







介绍
这门课有一个很好的笔记在52nlp网站上
部分摘录+自己补充
机器学习的定义
Arthur Samuel (1959): Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998) : Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
分类
supervised learning监督学习, 训练集是标记的
本课程涉及了分类(预测离散值),线性/逻辑回归(预测连续值),神经网络,支持向量机SVMunsupercised leaning 无监督学习,训练集没有标记
训练集没有标记,本课程涉及K-means,PCA主成分分析,异常检测e.g. “ 鸡尾酒会问题”(cocktail party problem)
鸡尾酒会问题算法主需要一行代码
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x’);Gradient descent(梯度下降)
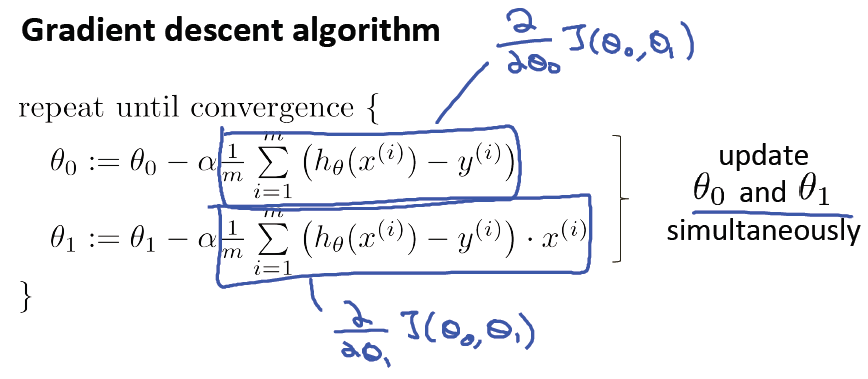
1、给
θ0
,
θ1
一个初始值,例如都等于0
2、每次改变
θ0
,
θ1
的时候都保持
J(θ0
,
θ1)
递减,直到达到一个我们满意的最小值

需要注意,先用原来的
θ0
,
θ1
来计算新的
θ0
,
θ1
,再用新值替换旧值,不要计算一个,替换一个。
对应的代码为
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters)
m = length(y); % number of training examples
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
temp1 = theta(1) - (alpha/m)*(X*theta-y)'*X(:,1);
temp2 = theta(2) - (alpha/m)*(X*theta-y)'*X(:,2);
theta(1) = temp1;
theta(2) = temp2;
J_history(iter) = computeCost(X, y, theta);
end
end这里的
α
是learning rate(又称为步长),如果α过小,梯度下降可能很慢;如果过大,梯度下降有可能“迈过”(overshoot)最小点,并且有可能收敛失败,并且产生“分歧”(diverge)。
注意:梯度下降可能使函数收敛到一个局部最小值,而不是global optima
给出单变量线性回归梯度下降算法:
体现在代码上的区别:求和函数需要写循环,向量化则简洁得多:















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









