










文章目录
- SAM相关论文
- SAM优化或功能拓展
- [Medical Image Analysis2025]UN-SAM: Domain-Adaptive Self-Prompt Segmentation for Universal Nuclei Images - 通过自动生成掩码prompt减轻标注工作,实现细胞通用分割
- [NIPS2023]Segment Everything Everywhere All at Once - 比SAM交互能力更强
- PERSONALIZE SEGMENT ANYTHING MODEL WITH ONE SHOT - 1个参考样本实现SAM的指定物体分割
- [Nature Communications] MedSAM: Segment Anything in Medical Images - 医学领域SAM
- Personalizing Vision-Language Models With Hybrid Prompts for Zero-Shot Anomaly Detection - SAM用于zero-shot异常检测/分割一切异常[:boom:文本与异常图像的对齐,类似[GroundingDINO](https://github.com/IDEA-Research/GroundingDINO)/[GroundedSAM](https://github.com/IDEA-Research/Grounded-Segment-Anything)]
- 高效SAM
- 基于SAM实现的工具
- 综述
- SAM原作参考SAM解读
- SAM微调参考SAM微调
- 综合看下来与SAM相关的论文有很多,但对SAM本身进行优化的工作很少,大部分是结合SAM对具体场景的适配或优化,或实现功能的扩展例如增加mask的类别实现实例分割。还有很多将SAM扩展到可以用于3D对象的分割,本文不做关注因此未列出。
SAM相关论文
SAM优化或功能拓展
[Medical Image Analysis2025]UN-SAM: Domain-Adaptive Self-Prompt Segmentation for Universal Nuclei Images - 通过自动生成掩码prompt减轻标注工作,实现细胞通用分割
paper:https://www.sciencedirect.com/science/article/abs/pii/S1361841525001549
code:https://github.com/CUHK-AIM-Group/UN-SAM
SAM在自然场景中展现出卓越的性能,并对医学成像表现出令人瞩目的适应性。尽管有这些优势,但依赖劳动密集型的手动标注作为分割提示严重阻碍了其临床应用,特别是对于包含大量细胞的细胞核图像分析,密集的手动提示并不现实。为了在保留优势的同时克服当前SAM方法的局限性,我们提出了用于通用细胞核分割的域自适应自提示SAM框架(UN - SAM),通过提供一种在不同领域都具有卓越性能的全自动解决方案。具体而言,为了消除对每个细胞核进行提示标注所需的大量人力,我们设计了一个多尺度自提示生成(SPGen)模块,通过自动生成高质量的掩码提示来指导分割任务,从而彻底改变临床工作流程。此外,为了在各种细胞核图像中发挥SAM的能力,我们设计了一个域自适应调谐编码器(DT - Encoder),将视觉特征与领域通用和领域特定知识无缝融合,并进一步设计了一个域查询增强解码器(DQ - Decoder),通过利用可学习的域查询在不同的细胞核领域进行分割解码。大量实验证明,我们的UN - SAM在细胞核实例分割和语义分割方面超越了现有技术,尤其是在未知细胞核领域的泛化能力。
[NIPS2023]Segment Everything Everywhere All at Once - 比SAM交互能力更强
威斯康星+微软
- 比SAM更丰富的交互方式,例如涂鸦、文本+视觉提示组合等。
paper:https://arxiv.org/pdf/2304.06718
code:https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
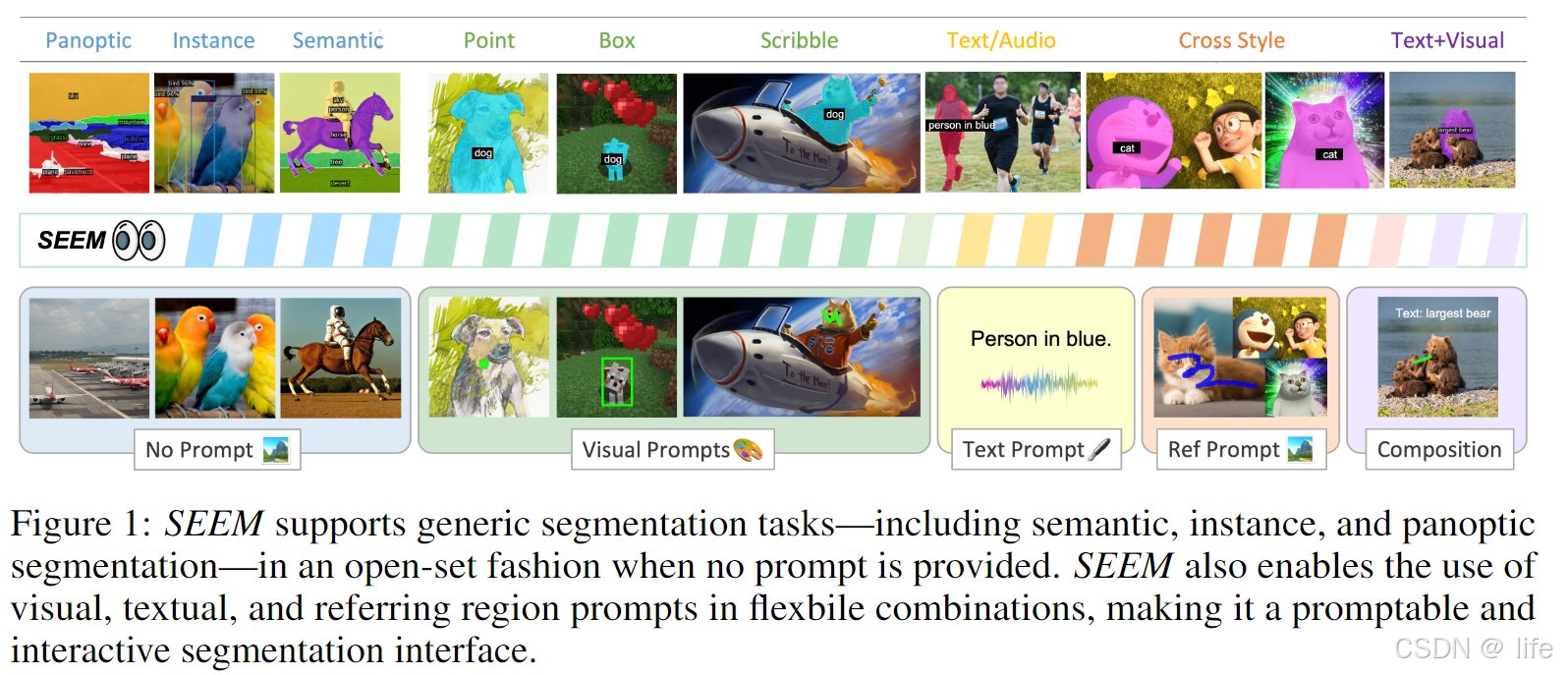
在这项工作中,我们提出了SEEM——一种可提示的交互式模型,能够对图像中任意位置的所有物体进行一次性分割,如图1所示。在SEEM中,我们设计了一种新颖的解码机制,支持对所有类型分割任务的多样化提示,旨在构建一个行为类似大型语言模型(LLM)的通用分割接口。具体而言,SEEM的设计遵循四个核心原则:i)通用性。我们引入新型视觉提示以统一不同空间查询(包括点、框、涂鸦和掩码),并可进一步泛化到不同参考图像;ii)组合性。我们学习文本与视觉提示的联合视觉语义空间,助力各类分割任务所需的两种提示类型的动态组合;iii)交互性。我们在解码器中融入可学习记忆提示,通过解码器到图像特征的掩码引导交叉注意力来保留分割历史;iv)语义感知。我们使用文本编码器将文本查询和掩码标签编码到同一语义空间,实现开放词汇分割。我们通过全面的实证研究验证了SEEM在多种分割任务中的有效性。值得注意的是,单个SEEM模型在9个数据集上的交互式分割、通用分割、指称分割和视频目标分割任务中均取得了具有竞争力的性能,且仅需最少1/100的监督量。此外,SEEM展现出对新提示或其组合的卓越泛化能力,使其成为现成的通用图像分割接口。
PERSONALIZE SEGMENT ANYTHING MODEL WITH ONE SHOT - 1个参考样本实现SAM的指定物体分割
香港中文大学、上海人工智能实验室
paper:https://arxiv.org/pdf/2305.03048
code:https://github.com/ZrrSkywalker/Personalize-SAM
在大数据预训练的推动下,Segment Anything Model(SAM)已被证明是一个强大的可提示框架,彻底革新了图像分割领域。尽管SAM具有通用性,但针对特定视觉概念在无需人工设计提示的情况下对其进行定制化的研究仍较为匮乏——例如从大量图像中自动分割出用户的宠物狗。本文提出了一种无需训练的SAM个性化方法PerSAM。仅需单样本数据(即一张带有参考掩码的图像),我们首先为新图像中的目标概念获取正负位置先验。然后,借助目标视觉语义,通过两项核心技术赋予SAM个性化目标分割能力:目标引导注意力机制与目标语义提示策略。通过这种方式,我们能够在完全无需训练的前提下,高效地将通用型SAM定制为专用模型。为进一步解决分割尺度模糊问题,我们提出了高效单样本微调变体PerSAM-F:在冻结整个SAM模型的基础上,引入尺度感知微调技术聚合多尺度掩码,仅需调整2个参数(耗时10秒)即可提升性能。为验证方法有效性,我们构建了全新数据集PerSeg用于个性化目标分割评估,并在多个单样本图像与视频分割基准上进行测试。此外,我们提出利用PerSAM改进DreamBooth实现个性化文本到图像合成,通过减轻训练集背景干扰,该方法在目标外观生成质量和文本提示保真度上均展现出优势。相关代码已开源至https://github.com/ZrrSkywalker/Personalize-SAM。
[Nature Communications] MedSAM: Segment Anything in Medical Images - 医学领域SAM
code:https://github.com/bowang-lab/MedSAM
医学图像分割是临床实践中的关键组成部分,有助于准确诊断、治疗方案规划和疾病监测。然而,现有的方法通常是针对特定的模态或疾病类型量身定制的,在各种医学图像分割任务中缺乏通用性。在此,我们提出了MedSAM,这是一个基础模型,旨在通过实现通用的医学图像分割来弥合这一差距。该模型是在一个大规模医学图像数据集上开发的,该数据集包含1570263个图像-掩码对,涵盖10种成像模态和30多种癌症类型。我们对86项内部验证任务和60项外部验证任务进行了全面评估,结果表明,与基于模态的专业模型相比,该模型具有更高的准确性和鲁棒性。通过在广泛的任务中提供准确、高效的分割,MedSAM在加速诊断工具的发展和治疗方案的个性化方面具有巨大潜力。
Personalizing Vision-Language Models With Hybrid Prompts for Zero-Shot Anomaly Detection - SAM用于zero-shot异常检测/分割一切异常[💥文本与异常图像的对齐,类似GroundingDINO/GroundedSAM]
华科
- 通过非图像的特定提示(异常描述+mask数量+物体名称等),对输入的要求挺高的,但其实现了文本描述-异常的感知,框架可以借鉴
paper:https://ieeexplore.ieee.org/document/10884560
code:https://github.com/caoyunkang/Segment-Any-Anomaly
零样本异常检测(ZSAD)旨在开发一种基础模型,该模型能够在不依赖参考图像的情况下检测任意类别的异常。然而,由于“异常”本质上是相对于特定类别中的“正常”来定义的,因此在没有描述相应正常上下文的参考图像的情况下检测异常仍然是一项重大挑战。作为参考图像的替代方案,本研究探索使用广泛可用的产品标准来描述正常上下文和潜在的异常状态。具体而言,本研究引入了AnomalyVLM,它利用通用预训练视觉语言模型(VLM)来解读这些标准并检测异常。鉴于当前VLM在理解复杂文本信息方面的局限性,AnomalyVLM从标准中生成混合提示(包括针对异常区域的提示、符号规则和区域编号),以促进更有效的理解。这些混合提示被整合到所选VLM中异常检测过程的各个阶段,包括异常区域生成器和异常区域优化器。通过使用混合提示,VLM被定制为特定类别的异常检测器,为用户提供了在无需训练数据的情况下检测新类别异常的灵活性和控制权。在四个公开的工业异常检测数据集以及实际汽车零部件检测任务上的实验结果突出了AnomalyVLM的卓越性能和更强的泛化能力,尤其是在纹理类别中。
高效SAM
可以参考以下,包含FastSAM、MobileSAM、Efficient-SAM、Edge-SAM、RepViT-SAM
https://github.com/IDEA-Research/Grounded-Segment-Anything/tree/main/EfficientSAM
基于SAM实现的工具
半自动标注
anylabeling
code:https://github.com/vietanhdev/anylabeling
Effortless data labeling with AI support from YOLO and Segment Anything! AnyLabeling = LabelImg + Labelme + Improved UI + Auto-labeling
X-AnyLabeling - 相比anylabeling模型集成更丰富
code:https://github.com/CVHub520/X-AnyLabeling
X-AnyLabeling 是一款基于AI推理引擎和丰富功能特性于一体的强大辅助标注工具,其专注于实际应用,致力于为图像数据工程师提供工业级的一站式解决方案,可自动快速进行各种复杂任务的标定。
OpenMMLab PlayGround: Semi-Automated Annotation with Label-Studio and SAM
https://github.com/open-mmlab/playground/tree/main/label_anything
Segment Anything Labelling Tool (SALT)
code:https://github.com/anuragxel/salt#segment-anything-labelling-tool-salt
图像编辑
Edit Anything by Segment-Anything
code:https://github.com/sail-sg/EditAnything
This is an ongoing project aims to Edit and Generate Anything in an image, powered by Segment Anything, ControlNet, BLIP2, Stable Diffusion, etc.
综述
https://arxiv.org/pdf/2305.08196
可以看出大部分都是结合SAM与其他模型实现的工具,例如
- 与CLIP结合实现语义感知
- 与stabel diffusion、controlnet结合实现inpainting或图像编辑
- 与目标检测模型结合实现实例分割
| No. | Project | Title | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| 001 | SAM-Track | Segment and Track Anything | Google Colab | GitHub | Zhejiang University | 用于视频中自动或交互式跟踪和分割任何对象,结合SAM和XMem等技术。 |
| 002 | Grounded-SAM | Grounded Segment Anything | Google Colab | GitHub | IDEA Research | 结合Grounding DINO和SAM,支持文本输入的对象检测与分割。 |
| 003 | MMDet-SAM | - | - | GitHub | OpenMMLab | 结合SAM与目标检测(封闭集、开放集、接地检测)的实例分割方案。 |
| 004 | MMRotate-SAM | Zero-shot Oriented Object Detection with SAM | - | GitHub | OpenMMLab | 结合SAM和弱监督水平框检测,实现旋转框检测。 |
| 005 | MMOCR-SAM | - | - | GitHub | OpenMMLab | 文本检测/识别与SAM结合,支持文本字符分割和扩散模型驱动的文本去除/修复。 |
| 006 | MMEditing-SAM | - | - | GitHub | OpenMMLab | 结合SAM和图像生成,支持图像编辑和生成。 |
| 007 | Label-Studio-SAM | Semi-Automated Annotation with Label-Studio and SAM | - | GitHub | OpenMMLab | 结合Label-Studio和SAM实现半自动标注。 |
| 008 | PaddleSeg-SAM | Segment Anything with PaddleSeg | - | GitHub | PaddlePaddle | PaddlePaddle格式的SAM预训练模型参数。 |
| 009 | SegGPT | Segmenting Everything In Context | Hugging Face | GitHub | BAAI-Vision | 基于Painter的上下文分割模型,支持“分割一切”。 |
| 010 | SEEM | Segment Everything Everywhere All at Once | Hugging Face | GitHub | Microsoft | 支持多模态提示的通用分割模型。 |
| 011 | CLIP Surgery | CLIP Surgery for Better Explainability | Demo | GitHub | HKUST | 基于CLIP的可解释性改进,实现无手动点的文本到掩码生成。 |
| 012 | SAMCOD | Can SAM Segment Anything? When SAM Meets Camouflaged Object Detection | - | GitHub | - | SAM与伪装对象检测(COD)任务结合。 |
| 013 | Inpaint Anything | Segment Anything Meets Image Inpainting | Hugging Face | GitHub | USTC and EIT | SAM与图像修复结合,支持对象平滑去除。 |
| 014 | PerSAM | Personalize Segment Anything with One Shot | arXiv | GitHub | - | 单样本个性化SAM,支持特定视觉概念分割。 |
| 015 | MedSAM | Segment Anything in Medical Images | - | GitHub | - | 医学图像分割的SAM教程,支持小数据集快速应用。 |
| 016 | Segment-Any-Anomaly | GroundedSAM Anomaly Detection | Google Colab | GitHub | HUST | 结合Grounding DINO和SAM的异常分割模型。 |
| 017 | SSA | Semantic Segment Anything | - | GitHub | Fudan University | 自动密集类别标注引擎,为SA-1B数据集提供初始语义标注。 |
| 018 | Magic Copy | - | - | GitHub | - | Chrome扩展,使用SAM提取图像前景并复制到剪贴板。 |
| 019 | Segment Anything with Clip | - | Hugging Face | GitHub | - | SAM与CLIP结合的应用。 |
| 020 | MetaSeg | Segment Anything Video | Hugging Face | GitHub | - | SAM的视频处理打包版本。 |
| 021 | SAM in Napari | Segment Anything Model (SAM) in Napari | Napari Hub | GitHub | Applied Computer Vision Lab and German Cancer Research Center | 将SAM的点击分割扩展到全点击语义/实例分割,集成到Napari。 |
| 022 | SAM Medical Imaging | - | - | GitHub | - | 医学影像领域的SAM应用。 |
| 023 | 3D-Box | 3D-Box via Segment Anything | - | GitHub | - | 结合SAM和VoxelNeXt,扩展至3D感知。 |
| 024 | Anything-3D | - | - | GitHub | - | 支持3D新视图生成、NeRF和3D人脸的SAM扩展。 |
| 025 | L2SET | Learning to Segment EveryThing | - | GitHub | UC Berkeley, FAIR | 实例分割的部分监督训练范式。 |
| 026 | Edit Anything | Edit Anything by Segment-Anything | - | GitHub | - | 基于SAM、ControlNet、StableDiffusion的图像编辑工具。 |
| 027 | Image Edit Anything (IEA) | - | - | GitHub | - | 使用Stable Diffusion和SAM进行图像编辑。 |
| 028 | SAM for Stable Diffusion Webui | Segment Anything for Stable Diffusion WebUI | - | GitHub | - | 连接Stable Diffusion WebUI和ControlNet,增强图像修复功能。 |
| 029 | Earth Observation Tools | Segment Anything EO tools | Google Colab | GitHub | - | SAM的地球观测工具,支持GeoTIFF和TMS数据处理。 |
| 030 | Moving Object Detection | Towards Segmenting Anything That Moves | - | GitHub | - | SAM与运动对象检测结合的项目。 |
| 031 | OCR-SAM | Optical Character Recognition with Segment Anything | 知乎 | GitHub | - | 结合MMOCR、SAM和Stable Diffusion的OCR方案。 |
| 032 | SALT | Segment Anything Labelling Tool | - | GitHub | - | 使用SAM的轻量标注工具,支持COCO格式掩码保存。 |
| 033 | Prompt Segment Anything | - | - | GitHub | - | 基于SAM的零样本实例分割实现。 |
| 034 | SAM-RBox | - | - | GitHub | - | 使用SAM生成旋转边界框,对比H2RBox-v2方法。 |
| 035 | VISAM | MOTRv2: Bootstrapping End-to-End Multi-Object Tracking by Pretrained Object Detectors | - | GitHub | - | 结合SAM和MOT,开启“MOTS”时代。 |
| 036 | SegEO | Segment Anything EO | - | GitHub | - | 基于滑动窗口算法的空间数据(GeoTIFF/TMS)处理工具。 |
| 037 | Napari Segment Anything tools | - | Codecov | GitHub | - | SAM的原生Qt UI工具。 |
| 038 | SegDrawer | Simple static web-based mask drawer | - | GitHub | - | 简单的基于Web的掩码绘制工具,支持SAM语义分割。 |
| 039 | Segment-Anything-U-Specify | - | Google Colab | GitHub | - | 使用CLIP和SAM,通过文本提示分割指定实例。 |
| 040 | Track Anything | Segment Anything Meets Videos | Hugging Face | GitHub | SUSTech | 灵活的交互式视频对象跟踪与分割工具。 |
| 041 | Count Anything | - | - | GitHub | - | 使用SAM和CLIP,基于文本提示计数任意对象,无需手动标注。 |
| 042 | RAM | Relate Anything Model | Hugging Face | GitHub | MMLab, NTU and VisCom Lab, KCL/TongJi | 输入图像,利用SAM识别对应掩码。 |
| 043 | SegmentAnyRGBD | - | Hugging Face | GitHub | Showlab, NUS | 基于SAM的RGBD图像分割工具箱。 |
| 044 | Show Anything | - | Hugging Face | GitHub | Showlab, NUS | 兼容SAM和生成模型的应用集合。 |
| 045 | Any-to-Any Style Transfer | Making Picasso and Da Vinci Collaborate | - | GitHub | LV-lab, NUS | 交互式风格迁移工具,支持不同区域应用不同风格。 |
| 046 | Caption Anything | - | Google Colab | GitHub | VIP lab, SUSTech | 结合SAM、视觉caption和ChatGPT的多功能图像处理工具。 |
| 047 | Image2Paragraph | Transform Image Into Unique Paragraph | 个人主页 | GitHub | - | 利用OFA、ChatGPT、BLIP2等将图像转换为文本段落。 |
| 048 | LIME-SAM | Local Interpretable Model-agnostic Explanations for Segment Anything | Google Colab | GitHub | - | 基于LIME的SAM可解释性工具,替换超像素方法。 |
| 049 | Paint Anything | - | - | GitHub | - | 基于SAM的交互式笔触绘画工具,支持类人绘画。 |
| 050 | SAMed | Customized Segment Anything Model for Medical Image Segmentation | Google Colab | GitHub | USTC | 基于SAM的医学图像分割定制模型,探索大规模模型定制范式。 |
| 051 | Personalize SAM | Personalize Segment Anything with 1 Shot in 10 Seconds | Hugging Face | GitHub | MMLab, CUHK | 无训练个性化方法PerSAM,单样本快速定制SAM。 |
| 052 | Open-vocabulary-Segment-Anything | - | - | GitHub | - | 结合OwlViT和SAM,支持开放词汇检测与分割(文本/图像条件)。 |
| 053 | Label-Anything-Pipeline | - | - | GitHub | ZJU | 结合GPT-4和SAM的视觉任务一站式标注管道。 |
| 054 | Grounded-Segment-Any-Parts | Grounded Segment Anything: From Objects to Parts | 项目主页 | GitHub | HKU | 扩展SAM支持文本提示(对象级/部件级)的分割。 |
| 055 | AnyLabeling | - | YouTube | GitHub | - | 基于SAM和YOLO的AI辅助数据标注工具。 |
| 056 | SSA | Semantic Segment Anything | Replicate | GitHub | - | 自动密集类别标注引擎,为SA-1B提供初始语义标签。 |
| 057 | RefSAM | Label Data with Segment Anything in Roboflow | 博客 | GitHub | - | 基于SAM的Referring图像分割基准测试。 |
| 058 | Roboflow Annotate | Launch: Label Data with Segment Anything in Roboflow | 博客 | Roboflow平台 | Roboflow | SAM辅助标注工具,用于训练计算机视觉模型。 |
| 059 | ImageBind SAM | - | - | GitHub | IDEA Research | 结合ImageBind和SAM,支持多模态掩码生成的实验性演示。 |
参考,感谢以下研究人员的整理:
https://zhuanlan.zhihu.com/p/630529550
https://blog.csdn.net/m0_61899108/article/details/132024941
https://github.com/liliu-avril/Awesome-Segment-Anything


















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











