







首先,学习朴素贝叶斯算法得了解一些基本知识,比如全概率公式和贝叶斯公式,这些知识随便找一本书或者在网上都能够获得。在此,这里仅关注贝叶斯算法本身,以及其具体的实现(以例4.1的例子为参考)。
贝叶斯算法:


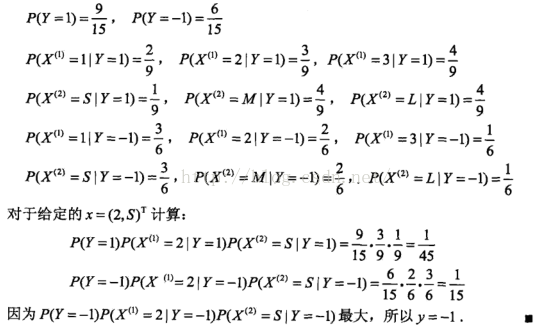
首先,学习朴素贝叶斯算法得了解一些基本知识,比如全概率公式和贝叶斯公式,这些知识随便找一本书或者在网上都能够获得。在此,这里仅关注贝叶斯算法本身,以及其具体的实现(以例4.1的例子为参考)。
贝叶斯算法:
 1335
1299
1002
1335
1299
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















