







1、数据类型总体介绍
refer to: https://www.postgresql.org/docs/14/datatype.html
| Name | Aliases | Description |
|---|---|---|
bigint |
int8 |
signed eight-byte integer |
bigserial |
serial8 |
autoincrementing eight-byte integer |
bit [ (*n*) ] |
fixed-length bit string | |
bit varying [ (*n*) ] |
varbit [ (*n*) ] |
variable-length bit string |
boolean |
bool |
logical Boolean (true/false) |
box |
rectangular box on a plane | |
bytea |
binary data (“byte array”) | |
character [ (*n*) ] |
char [ (*n*) ] |
fixed-length character string |
character varying [ (*n*) ] |
varchar [ (*n*) ] |
variable-length character string |
cidr |
IPv4 or IPv6 network address | |
circle |
circle on a plane | |
date |
calendar date (year, month, day) | |
double precision |
float8 |
double precision floating-point number (8 bytes) |
inet |
IPv4 or IPv6 host address | |
integer |
int, int4 |
signed four-byte integer |
interval [ *fields* ] [ (*p*) ] |
time span | |
json |
textual JSON data | |
jsonb |
binary JSON data, decomposed | |
line |
infinite line on a plane | |
lseg |
line segment on a plane | |
macaddr |
MAC (Media Access Control) address | |
macaddr8 |
MAC (Media Access Control) address (EUI-64 format) | |
money |
currency amount | |
numeric [ (*p*, *s*) ] |
decimal [ (*p*, *s*) ] |
exact numeric of selectable precision |
path |
geometric path on a plane | |
pg_lsn |
PostgreSQL Log Sequence Number | |
pg_snapshot |
user-level transaction ID snapshot | |
point |
geometric point on a plane | |
polygon |
closed geometric path on a plane | |
real |
float4 |
single precision floating-point number (4 bytes) |
smallint |
int2 |
signed two-byte integer |
smallserial |
serial2 |
autoincrementing two-byte integer |
serial |
serial4 |
autoincrementing four-byte integer |
text |
variable-length character string | |
time [ (*p*) ] [ without time zone ] |
time of day (no time zone) | |
time [ (*p*) ] with time zone |
timetz |
time of day, including time zone |
timestamp [ (*p*) ] [ without time zone ] |
date and time (no time zone) | |
timestamp [ (*p*) ] with time zone |
timestamptz |
date and time, including time zone |
tsquery |
text search query | |
tsvector |
text search document | |
txid_snapshot |
user-level transaction ID snapshot (deprecated; see pg_snapshot) |
|
uuid |
universally unique identifier | |
xml |
XML data |
2、简单查询
2.1、标识符及关键字、常量的转义
关键字
select word from pg_get_keywords();
为避免一些不必要的麻烦,不要用关键字去定义数据库对象的名字。它会给PG的解析造成潜在的问题。尤其是在生产环境中,不要给自己制造麻烦。
转义
$$或者$tag$, 之间的串不用转义
internals=> select $$fkjdsafjaf'''<xml][['''\\$$;
?column?
---------------------------
fkjdsafjaf'''<xml][['''\\
(1 row)
internals=> select $tag$fkjdsafjaf''''''\\$$;$tag$;
?column?
-----------------------
fkjdsafjaf''''''\\$$;
(1 row)
E前缀,C风格的转义符
mydb=> select E'\tabcd';
?column?
--------------
abcd
位串常量,二进制使用B前缀,16进制采用X作前缀
mydb=> select B'1001'::int;
int4
------
9
mydb=> select X'0B'::int;
int4
------
11
3、简单SQL
3.1、基础SQL
建表
CREATE TABLE table_name ( col_1 data_type, col_2 data_type, … col_n data_type );
CREATE TABLE departments(
department_id integer primary key,
name varchar(50)
);
删表
DROP TABLE [IF EXISTS] name [, name2, ...] [CASCADE];
更改表
see: https://www.postgresql.org/docs/14/sql-altertable.html
ALTER TABLE [IF EXISTS] name {action}
action:
ADD [ COLUMN ] [ IF NOT EXISTS ] column_name data_type
DROP [ COLUMN ] [ IF EXISTS ] column_name [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] column_name [ SET DATA ] TYPE data_type [ COLLATE collation ] [ USING expression ]
ALTER [ COLUMN ] column_name SET DEFAULT expression
ALTER [ COLUMN ] column_name DROP DEFAULT
ALTER [ COLUMN ] column_name { SET | DROP } NOT NULL
ALTER [ COLUMN ] column_name ADD GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( sequence_options ) ]
CLUSTER ON index_name
插入数据
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT }
[, ...] ) | query }
e.g.
INSERT INTO departments (department_id, name)
VALUES (1, 'Development');
-- 插入多行
INSERT INTO emp (empno, ename, job) VALUES
(2,'JOHN', 'MANAGER'),
(3, 'MARY', 'CLERK'),
(4, 'HARRY', 'MANAGER');
see: https://vladmihalcea.com/postgresql-multi-row-insert-rewritebatchedinserts-property/
https://jdbc.postgresql.org/documentation/head/connect.html
very important property: reWriteBatchedInserts = true
SELECT数据
SELECT column_1, column_2 , … column_n
FROM table
WHERE condition
ORDER BY column_list
SELECT department_id, name
FROM departments
WHERE department_id = 1
ORDER BY name;
使用列和表别名(alias)
-
提升复杂SQL语句的可读性
-
减少代码输入
-
<br />e.g.<br />SELECT ename, dname<br />FROM emp e, dept d<br />WHERE e.deptno = d.deptno;<br />
更新数据
UPDATE [ ONLY ] table SET column = {expression | DEFAULT}
[,...]
[ FROM fromlist ]
[ WHERE condition ]
UPDATE departments SET name='DEVELOPMENT'
WHERE department_id=1;
删除数据
DELETE FROM [ ONLY ] table [ WHERE condition ]
DELETE FROM departments WHERE department_id = 2;
TRUNCATE 快速清空表中数据
使用SQL函数
-
可以在 SELECT 语句以及WHERE 中使用
-
• 包括
-
– String Functions
-
– Format Functions
-
– Date & Time Fuctions
-
– Aggregate Functions
例如:
SELECT lower(name) FROM departments;
SELECT * FROM departments WHERE lower(name) = 'development';
4、数据类型(Basic)
PostgreSQL 拥有大量的内置的数据类型用来存储不同类型的数据。
- 标准类型(Standard)
- – Boolean and Logic
- – Strings - char(n), varchar(n), varchar2(n) and text
- – Numbers - integer, floating point, numeric, number
- – Date/time - timestamp(), date, time(), interval(), datetime
- 扩展类型(Extended)
- – Geometric - point, line, box, etc
- – Network - inet, cidr, macaddr
- – Bit - bit, bit varying
- 数组和符合类型(Arrays and Composite types)
- 系统类型(System types)
4.1、Boolean型
Postgres 提供了标准的SQL类型boolean。 boolean 只能有如下两种状态中 的一种: “true” or “false”. 第三种, “unknown”, 可以用SQL null 值表示.
- TRUE, 't', 'true', 'y', 'yes', '1’
- FALSE, 'f', 'false', 'n', 'no', '0’
- 使用关键字 TRUE 和 FALSE 是首选的(它是SQL兼容的( SQL-compliant)).
mydb=> create table t(id int, col2 boolean);
CREATE TABLE
mydb=> insert into t values(1, 't'), (2, FALSE), (3, 'y'), (4, 'no');
INSERT 0 4
mydb=> select * from t;
id | col2
----+------
1 | t
2 | f
3 | t
4 | f
关于NULL值,一个重要的开关:transform_null_equals, 默认值 是false.
mydb=> create table t(id int, col2 boolean);
CREATE TABLE
mydb=> insert into t values(1, 't'), (2, FALSE), (3, 'y'), (4, 'no');
INSERT 0 4
mydb=> select * from t;
id | col2
----+------
1 | t
2 | f
3 | t
4 | f
(4 行记录)
mydb=> set transform_null_equals=true;
SET
mydb=> select * from t where col2=null;
id | col2
----+------
(0 行记录)
mydb=> insert into t values(5, null);
INSERT 0 1
mydb=> select * from t where col2=null;
id | col2
----+------
5 |
(1 行记录)
mydb=> set transform_null_equals=false;
SET
mydb=> select * from t where col2=null;
id | col2
----+------
(0 行记录)
将 transform_null_equals 设置为 on 就会使得 x = NULL 转换为 x IS NULL
a IS DISTINCT FROM b 等价于 a != b,除非 a 或 b 有一个为空,那就返回TRUE。如果a和b 都是 null, 他将返回FALSE. 这将使null的比较变的更简单。
4.2、case when, then, else ,end
mydb=> select id, case when col2 then 'col2 is true' else 'col2 is false' end as col from t;
id | col
----+---------------
1 | col2 is true
2 | col2 is false
3 | col2 is true
4 | col2 is false
5 | col2 is false
(5 行记录)
4.3、nullif与coalesce
coalesce: 取第一个非空值,
NULLIf(a, b)与它相反. 当value1和value2相等时,NULLIF: 如果 a与b相等,返回一个空值。 否则它返回value1。
mydb=> select coalesce(null, null, 'default');
coalesce
----------
default
mydb=> select nullif(2, 1) a, nullif(2, 2) b;
a | b
---+---
2 |
(1 行记录)
4.4、模式匹配:
like 或 , ilike 或 *, escape '\_' , escape '\%' 来限制通配符
mydb=> select 'abc' like 'a%', 'abc' ~~ 'a%';
?column? | ?column?
----------+----------
t | t
mydb=> select 'abc' ilike 'aB%', 'abc' ~~* 'Ab%';
?column? | ?column?
----------+----------
t | t
通配符:_ 相当于 ?, % 相当于 *
mydb=> insert into t123 values(3, 'abc_%dddd', 'abc_%ddef');
INSERT 0 1
mydb=> select * from t123;
id | col2 | col3
----+----------------------------------+-----------
1 | abc | abc
2 | abc | abc
3 | abc_%dddd | abc_%ddef
(3 行记录)
mydb=> select * from t123 where col2 like 'abc\_%' escape '\';
id | col2 | col3
----+----------------------------------+-----------
3 | abc_%dddd | abc_%ddef
(1 行记录)
注意escape的用法. 表示它后边的_是不用作通配的
正则匹配
string ~ regex, ~* : 大小写不敏感, !~, !~*: 不匹配
mydb=> select 'postgres' ~ 'gre';
?column?
----------
t
(1 行记录)
mydb=> select 'postgres' ~ 'gret';
?column?
----------
f
(1 行记录)
mydb=> select 'postgres' ~ 'g[a-z]*';
?column?
----------
t
(1 行记录)
string [NOT] SIMILAR to pattern [ESCAPE escape-character]
与like类似,用的是like方式的模式匹配
mydb=> select 'postgres' similar to '%g%';
?column?
----------
t
4.5、字符串类型
char(n)类型:
mydb=> create table t123(id int, col2 char(32), col3 varchar(32));
CREATE TABLE
mydb=> insert into t123 values(1, 'abc', 'abc'), (2, 'abc ', 'abc ');
INSERT 0 2
mydb=> select * from t123;
id | col2 | col3
----+----------------------------------+------
1 | abc | abc
2 | abc | abc
(2 行记录)
mydb=> select * from t123 where col2='abc';
id | col2 | col3
----+----------------------------------+------
1 | abc | abc
2 | abc | abc
(2 行记录)
mydb=> select * from t123 where col2='abc ';
id | col2 | col3
----+----------------------------------+------
1 | abc | abc
2 | abc | abc
(2 行记录)
拼接,最大最小值
mydb=> select 'a' || 'b', greatest('a', 'b', 'c'), least('a', 'b', 'c');
?column? | greatest | least
----------+----------+-------
ab | c | a
(1 行记录)
大小写及各种长度:
octet_length:字节数, bit_length:位数, char_length, character_length: 相同,都是字符数
mydb=> select upper('a'), lower('ABC'), length('ABC'), character_length('ABC'), char_length('ABC'), octet_length('ABC'), bit_length('ABC');
-[ RECORD 1 ]----+----
upper | A
lower | abc
length | 3
character_length | 3
char_length | 3
octet_length | 3
bit_length | 24
pad填充: lpad, rpad(string, length[, fill])
mydb=> select lpad('abc', 8, 'd'), rpad('abc', 8, 'xy');
lpad | rpad
----------+----------
dddddabc | abcxyxyx
trim: ltrim, rtrim, btrim(string[, characters])
删除字符串左边或右边或两边的characters字符 (默认是空格)
mydb=> select ltrim('abc','a'), rtrim('abc', 'bc'), btrim(' abcba ', ' ');
ltrim | rtrim | btrim
-------+-------+-------
bc | a | abcba
(1 行记录)
position函数: position(substring in string), 对比strpos
mydb=> select position('b' in 'abc');
position
----------
2
(1 行记录)
mydb=> select strpos('abc', 'b');
strpos
--------
2
(1 行记录)
substring函数:
-
substring(string [ from start][ for run])
-
substring(string from pattern)
-
substring(string from pattern for escape)
-
substr(string, from, count)
mydb=> sELECT substring('EnterpriseDB' from 8 for 5);
substring
-----------
iseDB
mydb=> sELECT substring('EnterpriseDB' from 8 );
substring
-----------
iseDB
4.6、数值型
Integers:
– int/integer/int4, smallint/int2, bigint/int8
– bigint 依赖于编译器的支持,因此不一定能在所有的平台上运行。
– bigint, int2, int4 and int8 是 Postgres扩展
Serial:
可以定义列 NOT NULL, serial, biserial, serial4, serial8
mydb=> create table t12(id bigserial, id2 serial, id3 serial8, col2 varchar(32));
CREATE TABLE
mydb=> \d t12
数据表 "public.t12"
栏位 | 类型 | 校对规则 | 可空的 | 预设
------+-----------------------+----------+----------+----------------------------------
id | bigint | | not null | nextval('t12_id_seq'::regclass)
id2 | integer | | not null | nextval('t12_id2_seq'::regclass)
id3 | bigint | | not null | nextval('t12_id3_seq'::regclass)
col2 | character varying(32) | | |
mydb=> insert into t12 (col2) values('abc'), ('abcd');
INSERT 0 2
mydb=> select * from t12;
id | id2 | id3 | col2
----+-----+-----+------
1 | 1 | 1 | abc
2 | 2 | 2 | abcd
CREATE TABLE s(s serial);
NOTICE: CREATE TABLE will create implicit sequence "s_s_seq" for serial
column "s.s"
\d s
...
s | integer | not null default nextval('s_s_seq'::regclass)
Floating Point
– real, double precision
– 它依赖于编译器,CPU, 和 OS 支持, 在不同的安装中细节会有不同
– real 通常有 6 位精度,范围至少在 1E-37 和 1E+37之间
– double通常有 15 位精度,范围至少在 1E-307 和 1E+308之间
– 特殊值 : Infinity, -Infinity, NaN
– SQL 标准表示法 float(p) 用于声明一个的数值类型,它以P(二进 制位表示的最低可接受精度,在7.4以前,P是一个十进制的位)。 P取值在1到24之间表示一个real的精度,在25到53之间表示 double的精度。如果有其他值将会返回错误。
– 如果没有定义float的precision,等价于 double的precision
Numeric
– 允许是任意 precision (所有位的个数) 和 scale (小数位数)
– 可以存储多达1000位的数值,但非常慢
– numeric(p, s) 定义了最大的 precision (须 > 0) 和最大的 scale (须 >= 0)
– numeric(p)是一个scale为0的 numeric
– 如果在numeric中没有定义任何的 precision 或者 scale,那他将允 许存储任意precision 和 scale的数值。这种形式不会将输入数值强 制转化成任何特定精度的值
– 如果一个要存储的数值的scale比声明的scale大, 那么系统将尝试 四舍五入该数值到指定的scale。如果小数点左边的数据位数超过 了声明的precision减去scale , 那么抛出一个错误。
– 数据在物理存储时其前后不带任何的0
– 允许 NaN
mydb=> create table t1(s numeric, col2 numeric(6,2));
CREATE TABLE
mydb=> insert into t1 values(487394743789748975979878979.1234155, 1234.12);
INSERT 0 1
mydb=> select * from t1;
s | col2
-------------------------------------+---------
487394743789748975979878979.1234155 | 1234.12
(1 行记录)
mydb=> insert into t1 values(134145, 143325.11);
ERROR: numeric field overflow
描述: A field with precision 6, scale 2 must round to an absolute value less than 10^4.
数值类型操作符
• +, -, *, /, % (also mod()), ^ (also power())
• |/ (prefix) square root (also sqrt()) 平方根
• ||/ (prefix) cube root (also cbrt()) 立方根
• ! (suffix), ! – factorial 阶乘
• @ (prefix) - absolute value (also abs()) 绝对值
mydb=> SELECT |/ 25, 5 !, @ -5;
?column? | ?column? | ?column?
----------+----------+----------
5 | 120 | 5
mydb=# select ||/125, |/625, @ -5, 2^3;
?column? | ?column? | ?column? | ?column?
----------+----------+----------+----------
5 | 25 | 5 | 8
(1 row)
数值函数
• ceil/ceiling, floor
• exp (exponential), ln, log
• greatest, least
• random, setseed
• round, truncate
• sign
• to_number
• degrees(radians), radians(degrees)
• cos, acos, sin, asin
• cot (cotangent), tan, atan
• atan2(x, y) = atan(x/y)
4.7、序列函数
• nextval() – 输出 sequence的下一个值
• currval() -输出 sequence的当前值
• setval() –设置 sequence将要输出的下一个值
mydb=> create table t(id serial);
CREATE TABLE
mydb=> select currval('t_id_seq');
ERROR: currval of sequence "t_id_seq" is not yet defined in this session
mydb=> select nextval('t_id_seq');
nextval
---------
1
mydb=> select setval('t_id_seq', 10);
setval
--------
10
(1 行记录)
mydb=> select nextval('t_id_seq');
nextval
---------
11
(1 行记录)
mydb=> select currval('t_id_seq');
currval
---------
11
4.8、日期/时间类型
日期/时间类型是最常用的几种数据类型之一,除包括不同日期/时间范围和精度的类 型外,还包括了时间间隔类型。
4.8.1、日期/时间类型介绍
1)、日期/时间类型列表

image-20221211094548320
需要注意的是,PostgreSQL中的时间类型可以精确到秒以下,而MySQL中的时间类 型只能精确到秒。time、timestamp、interval接受一个可选的精度值p以指明秒域中小数部 分的位数。如果没有明确的默认精度,对于timestamp和interval类型,p的取值范围是0~6 。
timestamp数值是以双精度浮点数的方式存储的,它以2000-01-01午夜之前或之后的秒 数存储。可以想象,在2000-01-01前后几年的日期中精度是可以达到微秒的,而在更远一 些的日子,精度可能达不到微秒,但达到毫秒是没有问题的。
也可以改变编译选项使timestamp以八字节整数的方式存储,那么微秒的精度就可以 在数值的全部范围内得到保证,不过这样一来八位整数的时间戳范围就缩小到了4713 BC 到294276 AD之间。此外,这个编译选项也决定了time和interval数值是保存成浮点数还是 八字节整数。同样,在以浮点数存储的时候,随着时间间隔的增加,interval数值的精度 也会降低。
4.8.2、日期的输入
在SQL中,任何日期或者时间的文本输入都需要由“日期/时间”类型加单引号括起来 的字符串组成,语法如下:
type [ (p) ] 'value'
日期和时间的输入几乎可以是任何合理的格式,包括ISO-8601格式、SQL-兼容格式 、传统的Postgres格式及其他形式。对于一些格式,日期输入中的月和日可能会使人产生 疑惑,因此系统支持自定义这些字段的顺序。如果DateStyle参数默认为“MDY”,则表示 按“月-日-年”的格式进行解析,如果参数设置为“DMY”,则按照“日-月-年”的格式进行解 析,设置为,“YMD”表示按照“年-月-日”的格式进行解析。示例如下:
internals=> create table tdate(col1 date);
CREATE TABLE
internals=> insert into tdate values(date '12-10-2010');
INSERT 0 1
internals=> select * from tdate;
col1
------------
2010-12-10
(1 row)
internals=> show datestyle;
DateStyle
-----------
ISO, MDY
(1 row)
internals=> set datestyle='YMD';
SET
internals=> insert into tdate values(date '2010-12-11');
INSERT 0 1
internals=> select * from tdate;
col1
------------
2010-12-10
2010-12-11
(2 rows)
更多的日期输入示例:
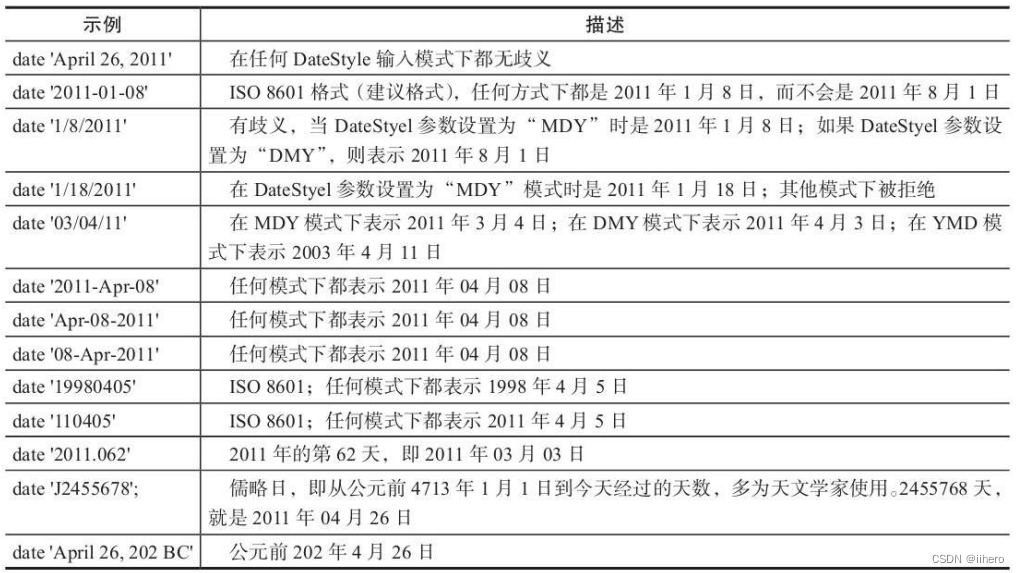
image-20221211094958978
对于中国人来说,使用“/”作为时间和日期分隔符容易产生歧义,最好使用“-”,然后 以“年-月-日”的格式输入日期。
4.8.3、时间输入
输入时间时需要注意时区的输入。time被认为是time without time zone的类型,这样 即使字符串中有时区也会被怱略,示例如下:
internals=> select time '04:05:06';
time
----------
04:05:06
(1 row)
internals=> select time '04:05:06 PST';
time
----------
04:05:06
(1 row)
internals=> select time with time zone'04:05:06 PST';
timetz
-------------
04:05:06-08
(1 row)
时间字符串可以使用冒号作分隔符,即输入格式为“hh:mm:ss”,如“10:23:45”,也可 以不用分隔符,如“102345”表示10点23分45秒。
更多的时间类型的输入示例:
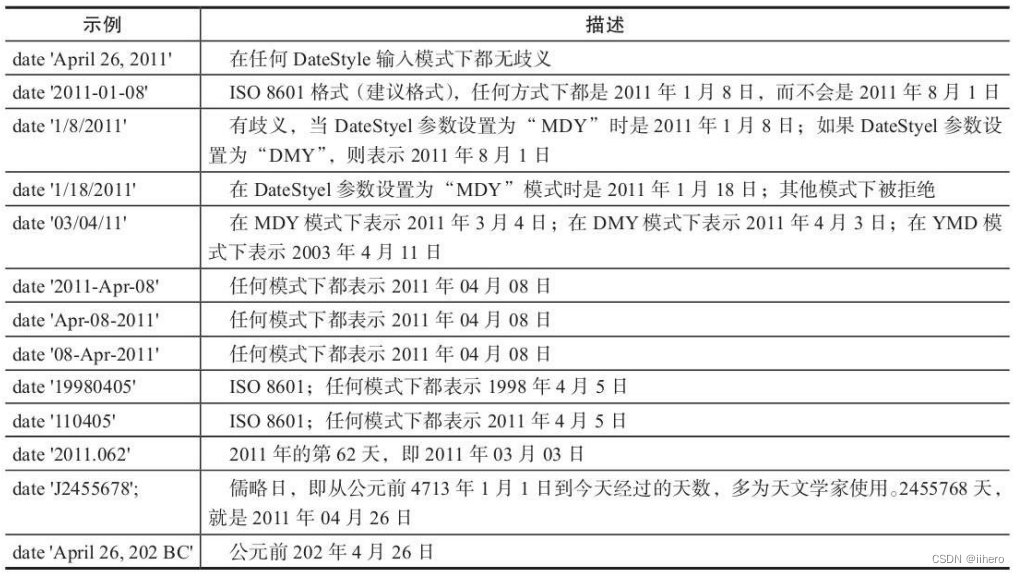
image-20221211095145522
最好不要用时区缩写来表示时区,因为这样有可能给阅读者带来困扰,如CST 时间有可能有以下几种含义:
- Central Standard Time (USA) UT-6:00,即美国标准时间
- Central Standard Time (Australia) UT+9:30,即澳大利亚标准时间。
- China Standard Time UT+8:00,即中国标准时间。
- Cuba Standard Time UT-4:00,即古巴标准时间。
这么多的时区都叫CST,是不是让人困惑?CST在PostgreSQL中代表Central Standard Time (USA) UT-6:00,缩写可以查询视图“pg_timezone_abbrevs”:
internals=> select * from pg_timezone_abbrevs where abbrev='CST';
abbrev | utc_offset | is_dst
--------+------------+--------
CST | -06:00:00 | f
(1 row)
在输入的时间后加“AT TIME ZONE”可以转换或指定时区:
internals=> SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40-05' AT TIME ZONE '+08:00';
timezone
---------------------
2001-02-16 17:38:40
(1 row)
4.8.4、特殊值
为方便起见,PostgreSQL中用了一些特殊的字符串输入值表示特定的意义。
日期时间输入的特殊值

image-20221211095401371
4.8.5、函数和操作符列表
日期、时间和inteval类型数值之间可以进行加减乘除运算,具体见表
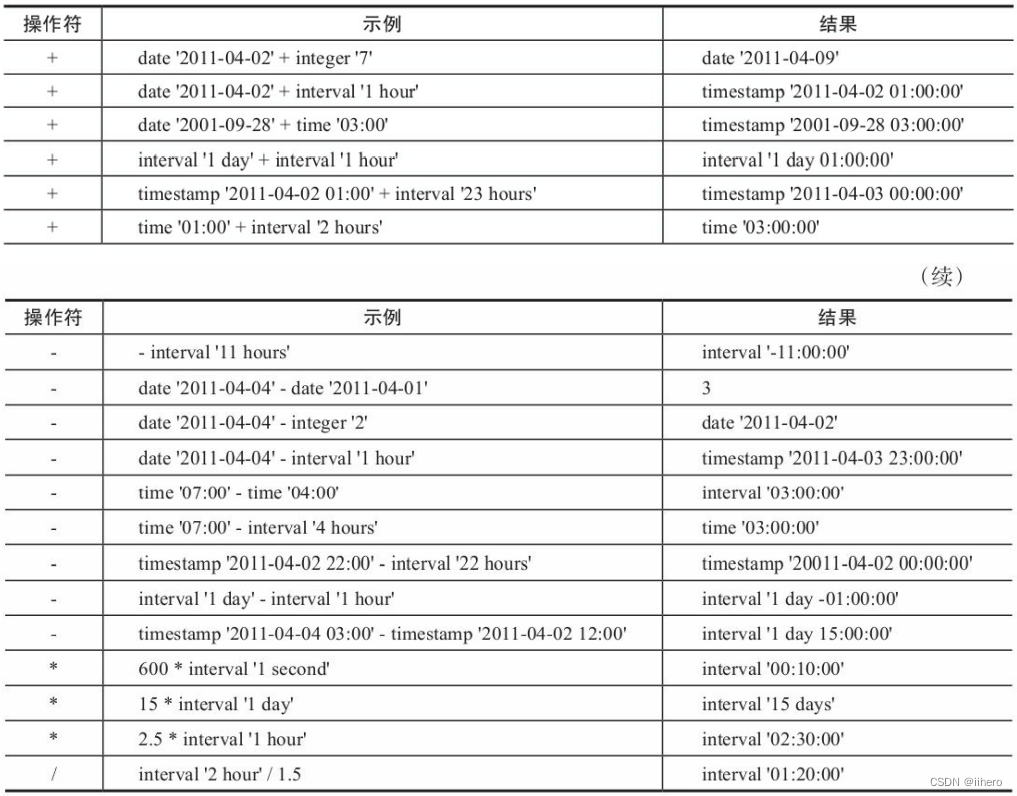
image-20221211095445429
日期、时间和inteval类型的函数见后表。
除了以上函数以外,PostgreSQL还支持SQL的OVERLAPS操作符,如下:
(start1, end1) OVERLAPS (start2, end2)
(start1, length1) OVERLAPS (start2, length2)
上面的表达式在两个时间域(用它们的终点定义)重叠的时候生成真值。终点可以用 一对日期、时间、时间戳来声明;或者是后面跟着一个表示时间间隔的日期、时间、时间 戳,示例如下:
internals=> SELECT (DATE'2001-02-16',DATE'2001-12-21') OVERLAPS (DATE'2001-10-30',DATE'2002-10-30');
overlaps
----------
t
(1 row)
internals=> SELECT (DATE'2001-02-16',INTERVAL'100days') OVERLAPS (DATE'20 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9274
9274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











