







大家好,我是 annus mirabilis。
俗话说得好,可以不懂人情世故,但不能不懂AI。这句话在当今这个时代,我觉得尤其适用。AI 浪潮汹涌澎湃,新技术层出不穷,稍不留神就可能被拍在沙滩上。而在 AI 的众多应用中,数字人无疑是最近风头最劲、也最引人关注的一个领域。它不仅能解放生产力,甚至能创造全新的内容形式和交互体验。

这不,最近有一个号称“硅基开源”的 HeyGem AI 数字人项目在圈子里传得火热。听闻效果惊人,而且还能在本地部署,这一下子就勾起了我的好奇心。作为数字人领域的“老兵”(姑且这么自称吧,哈哈),我可不能错过这么好的“玩具”。
于是,我马不停蹄地把它拿来进行了深度实测和研究。效果究竟如何?跑起来吃不吃配置?最关键的部署流程是不是像传说中那么复杂?以及,它号称的“开源”到底有几分真假?这些都是大家关心的问题,也是我 annus mirabilis 在这篇文章里将要为大家一一揭晓的秘密。
在本篇文章中,我将带大家走过一个完整的 HeyGem AI 体验旅程:
-
先看效果硬不硬:直接展示我用它生成的数字人视频,眼见为实。
-
再测资源吃不吃:详细分析运行它所需的硬件配置,特别是大家最关心的显卡占用情况。
-
手把手教你部署:分享我 annus mirabilis 独家整理的“一键部署”方法,让复杂的安装变得像“大象装冰箱”一样简单。
-
最后揭秘“开源”:深入剖析 HeyGem AI 的技术架构,聊聊它究竟“开源”了什么,又“藏着”什么。
话不多说,咱们直接进入正题!
一、惊艳初见:HeyGem AI 数字人效果实测
任何工具,效果好才是硬道理。在我 annus mirabilis 看来,一个数字人工具的优劣,最直观的体现就是它生成的视频是否自然、逼真。
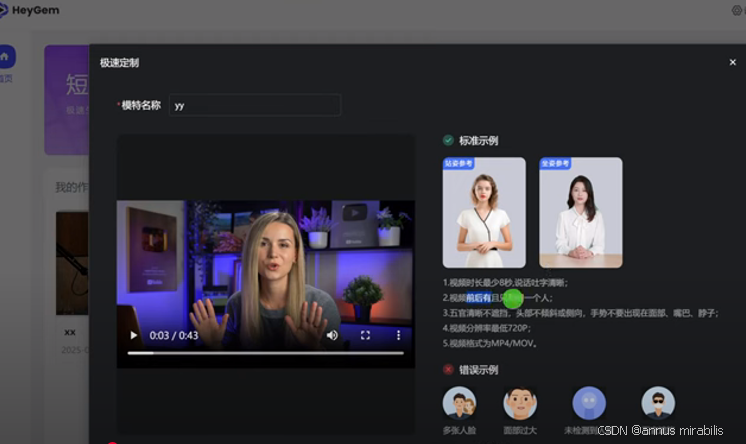
我首先导入了一段我自己的原始视频素材。这段视频时长超过了 HeyGem AI 要求的最短 8 秒限制,画面也比较清晰,符合它对模特视频的要求。说实话,这原始视频嘛,就是普通的记录,没什么特别之处。
接着,我利用 HeyGem AI,基于这段原始素材生成了一段新的数字人视频。当我第一次看到生成结果时,说实话,心里是“咯噔”一下——哇塞,效果确实超出预期!
对比原始视频,数字人视频中的我(或者说我的数字分身)嘴型与新的语音内容(我输入了一段新的文本让它去合成)完美匹配,面部的细微表情也能跟着语气的变化而联动。眼神、头部的小动作都显得很自然,不像一些低质量数字人那样显得僵硬或呆板。听觉上,合成的语音也相当流畅自然,几乎没有明显的机器感。
在我 annus mirabilis 过去接触过的许多号称“开源”或半开源的数字人项目中,达到这种级别的效果的,HeyGem AI 绝对是目前我所见到的第一家。它在效果上,确实立住了脚跟。
当然,这里我已经在心里给它的“开源”属性打了个问号,这个问号我们在文章的最后一部分会详细解答。但从纯粹的效果层面讲,HeyGem AI 的表现是令人满意的。
二、能跑起来吗?资源占用深度解析
效果再好,如果“吃”的资源太多,让大多数人的电脑望而却步,那也意义不大。所以,效果看完,我 annus mirabilis 立刻把注意力转向了它的资源占用情况。这是大家普遍关心的问题:我的电脑到底能不能跑得动?跑起来流畅不流畅?
在使用过程中,HeyGem AI 的运行架构是这样的:它有一个你直接操作的“前端”程序,就像一个漂亮的驾驶舱;而真正干活的“后端”则有三个服务在默默运行,它们是数字人生成的“发动机”和“变速箱”。我们主要观察的就是这三个后端服务工作时的资源消耗。
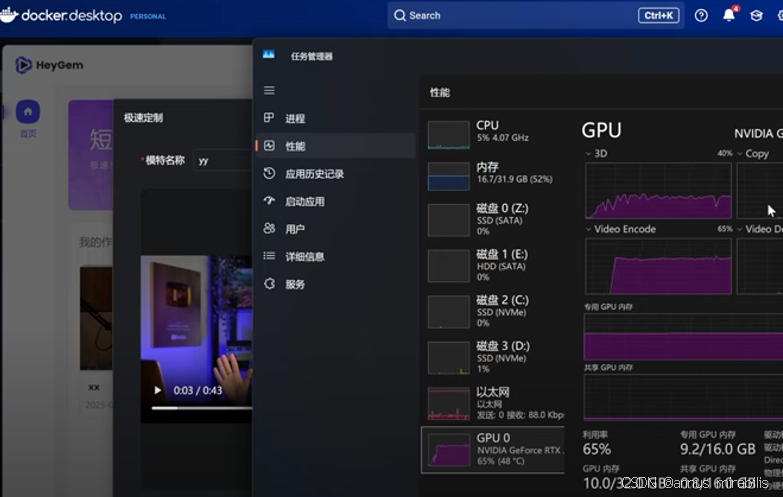
我分别在定制模特和生成视频两个关键环节观察了系统的资源管理器。
-
定制模特阶段:
当你上传视频素材,让它去“学习”生成你的数字分身模型时,这个阶段的资源占用并不高。主要是文件上传、初步分析等任务,对 CPU、内存和 GPU 的压力都相对较小。这是一个“准备”过程,机器配置稍弱一点也不用担心。 -
生成视频阶段 (核心!):
这才是真正“见真章”的时候。当你输入文本或音频,点击“生成视频”的那一刻起,系统的资源占用就开始攀升了。-
内存 (RAM): 在我的测试中,总共 32GB 的内存,它大概占用了 18GB 左右。这说明 HeyGem AI 在生成过程中会使用相当一部分内存来加载数据和中间结果。如果你只有 8GB 或 16GB 内存,可能需要关闭一些其他程序,确保内存充足。16GB 勉强够用,32GB 更稳妥。
-
CPU: 令人意外的是,CPU 在整个生成过程中并非主要瓶颈,占用率并不持续处于高位。大部分繁重的计算任务,都交给了另一个硬件。
-
GPU (显卡,划重点!): 这才是 HeyGem AI 的“动力心脏”,也是决定你能否流畅运行、甚至能否运行的关键!
-
在视频合成过程中,GPU 的利用率会显著飙升。我观察到,它的计算过程似乎是分批次的,比如每处理几帧画面,GPU 利用率就会上来一下,然后再稍微回落,呈现出一种波动的状态。这是因为后端服务在进行人脸检测、特征提取、画面合成、人脸增强等一系列复杂的图形学和 AI 计算。
-
更重要的是 GPU 的显存 (VRAM) 占用。在我使用的 16GB 显存显卡上,我看到显存占用峰值大约在 10GB 到 13GB 之间波动。这个数据非常关键!
-
结论: 这意味着,HeyGem AI 对显卡显存的要求是比较高的。如果你有一块显存达到 16GB 的独立显卡(比如 RTX 4060Ti 16G、RTX 3090、RTX 4080 等),跑起来会相对流畅,生成速度也更快。如果是12GB 显存的显卡(比如 RTX 3060 12G、RTX 4070 等),可能需要根据具体视频长度和分辨率来看,有时候可能会遇到显存不足导致的生成失败或速度极慢的情况。显存低于 12GB 的显卡,我annus mirabilis 觉得,可能就比较困难,甚至无法正常运行了。
-
生成速度方面,在我配置还不错的机器上(使用 RTX 4060Ti 16GB 显卡进行测试),生成视频的时长与实际耗时比,大约在 1:4 到 1:8 之间。也就是说,生成一分钟的数字人视频,可能需要四到八分钟。这个速度取决于你的硬件性能,特别是显卡性能。
所以,总结一下硬件需求:内存建议 16GB 或以上,CPU 要求不高,但显卡必须给力,特别是显存,强烈建议 16GB 及以上,最低也得是 12GB 显存的型号。 如果你的显卡显存达不到这个标准,那么即使你对 HeyGem AI 再感兴趣,可能也只能先“持币观望”或者考虑升级硬件了。
-
三、告别复杂:annus mirabilis 的一键部署秘籍
了解了硬件要求,接下来就是最让许多小伙伴头疼的问题:怎么把这个 HeyGem AI 装到我自己的电脑上跑起来?官方的部署文档,对于不熟悉 Docker、命令行操作的小白用户来说,确实像看天书一样晦涩难懂。各种环境配置、依赖安装、服务启动,每一步都可能隐藏着无数的“坑”。
不过别担心!我 annus mirabilis 出马,当然是要把复杂的事情简单化。我已经为大家整理好了一个“懒人包”,并且编写了一个超简单的“一键部署”脚本。只要跟着我的步骤来,把“大象装冰箱”这件事,轻松搞定!
就像把大象装进冰箱只需要三步一样,把 HeyGem AI 部署到你本地,跟着我 annus mirabilis 的方法,也只需要简单的三步:
第一步:获取 annus mirabilis 的 HeyGem AI 懒人包
首先,你需要下载我 annus mirabilis 为大家精心准备的 HeyGem AI 资源包。这个包里包含了所有必需的文件:
-
HeyGem AI 前端程序安装包 (一个 .exe 文件)
-
Docker Desktop 安装包 (用于运行后端服务)
-
三个 HeyGem AI 后端服务的 Docker 镜像文件 (体积庞大!)
-
我的“一键部署”脚本文件 (init_base.bat)
-
一份简单的图文说明文档
这些资源文件总体积不小,特别是 Docker 镜像,加起来几十个 GB 是跑不掉的。所以下载需要一些时间和耐心,并且确保你有足够的硬盘空间来存放它们。
资源包的下载链接,我通常会放在这篇文章的评论区或者我的个人官网上对应的文章页面,大家去那里找就好了。
第二步:安装 Docker Desktop 并导入后端服务镜像
这是最关键的一步,也是我 annus mirabilis 用“一键脚本”为大家解决最大难题的地方。
-
安装 Docker Desktop: 打开资源包,找到 Docker Desktop Installer.exe 文件,双击运行,像安装普通软件一样把它装上。过程中如果需要重启电脑,按提示操作即可。
-
安装验证(可选但推荐): 安装完成后,打开系统的命令提示符 (CMD) 或 PowerShell。最好是在你存放 annus mirabilis 资源包的那个文件夹里打开终端。怎么打开呢?最简单的方法是,进入存放资源包的文件夹,然后在文件管理器的地址栏里输入 cmd 或 powershell,回车,终端窗口就会在你当前目录下打开。在终端里输入 docker --version 回车,如果看到类似 Docker version XX.YY.Z, build ... 的输出,就说明 Docker 安装成功了。别担心,即使你不手动检查,我的一键脚本也会帮你检查。
-
-
运行 annus mirabilis 的一键部署脚本 init_base.bat:
-
确保你当前在存放资源包的那个文件夹里(如果你按照上一步的方法打开的终端,那就在正确位置)。
-
直接双击运行 init_base.bat 这个文件,或者在刚才打开的终端中输入 init_base.bat 回车。
-
脚本会自动执行:首先检查 Docker 环境是否就绪,然后会自动加载资源包里的三个 HeyGem AI 后端服务的 Docker 镜像。
-
耐心等待: 这一步需要一些时间,因为脚本正在将几十 GB 的镜像导入 Docker。请耐心等待,直到脚本运行完毕并提示成功。
-
-
验证后端服务是否正常运行:
-
打开 Docker Desktop 程序。
-
在左侧或顶部的菜单中找到 Containers (容器) 或 Images (镜像) 选项。
-
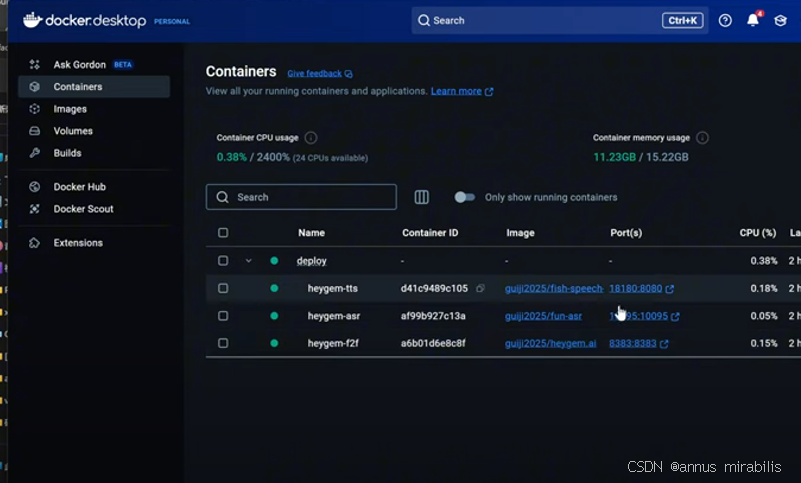
你应该能在 Containers 列表中看到三个名字类似 tts, asr, f2f 的容器正在运行中(状态显示为 Running)。如果都显示 Running,恭喜你,后端服务已经部署成功并启动了!
【特别注意!硬盘空间问题!】
这里有一个非常重要的细节,我 annus mirabilis 必须强调一下:Docker 默认会将下载和导入的镜像文件以及容器产生的数据存储在系统盘,通常是 C 盘!前面说了,这三个后端服务的镜像文件体积巨大,加起来轻轻松松几十个 GB。如果你像我一样,C 盘空间比较紧张(比如很多笔记本电脑的 C 盘只有 256GB 或 512GB SSD,系统和常用软件装完就没剩多少了),务必在运行一键脚本之前,更改 Docker 的数据存储路径!如何更改 Docker 数据路径: 打开 Docker Desktop 程序 -> 点击右上角的设置齿轮图标 (Settings) -> 在左侧菜单选择 Resources (资源) -> 找到 Disk image location (磁盘镜像位置) 或 Docker data folder 类似的选项 -> 点击 Browse (浏览) -> 选择一个空间充足的硬盘分区作为 Docker 的数据存储目录 -> 点击 Apply & Restart (应用并重启)。
-
-
完成这一步后再运行我的 init_base.bat 脚本,这样那些大体积的镜像文件就会乖乖地存到你指定的新位置,不会挤爆你的 C 盘了!这个小技巧,能帮你避开一个巨大的“坑”。
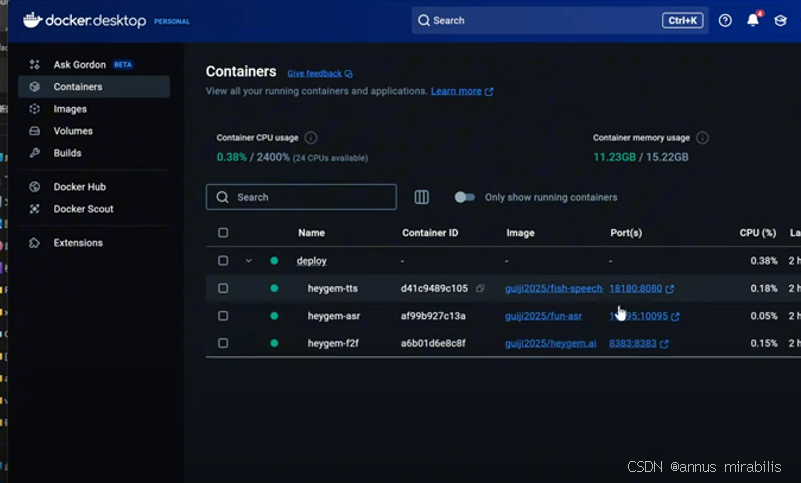
第三步:安装 HeyGem AI 前端程序并启动
前两步搞定,剩下的就很轻松了。
-
安装前端程序: 打开资源包,找到 HeyGem AI 的安装程序文件 (比如 HeyGem 1.03.exe),双击运行,按照提示一步步安装即可。这个程序本身不大。
-
启动程序: 安装完成后,在桌面或开始菜单找到 HeyGem AI 的图标,双击启动。
启动后的 HeyGem AI 界面,最初会是空白的模特列表和作品列表。这是正常的,因为你还没有添加任何模特或创建作品。接下来,你就可以按照前面“效果实测”部分提到的使用流程,点击“快速定制”上传你自己的视频来创建模特,然后选择模特和文本/音频来生成你的第一个数字人视频作品了!
看吧,在我 annus mirabilis 的这套“组合拳”下,原本复杂的部署过程是不是变得异常简单?基本上就是安装两个程序,然后运行一个脚本等一会儿。只要你的硬件达标,按照这个流程来,成功率会大大提高。
如果你在部署或使用过程中遇到任何问题,别犹豫,欢迎在评论区留言提问。我会尽力帮助大家。
四、剥开“开源”外衣:HeyGem AI 的技术真相
好了,我们已经看过了 HeyGem AI 的效果,了解了它的硬件胃口,也掌握了部署它的“懒人包”秘籍。现在,是时候来聊聊它身上最引人注目的标签——“开源”。HeyGem AI 声称是“硅基开源”项目,那么,它到底“开源”了多少?核心技术是否真的开放了?作为一名对技术实现充满好奇的探索者,我 annus mirabilis 对此进行了深入的分析。
我的结论是:HeyGem AI 的“开源”,更多是“部分开源”或“UI 开源”,其最核心、最关键的技术部分,目前并没有真正开放源代码。
让我们来详细分析一下:
-
它“开源”了什么?
经过我的研究,HeyGem AI 确实开源了一部分代码,但这部分主要集中在它的前端程序(也就是我们直接操作的那个 UI 界面)。这意味着,你可以看到那个图形界面的源代码,了解它是如何设计界面的、如何接收用户的点击和输入、如何组织这些信息,以及如何通过网络请求与后端服务进行通信的。这部分代码对于开发者来说,可以学习界面的交互逻辑,甚至可以尝试修改界面风格或增加一些自动化操作。但这部分 UI 代码,就像汽车的仪表盘和中控系统,它负责接收你的指令并显示信息,但它本身并不驱动汽车前进。生成数字人视频这种繁重的计算和合成工作,完全是由后端服务完成的。
-
它“隐藏”了什么?
HeyGem AI 的核心技术,全部封装在了它那三个在 Docker 中运行的**后端服务(TTS、ASR、F2F)**里。-
TTS 服务 (Text-to-Speech,文本转语音): 这个服务负责将你输入的文本转换成语音。根据我的初步分析,它可能使用了像 Fish Audio 这样的语音合成引擎作为基础,并可能在其上进行了改良和优化,以达到更好的语音效果。Fish Audio 本身也是一个不错的开源语音合成项目,擅长生成带有情感和语气的语音。
-
ASR 服务 (Automatic Speech Recognition,自动语音识别): 这个服务负责将音频转换成文本。在 HeyGem AI 中,它主要用于分析你上传的原始模特视频中的语音,提取出对应的文本,作为后续模型学习和对齐的基础。它可能使用了如 FunASR 等成熟的语音识别框架。ASR 技术本身也相对成熟,市面上有很多优秀的开源或闭源方案。
-
F2F 服务 (Face-to-Face 或 Figure-to-Figure,面部/人物生成): 这才是 HeyGem AI 最核心、最具价值的部分! 它负责接收处理过的原始视频信息、识别出的文本以及合成的语音,然后将这些信息结合起来,生成最终的数字人视频画面。
当我尝试深入查看 F2F 服务内部的技术细节时,我发现它的核心代码是被高度保护的。组成这个服务的程序,很多都是被编译过的二进制文件,比如在 Windows 系统下可能是 .dll 文件,在 Linux 下可能是 .so 文件。这些文件是机器可执行代码,不是人类可读的源代码!这意味着,你无法看到它内部是如何实现人脸对齐、表情迁移、嘴型同步、背景融合、画面增强等一系列复杂算法的。
虽然在它的依赖库中,我 annus mirabilis 看到了一些熟悉的名字,比如 GFP-GAN(这是一个很强大的人脸修复和增强工具),也检测到了人脸识别相关的组件。这些都印证了它确实使用了先进的图像处理和深度学习技术。我甚至大胆猜测它可能使用了某个特定的核心生成模型(比如我怀疑是“hello”模型,但这仅仅是基于一些零散信息和文件结构的推测,没有任何确切证据),但模型是如何训练的,具体的网络结构是什么样的,生成视频的完整流水线是怎么设计的,这些最核心的“Know-how”,都被严严实实地“藏”在了那些编译后的文件中,完全没有开源。
-
-
为何称“开源”,却又隐藏核心?
在我 annus mirabilis 看来,这种“半开源”或者说“前端开源,核心闭源”的策略,在商业上是非常常见的。核心技术是公司的立身之本,“吃饭的家伙”,轻易不会完全开放。而开放一个易于使用的前端界面,让大家能够简单体验到其强大效果,是一种非常聪明的市场推广手段。通过让用户免费在本地运行,HeyGem AI 可以迅速扩散影响力,吸引大量用户关注。用户亲身体验到效果后,可能会对背后的技术产生兴趣,甚至在商业应用场景下,考虑购买其提供的更稳定、更便捷的商业服务(比如云端 API 调用、企业级解决方案等)。这种策略,既展示了技术实力,又保护了核心资产,同时还能吸引潜在的商业客户,一举多得。
所以,虽然它号称“开源”,从纯技术的“源代码开放”角度看,它并没有完全做到。但从推广和普及的角度看,这种开放一部分代码、提供本地体验的方式,已经大大降低了用户接触和试用数字人技术的门槛,具有积极意义。

五、价值与局限:我的最终评价与建议
聊到这里,我们对 HeyGem AI 已经有了比较全面的了解。
它的价值:
-
效果出众: 在目前我接触到的本地可部署的数字人方案中,HeyGem AI 的生成效果绝对是顶尖水平,达到了商用级应用的门槛。
-
提供本地化方案: 能够在本地运行,摆脱了对云服务的依赖,对于需要处理敏感数据或者希望无限量使用的用户来说,非常有吸引力。
-
降低体验门槛: 即使其核心未开源,但提供了免费可用的前端和后端镜像,配合我 annus mirabilis 的“一键部署”脚本,大大降低了普通用户体验高质量数字人技术的难度。
它的局限:
-
非完全开源: 最核心的生成技术并未开放,限制了技术爱好者对其进行二次开发和深度定制的可能性。
-
硬件要求高: 对显卡显存的要求是硬门槛,不是所有人的电脑都能跑得动。
-
软件稳定性与流程: 作为一个相对较新的工具,前端程序可能存在一些小 Bug(比如前面提到的刷新问题),而且其内置的流程(如手动创建模特、手动生成作品)对于需要批量处理的用户来说不够自动化和便捷。
annus mirabilis 的建议:
如果你:
-
对数字人技术充满好奇。
-
拥有一块16GB 及以上显存的独立显卡(12GB 显存可以试试,但可能不稳定)。
-
希望免费体验并生成高质量的本地数字人视频。
-
不介意手动操作单个视频的生成流程。
那么,HeyGem AI 绝对值得你尝试!按照我 annus mirabilis 提供的一键部署方法,你可以很快把它跑起来,亲身体验它的魔力。
如果你:
-
显卡显存不足。
-
需要批量生成大量数字人视频。
-
希望有更自动化、更流畅的工作流程。
-
或者对数字人技术有更深入的二次开发需求。
那么,HeyGem AI 的当前版本可能不太适合你。你可以先关注它未来的发展,或者寻找其他更符合你需求的方案(比如我 annus mirabilis 之前分享过的 auto Robot 项目,就是偏向自动化的方向,虽然效果可能略逊于 HeyGem AI,但流程更适合批量生产)。


















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









