







工作流模版地址:Fully Automated AI Video Generation & Multi-Platform Publishing | n8n workflow template
本文将全面剖析基于n8n平台的这个"全自动AI视频生成与多平台发布"工作流的技术架构、实现原理和关键节点,帮助开发者深入理解这一自动化流程的内部机制。
一、工作流整体架构
该工作流采用模块化设计,主要分为五个功能层:
-
触发层:负责工作流的启动机制
-
内容生成层:处理文本、图像和语音的AI生成
-
视频合成层:将多媒体素材组合成完整视频
-
发布层:处理多平台分发逻辑
-
监控层:记录执行状态和发送通知
二、触发机制详解
1. 核心触发类型
-
定时触发器(Cron节点):
json
{ "expression": "0 9 * * 1-5", "timezone": "Asia/Shanghai" }配置示例表示工作日早上9点自动执行,采用标准的cron表达式语法
-
REST API触发器(Webhook节点):
暴露一个HTTP端点接收外部请求,支持:-
GET/POST方法
-
请求参数验证
-
负载解析
-
-
手动触发器(Manual节点):
提供即时执行按钮,常用于测试和紧急发布
2. 触发条件优化
高级配置可包括:
-
依赖检查(如检查素材库更新)
-
速率限制(防止频繁触发)
-
上下文传递(跨工作流触发)
三、AI内容生成模块
1. 文本生成引擎
采用LLM模型实现:
javascript
// 典型配置参数
const llmParams = {
model: "gpt-4-turbo",
temperature: 0.7,
max_tokens: 2000,
prompt: `基于以下主题生成视频脚本:
主题:{{$node["主题输入"].json["topic"]}}
要求:包含开场、3个核心观点、结尾号召`
};
支持功能:
-
多轮对话式生成
-
结构化输出(JSON格式)
-
风格控制参数
2. 视觉素材生成
集成Stable Diffusion等模型:
python
# 图像生成伪代码
def generate_image(prompt):
payload = {
"engine": "stable-diffusion-xl",
"steps": 30,
"cfg_scale": 7,
"width": 1920,
"height": 1080,
"prompt": prompt + " cinematic style, 8k"
}
return api_call(payload)
关键参数:
-
分辨率适配各平台要求
-
风格一致性控制
-
批量生成与优选
3. 语音合成技术
采用TTS服务:
yaml
tts_config: provider: azure voice: zh-CN-YunxiNeural style: cheerful rate: +10% pitch: +5%
高级特性:
-
情感语调控制
-
多语言混合
-
发音校正
四、视频合成引擎
1. FFmpeg处理管道
典型视频合成命令:
bash
ffmpeg \ -y \ -i background.mp4 \ -i voiceover.mp3 \ -filter_complex \ "[0:v]scale=1920:1080[bg]; \ [bg][1:a]concat=n=1:v=1:a=1[v][a]; \ [v]subtitles=sub.ass:force_style='Fontsize=24'[outv]" \ -map "[outv]" -map "[a]" \ -c:v libx264 -crf 23 \ -preset fast \ output.mp4
处理阶段:
-
基础素材准备
-
多轨道合成
-
字幕渲染
-
编码输出
2. 动态效果处理
高级特效实现:
-
关键帧动画(通过AE脚本导出)
-
智能转场(基于内容分析)
-
自动节拍匹配(音频分析驱动)
3. 质量控制系统
自动化检测项目:
-
黑帧检测
-
静音检测
-
分辨率验证
-
码率分析
五、多平台发布模块
1. 平台适配层
统一接口设计:
typescript
interface PlatformAdapter {
authenticate(config: AuthConfig): Promise<Session>;
upload(video: VideoAsset, meta: Metadata): Promise<PostResult>;
formatMetadata(meta: RawMetadata): PlatformMetadata;
}
各平台实现差异:
-
YouTube:支持章节标记、结尾画面
-
Instagram:Reels和Feed不同规格
-
TikTok:需要特殊标签格式
2. 发布策略管理
智能调度功能:
-
最佳发布时间计算
-
平台优先级设置
-
失败重试策略
-
去重检测
3. 元数据自动化
动态生成:
-
标题优化(基于SEO分析)
-
标签推荐(内容关键词提取)
-
描述模板(包含CTA变量)
六、异常处理系统
1. 错误分类体系
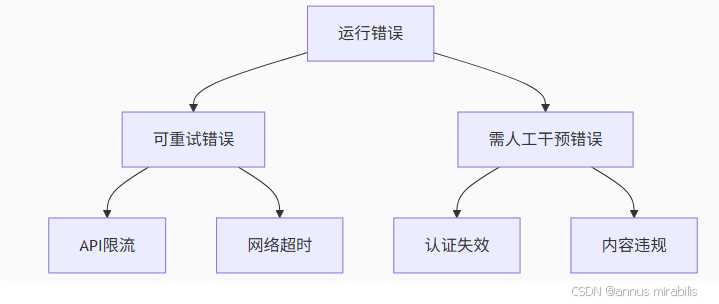
2. 恢复机制
典型处理流程:
-
错误捕获(try-catch块)
-
分类判断(错误代码映射)
-
重试策略(指数退避算法)
-
状态回滚(事务管理)
-
通知触发(告警升级)
七、性能优化方案
1. 并行处理架构
python
# 伪代码示例
with ParallelExecutor(max_workers=4) as executor:
futures = [
executor.submit(generate_script, topic),
executor.submit(generate_images, keywords),
executor.submit(prepare_music, mood)
]
results = [f.result() for f in futures]
2. 缓存策略
多级缓存设计:
-
内存缓存(高频素材)
-
磁盘缓存(处理中间结果)
-
外部存储(长期素材库)
3. 资源监控
关键指标采集:
go
type Metrics struct {
CPUUsage float64
MemoryMB int
APICalls map[string]int
StepTiming map[string]time.Duration
ErrorRates map[string]float64
}
八、安全合规考虑
1. 内容审核流程
审核节点配置:
-
文本过滤(敏感词库)
-
图像识别(违规内容检测)
-
版权校验(音乐/图像授权)
2. 数据保护措施
安全实践:
-
API密钥加密存储
-
临时文件安全删除
-
传输层加密(TLS 1.3)
-
访问日志审计
九、扩展设计模式
1. 插件式架构
扩展点设计:
/workflow
/extensions
/content_sources
/ai_models
/platforms
/effects
2. 配置驱动开发
模板化配置示例:
json
{
"content_flow": {
"script": {
"model": "claude-3-opus",
"template": "educational"
},
"visual": {
"style": "infographic",
"branding": {
"logo": "assets/logo.png",
"watermark": true
}
}
}
}
十、技术演进方向
-
AI模型微调:针对垂直领域优化生成质量
-
实时渲染:基于WebGL的浏览器端合成
-
智能剪辑:内容理解驱动的自动剪辑
-
跨平台分析:发布后效果反馈闭环
该工作流展示了如何将现代AI能力与自动化工程实践深度整合,通过n8n的可视化编程界面,开发者可以灵活调整每个处理环节的参数和逻辑,构建符合特定业务需求的视频生产流水线。核心价值在于将原本需要多个专业工具和多人员协作的复杂流程,转变为可版本控制、可监控的标准化自动化系统。


















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









