







引言:AI视频生成技术的革命性突破
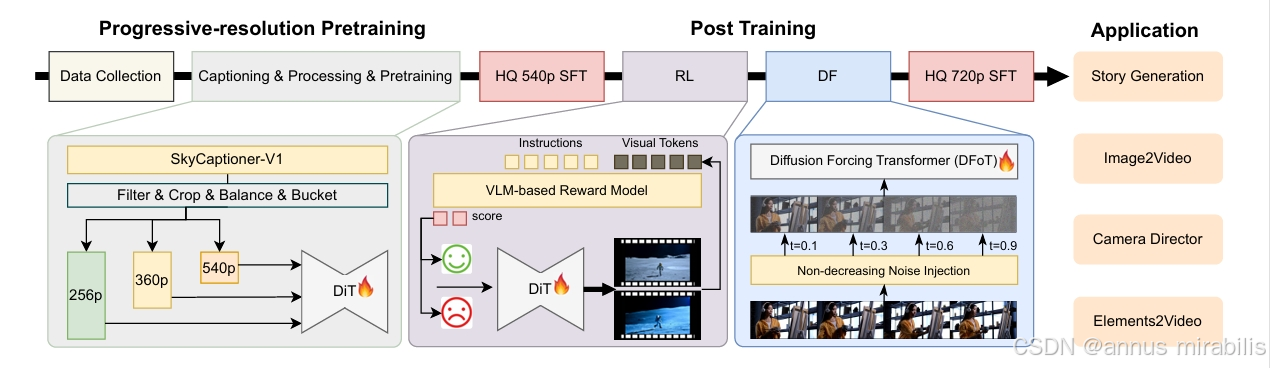
2025年4月21日,昆仑万维SkyReels团队正式发布并开源了全球首个使用扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型——SkyReels-V2,标志着AI视频生成技术迈入了一个全新阶段。这一突破性技术通过结合多模态大语言模型(MLLM)、多阶段预训练(Multi-stage Pretraining)、强化学习(Reinforcement Learning)和扩散强迫(Diffusion-forcing)框架,实现了前所未有的视频生成能力协同优化。
当前AI视频生成领域面临三大核心挑战:提示词遵循能力不足、视觉质量与运动动态难以兼顾、视频时长受限(通常仅5-10秒)。SkyReels-V2不仅成功解决了这些技术瓶颈,还支持生成30秒、40秒的高质量视频,具备高运动质量、高一致性和高保真度的特点,理论上可实现无限时长视频生成。本文将深入解析SkyReels-V2的技术原理、创新亮点、性能表现以及实际应用场景,帮助开发者全面了解这一前沿技术。
技术架构与核心创新
1. 多模态视频理解模型:SkyCaptioner-V1
SkyReels-V2的核心基础之一是影视级视频理解模型SkyCaptioner-V1。该模型采用了一种结构化的视频表示方法,创新性地将多模态大语言模型(MLLM)的一般描述与子专家模型的详细镜头语言相结合。这种设计使模型能够精准识别视频中的:
-
主体类型:识别场景中的人物、动物、物体等
-
外观特征:包括服装、颜色、材质等细节
-
表情变化:捕捉人物面部情绪的细微变化
-
动作模式:分析运动轨迹和行为模式
-
空间位置:确定主体在场景中的相对位置
团队通过大量人工标注和模型训练,显著提升了对专业镜头语言的理解能力。SkyCaptioner-V1不仅能理解视频的一般内容,还能捕捉电影场景中的专业镜头语言(如推拉摇移等运镜技巧),从而大幅提高了生成视频的提示词遵循能力。这一模型现已开源,开发者可直接使用。
2. 运动质量偏好优化技术
现有视频生成模型在运动质量上表现不佳,主要原因是优化目标未能充分考虑时序一致性和运动合理性。SkyReels-V2通过强化学习(RL)训练框架,结合人工标注和合成失真数据,有效解决了动态扭曲、运动不合理等常见问题。
为降低数据标注成本,团队设计了一个半自动数据收集管道,能够高效生成偏好对比数据对。具体方法包括:
-
I2V Distortion:基于图像到视频生成的失真数据
-
T2V Distortion:基于文本到视频生成的失真数据
-
人工标注修正:专业人员对关键运动序列进行标注
通过这些数据训练奖励模型并进行直接偏好优化(DPO),SkyReels-V2在运动动态性、流畅性和物理合理性方面表现卓越,能够生成自然流畅且符合物理规律的运动内容。
3. 扩散强迫(Diffusion-forcing)框架
扩散强迫框架是SkyReels-V2实现长视频生成的核心技术创新。与传统方法不同,团队通过微调预训练的扩散模型,将其转化为扩散强迫模型,而非从零开始训练,这显著降低了训练成本并提高了生成效率。
关键技术突破在于采用了非递减噪声时间表,将连续帧的去噪时间表搜索空间从O(1e48)大幅降低到O(1e32)。这一优化使模型能够高效生成长视频内容,理论上支持无限时长视频生成。
扩散强迫框架的工作原理是:为每个帧分配独立的噪声水平,通过精心设计的噪声调度策略,确保视频序列在时间上的连贯性和稳定性。这种架构特别适合处理长视频生成中的错误累积问题,通过在前一帧添加轻微噪声来稳定生成过程。
4. 渐进式训练与多阶段优化
SkyReels-V2采用了渐进式分辨率预训练与四阶段后训练优化
的创新训练策略。训练数据来自三个主要来源:
-
通用数据集:整合了多个高质量开源资源,提供广泛的基础视频素材
-
自收集媒体:包含数十万部影视作品,覆盖120多个国家,总时长超600万小时
-
艺术资源库:精选互联网高质量视频资产,确保视觉质量达到专业标准
训练过程分为四个关键阶段:
-
初始概念平衡的监督微调(SFT)
-
运动特定的强化学习(RL)训练
-
扩散强迫框架(DF)训练
-
高质量SFT微调
这种阶梯式训练策略确保了模型性能的持续提升。
性能评估与基准测试
1. 专业评估体系
团队构建了专业评估体系,系统性评估四个关键维度:
-
指令遵循:评估对复杂导演意图的实现能力
-
运动质量:评估动态性、流畅性和物理合理性
-
一致性:评估主体和场景的持续一致性
-
视觉质量:评估画面清晰度、色彩准确性等
评估结果显示,SkyReels-V2在各项指标上均表现优异,能够精准理解并实现复杂的创作意图,生成的内容自然流畅,视觉质量达到专业影视级别。
2. 自动化评估表现
在主流自动化评估基准上,SkyReels-V2在总分和质量分上均优于所有对比模型。特别在长prompt评估中,展现出对复杂文本描述的出色理解能力,能够准确实现包含多个动作序列和场景变化的复杂提示。
应用场景与实践指南
1. 长视频创作
SkyReels-V2支持生成理论上无限时长的视频内容,通过滑动窗口方法保持连贯性。开发者可以通过一系列叙事文本提示,让模型编排连贯的视觉叙事,特别适合:
-
电影制作:生成复杂叙事和长镜头
-
广告创作:将静态故事板转化为动态视频
-
短剧制作:快速生成高质量短视频内容
2. 图像到视频合成
SkyReels-V2提供两种图像到视频生成方法:
-
微调全序列文本到视频架构
-
扩散强迫模型与帧条件结合
在专业评估中,其图像到视频生成质量与闭源商业模型相当。
3. 专业运镜控制
模型在摄像机运动方面表现出色,支持通过专业术语如"推镜头"、"摇摄"等精确控制运镜方式,实现电影级的镜头语言表达。
4. 多元素视频生成
基于SkyReels-V2的扩展方案支持将任意视觉元素组合成由文本引导的连贯视频,特别适合:
-
短剧制作:生成包含特定角色的连贯剧情
-
音乐视频:根据音乐生成匹配视觉
-
虚拟电商:为产品生成展示视频
快速入门指南
1. 基础文本到视频生成
python
from skyreels import SkyReelsV2
model = SkyReelsV2.from_pretrained("SkyworkAI/SkyReels-V2")
video_frames = model.generate(
prompt="宇航员在火星漫步,沙尘暴正在形成,电影质感",
num_frames=40,
guidance_scale=7.5,
seed=42
)
video_frames.save("output.mp4")
2. 图像到视频生成
python
from PIL import Image
from skyreels import SkyReelsV2_I2V
model = SkyReelsV2_I2V.from_pretrained("SkyworkAI/SkyReels-V2-I2V")
input_image = Image.open("input.jpg")
video_frames = model.generate(
image=input_image,
prompt="海浪拍打礁石,慢动作特写",
num_frames=30,
guidance_scale=8.0,
seed=123
)
video_frames.save("output.mp4")
技术挑战与未来展望
当前技术挑战包括:
-
计算资源需求较高
-
超长视频逻辑一致性
-
细粒度控制能力
未来发展方向:
-
更高效的架构
-
多模态交互
-
实时生成能力
-
个性化风格学习
结语
SkyReels-V2的发布标志着AI视频生成技术的重要突破,为创作者提供了前所未有的自由度和表现力。开发者可以基于这一先进技术构建各种创新应用,从影视制作辅助工具到个性化内容生成平台。随着技术不断演进,AI视频生成将彻底改变内容创作方式,释放人类创造力。建议开发者从简单示例开始,逐步探索更复杂的创作可能。


















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









