






在以往推送中已经介绍了相当多的计算材料Raman的方法,使用的软件主要为Phonopy-Spectroscopy,相关软件还有vasp,phonopy,phono3py等。
Phonopy-Spectroscopy计算材料红外和Raman光谱
Phonopy-Spectroscopy 计算红外和拉曼光谱
也有一些教程介绍了无需额外软件即可得到材料Raman信息的脚本vasp_raman.py,但脚本缺少自由度并且需要额外的数据处理。
本篇推送即介绍这一脚本计算材料Raman信息的流程。
脚本和案例可在作者处下载:
https://github.com/ZeliangSu/VaspRoutine/blob/main/raman-sc/
在本文最后也会附上0.6.0版本的脚本
准备工作
计算可得到无虚频的声子谱的结构文件
这里使用单晶硅作案例
Si1.05.4661639157319968 0.0000000000000000 0.00000000000000000.0000000000000000 5.4661639157319968 0.00000000000000000.0000000000000000 0.0000000000000000 5.4661639157319968Si8Direct0.8750000000000000 0.8750000000000000 0.87500000000000000.8750000000000000 0.3750000000000000 0.37500000000000000.3750000000000000 0.8750000000000000 0.37500000000000000.3750000000000000 0.3750000000000000 0.87500000000000000.1250000000000000 0.1250000000000000 0.12500000000000000.1250000000000000 0.6250000000000000 0.62500000000000000.6250000000000000 0.1250000000000000 0.62500000000000000.6250000000000000 0.6250000000000000 0.1250000000000000
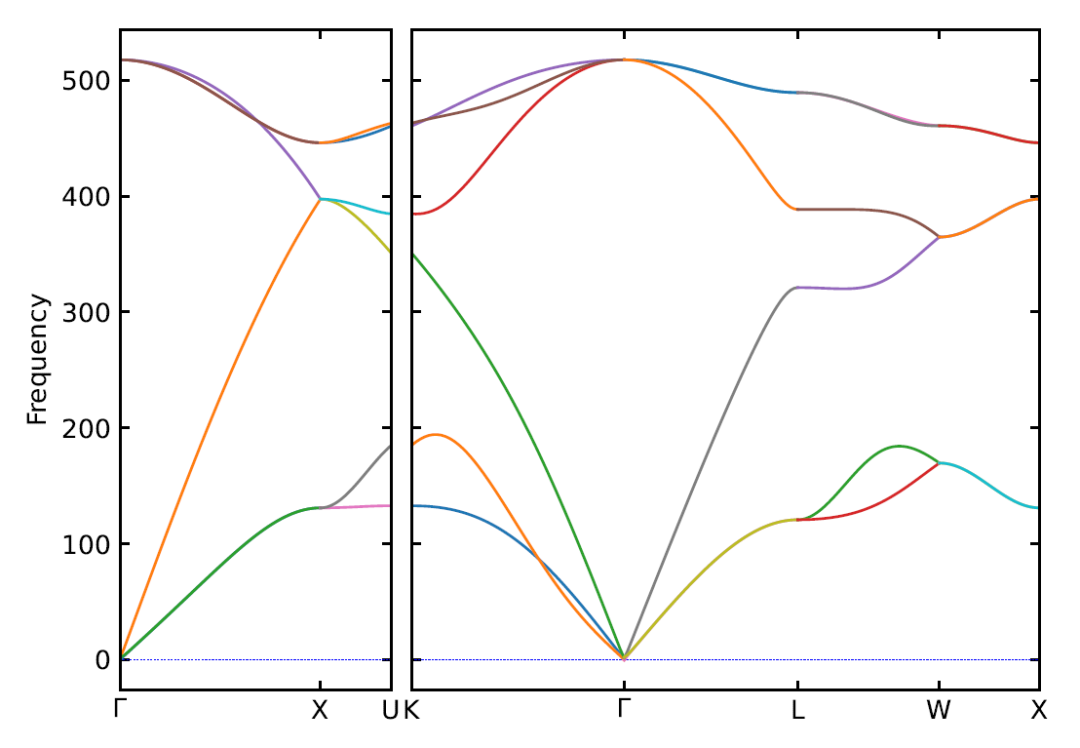
这里已将声子谱反折叠为原胞第一布里渊区内的声子色散,并将纵坐标单位设置为(cm-1)
计算第一步:频率信息
计算INCAR参考:
SYSTEM = Si_bulkISTART = 0 # From-scratch; job : 0-new 1-cont 2-samecutNWRITE = 3 Verbosity! electronic relaxationENCUT = 300.0 # cut-off energyPREC = Accurate # precision : accurate/normal/lowISPIN = 1 # 1 - off, 2 - on (non spin-polarized calculation)ICHARG = 2 # > 10 for non-SC calculationIALGO = 38 # DAVidson, then RMM-DIISEDIFF = 1.0E-8 # defaultISMEAR = 0 # gaussianSIGMA = 0.05! PAW'sLREAL = .FALSE. # default - Automatic choice of how projection is doneADDGRID = .TRUE.! phononsIBRION = 5POTIM = 0.01! parallelisationLPLANE = .FALSE.KPAR=8! outputLWAVE = .FALSE. # WAVECAR fileLCHARG = .FALSE. # CHCAR fileLELF = .FALSE.LVTOT = .FALSE.
特别注意参数:NWRITE = 3 Verbosity
计算完成后可自行处理声子色散和相关数据。材料的频率信息在OUTCAR中可自行查看。
计算第二步:宏观介电张量
将第一步计算结果中的POSCAR复制为POSCAR.phon,将OUTCAR复制为OUTCAR.phon。
第二步INCAR参考:
SYSTEM = Si_bulkISTART = 0 # From-scratch; job : 0-new 1-cont 2-samecutNWRITE = 3 Verbosity! electronic relaxationENCUT = 300.0 # cut-off energyPREC = Accurate # precision : accurate/normal/lowISPIN = 1 # 1 - off, 2 - on (non spin-polarized calculation)ICHARG = 2 # > 10 for non-SC calculationIALGO = 38 # DAVidson, then RMM-DIISEDIFF = 1.0E-8 # defaultISMEAR = 0 # gaussianSIGMA = 0.05! PAW'sLREAL = .FALSE. # default - Automatic choice of how projection is doneADDGRID = .TRUE.! phonons!! IBRION = 5!! POTIM = 0.01LEPSILON=.TRUE.! parallelisationLPLANE = .FALSE.KPAR=8! outputLWAVE = .FALSE. # WAVECAR fileLCHARG = .FALSE. # CHCAR fileLELF = .FALSE.LVTOT = .FALSE.
此时需要调用脚本vasp_raman.py 进行第二步计算命令为:
export VASP_RAMAN_RUN='aprun -B /u/afonari/vasp.5.3.2/vasp.5.3/vasp &> job.out'export VASP_RAMAN_PARAMS='01_21_2_0.01'python vasp_raman.py > vasp_raman.out
第一行中 VASP_RAMAN_RUN为服务器等计算资源可使用的vasp的执行命令
注意:在集群使用队列资源排队进行计算的时候需要将上面三行命令都填写进队列系统脚本中,并替代原有的执行命令,具体请根据实际计算情况更改
第二行中VASP_RAMAN_PARAMS参数为Raman计算针对的频率范围和计算设置。
第一个数为起始频率编号,01为起始频率编号;
第二个数为截至频率编号,最大值为POSCAR总原子数×3。
计算总任务数为第二个数减去第一个数再乘第三个数。
计算过程中脚本会读取OUTCAR.phon中的频率信息针对不同频率的声子所对应的原子振动模式对结构施加微扰。
同时会实时将新生成的OUTCAR另存最后统一数据处理。

计算结果保存在vasp_raman.dat
# mode freq(cm-1) alpha beta2 activity001 517.72301 -0.0219904 520.9354925 3646.5702084002 517.71996 0.0177803 521.9308522 3653.5301918003 517.71816 -0.0130798 521.3205054 3649.2512364004 446.13270 -0.0022072 0.0007120 0.0052035005 446.12649 -0.0026568 0.0001072 0.0010683006 446.11229 -0.0091150 0.0020607 0.0181638007 446.10094 0.0056815 0.0001899 0.0027820008 446.09466 0.0108317 0.0016816 0.0170508009 446.08791 0.0082157 0.0009541 0.0097161010 397.45270 -0.0004496 0.0001839 0.0012966011 397.45083 -0.0050684 0.0004061 0.0039986012 397.44702 0.0011036 0.0020508 0.0144103013 397.44649 -0.0029021 0.0011642 0.0085283014 397.44295 -0.0007766 0.0000371 0.0002871015 397.44138 0.0047005 0.0005162 0.0046073016 130.93534 -0.0010219 0.0000026 0.0000654017 130.92851 0.0026977 0.0000319 0.0005511018 130.92701 -0.0001635 0.0000030 0.0000221019 130.92623 -0.0006949 0.0000040 0.0000499020 130.92383 -0.0003270 0.0000030 0.0000261021 130.92351 0.0000817 0.0000035 0.0000247
可见Raman活性频率为517cm-1,与Si实验值520cm-1相当接近 (J.H. Parker, et al., Phys Rev, 155, 712 (1967))。
如果吹毛求疵,可以在计算频率或声子时便通过高精度结构优化和使用实验值的晶格常数等方法将所得对应的频率和实验值矫正。
使用脚本将已经得到Raman信息处理(可自行选择拟合方式Gaussian或Lorentzian)
python broaden.py vasp_raman.dat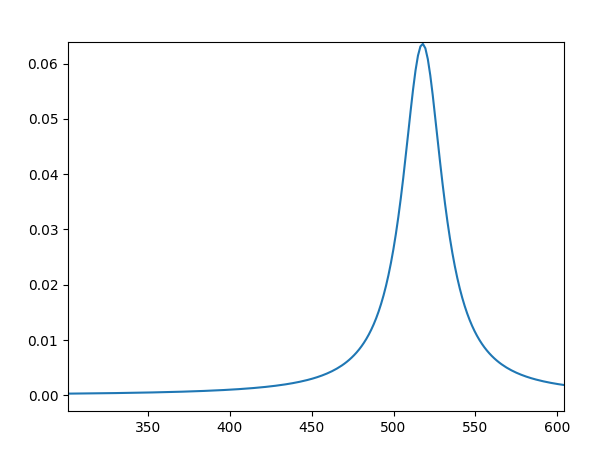
附:
vasp_raman.py脚本:
https://github.com/ZeliangSu/VaspRoutine/blob/main/raman-sc/vasp_raman.py
#!/usr/bin/env python## vasp_raman.py v. 0.6.0## Raman off-resonant activity calculator# using VASP as a back-end.## Contributors: Alexandr Fonari (Georgia Tech)# Shannon Stauffer (UT Austin)## URL: http://raman-sc.github.io## MIT license, 2013 - 2016#import reimport sysdef MAT_m_VEC(m, v):p = [ 0.0 for i in range(len(v)) ]for i in range(len(m)):assert len(v) == len(m[i]), 'Length of the matrix row is not equal to the length of the vector'p[i] = sum( [ m[i][j]*v[j] for j in range(len(v)) ] )return pdef T(m):p = [[ m[i][j] for i in range(len( m[j] )) ] for j in range(len( m )) ]return pdef parse_poscar(poscar_fh):# modified subroutine from phonopy 1.8.3 (New BSD license)#poscar_fh.seek(0) # just in caselines = poscar_fh.readlines()#print(lines)scale = float(lines[1])if scale < 0.0:print("[parse_poscar]: ERROR negative scale not implemented.")sys.exit(1)#b = []for i in range(2, 5):b.append([float(x)*scale for x in lines[i].split()[:3]])#vol = b[0][0]*b[1][1]*b[2][2] + b[1][0]*b[2][1]*b[0][2] + b[2][0]*b[0][1]*b[1][2] - \b[0][2]*b[1][1]*b[2][0] - b[2][1]*b[1][2]*b[0][0] - b[2][2]*b[0][1]*b[1][0]#try:num_atoms = [int(x) for x in lines[5].split()]line_at = 6except ValueError:symbols = [x for x in lines[5].split()]num_atoms = [int(x) for x in lines[6].split()]line_at = 7nat = sum(num_atoms)#if lines[line_at][0].lower() == 's':line_at += 1#if (lines[line_at][0].lower() == 'c' or lines[line_at][0].lower() == 'k'):is_scaled = Falseelse:is_scaled = True#line_at += 1#positions = []for i in range(line_at, line_at + nat):pos = [float(x) for x in lines[i].split()[:3]]#if is_scaled:pos = MAT_m_VEC(T(b), pos)#positions.append(pos)#poscar_header = ''.join(lines[1:line_at-1]) # will add title and 'Cartesian' laterreturn nat, vol, b, positions, poscar_headerdef parse_env_params(params):tmp = params.strip().split('_')if len(tmp) != 4:print("[parse_env_params]: ERROR there should be exactly four parameters")sys.exit(1)#[first, last, nderiv, step_size] = [int(tmp[0]), int(tmp[1]), int(tmp[2]), float(tmp[3])]#return first, last, nderiv, step_size#### subs for the output from VTST toolsdef parse_freqdat(freqdat_fh, nat):freqdat_fh.seek(0) # just in case#eigvals = [ 0.0 for i in range(nat*3) ]#for i in range(nat*3): # all frequencies should be supplied, regardless of requested to calculatetmp = freqdat_fh.readline().split()eigvals[i] = float(tmp[0])#return eigvals#def parse_modesdat(modesdat_fh, nat):from math import sqrtmodesdat_fh.seek(0) # just in case#eigvecs = [ 0.0 for i in range(nat*3) ]norms = [ 0.0 for i in range(nat*3) ]#for i in range(nat*3): # all frequencies should be supplied, regardless of requested to calculateeigvec = []for j in range(nat):tmp = modesdat_fh.readline().split()eigvec.append([ float(tmp[x]) for x in range(3) ])#modesdat_fh.readline().split() # empty lineeigvecs[i] = eigvecnorms[i] = sqrt( sum( [abs(x)**2 for sublist in eigvec for x in sublist] ) )#return eigvecs, norms#### end subs for VTST#def get_modes_from_OUTCAR(outcar_fh, nat):from math import sqrteigvals = [ 0.0 for i in range(nat*3) ]eigvecs = [ 0.0 for i in range(nat*3) ]norms = [ 0.0 for i in range(nat*3) ]#outcar_fh.seek(0) # just in casewhile True:line = outcar_fh.readline()if not line:break#if "Eigenvectors after division by SQRT(mass)" in line:outcar_fh.readline() # empty lineoutcar_fh.readline() # Eigenvectors and eigenvalues of the dynamical matrixoutcar_fh.readline() # ----------------------------------------------------outcar_fh.readline() # empty line#for i in range(nat*3): # all frequencies should be supplied, regardless of those requested to calculateoutcar_fh.readline() # empty linep = re.search(r'^\s*(\d+).+?([\.\d]+) cm-1', outcar_fh.readline())eigvals[i] = float(p.group(2))#outcar_fh.readline() # X Y Z dx dy dzeigvec = []#for j in range(nat):tmp = outcar_fh.readline().split()#eigvec.append([ float(tmp[x]) for x in range(3,6) ])#eigvecs[i] = eigvecnorms[i] = sqrt( sum( [abs(x)**2 for sublist in eigvec for x in sublist] ) )#return eigvals, eigvecs, norms#print("[get_modes_from_OUTCAR]: ERROR Couldn't find 'Eigenvectors after division by SQRT(mass)' in OUTCAR. Use 'NWRITE=3' in INCAR. Exiting...")sys.exit(1)#def get_epsilon_from_OUTCAR(outcar_fh):epsilon = []#outcar_fh.seek(0) # just in casewhile True:line = outcar_fh.readline()if not line:break#if "MACROSCOPIC STATIC DIELECTRIC TENSOR" in line:try:outcar_fh.readline()epsilon.append([float(x) for x in outcar_fh.readline().split()])epsilon.append([float(x) for x in outcar_fh.readline().split()])epsilon.append([float(x) for x in outcar_fh.readline().split()])except:from lxml import etree as ETdoc = ET.parse('vasprun.xml')epsilon = [[float(x) for x in c.text.split()] for c in doc.xpath("/modeling/calculation/varray")[3].getchildren()]return epsilon#raise RuntimeError("[get_epsilon_from_OUTCAR]: ERROR Couldn't find dielectric tensor in OUTCAR")return 1#if __name__ == '__main__':from math import pifrom shutil import moveimport osimport datetimeimport time#import argparseimport optparse#print("")print(" Raman off-resonant activity calculator,")print(" using VASP as a back-end.")print("")print(" Contributors: Alexandr Fonari (Georgia Tech)")print(" Shannon Stauffer (UT Austin)")print(" MIT License, 2013")print(" URL: http://raman-sc.github.io")print(" Started at: "+datetime.datetime.now().strftime("%Y-%m-%d %H:%M"))print("")#description = "Before run, set environment variables:\n"description += " VASP_RAMAN_RUN='mpirun vasp'\n"description += " VASP_RAMAN_PARAMS='[first-mode]_[last-mode]_[nderiv]_[step-size]'\n\n"description += "bash one-liner is:\n"description += "VASP_RAMAN_RUN='mpirun vasp' VASP_RAMAN_PARAMS='1_2_2_0.01' python vasp_raman.py"#parser = optparse.OptionParser(description=description)parser.add_option('-g', '--gen', help='Generate POSCAR only', action='store_true')parser.add_option('-u', '--use_poscar', help='Use provided POSCAR in the folder, USE WITH CAUTION!!', action='store_true')(options, args) = parser.parse_args()#args = vars(parser.parse_args())args = vars(options)#VASP_RAMAN_RUN = os.environ.get('VASP_RAMAN_RUN')if VASP_RAMAN_RUN == None:print("[__main__]: ERROR Set environment variable 'VASP_RAMAN_RUN'")print("")parser.print_help()sys.exit(1)print("[__main__]: VASP_RAMAN_RUN='"+VASP_RAMAN_RUN+"'")#VASP_RAMAN_PARAMS = os.environ.get('VASP_RAMAN_PARAMS')if VASP_RAMAN_PARAMS == None:print("[__main__]: ERROR Set environment variable 'VASP_RAMAN_PARAMS'")print("")parser.print_help()sys.exit(1)print("[__main__]: VASP_RAMAN_PARAMS='"+VASP_RAMAN_PARAMS+"'")#first, last, nderiv, step_size = parse_env_params(VASP_RAMAN_PARAMS)assert first >= 1, '[__main__]: First mode should be equal or larger than 1'assert last >= first, '[__main__]: Last mode should be equal or larger than first mode'if args['gen']: assert last == first, "[__main__]: '-gen' mode -> only generation for the one mode makes sense"assert nderiv == 2, '[__main__]: At this time, nderiv = 2 is the only supported'disps = [-1, 1] # hardcoded forcoeffs = [-0.5, 0.5] # three point stencil (nderiv=2)#try:poscar_fh = open('POSCAR.phon', 'r')except IOError:print("[__main__]: ERROR Couldn't open input file POSCAR.phon, exiting...\n")sys.exit(1)## nat, vol, b, poscar_header = parse_poscar_header(poscar_fh)nat, vol, b, pos, poscar_header = parse_poscar(poscar_fh)print(pos)#print poscar_header#sys.exit(0)## either use modes from vtst tools or VASPif os.path.isfile('freq.dat') and os.path.isfile('modes_sqrt_amu.dat'):try:freqdat_fh = open('freq.dat', 'r')except IOError:print("[__main__]: ERROR Couldn't open freq.dat, exiting...\n")sys.exit(1)#eigvals = parse_freqdat(freqdat_fh, nat)freqdat_fh.close()#try:modes_fh = open('modes_sqrt_amu.dat' , 'r')except IOError:print("[__main__]: ERROR Couldn't open modes_sqrt_amu.dat, exiting...\n")sys.exit(1)#eigvecs, norms = parse_modesdat(modes_fh, nat)modes_fh.close()#elif os.path.isfile('OUTCAR.phon'):try:outcar_fh = open('OUTCAR.phon', 'r')except IOError:print("[__main__]: ERROR Couldn't open OUTCAR.phon, exiting...\n")sys.exit(1)#eigvals, eigvecs, norms = get_modes_from_OUTCAR(outcar_fh, nat)outcar_fh.close()#else:print("[__main__]: Neither OUTCAR.phon nor freq.dat/modes_sqrt_amu.dat were found, nothing to do, exiting...")sys.exit(1)#output_fh = open('vasp_raman.dat', 'w')output_fh.write("# mode freq(cm-1) alpha beta2 activity\n")for i in range(first-1, last):eigval = eigvals[i]eigvec = eigvecs[i]norm = norms[i]#print("")print("[__main__]: Mode #%i: frequency %10.7f cm-1; norm: %10.7f" % ( i+1, eigval, norm ))#ra = [[0.0 for x in range(3)] for y in range(3)]for j in range(len(disps)):disp_filename = 'OUTCAR.%04d.%+d.out' % (i+1, disps[j])#try:outcar_fh = open(disp_filename, 'r')print("[__main__]: File "+disp_filename+" exists, parsing...")except IOError:if args['use_poscar'] != True:print("[__main__]: File "+disp_filename+" not found, preparing displaced POSCAR")poscar_fh = open('POSCAR', 'w')poscar_fh.write("%s %4.1e \n" % (disp_filename, step_size))poscar_fh.write(poscar_header)poscar_fh.write("Cartesian\n")#for k in range(nat):pos_disp = [ pos[k][l] + eigvec[k][l]*step_size*disps[j]/norm for l in range(3)]poscar_fh.write( '%15.10f %15.10f %15.10f\n' % (pos_disp[0], pos_disp[1], pos_disp[2]) )#print '%10.6f %10.6f %10.6f %10.6f %10.6f %10.6f' % (pos[k][0], pos[k][1], pos[k][2], dis[k][0], dis[k][1], dis[k][2])poscar_fh.close()else:print("[__main__]: Using provided POSCAR")#if args['gen']: # only generate POSCARsposcar_fn = 'POSCAR.%+d.out' % disps[j]move('POSCAR', poscar_fn)print("[__main__]: '-gen' mode -> "+poscar_fn+" with displaced atoms have been generated")#if j+1 == len(disps): # last iteration for the current displacements listprint("[__main__]: '-gen' mode -> POSCAR files with displaced atoms have been generated, exiting now")sys.exit(0)else: # run VASP hereprint("[__main__]: Running VASP...")os.system(VASP_RAMAN_RUN)try:move('OUTCAR', disp_filename)except IOError:print("[__main__]: ERROR Couldn't find OUTCAR file, exiting...")sys.exit(1)#outcar_fh = open(disp_filename, 'r')#try:eps = get_epsilon_from_OUTCAR(outcar_fh)outcar_fh.close()except Exception as err:print(err)print("[__main__]: Moving "+disp_filename+" back to 'OUTCAR' and exiting...")move(disp_filename, 'OUTCAR')sys.exit(1)#for m in range(3):for n in range(3):ra[m][n] += eps[m][n] * coeffs[j]/step_size * norm * vol/(4.0*pi)#units: A^2/amu^1/2 = dimless * 1/A * 1/amu^1/2 * A^3#alpha = (ra[0][0] + ra[1][1] + ra[2][2])/3.0beta2 = ( (ra[0][0] - ra[1][1])**2 + (ra[0][0] - ra[2][2])**2 + (ra[1][1] - ra[2][2])**2 + 6.0 * (ra[0][1]**2 + ra[0][2]**2 + ra[1][2]**2) )/2.0print("")print("! %4i freq: %10.5f alpha: %10.7f beta2: %10.7f activity: %10.7f " % (i+1, eigval, alpha, beta2, 45.0*alpha**2 + 7.0*beta2))output_fh.write("%03i %10.5f %10.7f %10.7f %10.7f\n" % (i+1, eigval, alpha, beta2, 45.0*alpha**2 + 7.0*beta2))output_fh.flush()#output_fh.close()
绘图脚本:
https://github.com/ZeliangSu/VaspRoutine/blob/main/raman-sc/broaden.py(有修改)
#!/usr/bin/env python#def to_plot(hw,ab,gam=0.001,type='lorentzian'):import numpy as np#fmin = min(hw)fmax = max(hw)erange = np.arange(fmin-40*gam,fmax+40*gam,gam/10)#np.arange(fmin-40*gam,fmax+40*gam,gam/10)spectrum = 0.0*erangefor i in range(len(hw)):if type=='Gaussian':spectrum += (2*np.pi)**(-.5)/gam*np.exp(np.clip(-1.0*(hw[i]-erange)**2/(2*gam**2),-300,300))elif type=='Lorentzian':spectrum += ab[i]*1/np.pi*gam/((hw[i]-erange)**2+gam**2)#return erange, spectrum#if __name__ == '__main__':import numpy as npimport sys#hw=np.genfromtxt(sys.argv[1], dtype=float)cm1 = hw[:,1]int1 = hw[:,4]int1 /= np.max(np.abs(int1),axis=0)Es1,Spectrum1 = to_plot(cm1, int1, 15.0, 'Lorentzian')#filename = "new-broaden.dat"print( "Writing", filename)f = open(filename,'w')f.write('# freq/cm-1 Intensity \n')for i in range(len(Es1)):f.write('%.5e %.5e\n' % (Es1[i],Spectrum1[i]))f.close()import matplotlib.pyplot as pltimport numpy as npdata = np.loadtxt("new-broaden.dat", unpack=True)plt.plot(data[0], data[1])plt.show()















 6314
6314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









