{1}} \cdots \sum_{i_{M}=1}^{i_{M-1}} \widetilde{w}_{i_{1} i_{2} \cdots i_{M}} x_{i_{1}} x_{i_{2}} \cdots x_{i_{M}} ∑i1=1D∑i2=1i1⋯∑iM=1iM−1w i1i2⋯iMxi1xi2⋯xiM。
Tips:实际上我还是没有想明白对称的高维张量是长啥样的。
接着要证明 n ( D , M ) = ∑ i = 1 D n ( i , M − 1 ) n(D, M)=\sum_{i=1}^{D} n(i, M-1) n(D,M)=∑i=1Dn(i,M−1),这个也很简单,就将上面第一问的结果拿来用,最外围的求和就是在 i 1 i_1 i1从 1 1 1取到 D D D的过程中后方所有项的求和,而 i 2 i_2 i2到 i M i_M iM一共有 M − 1 M-1 M−1项,所以得证。这个递推式还是比较直观的。
第三小问归纳法也很直接, D = 1 D=1 D=1的情况下, ∑ i = 1 D ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! = ( M − 1 ) ! ( M − 1 ) ! = 1 = ( D + M − 1 ) ! ( D − 1 ) ! M ! = ( 1 + M − 1 ) ! ( 1 − 1 ) ! M ! = M ! M ! \sum_{i=1}^{D} \frac{(i+M-2) !}{(i-1) !(M-1) !}=\frac{(M-1)!}{(M-1)!}=1=\frac{(D+M-1) !}{(D-1) ! M !}=\frac{(1+M-1) !}{(1-1) ! M !}=\frac{M!}{M!} ∑i=1D(i−1)!(M−1)!(i+M−2)!=(M−1)!(M−1)!=1=(D−1)!M!(D+M−1)!=(1−1)!M!(1+M−1)!=M!M!,此时等式成立,假设取数字 D D D时,等式成立,则 ∑ i = 1 D ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! = ( D + M − 1 ) ! ( D − 1 ) ! M ! \sum_{i=1}^{D} \frac{(i+M-2) !}{(i-1) !(M-1) !}=\frac{(D+M-1) !}{(D-1) ! M !} ∑i=1D(i−1)!(M−1)!(i+M−2)!=(D−1)!M!(D+M−1)!,则取数字 D + 1 D+1 D+1时, ∑ i = 1 D + 1 ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! = ∑ i = 1 D [ ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! ] + ( D + M − 1 ) ! D ! ( M − 1 ) ! = ( D + M − 1 ) ! ( D − 1 ) ! M ! + ( D + M − 1 ) ! D ! ( M − 1 ) ! = ( D + M ) ( D + M − 1 ) ! D ! M ! \sum_{i=1}^{D+1} \frac{(i+M-2) !}{(i-1) !(M-1) !}=\sum_{i=1}^{D} [\frac{(i+M-2) !}{(i-1) !(M-1) !}]+\frac{(D+M-1) !}{D ! (M-1) !}=\frac{(D+M-1) !}{(D-1) ! M !}+\frac{(D+M-1) !}{D ! (M-1) !}=\frac{(D+M)(D+M-1)!}{D!M!} ∑i=1D+1(i−1)!(M−1)!(i+M−2)!=∑i=1D[(i−1)!(M−1)!(i+M−2)!]+D!(M−1)!(D+M−1)!=(D−1)!M!(D+M−1)!+D!(M−1)!(D+M−1)!=D!M!(D+M)(D+M−1)!,所以 ∑ i = 1 D + 1 ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! = ( D + M ) ! D ! M ! = ( D + 1 + M − 1 ) ! ( D + 1 − 1 ) ! M ! \sum_{i=1}^{D+1} \frac{(i+M-2) !}{(i-1) !(M-1) !}=\frac{(D+M)!}{D!M!}=\frac{(D+1+M-1)!}{(D+1-1)!M!} ∑i=1D+1(i−1)!(M−1)!(i+M−2)!=D!M!(D+M)!=(D+1−1)!M!(D+1+M−1)!,说明该式在 D + 1 D+1 D+1时仍旧成立,从而归纳得证。
对于任意 D ≥ 1 D \ge 1 D≥1,取 M = 2 M=2 M=2,则有 n ( D , M ) = ( D + M − 1 ) ! ( D − 1 ) ! M ! = ( D + 1 ) ! ( D − 1 ) ! 2 ! = D ( D + 1 ) 2 n(D, M)=\frac{(D+M-1) !}{(D-1) ! M !}=\frac{(D+1) !}{(D-1) !2 !}=\frac{D(D+1)}{2} n(D,M)=(D−1)!M!(D+M−1)!=(D−1)!2!(D+1)!=2D(D+1),正如我们在题目1.14中得到结果一样。现在假设 M − 1 M-1 M−1时,该式成立,即 n ( D , M − 1 ) = ( D + M − 2 ) ! ( D − 1 ) ! ( M − 1 ) ! n(D, M-1)=\frac{(D+M-2) !}{(D-1) ! (M-1) !} n(D,M−1)=(D−1)!(M−1)!(D+M−2)!,而 n ( D , M ) = ∑ i = 1 D n ( i , M − 1 ) = ∑ i = 1 D ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! n(D, M)=\sum_{i=1}^{D} n(i, M-1)=\sum_{i=1}^{D} \frac{(i+M-2) !}{(i-1) ! (M-1) !} n(D,M)=∑i=1Dn(i,M−1)=∑i=1D(i−1)!(M−1)!(i+M−2)!,又因为 ∑ i = 1 D ( i + M − 2 ) ! ( i − 1 ) ! ( M − 1 ) ! = ( D + M − 1 ) ! ( D − 1 ) ! M ! \sum_{i=1}^{D} \frac{(i+M-2) !}{(i-1) !(M-1) !}=\frac{(D+M-1) !}{(D-1) ! M !} ∑i=1D(i−1)!(M−1)!(i+M−2)!=(D−1)!M!(D+M−1)!,所以 n ( D , M ) = ( D + M − 1 ) ! ( D − 1 ) ! M ! n(D, M)=\frac{(D+M-1) !}{(D-1) ! M !} n(D,M)=(D−1)!M!(D+M−1)!,所以在 M M M时,该式依旧成立,从而归纳得证。
1.16
第一小问很直观,根据式(1.74)可知, n ( D , M ) n(D,M) n(D,M)仅表征了第 M M M阶参数的独立元素个数,现在的 N ( D , M ) N(D,M) N(D,M)相当于求取所有阶( 0 0 0阶到 M M M阶)的独立参数数量,因此 N ( D , M ) = ∑ m = 0 M n ( D , m ) N(D, M)=\sum_{m=0}^{M} n(D, m) N(D,M)=∑m=0Mn(D,m)。
第二小问,当 M = 0 M=0 M=0时, N ( D , M ) = ( D + M ) ! D ! M ! = 1 N(D, M)=\frac{(D+M) !}{D ! M !}=1 N(D,M)=D!M!(D+M)!=1,这与实际相符,当仅含有 0 0 0阶时,由于 x x x无关,所以实际上就一个常数项,因此参数的数量就是 1 1 1。现在假设 M M M时成立,即 N ( D , M ) = ( D + M ) ! D ! M ! N(D, M)=\frac{(D+M) !}{D ! M !} N(D,M)=D!M!(D+M)!,则取 M + 1 M+1 M+1时, N ( D , M + 1 ) = ( D + M ) ! D ! M ! + n ( D , M + 1 ) = ( D + M ) ! D ! M ! + ( D + M ) ! ( D − 1 ) ! ( M + 1 ) ! = ( M + 1 ) ( D + M ) ! + D ( D + M ) ! D ! ( M + 1 ) ! = ( D + M + 1 ) ! D ! ( M + 1 ) ! N(D, M+1)=\frac{(D+M) !}{D ! M !}+n(D,M+1)=\frac{(D+M) !}{D ! M !}+\frac{(D+M) !}{(D-1) ! (M+1) !}=\frac{(M+1)(D+M)!+D(D+M)!}{D!(M+1)!}=\frac{(D+M+1)!}{D!(M+1)!} N(D,M+1)=D!M!(D+M)!+n(D,M+1)=D!M!(D+M)!+(D−1)!(M+1)!(D+M)!=D!(M+1)!(M+1)(D+M)!+D(D+M)!=D!(M+1)!(D+M+1)!,这里使用了式(1.137)的结论,从而归纳得证。
第三小问使用了斯特林公式 n ! ≃ n n e − n n ! \simeq n^{n} e^{-n} n!≃nne−n,若 D ≫ M D \gg M D≫M,则 N ( D , M ) = ( D + M ) ! D ! M ! ≃ ( D + M ) ! D ! ≃ ( D + M ) D + M e − ( D + M ) D D e − D ≃ ( D + M ) D + M D D ≃ D D + M D D = D M N(D, M)=\frac{(D+M) !}{D ! M !} \simeq \frac{(D+M)!}{D!} \simeq \frac{(D+M)^{D+M}e^{-(D+M)}}{D^De^{-D}} \simeq \frac{(D+M)^{D+M}}{D^D} \simeq \frac{D^{D+M}}{D^D}=D^M N(D,M)=D!M!(D+M)!≃D!(D+M)!≃DDe−D(D+M)D+Me−(D+M)≃DD(D+M)D+M≃DDDD+M=DM,同理,若 M ≫ D M \gg D M≫D,则有 N ( D , M ) = ( D + M ) ! D ! M ! ≃ ( D + M ) ! M ! ≃ ( D + M ) D + M e − ( D + M ) M M e − M ≃ ( D + M ) D + M M M ≃ M D + M M M = M D N(D, M)=\frac{(D+M) !}{D ! M !} \simeq \frac{(D+M)!}{M!} \simeq \frac{(D+M)^{D+M}e^{-(D+M)}}{M^Me^{-M}} \simeq \frac{(D+M)^{D+M}}{M^M} \simeq \frac{M^{D+M}}{M^M}=M^D N(D,M)=D!M!(D+M)!≃M!(D+M)!≃MMe−M(D+M)D+Me−(D+M)≃MM(D+M)D+M≃MMMD+M=MD,从而得证。
N ( 10 , 3 ) = ( 10 + 3 ) ! 10 ! 3 ! = 286 N(10, 3)=\frac{(10+3) !}{10 ! 3 !}=286 N(10,3)=10!3!(10+3)!=286, N ( 100 , 3 ) = ( 100 + 3 ) ! 100 ! 3 ! = 176851 N(100, 3)=\frac{(100+3) !}{100 ! 3 !}=176851 N(100,3)=100!3!(100+3)!=176851。
1.17
已知 Γ ( x ) ≡ ∫ 0 ∞ u x − 1 e − u d u \Gamma(x) \equiv \int_{0}^{\infty} u^{x-1} e^{-u} \mathrm{d} u Γ(x)≡∫0∞ux−1e−udu,根据分部积分法,可以得到 Γ ( x ) = ∫ 0 ∞ − u x − 1 d e − u = − u x − 1 e − u ∣ 0 ∞ + ∫ 0 ∞ e − u d u x − 1 = ∫ 0 ∞ e − u d u x − 1 \Gamma(x)=\int_{0}^{\infty}-u^{x-1}\mathrm{d}e^{-u}=-u^{x-1}e^{-u}|_0^{\infty}+\int_{0}^{\infty}e^{-u}\mathrm{d}u^{x-1}=\int_{0}^{\infty}e^{-u}\mathrm{d}u^{x-1} Γ(x)=∫0∞−ux−1de−u=−ux−1e−u∣0∞+∫0∞e−udux−1=∫0∞e−udux−1,前半部分的积分为 0 0 0不做赘述,简单说明一下就是 x x x是有限项,而 u u u取无限大项时,无限大的有限次方除以 e e e的无限大次方时趋近于 0 0 0,你也可以用MATLAB测试一下。而 Γ ( x + 1 ) = ∫ 0 ∞ e − u d u x = ∫ 0 ∞ x e − u d u x − 1 = x Γ ( x ) \Gamma(x+1)=\int_{0}^{\infty}e^{-u}\mathrm{d}u^{x}=\int_{0}^{\infty}xe^{-u}\mathrm{d}u^{x-1}=x\Gamma(x) Γ(x+1)=∫0∞e−udux=∫0∞xe−udux−1=xΓ(x),得证。
Γ ( 1 ) = ∫ 0 ∞ e − u d u = − e − u ∣ 0 ∞ = 1 \Gamma(1)=\int_{0}^{\infty}e^{-u}\mathrm{d}u=-e^{-u}|_0^{\infty}=1 Γ(1)=∫0∞e−udu=−e−u∣0∞=1,得证。
若 x x x为整数,那么 Γ ( x + 1 ) = ∫ 0 ∞ e − u d u x \Gamma(x+1) = \int_{0}^{\infty}e^{-u}\mathrm{d}u^{x} Γ(x+1)=∫0∞e−udux,式子中,微分项 u x u^{x} ux的次幂就可以一直取下来,得到 Γ ( x + 1 ) = ∫ 0 ∞ e − u d u x = x ! ∫ 0 ∞ e − u d u = x ! \Gamma(x+1) = \int_{0}^{\infty}e^{-u}\mathrm{d}u^{x}=x!\int_{0}^{\infty}e^{-u}\mathrm{d}u=x! Γ(x+1)=∫0∞e−udux=x!∫0∞e−udu=x!。
1.18
有一个疑问,式(1.142)中,为何就称那一项为 S D S_D SD的呢?凭什么那一项所代表的的含义就是 D D D维空间中单位球体的表面积呢?我自己想了一下,但是也只是一个头绪,我们看一下题目1.7中的计算过程,其中有一步是算到了 I 2 = ∫ o 2 π ∫ 0 ∞ exp ( − 1 2 σ 2 r 2 ) r d r d θ I^{2}=\int_o^{2 \pi}\int_0^{\infty}\exp(-\frac{1}{2\sigma^2}r^2)r\mathrm{d}r\mathrm{d}\theta I2=∫o2π∫0∞exp(−2σ21r2)rdrdθ,为了和本题结合,我们取 σ 2 = 1 / 2 \sigma^2=1/2 σ2=1/2,则有 I 2 = ∫ o 2 π ∫ 0 ∞ exp ( − r 2 ) r d r d θ I^{2}=\int_o^{2 \pi}\int_0^{\infty}\exp(-r^2)r\mathrm{d}r\mathrm{d}\theta I2=∫o2π∫0∞exp(−r2)rdrdθ,将这个公式对照题目1.18里面的式(1.142),就可以看到, S D S_D SD就是我们算出来的这个双重积分项 ∫ o 2 π ∫ 0 ∞ exp ( − r 2 ) r d r d θ \int_o^{2 \pi}\int_0^{\infty}\exp(-r^2)r\mathrm{d}r\mathrm{d}\theta ∫o2π∫0∞exp(−r2)rdrdθ除以这个积分项内层的积分,简单来说,通过这么一个除法,原本对于整个平面的积分( r r r从 0 0 0取到 ∞ \infty ∞),变成了单位长度,同时又消除了 exp ( − r 2 ) \exp (-r^2) exp(−r2)这一项的积分影响,相当于算了一个在极小角度下的单位半径的扇形的面积,那么再对这个扇形进行角度上的积分,转一圈就得到了单位圆的面积。所以式(1.142)就是这个过程在更高维空间的一个推广。这是我的理解。
首先,根据式(1.126),可以推知, ∏ i = 1 D ∫ − ∞ ∞ e − x i 2 d x i = π D / 2 \prod_{i=1}^{D} \int_{-\infty}^{\infty} e^{-x_{i}^{2}} \mathrm{d} x_{i}=\pi^{D/2} ∏i=1D∫−∞∞e−xi2dxi=πD/2,简单说一下就是,根据式(1.126),我们知道在 D = 2 D=2 D=2的时候, ∏ i = 1 2 ∫ − ∞ ∞ e − x i 2 d x i = π \prod_{i=1}^{2} \int_{-\infty}^{\infty} e^{-x_{i}^{2}} \mathrm{d} x_{i}=\pi ∏i=12∫−∞∞e−xi2dxi=π,所以就比较明显了。这样子我们就有了左式的值,对于右式,可以转化为 S D ∫ 0 ∞ e − r 2 r D − 1 d r = S D 1 2 ∫ 0 ∞ e − r 2 ( r 2 ) D / 2 − 1 d r 2 S_{D} \int_{0}^{\infty} e^{-r^{2}} r^{D-1} \mathrm{d} r=S_D\frac{1}{2}\int_0^{\infty}e^{-r^2}(r^2)^{D/2-1}\mathrm{d}r^2 SD∫0∞e−r2rD−1dr=SD21∫0∞e−r2(r2)D/2−1dr2,根据题目1.17,也就可以看出, S D ∫ 0 ∞ e − r 2 r D − 1 d r = S D 1 2 Γ ( D / 2 ) S_{D} \int_{0}^{\infty} e^{-r^{2}} r^{D-1} \mathrm{d} r=S_D\frac{1}{2}\Gamma(D/2) SD∫0∞e−r2rD−1dr=SD21Γ(D/2),所以 π D / 2 = S D 1 2 Γ ( D / 2 ) \pi^{D/2}=S_D\frac{1}{2}\Gamma(D/2) πD/2=SD21Γ(D/2),所以 S D = 2 π D / 2 Γ ( D / 2 ) S_{D}=\frac{2 \pi^{D / 2}}{\Gamma(D / 2)} SD=Γ(D/2)2πD/2。
同样用简单一点的情况来帮助我们理解复杂的高维情况,比如说我们现在知道一个单位圆的周长,如何得到单位圆的面积呢,已知单位圆周长为 2 π 2\pi 2π,面积就相当于这个单位圆向内放缩后直至变成零点的所有圆的周长积分,同时,还需要了解一个基本事实,那就是在一个 D D D维空间中,其体积的大小正比于 r D r^D rD,而表面积则正比于 r D − 1 r^{D-1} rD−1。现在我们举的例子是在 2 2 2维空间下,因此二维单位圆面积就等于 ∫ 0 1 2 π r 2 − 1 d r = π \int_0^1 2\pi r^{2-1}\mathrm{d}r=\pi ∫012πr2−1dr=π,这也符合我们已知的先验事实。因此, V D = ∫ 0 1 S D r D − 1 d r = S D 1 D r D ∣ 0 1 = S D D V_D=\int_0^1S_D r^{D-1}\mathrm{d}r=S_D \frac{1}{D}r^D|_0^1=\frac{S_D}{D} VD=∫01SDrD−1dr=SDD1rD∣01=DSD。
D = 2 D=2 D=2时, S D = 2 π S_D=2\pi SD=2π, V D = π V_D=\pi VD=π, D = 3 D=3 D=3时, S D = 4 π S_D=4\pi SD=4π, V D = 4 3 π V_D=\frac{4}{3}\pi VD=34π。
多说一点,PRML书中说在高维空间中,球体体积就几乎完全贴近表面分布,其实在 2 2 2维单位圆中这种现象就已经初现端倪了,在刚刚给出的求出单位圆面积的积分过程中,很明显越靠近圆心的单位圆,其周长越小,对整个圆的表面积贡献越小,而半径越接近 1 1 1的圆其周长越大,对整个圆的表面积贡献就越大,这种效应在高维空间中会表现得更加显著,因为往高维变化的过程中,周长正比于半径的 D − 1 D-1 D−1次方,次幂会加剧这种拉扯。感性理解一下就好。
1.19
半径为 a a a的 D D D维超球,体积就是 ∫ 0 a S D r D − 1 d r = S D a D / D \int_0^a S_D r^{D-1}\mathrm{d}r=S_D a^D/D ∫0aSDrD−1dr=SDaD/D,而边长为 2 a 2a 2a的 D D D维超立方体体积很容易求得为 2 D a D 2^Da^D 2DaD,因此 volumeofsphere volumeofcube = S D D 2 D = 2 π D / 2 Γ ( D / 2 ) D 2 D = π D / 2 D 2 D − 1 Γ ( D / 2 ) \frac{\operatorname{volume of sphere} }{\operatorname{volume of cube} }=\frac{S_D}{D2^D}=\frac{\frac{2 \pi^{D / 2}}{\Gamma(D / 2)}}{D2^D}=\frac{\pi^{D / 2}}{D 2^{D-1}\Gamma(D / 2)} volumeofcubevolumeofsphere=D2DSD=D2DΓ(D/2)2πD/2=D2D−1Γ(D/2)πD/2。因此在超高维空间中,单位超球的体积对于包络住这个单位超球的超立方体而言是微不足道的。
第二小问这个直接带进去,很容易看到趋近于 0 0 0,不做赘述。
D D D维空间中,边长为 2 a 2a 2a的超立方体的中心到角落的距离为 ∑ 1 D a 2 = D a 2 = D a \sqrt{\sum_1^D a^2}=\sqrt{Da^2}=\sqrt{D}a ∑1Da2=Da2=Da,所以其与半径之比就是 D \sqrt{D} D。如果你要问为什么这么求,其实依然是可以从简单的情况出发的,比如说在三维空间中,你为了求出立方体的中心到角落的距离,就是使用两次勾股定理,相当于进行两次降维,最终到达角落所处的点。如果从线性代数的角度来说的话,就是我们沿着标准基的方向走。还是比较好理解的。
1.20
式(1.148)可以直观得到,在使用 r r r作为随机变量后,一个随机变量对应的几何形式就是“一周”,例如二维高斯分布中,依题目中均值均为 0 0 0,且方差相等的设置,同一 r r r对应的就是以原点为中心的圆形,因此其对应的概率函数就是“周长”乘以对应的概率值,即 p ( r ) = S D r D − 1 ( 2 π σ 2 ) D / 2 exp ( − r 2 2 σ 2 ) p(r)=\frac{S_D r^{D-1}}{(2\pi \sigma^2)^{D/2}}\exp (-\frac{r^2}{2\sigma^2}) p(r)=(2πσ2)D/2SDrD−1exp(−2σ2r2)。
第二小问 d p ( r ) d r = ( D − 1 ) S D r D − 2 ( 2 π σ 2 ) D / 2 exp ( − r 2 2 σ 2 ) + − S D r D σ 2 ( 2 π σ 2 ) D / 2 exp ( − r 2 2 σ 2 ) = 0 \frac{\mathrm{d}p(r)}{\mathrm{d}r}=\frac{(D-1)S_D r^{D-2}}{(2\pi \sigma^2)^{D/2}}\exp (-\frac{r^2}{2\sigma^2})+\frac{-S_D r^{D}}{\sigma^2(2\pi \sigma^2)^{D/2}}\exp (-\frac{r^2}{2\sigma^2})=0 drdp(r)=(2πσ2)D/2(D−1)SDrD−2exp(−2σ2r2)+σ2(2πσ2)D/2−SDrDexp(−2σ2r2)=0,等式两边除以一些共有项,则有 ( r D − 2 ) ( D − 1 ) = r D σ 2 (r^{D-2})(D-1)=\frac{r^{D}}{\sigma^2} (rD−2)(D−1)=σ2rD,因为 D D D足够大,因此可以转化为 ( r D − 2 ) D ≃ r D σ 2 (r^{D-2})D \simeq \frac{r^{D}}{\sigma^2} (rD−2)D≃σ2rD,所以 r ^ ≃ D σ \hat{r}\simeq \sqrt{D}\sigma r^≃Dσ。
已知 p ( r ) ∝ r D − 1 exp ( − r 2 2 σ 2 ) = exp { − r 2 2 σ 2 + ( D − 1 ) ln ( r ) } p(r) \propto r^{D-1} \exp (-\frac{r^2}{2\sigma^2})=\exp \{-\frac{r^2}{2 \sigma^2}+(D-1)\ln (r)\} p(r)∝rD−1exp(−2σ2r2)=exp{−2σ2r2+(D−1)ln(r)},需要注意,式子中省略了 S D ( 2 π σ 2 ) D / 2 \frac{S_D}{(2\pi \sigma^2)^{D/2}} (2πσ2)D/2SD这一项,在驻点附近,使用泰勒级数展开,以求出 ln ( r ^ + ϵ ) \ln (\hat{r}+\epsilon) ln(r^+ϵ),所以 p ( r ^ + ϵ ) ∝ exp { − ( r ^ + ϵ ) 2 2 σ 2 + ( D − 1 ) ln ( r ^ + ϵ ) } p(\hat{r}+\epsilon) \propto\exp \{-\frac{(\hat{r}+\epsilon)^2}{2 \sigma^2}+(D-1)\ln (\hat{r}+\epsilon)\} p(r^+ϵ)∝exp{−2σ2(r^+ϵ)2+(D−1)ln(r^+ϵ)},而 ln ( r ^ + ϵ ) ≃ ln ( r ^ ) + 1 r ^ ϵ − 1 2 r ^ 2 ϵ 2 \ln (\hat{r}+\epsilon)\simeq \ln(\hat{r})+\frac{1}{\hat{r}}\epsilon-\frac{1}{2\hat{r}^2}\epsilon^2 ln(r^+ϵ)≃ln(r^)+r^1ϵ−2r^21ϵ2,放进去就可以得到 p ( r ^ + ϵ ) ∝ exp { − ( r ^ + ϵ ) 2 2 σ 2 + ( D − 1 ) ( ln ( r ^ ) + 1 r ^ ϵ − 1 2 r ^ 2 ϵ 2 ) } = r ^ D − 1 exp ( − ( r ^ + ϵ ) 2 2 σ 2 + ( D − 1 ) ( 1 r ^ ϵ − 1 2 r ^ 2 ϵ 2 ) ) p(\hat{r}+\epsilon) \propto\exp \{-\frac{(\hat{r}+\epsilon)^2}{2 \sigma^2}+(D-1)( \ln(\hat{r})+\frac{1}{\hat{r}}\epsilon-\frac{1}{2\hat{r}^2}\epsilon^2)\}=\hat{r}^{D-1}\exp(-\frac{(\hat{r}+\epsilon)^2}{2 \sigma^2}+(D-1)(\frac{1}{\hat{r}}\epsilon-\frac{1}{2\hat{r}^2}\epsilon^2)) p(r^+ϵ)∝exp{−2σ2(r^+ϵ)2+(D−1)(ln(r^)+r^1ϵ−2r^21ϵ2)}=r^D−1exp(−2σ2(r^+ϵ)2+(D−1)(r^1ϵ−2r^21ϵ2)),在指数项中代入 r ^ ≃ D σ \hat{r}\simeq \sqrt{D}\sigma r^≃Dσ,同时由于 D D D很大,因此得到 p ( r ^ + ϵ ) ∝ r ^ D − 1 exp ( − ( r ^ + ϵ ) 2 2 σ 2 + 2 r ^ ϵ − ϵ 2 2 σ 2 ) p(\hat{r}+\epsilon) \propto\hat{r}^{D-1}\exp(-\frac{(\hat{r}+\epsilon)^2}{2 \sigma^2}+\frac{2\hat{r}\epsilon-\epsilon^2}{2\sigma^2}) p(r^+ϵ)∝r^D−1exp(−2σ2(r^+ϵ)2+2σ22r^ϵ−ϵ2),也就是 p ( r ^ + ϵ ) ∝ r ^ D − 1 exp ( − r ^ 2 2 σ 2 − 2 ϵ 2 2 σ 2 ) p(\hat{r}+\epsilon) \propto\hat{r}^{D-1}\exp(-\frac{\hat{r}^2}{2 \sigma^2}-\frac{2\epsilon^2}{2\sigma^2}) p(r^+ϵ)∝r^D−1exp(−2σ2r^2−2σ22ϵ2),所以 p ( r ^ + ϵ ) = p ( r ^ ) exp ( − ϵ 2 σ 2 ) p(\hat{r}+\epsilon)=p(\hat{r})\exp(-\frac{\epsilon^2}{\sigma^2}) p(r^+ϵ)=p(r^)exp(−σ2ϵ2)。这里我算出来和题目给的不一样,我检查了好几遍,级数展开那边是没有问题的。留待观察吧。
p ( ∣ ∣ x ∣ ∣ = 0 ) = 1 ( 2 π σ 2 ) D / 2 p(||\mathbf{x}||=\mathbf{0})=\frac{1}{(2\pi \sigma^2)^{D/2}} p(∣∣x∣∣=0)=(2πσ2)D/21, p ( ∣ ∣ x ∣ ∣ = r ^ ) = 1 ( 2 π σ 2 ) D / 2 exp ( − D / 2 ) p(||\mathbf{x}||=\hat{r})=\frac{1}{(2\pi \sigma^2)^{D/2}}\exp(-D/2) p(∣∣x∣∣=r^)=(2πσ2)D/21exp(−D/2),因此 p ( ∣ ∣ x ∣ ∣ = 0 ) = p ( ∣ ∣ x ∣ ∣ = r ^ ) exp ( − D / 2 ) p(||\mathbf{x}||=\mathbf{0})=p(||\mathbf{x}||=\hat{r})\exp(-D/2) p(∣∣x∣∣=0)=p(∣∣x∣∣=r^)exp(−D/2)。
1.21
因为 0 ≤ a ≤ b 0 \le a \le b 0≤a≤b,所以 a 2 ≤ a b a^2 \le ab a2≤ab,所以 a ≤ ( a b ) 1 / 2 a \le (ab)^{1/2} a≤(ab)1/2。
[外链图片转存失败(img-2amJrAcX-1565057031898)(.\curve.jpg)]
这里我按照书中的Figure 1.24绘制了上图,按照最小化误差率进行了分割,那么可以看到,两条概率曲线是有重合的部分的,我设其对应的随机变量取值分别为 K 1 K_1 K1和 K 3 K_3 K3,而分割处对应的随机变量为 K 2 K_2 K2,由式(1.78)可知, p ( mistake ) = ∫ R 1 p ( x , C 2 ) d x + ∫ R 2 p ( x , C 1 ) d x p(\operatorname{mistake})=\int_{\mathcal{R_1}}p(\mathbf{x, \mathcal{C}_2})\mathrm{d}\mathbf{x}+\int_{\mathcal{R_2}}p(\mathbf{x, \mathcal{C}_1})\mathrm{d}\mathbf{x} p(mistake)=∫R1p(x,C2)dx+∫R2p(x,C1)dx,那么根据上面这种图片(左峰是 p ( x , C 1 ) p(\mathbf{x}, \mathcal{C}_1) p(x,C1)),我们更加精确地表达这个式子,即 p ( mistake ) = ∫ K 1 K 2 p ( x , C 2 ) d x + ∫ K 2 K 3 p ( x , C 1 ) d x = p(\operatorname{mistake})=\int_{K_1}^{K_2}p(\mathbf{x, \mathcal{C}_2})\mathrm{d}\mathbf{x}+\int_{K_2}^{K_3}p(\mathbf{x, \mathcal{C}_1})\mathrm{d}\mathbf{x}= p(mistake)=∫K1K2p(x,C2)dx+∫K2K3p(x,C1)dx= a a a,而在随机变量取值 K 1 K_1 K1至 K 3 K_3 K3之间的全部面积,其面积大小为 b = ∫ K 1 K 2 p ( x , C 1 ) d x + ∫ K 2 K 3 p ( x , C 2 ) d x b=\int_{K_1}^{K_2}p(\mathbf{x, \mathcal{C}_1})\mathrm{d}\mathbf{x}+\int_{K_2}^{K_3}p(\mathbf{x, \mathcal{C}_2})\mathrm{d}\mathbf{x} b=∫K1K2p(x,C1)dx+∫K2K3p(x,C2)dx,可以看到 0 ≤ a ≤ b 0 \le a \le b 0≤a≤b,因此就有 p ( mistake ) ≤ ( a b ) 1 / 2 p(\operatorname{mistake}) \le (ab)^{1/2} p(mistake)≤(ab)1/2,积分决定了两项之间是否能够相乘,因此就有 ( a b ) 1 / 2 = ∫ K 1 K 3 { p ( x , C 1 ) p ( x , C 2 ) } 1 / 2 d x (ab)^{1/2}=\int_{K_1}^{K_3}\{p(\mathbf{x, \mathcal{C}_1})p(\mathbf{x, \mathcal{C}_2})\}^{1/2}\mathrm{d}\mathbf{x} (ab)1/2=∫K1K3{p(x,C1)p(x,C2)}1/2dx,从而得证。
1.22
根据式(1.80)可知,当损失矩阵按照题目的意思设置时, E [ L ] = ∑ k ∑ j ( j ≠ k ) ∫ R j p ( x , C k ) d x \mathbb{E}[L]=\sum_k\sum_{j(j \ne k)}\int_{\mathcal{R}_j}p(\mathbf{x},\mathcal{C}_k)\mathrm{d}\mathbf{x} E[L]=∑k∑j(j̸=k)∫Rjp(x,Ck)dx,此时该式就相当于最小化 p ( mistake ) p(\operatorname{mistake}) p(mistake)因此也就相当于退化为,谁的后验概率大就取谁的值。简单来说就是,这种损失矩阵对于所有的错误判断都一视同仁,权重都是 1 1 1,那这时候有没有这个损失矩阵都没差别了。也就变成了前一小节所说的最小化错误分类概率。
1.23
对于某一类,如 C j \mathcal{C}_j Cj,按照式(1.81),就相当于对该类最小化 ∑ k L k j p ( C k ∣ x ) \sum_k L_{kj}p(\mathcal{C}_k|\mathbf{x}) ∑kLkjp(Ck∣x),而 p ( C k ∣ x ) = p ( x ∣ C k ) p ( C k ) p ( x ) p(\mathcal{C}_k|\mathbf{x})=\frac{p(\mathbf{x}|\mathcal{C}_k)p(\mathcal{C}_k)}{p(\mathbf{x})} p(Ck∣x)=p(x)p(x∣Ck)p(Ck),所以就要最小化 ∑ k L k j p ( x ∣ C k ) p ( C k ) p ( x ) \sum_k L_{kj}\frac{p(\mathbf{x}|\mathcal{C}_k)p(\mathcal{C}_k)}{p(\mathbf{x})} ∑kLkjp(x)p(x∣Ck)p(Ck)。
1.24
这题我刚开始做是比较懵逼的,主要是看不懂题目,太难翻译了有木有。来,我给大家准确梳理一下这道题的意思,分类问题中可以引入损失的权重来计算期望损失,并尽可能最小化该值,先不管什么拒绝选项,那我们可以根据式(1.81)知道,当新来了一个 x \mathbf{x} x的时候,我要做的就是遍历所有的 j j j,然后看哪个 j j j带进去的时候, ∑ k L k j p ( C k ∣ x ) \sum_kL_{kj}p(\mathcal{C}_k|\mathbf{x}) ∑kLkjp(Ck∣x)能取到最小值,而且按照书中的说法,决策论干的这些个事都很简单,毕竟推断的阶段,把那些个求解过程中需要的概率分布都给决策论准备好了。那么现在,我们再引入拒绝选项这个概念,所谓拒绝选项的含义就是,比如说在二分类问题中,就比如上面那张图片,在 K 2 K_2 K2处,这俩的概率是完全相同的,如果从后验概率的角度来说,就是这俩“五五开”。这种时候,数学也很为难,拒绝选项就可以在这种接近于五五开的情况下做出拒绝判断的选择。而题目中给出的 λ \lambda λ就是在使用期望分类损失之后引入的“损失阈值”,说实话,光看题目我愣是没有抿出 λ \lambda λ是这个意思,看了solution又悟了好久才把作者的整个思路弄明白。那就很简单了,所谓的决策就是,在能够使得 ∑ k L k j p ( C k ∣ x ) \sum_kL_{kj}p(\mathcal{C}_k|\mathbf{x}) ∑kLkjp(Ck∣x)取得最小值的情况下,如果该值还是超过 λ \lambda λ,就拒绝,其他情况就分类为能够使得 ∑ k L k j p ( C k ∣ x ) \sum_kL_{kj}p(\mathcal{C}_k|\mathbf{x}) ∑kLkjp(Ck∣x)最小的那个第 j j j类。在 L k j = 1 − I k j L_{kj}=1-I_{kj} Lkj=1−Ikj的情况下,与题目1.22一致,此时所有后验分布一视同仁,不厚此薄彼,根据sum rule,就可以得到 ∑ k p ( C k ∣ x ) = 1 − p ( C j ∣ x ) \sum_kp(\mathcal{C}_k|\mathbf{x})=1-p(\mathcal{C}_j|\mathbf{x}) ∑kp(Ck∣x)=1−p(Cj∣x),这时候,就是最开始我们接触的没有权重的拒绝选项了。对比Figure 1.26,也很容易得到 λ = 1 − θ \lambda = 1-\theta λ=1−θ。
1.25
已知 E [ L ( t , y ( x ) ) ] = ∬ ∣ ∣ y ( x ) − t ∣ ∣ 2 p ( x , t ) d x d t \mathbb{E}[L(\mathbf{t},\mathbf{y}(\mathbf{x}))]=\iint||\mathbf{y}(\mathbf{x})-\mathbf{t}||^2p(\mathbf{x},\mathbf{t})\mathrm{d}\mathbf{x}\mathrm{d}\mathbf{t} E[L(t,y(x))]=∬∣∣y(x)−t∣∣2p(x,t)dxdt,所以可得 δ E [ L ( t , y ( x ) ) ] δ y ( x ) = 2 ∫ { y ( x ) − t } p ( x , t ) d t = 0 \frac{\delta \mathbb{E}[L(\mathbf{t},\mathbf{y}(\mathbf{x}))]}{\delta \mathbf{y}(\mathbf{x})}=2\int \{\mathbf{y}(\mathbf{x})-\mathbf{t} \} p(\mathbf{x},\mathbf{t})\mathrm{d}\mathbf{t}=0 δy(x)δE[L(t,y(x))]=2∫{y(x)−t}p(x,t)dt=0,所以可得 y ( x ) ∫ p ( x , t ) d t = ∫ t p ( x , t ) d t \mathbf{y}(\mathbf{x}) \int p(\mathbf{x},\mathbf{t}) \mathrm{d} \mathbf{t}=\int \mathbf{t} p(\mathbf{x},\mathbf{t}) \mathrm{d} \mathbf{t} y(x)∫p(x,t)dt=∫tp(x,t)dt。根据sum rule,可推知 y ( x ) p ( x ) = ∫ t p ( x , t ) d t \mathbf{y}(\mathbf{x}) p(\mathbf{x})=\int \mathbf{t} p(\mathbf{x},\mathbf{t}) \mathrm{d} \mathbf{t} y(x)p(x)=∫tp(x,t)dt,所以 y ( x ) = ∫ t p ( x , t ) d t p ( x ) = ∫ t p ( t ∣ x ) d t = E t [ t ∣ x ] \mathbf{y}(\mathbf{x})= \frac{ \int \mathbf{t} p(\mathbf{x},\mathbf{t}) \mathrm{d} \mathbf{t} }{ p(\mathbf{x})}= \int \mathbf{t} p(\mathbf{t}|\mathbf{x}) \mathrm{d} \mathbf{t}=\mathbb{E}_{\mathbf{t}}[\mathbf{t} | \mathbf{x}] y(x)=p(x)∫tp(x,t)dt=∫tp(t∣x)dt=Et[t∣x]。很明显,如果目标量由向量 t \mathbf{t} t变为标量 t t t,则对应的结果就退化为式(1.89),即 y ( x ) = E t [ t ∣ x ] y(\mathbf{x})=\mathbb{E}_{t}[t | \mathbf{x}] y(x)=Et[t∣x]。
1.26
这道题很简单,依葫芦画瓢即可,那些过程和繁杂的公式我宁可不耗费时间去把它打出来,我有一个疑问,那就是为什么中间的那个交叉项消失了?
先来看式(1.90)的推导过程中的那个式子 { y ( x ) − t } 2 = { y ( x ) − E [ t ∣ x ] } 2 + 2 { y ( x ) − E [ t ∣ x ] } { E [ t ∣ x ] − t } + { E [ t ∣ x ] − t } 2 \{ y(\mathbf{x}) - t \}^2 = \{ y(\mathbf{x}) - \mathbb{E}[t|\mathbf{x}] \}^2 + 2\{ y(\mathbf{x}) - \mathbb{E}[t|\mathbf{x}] \} \{ \mathbb{E}[t|\mathbf{x}] - t \} + \{ \mathbb{E}[t|\mathbf{x}] - t \}^2 {y(x)−t}2={y(x)−E[t∣x]}2+2{y(x)−E[t∣x]}{E[t∣x]−t}+{E[t∣x]−t}2,中间的交叉项在积分过程中即 ∬ 2 { y ( x ) − E [ t ∣ x ] } { E [ t ∣ x ] − t } p ( x , t ) d x d t \iint 2\{ y(\mathbf{x}) - \mathbb{E}[t|\mathbf{x}] \} \{ \mathbb{E}[t|\mathbf{x}] - t \} p(\mathbf{x},t)\mathrm{d}\mathbf{x}\mathrm{d}t ∬2{y(x)−E[t∣x]}{E[t∣x]−t}p(x,t)dxdt,注意,式子中, E [ t ∣ x ] \mathbb{E}[t|\mathbf{x}] E[t∣x]是 E t [ t ∣ x ] \mathbb{E}_t[t|\mathbf{x}] Et[t∣x]的简写,所以 E [ t ∣ x ] \mathbb{E}[t|\mathbf{x}] E[t∣x]是关于 x \mathbf{x} x的表达式,中间项的积分即 2 ∬ { y ( x ) E [ t ∣ x ] − y ( x ) t − ( E [ t ∣ x ] ) 2 + t E [ t ∣ x ] } p ( x , t ) d x d t 2\iint \{y(\mathbf{x})\mathbb{E}[t|\mathbf{x}] - y(\mathbf{x}) t - (\mathbb{E}[t|\mathbf{x}])^2 + t\mathbb{E}[t|\mathbf{x}] \} p(\mathbf{x},t)\mathrm{d}\mathbf{x}\mathrm{d}t 2∬{y(x)E[t∣x]−y(x)t−(E[t∣x])2+tE[t∣x]}p(x,t)dxdt,这里说白了就是四项之和的双重积分,一项一项来看,忽略掉最前面的系数 2 2 2,第一项为 ∬ y ( x ) E [ t ∣ x ] p ( x , t ) d x d t = ∫ y ( x ) E [ t ∣ x ] ∫ p ( x , t ) d t d x = ∫ y ( x ) E [ t ∣ x ] p ( x ) d x \iint y(\mathbf{x})\mathbb{E}[t|\mathbf{x}]p(\mathbf{x},t)\mathrm{d}\mathbf{x}\mathrm{d}t=\int y(\mathbf{x})\mathbb{E}[t|\mathbf{x}] \int p(\mathbf{x},t)\mathrm{d}t \mathrm{d}\mathbf{x}=\int y(\mathbf{x}) \mathbb{E}[t|\mathbf{x}]p(\mathbf{x})\mathrm{d}\mathbf{x} ∬y(x)E[t∣x]p(x,t)dxdt=∫y(x)E[t∣x]∫p(x,t)dtdx=∫y(x)E[t∣x]p(x)dx,第二项为 ∬ − y ( x ) t p ( x , t ) d x d t = ∫ − y ( x ) p ( x ) ∫ t p ( x , t ) p ( x ) d t d x = ∫ − y ( x ) p ( x ) E [ t ∣ x ] d x \iint -y(\mathbf{x})t p(\mathbf{x},t) \mathrm{d}\mathbf{x}\mathrm{d}t=\int -y(\mathbf{x})p(\mathbf{x}) \int t\frac{p(\mathbf{x},t)}{p(\mathbf{x})}\mathrm{d}t \mathrm{d}\mathbf{x}=\int -y(\mathbf{x}) p(\mathbf{x})\mathbb{E}[t|\mathbf{x}]\mathrm{d}\mathbf{x} ∬−y(x)tp(x,t)dxdt=∫−y(x)p(x)∫tp(x)p(x,t)dtdx=∫−y(x)p(x)E[t∣x]dx,这样一来,第一项和第二项就抵消了,第三项为 ∬ − ( E [ t ∣ x ] ) 2 p ( x , t ) d x d t = ∫ − ( E [ t ∣ x ] ) 2 ∫ p ( x , t ) d t d x = ∫ − ( E [ t ∣ x ] ) 2 p ( x ) d x \iint -(\mathbb{E}[t|\mathbf{x}])^2p(\mathbf{x},t)\mathrm{d}\mathbf{x}\mathrm{d}t=\int -(\mathbb{E}[t|\mathbf{x}])^2 \int p(\mathbf{x},t)\mathrm{d}t \mathrm{d}\mathbf{x}=\int -(\mathbb{E}[t|\mathbf{x}])^2p(\mathbf{x})\mathrm{d}\mathbf{x} ∬−(E[t∣x])2p(x,t)dxdt=∫−(E[t∣x])2∫p(x,t)dtdx=∫−(E[t∣x])2p(x)dx,第四项为 ∬ t E [ t ∣ x ] p ( x , t ) d x d t = ∫ E [ t ∣ x ] p ( x ) ∫ t p ( x , t ) p ( x ) d t d x = ∫ ( E [ t ∣ x ] ) 2 p ( x ) d x \iint t\mathbb{E}[t|\mathbf{x}]p(\mathbf{x},t)\mathrm{d}\mathbf{x}\mathrm{d}t=\int \mathbb{E}[t|\mathbf{x}] p(\mathbf{x}) \int t \frac{p(\mathbf{x},t)}{p(\mathbf{x})}\mathrm{d}t \mathrm{d}\mathbf{x}=\int (\mathbb{E}[t|\mathbf{x}])^2p(\mathbf{x})\mathrm{d}\mathbf{x} ∬tE[t∣x]p(x,t)dxdt=∫E[t∣x]p(x)∫tp(x)p(x,t)dtdx=∫(E[t∣x])2p(x)dx,这样一来,第三项和第四项也抵消了,如此即可得到式(1.90)的结果。
本题实际上是一样的推导过程,只是由于变成了向量,在处理时需要注意中间项变为了 ( y ( x ) − E [ t ∣ x ] ) T ( E [ t ∣ x ] − t ) + ( E [ t ∣ x ] − t ) T ( y ( x ) − E [ t ∣ x ] ) (\mathbf{y}(\mathbf{x})-\mathbb{E}[\mathbf{t}|\mathbf{x}])^{\operatorname{T}}(\mathbb{E}[\mathbf{t}|\mathbf{x}] - \mathbf{t}) + (\mathbb{E}[\mathbf{t}|\mathbf{x}] - \mathbf{t})^{\operatorname{T}}(\mathbf{y}(\mathbf{x})-\mathbb{E}[\mathbf{t}|\mathbf{x}]) (y(x)−E[t∣x])T(E[t∣x]−t)+(E[t∣x]−t)T(y(x)−E[t∣x]),因此最终结果可以写成 E [ L ] = ∫ ∣ ∣ y ( x ) − E [ t ∣ x ] ∣ ∣ 2 p ( x ) d x + ∫ var [ t ∣ x ] p ( x ) d x \mathbb{E}[L]=\int ||\mathbf{y}(\mathbf{x}) - \mathbb{E}[\mathbf{t}|\mathbf{x}]||^2p(\mathbf{x})\mathrm{d}\mathbf{x}+\int \operatorname{var}[\mathbf{t}|\mathbf{x}]p(\mathbf{x})\mathrm{d}\mathbf{x} E[L]=∫∣∣y(x)−E[t∣x]∣∣2p(x)dx+∫var[t∣x]p(x)dx。
1.27
实话说,看到这题的我也是懵逼的,说起来很简单,就是要保证 E [ L q ] \mathbb{E}[L_q] E[Lq]可微,且其微分等于 0 0 0是有解的。但是问题来了,对谁微分呢?考虑到问题中问的是 y ( x ) y(\mathbf{x}) y(x)需要满足的条件,而双重积分的微分也是相当棘手,所以最终我还是翻看了solution。作者的意思是既然 y ( x ) y(\mathbf{x}) y(x)是由我们选择的,同时 p ( t , x ) p(t,\mathbf{x}) p(t,x)正比于 p ( t ∣ x ) p(t|\mathbf{x}) p(t∣x),那么这个双重积分也就可以表达为 ∫ ∣ y ( x ) − t ∣ q p ( t ∣ x ) d t \int |y(\mathbf{{x}})-t|^q p(t|\mathbf{x})\mathrm{d}t ∫∣y(x)−t∣qp(t∣x)dt,在这个式子基础上,对 y ( x ) y(\mathbf{x}) y(x)进行微分,得到 ∫ q ∣ y ( x ) − t ∣ q − 1 sign ( y ( x ) − t ) p ( t ∣ x ) d t = 0 \int q |y(\mathbf{{x}})-t|^{q-1} \operatorname{sign}(y(\mathbf{{x}})-t)p(t|\mathbf{x})\mathrm{d}t=0 ∫q∣y(x)−t∣q−1sign(y(x)−t)p(t∣x)dt=0,本来走到这一步我觉得我勉强能够理解(其实已经很困难了好嘛),作者又一波神奇操作,将其变为 q ( ∫ − ∞ y ( x ) ∣ y ( x ) − t ∣ q − 1 p ( t ∣ x ) d t − ∫ y ( x ) ∞ ∣ y ( x ) − t ∣ q − 1 p ( t ∣ x ) d t ) = 0 q(\int_{- \infty}^{y(\mathbf{x})}|y(\mathbf{{x}})-t|^{q-1}p(t|\mathbf{x})\mathrm{d}t-\int^{\infty}_{y(\mathbf{x})}|y(\mathbf{{x}})-t|^{q-1}p(t|\mathbf{x})\mathrm{d}t)=0 q(∫−∞y(x)∣y(x)−t∣q−1p(t∣x)dt−∫y(x)∞∣y(x)−t∣q−1p(t∣x)dt)=0,所以要满足的条件就是 ∫ − ∞ y ( x ) ∣ y ( x ) − t ∣ q − 1 p ( t ∣ x ) d t = ∫ y ( x ) ∞ ∣ y ( x ) − t ∣ q − 1 p ( t ∣ x ) d t \int_{- \infty}^{y(\mathbf{x})}|y(\mathbf{{x}})-t|^{q-1}p(t|\mathbf{x})\mathrm{d}t=\int^{\infty}_{y(\mathbf{x})}|y(\mathbf{{x}})-t|^{q-1}p(t|\mathbf{x})\mathrm{d}t ∫−∞y(x)∣y(x)−t∣q−1p(t∣x)dt=∫y(x)∞∣y(x)−t∣q−1p(t∣x)dt。真的看不大懂每一步操作的理由是什么。
好了我编不下去了,上面几乎就是把solution翻译了一遍,我选择放弃,再想想看。
看了一段时间,稍微有了一些想法,可以看一下式(1.88),我们不妨就从这个角度切入。为什么选择这个角度?因为正是式(1.88)到式(1.89)的推导过程,推出了在 q = 2 q=2 q=2的情况下,条件均值为 y ( x ) y(\mathbf{x}) y(x)最优解。因此,我们二话不说依葫芦画瓢进行微分(这里使用到了变分法,不做赘述),得到了 δ E [ L ] δ y ( x ) = q ∫ ∣ y ( x ) − t ∣ q − 1 sign ( y ( x ) − t ) p ( x , t ) d t = 0 \frac{\delta \mathbb{E}[L]}{\delta y(\mathbf{x})}=q\int |y(\mathbf{x})-t|^{q-1} \operatorname{sign}(y(\mathbf{{x}})-t) p(\mathbf{x},t)\mathrm{d}t=0 δy(x)δE[L]=q∫∣y(x)−t∣q−1sign(y(x)−t)p(x,t)dt=0。那么之所以要使用 y ( x ) y(\mathbf{x}) y(x)来进行区间的划分,也是为了简化该式的符号项,这才有了 q ( ∫ − ∞ y ( x ) ( t − y ( x ) ) q − 1 p ( t ∣ x ) d t + ∫ y ( x ) ∞ ( y ( x ) − t ) q − 1 p ( t ∣ x ) d t ) = 0 q(\int_{- \infty}^{y(\mathbf{x})}(t-y(\mathbf{{x}}))^{q-1}p(t|\mathbf{x})\mathrm{d}t+\int^{\infty}_{y(\mathbf{x})}(y(\mathbf{{x}})-t)^{q-1}p(t|\mathbf{x})\mathrm{d}t)=0 q(∫−∞y(x)(t−y(x))q−1p(t∣x)dt+∫y(x)∞(y(x)−t)q−1p(t∣x)dt)=0,这样符号关系就对了,之后再转换一下正负号,将两部分分别挪至等号两侧,就有了 ∫ − ∞ y ( x ) ( y ( x ) − t ) q − 1 p ( t ∣ x ) d t = ∫ y ( x ) ∞ ( y ( x ) − t ) q − 1 p ( t ∣ x ) d t \int_{- \infty}^{y(\mathbf{x})}(y(\mathbf{{x}})-t)^{q-1}p(t|\mathbf{x})\mathrm{d}t=\int^{\infty}_{y(\mathbf{x})}(y(\mathbf{{x}})-t)^{q-1}p(t|\mathbf{x})\mathrm{d}t ∫−∞y(x)(y(x)−t)q−1p(t∣x)dt=∫y(x)∞(y(x)−t)q−1p(t∣x)dt。
如果 q = 1 q=1 q=1,则有 y ( x ) y(\mathbf{x}) y(x)满足 ∫ − ∞ y ( x ) p ( t ∣ x ) d t = ∫ y ( x ) ∞ p ( t ∣ x ) d t \int_{- \infty}^{y(\mathbf{x})}p(t|\mathbf{x})\mathrm{d}t=\int^{\infty}_{y(\mathbf{x})}p(t|\mathbf{x})\mathrm{d}t ∫−∞y(x)p(t∣x)dt=∫y(x)∞p(t∣x)dt,也就是说 p ( t ∣ x ) p(t|\mathbf{x}) p(t∣x)在 t < y ( x ) t<y(\mathbf{x}) t<y(x)的区域中与 t ≥ p ( t ∣ x ) t \ge p(t|\mathbf{x}) t≥p(t∣x)的区域上积分大小相同,此时 y ( x ) y(\mathbf{x}) y(x)所在的位置也就是题目所谓的条件中数的含义。
如果 q → 0 q \to 0 q→0, ∣ y ( x ) − t ∣ q |y(\mathbf{{x}})-t|^{q} ∣y(x)−t∣q趋近于 1 1 1,这样的话 ∫ ∣ y ( x ) − t ∣ q p ( t ∣ x ) d t \int |y(\mathbf{{x}})-t|^q p(t|\mathbf{x})\mathrm{d}t ∫∣y(x)−t∣qp(t∣x)dt也就趋近于 1 1 1。但是当 y ( x ) y(\mathbf{{x}}) y(x)与 t t t之间的距离同样非常靠近时, ∣ y ( x ) − t ∣ q |y(\mathbf{{x}})-t|^{q} ∣y(x)−t∣q趋近于 1 1 1这一点就要打个问号了,这种情况下, ∣ y ( x ) − t ∣ q |y(\mathbf{{x}})-t|^{q} ∣y(x)−t∣q会比 1 1 1还要小一些(可以使用MATLAB进行验证)。这样一来,能够使得这个“小一些”足够小的 y ( x ) y(\mathbf{{x}}) y(x)也就要尽可能靠近出现概率最大的 t t t值,此时,相当于 y ( x ) y(\mathbf{{x}}) y(x)就是条件分布的众数。
1.28
n n n为正整数为前提条件下, h ( p 2 ) = h ( p ) + h ( p ) = 2 h ( p ) h(p^2)=h(p)+h(p)=2h(p) h(p2)=h(p)+h(p)=2h(p), h ( p n ) = h ( p ) + ⋯ + h ( p ) = n h ( p ) h(p^n)=h(p)+\dots+h(p)=nh(p) h(pn)=h(p)+⋯+h(p)=nh(p)。
m m m为正整数为前提条件下, h ( p n / m ) = n h ( p 1 / m ) = n m m h ( p 1 / m ) = n m h ( p ) h(p^{n/m})=nh(p^{1/m})=\frac{n}{m}mh(p^{1/m})=\frac{n}{m}h(p) h(pn/m)=nh(p1/m)=mnmh(p1/m)=mnh(p)。这里你可以将 p 1 / m p^{1/m} p1/m看成上面公式中的 p p p,视其为一个整体,因为题中对 p p p是没有任何要求的。这样一来,就可以看到,对于任何一个正整数 x x x, h ( p x ) = x h ( p ) h(p^x)=xh(p) h(px)=xh(p)。
最后一小问没啥意思,不证了。
1.29
H
[
x
]
=
∑
i
=
1
M
−
p
(
x
i
)
ln
p
(
x
i
)
=
∑
i
=
1
M
p
(
x
i
)
ln
p
(
1
x
i
)
\mathbf{H}[x]=\sum_{i=1}^M -p(x_i) \ln p(x_i) = \sum_{i=1}^M p(x_i) \ln p(\frac{1}{x_i})
H[x]=∑i=1M−p(xi)lnp(xi)=∑i=1Mp(xi)lnp(xi1),
ln
\ln
ln函数是一个concave函数,因此
f
(
∑
i
=
1
M
λ
i
x
i
)
≥
∑
i
=
1
M
λ
i
f
(
x
i
)
f(\sum_{i=1}^{M}\lambda_ix_i) \ge \sum_{i=1}^{M}\lambda_i f(x_i)
f(∑i=1Mλixi)≥∑i=1Mλif(xi),这里
p
(
x
i
)
p(x_i)
p(xi)即
λ
i
\lambda_i
λi,满足
λ
i
\lambda_i
λi所需的条件,因此
∑
i
=
1
M
p
(
x
i
)
ln
(
1
p
(
x
i
)
)
≤
ln
(
∑
i
=
1
M
p
(
x
i
)
1
p
(
x
i
)
=
ln
M
)
\sum_{i=1}^{M} p(x_i) \ln(\frac{1}{p(x_i)}) \le \ln(\sum_{i=1}^M p(x_i) \frac{1}{p(x_i)}=\ln M)
∑i=1Mp(xi)ln(p(xi)1)≤ln(∑i=1Mp(xi)p(xi)1=lnM)。
所以
H
[
x
]
≤
ln
M
\mathbf{H}[x] \le \ln M
H[x]≤lnM。
1.30
在 KL \operatorname{KL} KL散度的表达中,我一直有一个疑问,就是为什么我们预估的分布 q ( x ) q(x) q(x)的信息熵是 − ∫ p ( x ) ln q ( x ) d x -\int p(\mathbf{x}) \ln q(\mathbf{x}) \mathrm{d}\mathbf{x} −∫p(x)lnq(x)dx,而不是 − ∫ q ( x ) ln p ( x ) d x -\int q(\mathbf{x}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{x} −∫q(x)lnp(x)dx,最终觉得这是因为按照后者那样去写的话,所谓的编码平均附加信息量这个表达式,也就是 KL \operatorname{KL} KL散度的数学表达式并不具有良好的数学性质,利用不到convex函数的相关性质。因此才使用了前者那种表达,但是我还想从更加合理的角度来看待这样做的原因。
KL ( p ∣ ∣ q ) = − ∫ p ( x ) ln { q ( x ) p ( x ) } d x = ∫ p ( x ) { ln p ( x ) − ln q ( x ) } d x = ∫ p ( x ) { ln 1 ( 2 π σ 2 ) 1 / 2 exp ( − ( x − μ ) 2 2 σ 2 ) − ln 1 ( 2 π s 2 ) 1 / 2 exp ( − ( x − m ) 2 2 s 2 ) } d x = ∫ p ( x ) { − ln ( 2 π σ 2 ) 1 / 2 − ( x − μ ) 2 2 σ 2 + ln ( 2 π s 2 ) 1 / 2 + ( x − m ) 2 2 s 2 } d x = ∫ p ( x ) { ln s σ } d x − 1 2 σ 2 ∫ p ( x ) ( x − μ ) 2 d x + 1 2 s 2 ∫ p ( x ) ( x − m ) 2 d x = ln s σ + 1 2 s 2 ∫ p ( x ) ( x − m ) 2 d x − 1 2 = ln s σ + 1 2 s 2 ∫ p ( x ) ( x 2 − 2 m x + m 2 ) d x − 1 2 = ln s σ + 1 2 s 2 ( μ 2 + σ 2 − 2 m μ + m 2 ) − 1 2 = ln s σ + ( μ − m ) 2 + σ 2 2 s 2 − 1 2 \begin{aligned} \operatorname{KL}(p||q)&=-\int p(x) \ln\{ \frac{q(x)}{p(x)} \} \mathrm{d}x \\ &= \int p(x) \{\ln p(x) - \ln q(x) \} \mathrm{d}x \\ &= \int p(x) \{ \ln \frac{1}{(2 \pi \sigma^2)^{1/2}} \exp(-\frac{(x-\mu)^2}{2\sigma^2}) - \ln \frac{1}{(2 \pi s^2)^{1/2}} \exp(-\frac{(x-m)^2}{2s^2}) \} \mathrm{d}x \\ &= \int p(x) \{ - \ln (2 \pi \sigma^2)^{1/2} - \frac{(x-\mu)^2}{2\sigma^2} + \ln (2 \pi s^2)^{1/2} + \frac{(x-m)^2}{2s^2} \} \mathrm{d}x \\ &= \int p(x) \{ \ln \frac{s}{\sigma} \} \mathrm{d}x - \frac{1}{2\sigma^2}\int p(x) (x-\mu)^2 \mathrm{d}x + \frac{1}{2s^2}\int p(x) (x-m)^2 \mathrm{d}x\\ &= \ln \frac{s}{\sigma} + \frac{1}{2s^2}\int p(x) (x-m)^2 \mathrm{d}x - \frac{1}{2}\\ &= \ln \frac{s}{\sigma} + \frac{1}{2s^2}\int p(x) (x^2 - 2mx + m^2) \mathrm{d}x - \frac{1}{2}\\ &= \ln \frac{s}{\sigma} + \frac{1}{2s^2}(\mu^2 + \sigma^2 - 2m \mu + m^2) - \frac{1}{2}\\ &= \ln \frac{s}{\sigma} + \frac{(\mu - m)^2 + \sigma^2}{2s^2} - \frac{1}{2} \end{aligned} KL(p∣∣q)=−∫p(x)ln{p(x)q(x)}dx=∫p(x){lnp(x)−lnq(x)}dx=∫p(x){ln(2πσ2)1/21exp(−2σ2(x−μ)2)−ln(2πs2)1/21exp(−2s2(x−m)2)}dx=∫p(x){−ln(2πσ2)1/2−2σ2(x−μ)2+ln(2πs2)1/2+2s2(x−m)2}dx=∫p(x){lnσs}dx−2σ21∫p(x)(x−μ)2dx+2s21∫p(x)(x−m)2dx=lnσs+2s21∫p(x)(x−m)2dx−21=lnσs+2s21∫p(x)(x2−2mx+m2)dx−21=lnσs+2s21(μ2+σ2−2mμ+m2)−21=lnσs+2s2(μ−m)2+σ2−21
1.31
H [ x , y ] = − ∬ p ( x , y ) ln p ( x , y ) d y d x = − ∬ p ( x , y ) ln p ( y ∣ x ) d y d x − ∬ p ( x , y ) ln p ( x ) d y d x = − ∬ p ( x , y ) ln p ( y ∣ x ) d y d x − ∫ ln p ( x ) ∫ p ( x , y ) d y d x = H [ y ∣ x ] − ∫ ln p ( x ) p ( x ) d x = H [ y ∣ x ] + H [ x ] \begin{aligned} \operatorname{H}[\mathbf{x}, \mathbf{y}] &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{y}| \mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{y}| \mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} -\int \ln p(\mathbf{x}) \int p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{y}| \mathbf{x}] - \int \ln p(\mathbf{x}) p(\mathbf{x}) \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{y}| \mathbf{x}] + \operatorname{H}[\mathbf{x}] \\ \end{aligned} H[x,y]=−∬p(x,y)lnp(x,y)dydx=−∬p(x,y)lnp(y∣x)dydx−∬p(x,y)lnp(x)dydx=−∬p(x,y)lnp(y∣x)dydx−∫lnp(x)∫p(x,y)dydx=H[y∣x]−∫lnp(x)p(x)dx=H[y∣x]+H[x]
H [ x ] + H [ y ] = − ∫ p ( x ) ln p ( x ) d x − ∫ p ( y ) ln p ( y ) d y = − ∬ p ( x , y ) ln p ( x ) d y d x − ∬ p ( x , y ) ln p ( y ) d y d x = − ∬ p ( x , y ) ln p ( x ) p ( y ) d y d x \begin{aligned} \operatorname{H}[\mathbf{x}] + \operatorname{H}[\mathbf{y}] &= -\int p(\mathbf{x}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{x} -\int p(\mathbf{y}) \ln p(\mathbf{y}) \mathrm{d}\mathbf{y} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x})p(\mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \end{aligned} H[x]+H[y]=−∫p(x)lnp(x)dx−∫p(y)lnp(y)dy=−∬p(x,y)lnp(x)dydx−∬p(x,y)lnp(y)dydx=−∬p(x,y)lnp(x)p(y)dydx
要证明
H
[
x
,
y
]
≤
H
[
x
]
+
H
[
y
]
\operatorname{H}[\mathbf{x}, \mathbf{y}] \le \operatorname{H}[\mathbf{x}] + \operatorname{H}[\mathbf{y}]
H[x,y]≤H[x]+H[y],即变为证明
−
∬
p
(
x
,
y
)
ln
p
(
x
,
y
)
d
y
d
x
≤
−
∬
p
(
x
,
y
)
ln
p
(
x
)
p
(
y
)
d
y
d
x
-\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \le -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x})p(\mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x}
−∬p(x,y)lnp(x,y)dydx≤−∬p(x,y)lnp(x)p(y)dydx
根据互信息的定义,我们有
I
[
x
,
y
]
=
KL
(
p
(
x
,
y
)
∣
∣
p
(
x
)
p
(
y
)
)
=
−
∬
p
(
x
,
y
)
ln
(
p
(
x
)
p
(
y
)
p
(
x
,
y
)
)
d
y
d
x
\begin{aligned}I[\mathbf{x}, \mathbf{y}] &= \operatorname{KL}(p(\mathbf{x}, \mathbf{y})||p(\mathbf{x})p(\mathbf{y})) \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})p(\mathbf{y})}{p(\mathbf{x}, \mathbf{y})}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \end{aligned}
I[x,y]=KL(p(x,y)∣∣p(x)p(y))=−∬p(x,y)ln(p(x,y)p(x)p(y))dydx
且
I
[
x
,
y
]
≥
0
I[\mathbf{x}, \mathbf{y}] \ge 0
I[x,y]≥0,当且仅当两变量互相独立时等号才成立。所以
−
∬
p
(
x
,
y
)
ln
(
p
(
x
)
p
(
y
)
p
(
x
,
y
)
)
d
y
d
x
=
−
∬
p
(
x
,
y
)
ln
(
p
(
x
)
p
(
y
)
)
d
y
d
x
+
∬
p
(
x
,
y
)
ln
p
(
x
,
y
)
d
y
d
x
≥
0
\begin{gathered} -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})p(\mathbf{y})}{p(\mathbf{x}, \mathbf{y})}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} =\\ -\iint p(\mathbf{x}, \mathbf{y}) \ln (p(\mathbf{x})p(\mathbf{y})) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} + \iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \ge 0 \end{gathered}
−∬p(x,y)ln(p(x,y)p(x)p(y))dydx=−∬p(x,y)ln(p(x)p(y))dydx+∬p(x,y)lnp(x,y)dydx≥0
所以得到
−
∬
p
(
x
,
y
)
ln
p
(
x
,
y
)
d
y
d
x
≤
−
∬
p
(
x
,
y
)
ln
p
(
x
)
p
(
y
)
d
y
d
x
-\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \le -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x})p(\mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x}
−∬p(x,y)lnp(x,y)dydx≤−∬p(x,y)lnp(x)p(y)dydx
结论成立,且只有在两变量相互独立时等号才成立。
实话说我感觉我这个是伪证明,因为利用了互信息这个先验知识,但是其实也没差,互信息本身就是一种 KL \operatorname{KL} KL散度,因此必然大于等于 0 0 0。看了一眼solution给出的解法,我觉得相当奇怪,既然作者已经利用了互信息这个条件,为什么还整得那么绕?
1.32
非奇异的随机变量线性变换不会改变随机变量的概率密度值,因此
p
(
A
x
)
=
p
(
y
)
p(\mathbf{Ax}) = p(\mathbf{y})
p(Ax)=p(y),同时在概率密度一节中有提及:
p
(
x
)
∣
δ
x
∣
=
p
(
y
)
∣
δ
y
∣
p(\mathbf{x}) |\delta \mathbf{x}| = p(\mathbf{y}) | \delta \mathbf{y} |
p(x)∣δx∣=p(y)∣δy∣,所以有
p
(
x
)
=
p
(
y
)
∣
δ
y
δ
x
∣
=
p
(
y
)
∣
A
∣
p(\mathbf{x}) = p(\mathbf{y}) |\frac{\delta \mathbf{y}}{\delta \mathbf{x}}| = p(\mathbf{y}) | \mathbf{A} |
p(x)=p(y)∣δxδy∣=p(y)∣A∣,所以
H
[
y
]
=
−
∫
p
(
A
x
)
ln
(
p
(
A
x
)
)
d
x
=
−
∫
p
(
x
)
ln
(
p
(
x
)
∣
A
∣
−
1
)
d
x
=
−
∫
p
(
x
)
ln
(
x
)
d
x
−
∫
p
(
x
)
ln
(
∣
A
∣
−
1
)
d
x
=
H
[
x
]
+
ln
(
∣
A
∣
)
\begin{aligned} \operatorname{H}[\mathbf{y}] &= -\int p(\mathbf{Ax}) \ln (p(\mathbf{Ax})) \mathrm{d}\mathbf{x} \\ &= -\int p(\mathbf{x}) \ln (p(\mathbf{x})|\mathbf{A}|^{-1}) \mathrm{d}\mathbf{x} \\ &= -\int p(\mathbf{x}) \ln (\mathbf{x}) \mathrm{d}\mathbf{x} -\int p(\mathbf{x}) \ln (|\mathbf{A}|^{-1}) \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{x}] + \ln (|\mathbf{A}|) \end{aligned}
H[y]=−∫p(Ax)ln(p(Ax))dx=−∫p(x)ln(p(x)∣A∣−1)dx=−∫p(x)ln(x)dx−∫p(x)ln(∣A∣−1)dx=H[x]+ln(∣A∣)
1.33
已知
H
[
x
,
y
]
=
H
[
y
∣
x
]
+
H
[
x
]
\operatorname{H}[\mathbf{x}, \mathbf{y}] = \operatorname{H}[\mathbf{y} | \mathbf{x}] + \operatorname{H}[\mathbf{x}]
H[x,y]=H[y∣x]+H[x]。现在
H
[
y
∣
x
]
=
0
\operatorname{H}[\mathbf{y} | \mathbf{x}] = 0
H[y∣x]=0,所以
H
[
x
,
y
]
=
H
[
x
]
\operatorname{H}[\mathbf{x}, \mathbf{y}] = \operatorname{H}[\mathbf{x}]
H[x,y]=H[x]。因此
−
∬
p
(
x
,
y
)
ln
p
(
x
,
y
)
d
y
d
x
=
−
∬
p
(
x
,
y
)
ln
p
(
x
)
d
y
d
x
\begin{aligned} -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} = -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \end{aligned}
−∬p(x,y)lnp(x,y)dydx=−∬p(x,y)lnp(x)dydx
所以
p
(
x
,
y
)
=
p
(
x
)
p(\mathbf{x}, \mathbf{y}) = p(\mathbf{x})
p(x,y)=p(x),又因为
p
(
x
,
y
)
=
p
(
y
∣
x
)
p
(
x
)
p(\mathbf{x}, \mathbf{y}) = p(\mathbf{y}|\mathbf{x}) p(\mathbf{x})
p(x,y)=p(y∣x)p(x),从而得到
p
(
y
∣
x
)
=
1
p(\mathbf{y}|\mathbf{x}) = 1
p(y∣x)=1,也就是说,在知道了
x
\mathbf{x}
x的前提条件下,
y
\mathbf{y}
y是多少一下子就知道了(因为概率为
1
1
1,所以说明对于一个固定的
x
\mathbf{x}
x,就只有一个固定的
y
\mathbf{y}
y与之对应),也就是说
y
\mathbf{y}
y与
x
\mathbf{x}
x之间有着对应的函数关系。这个函数关系并不一定是一一对应的,而只是要求在
x
\mathbf{x}
x确定了的情况下,只有一个
y
\mathbf{y}
y与之对应,这是不排除一个相同的
y
\mathbf{y}
y对应多个不同的
x
\mathbf{x}
x这种情况的。
1.34
泛函
F
F
F为:
−
∫
−
∞
∞
p
(
x
)
ln
p
(
x
)
d
x
+
λ
1
(
∫
−
∞
∞
p
(
x
)
d
x
−
1
)
+
λ
2
(
∫
−
∞
∞
x
p
(
x
)
d
x
−
μ
)
+
λ
3
(
∫
−
∞
∞
(
x
−
μ
)
2
p
(
x
)
d
x
−
σ
2
)
\begin{aligned} -\int_{-\infty}^{\infty} p(x) \ln p(x) \mathrm{d}x + \lambda_1 (\int_{-\infty}^{\infty} p(x) \mathrm{d}x - 1) + \lambda_2 (\int_{-\infty}^{\infty} xp(x) \mathrm{d}x - \mu) + \lambda_3 (\int_{-\infty}^{\infty} (x-\mu)^2 p(x) \mathrm{d}x - \sigma^2) \end{aligned}
−∫−∞∞p(x)lnp(x)dx+λ1(∫−∞∞p(x)dx−1)+λ2(∫−∞∞xp(x)dx−μ)+λ3(∫−∞∞(x−μ)2p(x)dx−σ2)
整理可得:
∫
−
∞
∞
{
−
p
(
x
)
ln
p
(
x
)
+
λ
1
p
(
x
)
+
λ
2
x
p
(
x
)
+
λ
3
(
x
−
μ
)
2
p
(
x
)
}
d
x
+
{
−
λ
1
−
λ
2
μ
−
λ
3
σ
2
)
}
\begin{aligned} \int_{-\infty}^{\infty} \{-p(x) \ln p(x) + \lambda_1 p(x) + \lambda_2 xp(x) + \lambda_3 (x-\mu)^2 p(x) \} \mathrm{d}x + \{ - \lambda_1 - \lambda_2 \mu - \lambda_3\sigma^2)\} \end{aligned}
∫−∞∞{−p(x)lnp(x)+λ1p(x)+λ2xp(x)+λ3(x−μ)2p(x)}dx+{−λ1−λ2μ−λ3σ2)}
令
G
=
−
p
(
x
)
ln
p
(
x
)
+
λ
1
p
(
x
)
+
λ
2
x
p
(
x
)
+
λ
3
(
x
−
μ
)
2
p
(
x
)
\begin{aligned} G = -p(x) \ln p(x) + \lambda_1 p(x) + \lambda_2 xp(x) + \lambda_3 (x-\mu)^2 p(x) \end{aligned}
G=−p(x)lnp(x)+λ1p(x)+λ2xp(x)+λ3(x−μ)2p(x)
则有
d
G
d
p
(
x
)
=
−
ln
p
(
x
)
−
1
+
λ
1
+
λ
2
x
+
λ
3
(
x
−
μ
)
2
=
0
\begin{aligned} \frac{\mathrm{d}G}{\mathrm{d}p(x)} &= -\ln p(x) - 1 + \lambda_1 + \lambda_2 x + \lambda_3 (x-\mu)^2 = 0\\ \end{aligned}
dp(x)dG=−lnp(x)−1+λ1+λ2x+λ3(x−μ)2=0
所以
p
(
x
)
=
exp
(
−
1
+
λ
1
+
λ
2
x
+
λ
3
(
x
−
μ
)
2
)
p(x) = \exp(-1 + \lambda_1 + \lambda_2 x + \lambda_3 (x-\mu)^2)
p(x)=exp(−1+λ1+λ2x+λ3(x−μ)2)。
这里参考了Appendix D章节的变分法内容。
1.35
p
(
x
)
=
1
(
2
π
σ
2
)
1
/
2
exp
{
−
(
x
−
μ
)
2
2
σ
2
}
p(x) = \frac{1}{(2 \pi \sigma^2)^{1/2}} \exp \{ -\frac{(x - \mu)^2}{2 \sigma^2} \}
p(x)=(2πσ2)1/21exp{−2σ2(x−μ)2},所以有
H
[
x
]
=
−
∫
p
(
x
)
ln
p
(
x
)
d
x
=
−
∫
1
(
2
π
σ
2
)
1
/
2
exp
{
−
(
x
−
μ
)
2
2
σ
2
}
ln
1
(
2
π
σ
2
)
1
/
2
exp
{
−
(
x
−
μ
)
2
2
σ
2
}
d
x
=
∫
p
(
x
)
(
ln
(
(
2
π
σ
2
)
1
/
2
)
)
d
x
+
∫
p
(
x
)
(
(
x
−
μ
)
2
2
σ
2
)
d
x
=
1
2
ln
(
2
π
σ
2
)
+
1
2
=
ln
(
2
π
σ
2
)
+
1
2
\begin{aligned} \operatorname{H}[x] &= -\int p(x) \ln p(x) \mathrm{d}x \\ &= -\int \frac{1}{(2 \pi \sigma^2)^{1/2}} \exp \{ -\frac{(x - \mu)^2}{2 \sigma^2} \} \ln \frac{1}{(2 \pi \sigma^2)^{1/2}} \exp \{ -\frac{(x - \mu)^2}{2 \sigma^2} \} \mathrm{d}x \\ &= \int p(x) (\ln ((2 \pi \sigma^2)^{1/2})) \mathrm{d}x + \int p(x) (\frac{(x - \mu)^2}{2 \sigma^2}) \mathrm{d}x \\ &= \frac{1}{2} \ln (2 \pi \sigma^2) + \frac{1}{2} \\ &= \frac{\ln (2 \pi \sigma^2) + 1}{2} \end{aligned}
H[x]=−∫p(x)lnp(x)dx=−∫(2πσ2)1/21exp{−2σ2(x−μ)2}ln(2πσ2)1/21exp{−2σ2(x−μ)2}dx=∫p(x)(ln((2πσ2)1/2))dx+∫p(x)(2σ2(x−μ)2)dx=21ln(2πσ2)+21=2ln(2πσ2)+1
注意其中有一步是由方差的计算公式得来的。
1.36
根据泰勒展开式,可得
f
(
x
)
=
f
(
x
0
)
+
f
′
(
x
0
)
(
x
−
x
0
)
+
1
2
f
′
′
(
x
0
)
(
x
−
x
0
)
2
\begin{aligned} f(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{1}{2}f''(x_0)(x-x_0)^2 \end{aligned}
f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2
由于
f
′
′
(
x
0
)
>
0
f''(x_0) > 0
f′′(x0)>0,因此
1
2
f
′
′
(
x
0
)
(
x
−
x
0
)
2
>
0
\frac{1}{2}f''(x_0)(x-x_0)^2 > 0
21f′′(x0)(x−x0)2>0,所以可得
f
(
x
)
>
f
(
x
0
)
+
f
′
(
x
0
)
(
x
−
x
0
)
\begin{aligned} f(x) > f(x_0) + f'(x_0)(x-x_0) \end{aligned}
f(x)>f(x0)+f′(x0)(x−x0)
设
x
0
=
λ
a
+
(
1
−
λ
)
b
x_0 = \lambda a + (1 - \lambda)b
x0=λa+(1−λ)b因此可以得到
f
(
a
)
>
f
(
λ
a
+
(
1
−
λ
)
b
)
+
f
′
(
λ
a
+
(
1
−
λ
)
b
)
(
(
1
−
λ
)
(
a
−
b
)
)
f
(
b
)
>
f
(
λ
a
+
(
1
−
λ
)
b
)
+
f
′
(
λ
a
+
(
1
−
λ
)
b
)
(
λ
(
b
−
a
)
)
λ
f
(
a
)
+
(
1
−
λ
)
f
(
b
)
>
f
(
λ
a
+
(
1
−
λ
)
b
)
\begin{aligned} & f(a) > f(\lambda a + (1 - \lambda)b) + f'(\lambda a + (1 - \lambda)b)((1-\lambda)(a-b)) \\ & f(b) > f(\lambda a + (1 - \lambda)b) + f'(\lambda a + (1 - \lambda)b)(\lambda (b - a)) \\ & \lambda f(a) + (1 - \lambda)f(b) > f(\lambda a + (1 - \lambda)b) \end{aligned}
f(a)>f(λa+(1−λ)b)+f′(λa+(1−λ)b)((1−λ)(a−b))f(b)>f(λa+(1−λ)b)+f′(λa+(1−λ)b)(λ(b−a))λf(a)+(1−λ)f(b)>f(λa+(1−λ)b)
从而得证。
1.37
H [ y ∣ x ] + H [ x ] = − ∬ p ( x , y ) ln p ( y ∣ x ) d y d x − ∫ p ( x ) ln p ( x ) d x = − ∬ p ( x , y ) ln p ( y ∣ x ) d y d x − ∬ p ( x , y ) ln p ( x ) d y d x = − ∬ p ( x , y ) ln { p ( y ∣ x ) p ( x ) } d y d x = − ∬ p ( x , y ) ln p ( x , y ) d y d x = H [ x , y ] \begin{aligned} \operatorname{H}[\mathbf{y} | \mathbf{x}] + \operatorname{H}[\mathbf{x}] &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{y}| \mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} - \int p(\mathbf{x}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{x}\\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{y}| \mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln \{p(\mathbf{y}| \mathbf{x}) p(\mathbf{x}) \} \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln p(\mathbf{x}, \mathbf{y}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{x}, \mathbf{y}] \end{aligned} H[y∣x]+H[x]=−∬p(x,y)lnp(y∣x)dydx−∫p(x)lnp(x)dx=−∬p(x,y)lnp(y∣x)dydx−∬p(x,y)lnp(x)dydx=−∬p(x,y)ln{p(y∣x)p(x)}dydx=−∬p(x,y)lnp(x,y)dydx=H[x,y]
1.38
当项数为
2
2
2时,根据式(1.114)可知
f
(
λ
a
+
(
1
−
λ
)
b
)
≤
λ
f
(
a
)
+
(
1
−
λ
)
f
(
b
)
\begin{aligned} f(\lambda a + (1-\lambda)b) \le \lambda f(a) + (1 - \lambda)f(b) \end{aligned}
f(λa+(1−λ)b)≤λf(a)+(1−λ)f(b)
现在假设项数为
M
M
M时满足
f
(
∑
i
=
1
M
λ
i
x
i
)
≤
∑
i
=
1
M
λ
i
f
(
x
i
)
\begin{aligned} f(\sum_{i=1}^{M} \lambda_i x_i ) \le \sum_{i=1}^{M} \lambda_i f(x_i) \end{aligned}
f(i=1∑Mλixi)≤i=1∑Mλif(xi)
当有
M
+
1
M+1
M+1项时,则有
f
(
∑
i
=
1
M
+
1
λ
i
x
i
)
=
f
(
∑
i
=
1
M
λ
i
x
i
+
λ
M
+
1
x
M
+
1
)
=
f
(
(
1
−
λ
M
+
1
)
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
x
i
+
λ
M
+
1
x
M
+
1
)
≤
(
1
−
λ
M
+
1
)
f
(
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
x
i
)
+
λ
M
+
1
f
(
x
M
+
1
)
\begin{aligned} f(\sum_{i=1}^{M+1} \lambda_i x_i ) & = f(\sum_{i=1}^{M} \lambda_i x_i + \lambda_{M+1} x_{M+1}) \\ & = f((1-\lambda_{M+1})\sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} x_i + \lambda_{M+1} x_{M+1}) \\ & \le (1-\lambda_{M+1}) f(\sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} x_i) + \lambda_{M+1} f(x_{M+1}) \\ \end{aligned}
f(i=1∑M+1λixi)=f(i=1∑Mλixi+λM+1xM+1)=f((1−λM+1)i=1∑M1−λM+1λixi+λM+1xM+1)≤(1−λM+1)f(i=1∑M1−λM+1λixi)+λM+1f(xM+1)
很明显,
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
=
1
\sum_{i=1}^M \frac{\lambda_i}{1-\lambda_{M+1}}=1
∑i=1M1−λM+1λi=1,因此
f
(
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
x
i
)
≤
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
f
(
x
i
)
\begin{aligned} f(\sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} x_i) \le \sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} f(x_i) \end{aligned}
f(i=1∑M1−λM+1λixi)≤i=1∑M1−λM+1λif(xi)
所以
f
(
∑
i
=
1
M
+
1
λ
i
x
i
)
=
f
(
∑
i
=
1
M
λ
i
x
i
+
λ
M
+
1
x
M
+
1
)
=
f
(
(
1
−
λ
M
+
1
)
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
x
i
+
λ
M
+
1
x
M
+
1
)
≤
(
1
−
λ
M
+
1
)
f
(
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
x
i
)
+
λ
M
+
1
f
(
x
M
+
1
)
≤
(
1
−
λ
M
+
1
)
∑
i
=
1
M
λ
i
1
−
λ
M
+
1
f
(
x
i
)
+
λ
M
+
1
f
(
x
M
+
1
)
=
∑
i
=
1
M
+
1
λ
i
f
(
x
i
)
\begin{aligned} f(\sum_{i=1}^{M+1} \lambda_i x_i ) & = f(\sum_{i=1}^{M} \lambda_i x_i + \lambda_{M+1} x_{M+1}) \\ & = f((1-\lambda_{M+1})\sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} x_i + \lambda_{M+1} x_{M+1}) \\ & \le (1-\lambda_{M+1}) f(\sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} x_i) + \lambda_{M+1} f(x_{M+1}) \\ & \le (1-\lambda_{M+1}) \sum_{i=1}^{M} \frac{\lambda_i}{1-\lambda_{M+1}} f(x_i) + \lambda_{M+1} f(x_{M+1}) \\ & = \sum_{i=1}^{M+1} \lambda_i f(x_i) \end{aligned}
f(i=1∑M+1λixi)=f(i=1∑Mλixi+λM+1xM+1)=f((1−λM+1)i=1∑M1−λM+1λixi+λM+1xM+1)≤(1−λM+1)f(i=1∑M1−λM+1λixi)+λM+1f(xM+1)≤(1−λM+1)i=1∑M1−λM+1λif(xi)+λM+1f(xM+1)=i=1∑M+1λif(xi)
由此归纳得证。
1.39
这道题理解了书中的相关公式很好做的,书里面几乎把关系全都明摆出来了。
( a ) ln 3 − 2 3 ln 2 \ln 3 - \frac{2}{3} \ln 2 ln3−32ln2
( b ) ln 3 − 2 3 ln 2 \ln 3 - \frac{2}{3} \ln 2 ln3−32ln2
( c ) 2 3 ln 2 \frac{2}{3} \ln 2 32ln2
( d ) 2 3 ln 2 \frac{2}{3} \ln 2 32ln2
( e ) ln 3 \ln{3} ln3
( f ) ln 3 − 4 3 ln 2 \ln{3} - \frac{4}{3} \ln 2 ln3−34ln2
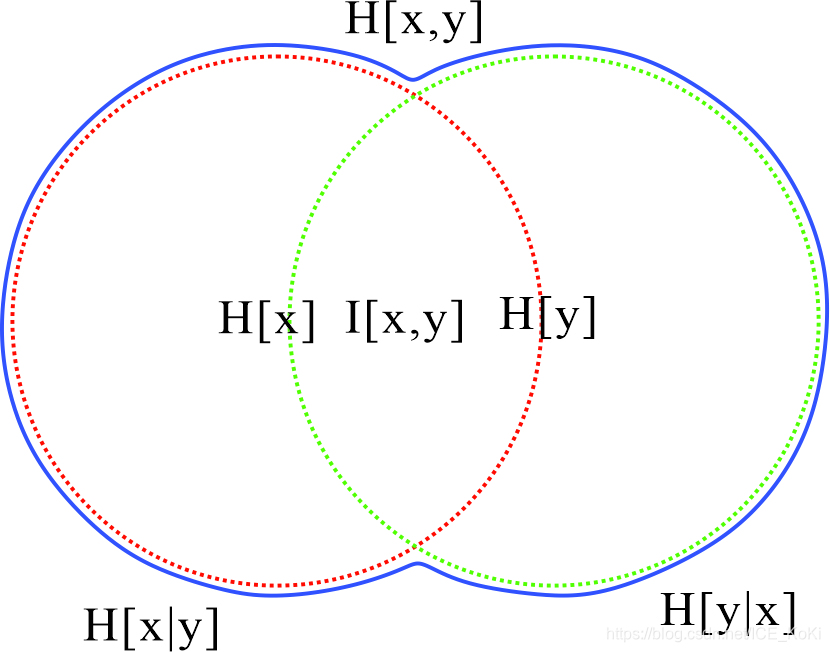
1.40
ln
(
∑
i
=
1
N
1
N
x
i
)
=
ln
(
1
N
∑
i
=
1
N
x
i
)
≤
∑
i
=
1
N
1
N
ln
x
i
=
1
N
∑
i
=
1
N
ln
x
i
=
1
N
ln
∏
i
=
1
N
x
i
=
ln
(
∏
i
=
1
N
x
i
)
1
N
\begin{aligned} \ln ( \sum_{i=1}^N \frac{1}{N} x_i ) = \ln ( \frac{1}{N} \sum_{i=1}^N x_i ) \le \sum_{i=1}^N \frac{1}{N} \ln x_i = \frac{1}{N} \sum_{i=1}^N \ln x_i = \frac{1}{N} \ln \prod_{i=1}^{N} x_i = \ln (\prod_{i=1}^{N} x_i)^{\frac{1}{N}} \end{aligned}
ln(i=1∑NN1xi)=ln(N1i=1∑Nxi)≤i=1∑NN1lnxi=N1i=1∑Nlnxi=N1lni=1∏Nxi=ln(i=1∏Nxi)N1
由于
ln
\ln
ln函数为递增函数,因此
1
N
∑
i
=
1
N
x
i
≤
(
∏
i
=
1
N
x
i
)
1
N
\begin{aligned} \frac{1}{N} \sum_{i=1}^N x_i \le (\prod_{i=1}^{N} x_i)^{\frac{1}{N}} \end{aligned}
N1i=1∑Nxi≤(i=1∏Nxi)N1
从而得证。
1.41
I [ x , y ] = KL ( p ( x , y ) ∣ ∣ p ( x ) p ( y ) ) = − ∬ p ( x , y ) ln ( p ( x ) p ( y ) p ( x , y ) ) d y d x = − ∬ p ( x , y ) ln ( p ( x ) p ( y ) p ( y ∣ x ) p ( x ) ) d y d x = − ∬ p ( x , y ) ln ( p ( y ) p ( y ∣ x ) ) d y d x = H [ y ] − H [ y ∣ x ] = − ∬ p ( x , y ) ln ( p ( x ) p ( y ) p ( x ∣ y ) p ( y ) ) d y d x = − ∬ p ( x , y ) ln ( p ( x ) p ( x ∣ y ) ) d y d x = H [ x ] − H [ x ∣ y ] \begin{aligned} I[\mathbf{x}, \mathbf{y}] &= \operatorname{KL}(p(\mathbf{x}, \mathbf{y})||p(\mathbf{x})p(\mathbf{y})) \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})p(\mathbf{y})}{p(\mathbf{x}, \mathbf{y})}) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})p(\mathbf{y})}{p(\mathbf{y}| \mathbf{x}) p(\mathbf{x}) }) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{y})}{p(\mathbf{y}| \mathbf{x}) }) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{y}] - \operatorname{H}[\mathbf{y} | \mathbf{x}] \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})p(\mathbf{y})}{p(\mathbf{x}| \mathbf{y}) p(\mathbf{y}) }) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= -\iint p(\mathbf{x}, \mathbf{y}) \ln (\frac{p(\mathbf{x})}{p(\mathbf{x}| \mathbf{y}) }) \mathrm{d}\mathbf{y} \mathrm{d}\mathbf{x} \\ &= \operatorname{H}[\mathbf{x}] - \operatorname{H}[\mathbf{x} | \mathbf{y}] \end{aligned} I[x,y]=KL(p(x,y)∣∣p(x)p(y))=−∬p(x,y)ln(p(x,y)p(x)p(y))dydx=−∬p(x,y)ln(p(y∣x)p(x)p(x)p(y))dydx=−∬p(x,y)ln(p(y∣x)p(y))dydx=H[y]−H[y∣x]=−∬p(x,y)ln(p(x∣y)p(y)p(x)p(y))dydx=−∬p(x,y)ln(p(x∣y)p(x))dydx=H[x]−H[x∣y]














 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









