







##1.明确目标
1.1在url上找到要爬取的信息

1.2.确定了信息,编写items文件
|
|
- **print 是测试 看是否能够打印出信息** **2.1user agent在settings中开启**
- 在网页中抓取 user agent 并写到settings中去

- 写到setting中

2.2创建main文件 并且执行 测试是否爬取信息
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())

2.3spider里面的parse通过写xpath进行解析
xpath教程
点击具体的名称 右击检查 即可看到位置 下载xpath插件 可以匹配到对应的位置


进入spider写对应的结果


可以测试 print(douban_item)查看是否能够下载进去
|
|
- def parse(self, response):
- movie_list=response.xpath("//div[@class='article']//ol[@class='grid_view']/li");
- for i_item in movie_list:
- douban_item = DoubanItem()
- douban_item['serial_number']=i_item.xpath(".//div[@class='item']//em//text()").extract_first()
- douban_item['movie_name']=i_item.xpath(".//div[@class='hd']//a//span[1]/text()").extract_first()
- content=i_item.xpath(".//div[@class='bd']//p[1]/text()").extract()
- for i_content in content:
- content_s = "".join(i_content.split())
- douban_item['introduce'] = content_s
- douban_item['star'] = i_item.xpath(".//div[@class='star']//span[2]/text()").extract_first()
- douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
- douban_item['describe'] = i_item.xpath(".//p[@class='quote']//span[1]/text()").extract_first()
- yield douban_item
- #链接下一页
- next_link = response.xpath("//span[@class='next']/link/@href").extract()
- if (next_link):
- next_link = next_link[0]
- #传给调度器
- yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
- pass
- ##(注意)对于内容有多行的(content) 就需要特殊处理 处理完后记得要```yield```将其发给pipeline 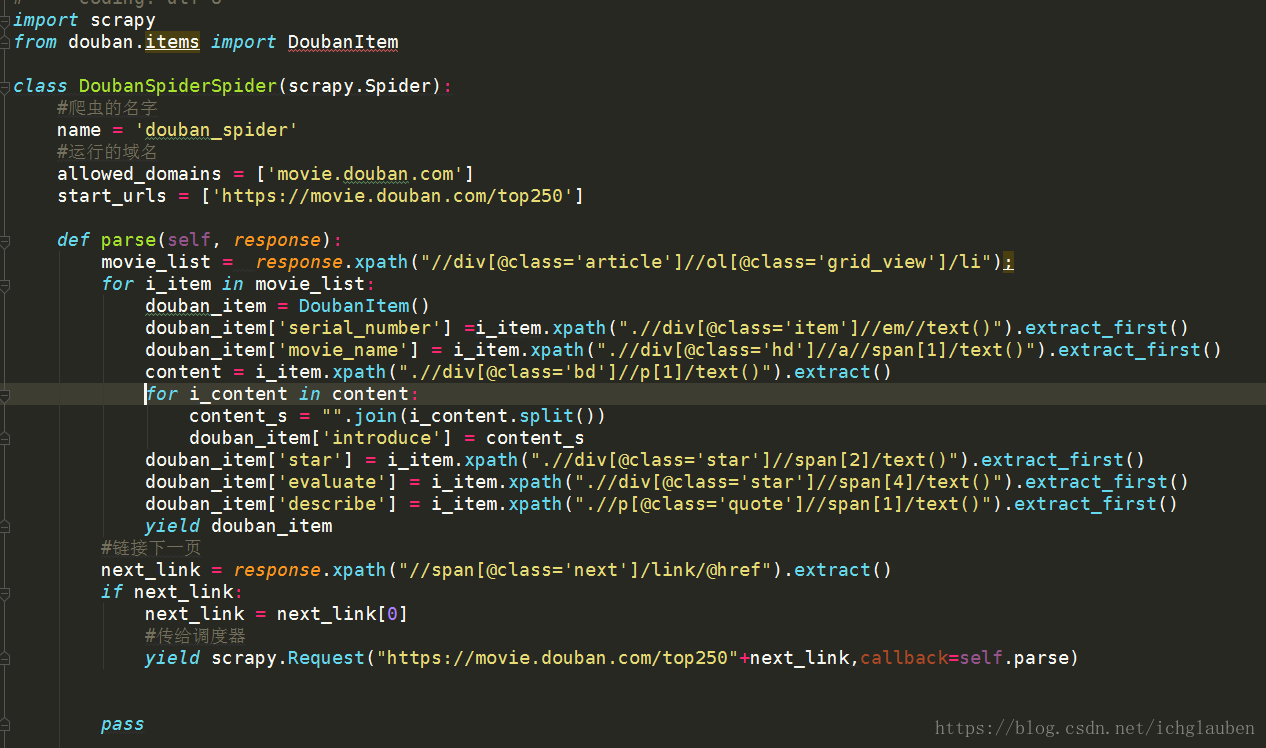
##解析下一页
自动检索下一页

#链接下一页 next_link = response.xpath("//span[@class='next']/link/@href").extract() if next_link: next_link = next_link[0] #传给调度器 yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)##将数据保存到json或者csv格式
scrapy crawl douban_spider -o douban.json scrapy crawl douban_spider -o douban.csv















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









