







Contents
1. 杨辉三角和转置矩阵
1.1. 杨辉三角
1.1.1. 构建方式
杨辉三角,又称为Pascal’s Triangle (,即帕斯卡三角,以法国著名的数学家、哲学家Blaise Pascal命名的)。
要构建这个三角,需要在第一层和第二层放上数字1(这三个数字构建为正三角形的形状),从第三层往后,两边放上数字1,其余的数字是上一层相对应的两个数字的和。每一层都与此前的层构成正三角形。具体如下所示:
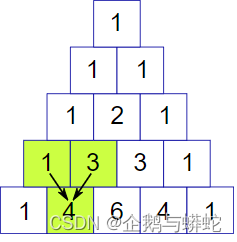
1.1.2. 对称性
杨辉三角是左右对称的,左边的数与右边的数相对称,形成镜像的感觉。具体如下图所示:

1.1.3. 每一层的数字之和是2的幂数
每一层的数字之和,是2的幂数,比如第一层,是2的0次幂;第二层是2的1次幂;第三层是2的2次幂;第四层是2的3次幂,依此类推。
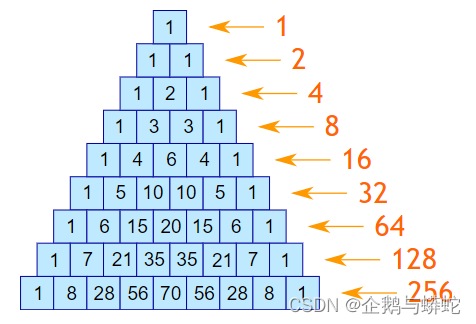
关于杨辉三角的更多特性,参见Pascals Triangle以及杨辉三角。
1.2. 转置矩阵
矩阵转置是指将矩阵沿着对角线进行翻转,使得原矩阵的行和列互换,即原来的行,转置之后编程新矩阵的列;原矩阵的列,转置之后变成新矩阵的行。
原矩阵右上角的符号T,表示对该矩阵进行转置操作。比如矩阵A进行转置操作,可标记为AT。
在下面的示例中,原矩阵第1行第三列的数字24,在转置之后变成第1列第3行。

对转置矩阵再进行转置,则得到最初的矩阵。即将矩阵A转置所得到的转置矩阵再进行转置操作,得到矩阵就是矩阵A自身。具体如下所示:

2. 说明list和set的异同之处
2.1. 关于list和set
list类型对象是任意对象的有序集合,可以通过索引和分片访问列表中的项目。列表为可变类型,支持就地修改。
set类型对象既不是键值映射类型的对象,也不是顺序存储类型的对象。set类型对象以无序的方式存储唯一且不可变类型的对象。且不支持索引、分片或者其他类似的顺序操作。虽然set类型对象中存储的是唯一且不可变的其他类型对象,但是set对象本身是可变的,支持就地修改操作。
2.2. list和set的相同点
两者都是可变类型对象,支持就地修改操作。
2.3. list和set的差异
list类型对象采用顺序存储的方式存储任意类型的对象;set类型对象不是顺序存储,且其中只能存储唯一且不可变类型对象。list类型对象支持索引、分片访问等顺序操作;set类型对象不支持按位置索引、分片等顺序访问操作。list类型对象中存储的数据可以重复;set类型对象中存储的数据不能重复,要求在set对象中保持唯一。
3. 列出set支持的所有方法
set类型支持17个方法函数,具体如下所示:
-
set.add:该方法用于向set类型对象中加入新的项目,如果在set中已经存在了该项目,则没有效果。该方法的使用示例如下所示:
In [523]: s Out[523]: {'a', 'b'} In [524]: s.add('c') In [525]: s Out[525]: {'a', 'b', 'c'} In [526]: s.add('a') In [527]: s Out[527]: {'a', 'b', 'c'} -
set.clear:该方法用于从set类型对象中移除其中的所有项目。该方法的使用效果如下所示:
In [527]: s Out[527]: {'a', 'b', 'c'} In [528]: s.clear() In [529]: s Out[529]: set() -
set.copy:该方法使用浅拷贝的方式复制set类型对象该方法的使用效果如下所示:
In [532]: s = set(('a', 'b')) In [533]: s Out[533]: {'a', 'b'} In [534]: s1 = s.copy() In [535]: s1 Out[535]: {'a', 'b'} -
set.difference:该方法用于返回两个set类型对象之间的差异。该方法的使用效果如下所示:
In [538]: s1.add('c') In [539]: s1 Out[539]: {'a', 'b', 'c'} In [540]: s Out[540]: {'a', 'b'} In [541]: s.difference(s1) Out[541]: set() In [544]: s1.difference(s) Out[544]: {'c'}该方法的逻辑是:调用该方法的
set类型对象s中的项目只需要被包含在作为参数对比的s1中即可,即s这里有的,但是s1那里没有的项目,才会列出来;至于s这里没有,s1那里有的,并不会列出来。这就是541条命令返回空的set类型对象的原因所在。同样的,当使用s1调用该方法的时候,则表示s1中有的项目,但是在s中没有的,才会作为差异的部分被列出来。这就是第544条命令列出包含’c’字符的原因。
-
set.difference_update:该方法表示从调用该方法的set对象中移除作为对比的set对象中相同的项目,只保留调用该方法的set对象中差异的部分。该方法的使用效果如下所示:
In [546]: s1 Out[546]: {'a', 'b', 'c'} In [547]: s Out[547]: {'a', 'b'} In [548]: s1.difference_update(s) In [549]: s1 Out[549]: {'c'} In [550]: s Out[550]: {'a', 'b'} -
set.discard:该方法用于从set类型对象中删除指定的项目。如果该项目不存在,则不做处理。该方法的执行效果如下所示:
In [554]: s Out[554]: {'a', 'b'} In [555]: s.discard('a') In [556]: s Out[556]: {'b'} In [557]: s.discard('c') In [558]: s Out[558]: {'b'} -
set.intersection:该方法返回两个set类型对象的交集。该方法的效果如下所示:
In [560]: s Out[560]: {'b'} In [561]: s1 Out[561]: {'c'} In [562]: s.add('a') In [563]: s1.add('a') In [564]: s Out[564]: {'a', 'b'} In [565]: s1 Out[565]: {'a', 'c'} In [566]: s.intersection(s1) Out[566]: {'a'} -
set.intersection_update:使用两个set类型对象的交集更新调用该方法的set类型对象。该方法的使用效果如下所示:
In [568]: s Out[568]: {'a', 'b'} In [569]: s1 Out[569]: {'a', 'c'} In [570]: s.intersection_update(s1) In [571]: s Out[571]: {'a'} In [572]: s1 Out[572]: {'a', 'c'} -
set.isdisjoint:该方法用于判断两个set类型对象是否含有交集,如果彼此没有交集,则返回True,否则返回False。该方法的使用效果如下所示:
In [574]: s Out[574]: {'a'} In [575]: s1 Out[575]: {'a', 'c'} In [576]: s.add('b') In [577]: s Out[577]: {'a', 'b'} In [578]: s.isdisjoint(s1) Out[578]: False In [579]: s.discard('a') In [580]: s Out[580]: {'b'} In [581]: s1 Out[581]: {'a', 'c'} In [582]: s.isdisjoint(s1) Out[582]: True -
set.issubset:用于判断嗲用该方法的set类型对象是否包含在另一个set类型对象中。如果是,则返回True,否则返回False。该方法的执行效果如下所示:
In [584]: s Out[584]: {'b'} In [585]: s1 Out[585]: {'a', 'c'} In [586]: s.issubset(s1) Out[586]: False In [587]: s2 = {'a',} In [588]: s2.issubset(s1) Out[588]: True -
set.issuperset:用于判断调用该方法的set类型对象是否完全包含了作为参数的另一个set类型对象。该方法的执行效果如下所示:
In [591]: s1 Out[591]: {'a', 'c'} In [592]: s2 Out[592]: {'a'} In [593]: s1.issuperset(s2) Out[593]: True In [594]: s2.add('b') In [595]: s2 Out[595]: {'a', 'b'} In [596]: s1.issuperset(s2) Out[596]: False -
set.pop:从set类型对象中随机移除一个项目,并且返回该项目。如果该对象为空,则抛出KeyError异常。该方法的执行效果如下所示:
In [601]: s1 Out[601]: {'a', 'c'} In [602]: s1.pop() Out[602]: 'c' In [603]: s1 Out[603]: {'a'} -
set.remove:从set类型对象中移除指定的项目,该项目必须存在。如果指定的要移除的项目不存在,则抛出KeyError异常。该方法的使用效果如下所示:
In [605]: s1 Out[605]: {'a'} In [606]: s1.remove('b') --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-606-9c50d6044346> in <module> ----> 1 s1.remove('b') KeyError: 'b' In [607]: s1.remove('a') In [608]: s1 Out[608]: set() -
set.symmetric_difference:从对比的两个set类型对象中返回两者共同包含之外的项目。该方法的执行效果如下所示:
In [610]: s1 = {'a', 'b', 'c'} In [611]: s2 = {'a', 'c'} In [612]: s2.symmetric_difference(s1) Out[612]: {'b'} In [613]: s1 Out[613]: {'a', 'b', 'c'} In [614]: s2 Out[614]: {'a', 'c'} In [615]: s1.symmetric_difference(s2) Out[615]: {'b'} In [616]: s2.add('d') In [617]: s2 Out[617]: {'a', 'c', 'd'} In [618]: s1.symmetric_difference(s2) Out[618]: {'b', 'd'} In [619]: s2.symmetric_difference(s1) Out[619]: {'b', 'd'} -
set.symmetric_difference_update:使用对比的两个set类型对象之间共有部分之外的部分,更新调用该方法的set类型对象。该方法的执行效果如下所示:
In [621]: s1 Out[621]: {'a', 'b', 'c'} In [622]: s2 Out[622]: {'a', 'c', 'd'} In [623]: s1.symmetric_difference_update(s2) In [624]: s1 Out[624]: {'b', 'd'} In [625]: s2 Out[625]: {'a', 'c', 'd'} -
set.union:返回两个set类型对象的合集,这个合集中包含了两个set类型对象中的所有项目。该方法的执行效果如下所示:
In [627]: s1 Out[627]: {'b', 'd'} In [628]: s2 Out[628]: {'a', 'c', 'd'} In [629]: s1.union(s2) Out[629]: {'a', 'b', 'c', 'd'} -
set.update:使用两个set类型对象的合集更新调用该方法的set类型对象。该方法的使用效果如下所示:
In [631]: s1 Out[631]: {'b', 'd'} In [632]: s2 Out[632]: {'a', 'c', 'd'} In [633]: s1.update(s2) In [634]: s1 Out[634]: {'a', 'b', 'c', 'd'}
4. 列出dict支持的所有方法
4.1. dict类型对象初始化的方法
dict类型的集中初始化方法如下所示:
-
键值对参数调用的方式创建
dict类型对象:dict(one=1, two=2, three=3)。注意,这种方式在python解释器中可以正常使用,但是在ipython中则无法使用。具体如下所示:
-
在iPython中使用的效果如下所示:
In [646]: dict(one=1, two=2, three=3) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-646-0e9868018104> in <module> ----> 1 dict(one=1, two=2, three=3) TypeError: 'dict' object is not callable提示
dict类型不是可调用类型。 -
在命令行中直接调用Python的效果如下所示:
>>> a = dict(one=1, two=2, three=3) >>> a {'one': 1, 'two': 2, 'three': 3}
-
-
采用花括号的方式创建
dict类型对象:b = {'one': 1, 'two': 2, 'three': 3}。这种方式在两种命令行中都可以正常使用。 -
采用小括号的形式传递键值对给
dict类:c = dict([('two', 2), ('one', 1), ('three', 3)])。这种方式在iPython中同样无法生效,但是在命令行中调用的python命令则可以生效。具体如下所示:
-
在iPython中的效果如下所示:
In [649]: c = dict([('two', 2), ('one', 1), ('three', 3)]) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-649-a3af7b252f4f> in <module> ----> 1 c = dict([('two', 2), ('one', 1), ('three', 3)]) TypeError: 'dict' object is not callable上述提示
dict不是可调用类型。 -
在命令行中调用python命令的执行效果如下所示:
>>> c = dict([('two', 2), ('one', 1), ('three', 3)]) >>> c {'two': 2, 'one': 1, 'three': 3}
-
-
与上一种方式类似,但是分别将key和value括在两组小括号中,使用zip生成(key, value)对:
d = dict(zip(['one', 'two', 'three'], [1, 2, 3]))。这种方式同样在iPython中无法执行,在命令行调用的python命令中可以执行。具体如下所示:
-
在iPython中的执行效果如下所示:
In [650]: d = dict(zip(['one', 'two', 'three'], [1, 2, 3])) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-650-91f9d9ee1a65> in <module> ----> 1 d = dict(zip(['one', 'two', 'three'], [1, 2, 3])) TypeError: 'dict' object is not callable -
在命令行中调用python命令的效果如下所示:
>>> d = dict(zip(['one', 'two', 'three'], [1, 2, 3])) >>> d {'one': 1, 'two': 2, 'three': 3}
-
-
将花括号定义的字典作为参数传递给
dict类:e = dict({'three': 3, 'one': 1, 'two': 2})。这种方式在iPython中无法应用;但是在命令行中调用的python命令中可以应用。具体如下所示:
-
iPython中的执行效果如下所示:
In [651]: e = dict({'three': 3, 'one': 1, 'two': 2}) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-651-6b7f00ba0a6c> in <module> ----> 1 e = dict({'three': 3, 'one': 1, 'two': 2}) TypeError: 'dict' object is not callable -
在命令行中调用python命令的效果如下所示:
>>> e = dict({'three': 3, 'one': 1, 'two': 2}) >>> e {'three': 3, 'one': 1, 'two': 2}
-
上述是初始化dict类型对象的几种方式。在iPython中只支持第二种方式,在命令行中调用python命令的时候,则全部支持。
4.2. dict类型对象支持的内建方法
dict类型对象共支持11中内建方法。具体如下所示:
-
dict.clear:从dict类型对象中移除其中的所有项目。该方法的使用效果如下所示:
In [657]: d = {'one': 1, 'two': 2, 'three': 3} In [658]: d Out[658]: {'one': 1, 'two': 2, 'three': 3} In [659]: d.clear() In [660]: d Out[660]: {} In [661]: type(d) Out[661]: dict -
dict.copy:使用浅拷贝的方式复制dict类型对象。该方法的使用效果如下所示:
In [664]: d = {'one': 1, 'two': 2, 'three': 3} In [665]: d1 = d.copy() In [666]: d1 Out[666]: {'one': 1, 'two': 2, 'three': 3} -
dict.fromkeys:使用指定的参数作为key创建dict类型对象。该方法的帮助信息如下所示:
fromkeys(iterable, value=None, /)method of builtins.type instance
Create a new dictionary with keys from iterable and values set to value.该方法的使用效果如下所示:
In [668]: t = tuple('string') In [669]: t Out[669]: ('s', 't', 'r', 'i', 'n', 'g') In [670]: d2 = dict.fromkeys(t, value=None) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-670-13fa4e0f6b11> in <module> ----> 1 d2 = dict.fromkeys(t, value=None) TypeError: fromkeys() takes no keyword arguments In [671]: d2 = dict.fromkeys(t) In [672]: d2 Out[672]: {'s': None, 't': None, 'r': None, 'i': None, 'n': None, 'g': None} In [673]: d3 = dict.fromkeys(t, 2) In [674]: d3 Out[674]: {'s': 2, 't': 2, 'r': 2, 'i': 2, 'n': 2, 'g': 2} In [675]: d3 = dict.fromkeys(t, (2,3,4,5,6,7)) In [676]: d3 Out[676]: {'s': (2, 3, 4, 5, 6, 7), 't': (2, 3, 4, 5, 6, 7), 'r': (2, 3, 4, 5, 6, 7), 'i': (2, 3, 4, 5, 6, 7), 'n': (2, 3, 4, 5, 6, 7), 'g': (2, 3, 4, 5, 6, 7)}该方法不支持关键字方式传递参数。该方法的value部分只支持1个值,且所有key都被赋予相同的value。
-
dict.get:该方法用于从dict类型对象中返回key对应的值。如果指定的key不存在,则返回default参数的值。该方法的帮助信息如下所示:
get(key, default=None, /)method of builtins.dict instance
Return the value for key if key is in the dictionary, else default.该方法的使用示例如下所示:
In [679]: d1 Out[679]: {'one': 1, 'two': 2, 'three': 3} In [680]: d1.get('one') Out[680]: 1 In [681]: d1.get('four', default=4) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-681-00197d6c74c9> in <module> ----> 1 d1.get('four', default=4) TypeError: get() takes no keyword arguments In [682]: d1.get('four', 4) Out[682]: 4同样,该方法函数不支持关键字形式的参数传递。
-
dict.items:返回对象形式的dict结果。该方法的使用效果如下所示:
In [685]: d1 Out[685]: {'one': 1, 'two': 2, 'three': 3} In [686]: d1.items() Out[686]: dict_items([('one', 1), ('two', 2), ('three', 3)]) -
dict.keys:返回dict类型对象的key。该方法的使用效果如下所示:
In [688]: d1 Out[688]: {'one': 1, 'two': 2, 'three': 3} In [689]: d1.keys() Out[689]: dict_keys(['one', 'two', 'three']) In [690]: type(d1.keys()) Out[690]: dict_keys In [691]: list(d1.keys()) Out[691]: ['one', 'two', 'three'] -
dict.pop:从dict类型对象中删除指定的key并返回其value。如果key不存在,同时制定了默认值,则返回默认值;否则抛出KeyError异常。该方法的帮助信息如下所示:
pop(…) method of builtins.dict instance
D.pop(k[,d])-> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised该方法的使用效果如下所示:
In [693]: d1 Out[693]: {'one': 1, 'two': 2, 'three': 3} In [694]: d1.pop('one') Out[694]: 1 In [695]: d1.pop('four', 4) Out[695]: 4 In [696]: d1.pop('four') --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-696-e14c9ca20006> in <module> ----> 1 d1.pop('four') KeyError: 'four' -
dict.popitem:从dict类型对象中随机移除并且返回(key, value)键值对,如果dict类型对象为空,则抛出KeyError异常。该方法的帮助信息如下所示:
popitem(…) method of builtins.dict instance
D.popitem()-> (k, v), remove and return some (key, value) pair as a
2-tuple; but raise KeyError if D is empty.该方法的使用效果如下所示:
In [698]: d1 Out[698]: {'two': 2, 'three': 3} In [699]: d1.popitem() Out[699]: ('three', 3) In [700]: d1 Out[700]: {'two': 2} -
dict.setdefault:如果指定的key在dict类型对象中不存在,则将key加入到该对象中,并且使用default指定的值作为key的值。如果该key存在,则返回key对应的值。该方法的帮助信息如下所示:
setdefault(key, default=None, /)method of builtins.dict instance
Insert key with a value of default if key is not in the dictionary.Return the value for key if key is in the dictionary, else default.
该方法的使用效果如下所示:
In [702]: d1 Out[702]: {'two': 2} In [703]: d1.setdefault('one', 1) Out[703]: 1 In [704]: d1 Out[704]: {'two': 2, 'one': 1} In [705]: d1.setdefault('two', 3) Out[705]: 2 In [706]: d1 Out[706]: {'two': 2, 'one': 1} -
dict.update:使用dict类型对象或者可迭代对象更新调用该方法的dict类型对象。如果E是dict类型,则D[k] = E[k];如果E是可迭代类型,且k, v包含在E中,则D[k] = v;对于其他情况,对于k包含在F中的情况,则D[k] = F[k]。该方法的帮助信息如下所示:
update(…) method of builtins.dict instance
D.update([E, ]**F)-> None. Update D from dict/iterable E and F.
If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]该方法的使用效果如下所示:
In [712]: d1 Out[712]: {'two': 2, 'one': 1} In [713]: d1.update(one=3, two=5) In [714]: d1 Out[714]: {'two': 5, 'one': 3} In [715]: d1.update(one=3, two=5, three=7) In [716]: d1 Out[716]: {'two': 5, 'one': 3, 'three': 7} In [716]: d1 Out[716]: {'two': 5, 'one': 3, 'three': 7} In [717]: d2 Out[717]: {'s': None, 't': None, 'r': None, 'i': None, 'n': None, 'g': None} In [718]: d1.update(**d2) In [719]: d1 Out[719]: {'two': 5, 'one': 3, 'three': 7, 's': None, 't': None, 'r': None, 'i': None, 'n': None, 'g': None} In [720]: -
dict.values:以对象的形式返回dict类型对象中的values。该方法的使用效果如下所示:
In [720]: d1 Out[720]: {'two': 5, 'one': 3, 'three': 7, 's': None, 't': None, 'r': None, 'i': None, 'n': None, 'g': None} In [721]: d1.values() Out[721]: dict_values([5, 3, 7, None, None, None, None, None, None]) In [722]: type(d1.values()) Out[722]: dict_values In [723]: list(d1.values()) Out[723]: [5, 3, 7, None, None, None, None, None, None]
5. 列出Python的内建函数
-
abs(x):如果x是整数或者浮点数,则返回x的绝对值;如果x是复数,则返回x的模(即实部与虚部平方和的根)。 -
all(iterable):如果iterable中的所有项目都是True,则这个函数最终返回True;否则其中有一个项目不为True,则返回False。 -
any(iterable):iterable中的任意一个项目为True,则这个函数就返回True;只有当所有项目都为False的时候,才返回False。 -
ascii(object):返回一个包含可打印对象的字符串,效果类似于repr()函数。 -
bin(x):将十进制数转换为0b开头的二进制字符串,结果是有效的Python表达式。 -
class bool([x]):返回布尔值,即True或者False中的一个。如果x为False,则返回False;否则返回True。 -
breakpoint(*args, **kws):这个函数会调用sys.breakpointhook()函数(接受任意位置参数以及关键字参数),默认情况下,sys.breakpointhook()函数调用pdb.set_trace()函数(不接受任何参数)。另外,也可以将sys.breakpointhook()函数设置为其他函数,此时breakpoint()函数也会自动调用该函数,从而实现选择调试器的目的。 -
class bytearray([source[, encoding[, errors]]]):返回字节array,bytearray类是可变类型的有序整数集合,范围在[0-256]。它支持绝大部分顺序存储的可变类型支持的方法。其中
source的取值有以下几种可能:- 当source取值为字符串的时候,需要同步给出encoding的值,随后bytearray将字符串使用encoding函数转换为字节字符串;
- 当source取值为整数的时候,此时表示bytearray的大小为source的值,同时用Null值进行初始化;
- 当source取值为遵循buffer接口的对象的时候,使用对象的只读buffer初始化bytearray;
- 当source取值为可迭代类型的时候,那么迭代类型中的项目必须是[0-256]范围区间的整数。
如果不指定任何参数,则bytearray的大小为0。
-
class bytes([source[, encoding[, errors]]]):返回一个不可变的字节对象,其中有序存储[0-256]范围内的整数。 -
callable(object):如果object是可调用的,则返回True,否则返回False。True表示object可以像函数一样被调用;False表示object不可以进行函数式调用。 -
chr(i):返回Unicode编码所对应整数的字符,如果要实现逆向操作,则可以调用ord()函数。 -
@classmethod:用于将函数转换为类的方法函数。类方法接收类作为其第一个隐式参数,就像实例方法就收实例作为其隐式的第一个参数一样。 -
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1):将source编译为AST对象,编码对象可以通过exec()以及eval()调用执行。source可以是正常的字符串、字节字符串、或者AST对象。filename参数应该指明包含代码的文件路径以及文件名。
mode参数应该指明将代码编译为何种形式。支持的形式包括:
exec,当source中包含顺序执行的语句的时候;eval,如果source中包含单个表达式的时候;single,如果source中包含了单个可交互语句的时候。flags以及dont_inherit参数为可选参数,用于指定未来可能对source编译有影响的特性。
optimize参数编译器的优化级别,默认值为-1,表示选择解释器的
-O选项中指定的优化级别;显式级别0,表示不进行优化;1表示移除assert语句;2表示移除docstring。 -
class complex([real[, imag]]):返回复数,即real + imag*1j的形式,或者将字符串或者数字转换为复数。如果第一个参数式字符串,那么它会被解释为复数,此时不能指定第二个参数。第二个参数永远不能是字符串。 -
delattr(object, name):相对于setattr()方法,要求两个参数,其中第一个为对象,第二个为字符串,字符串必须是对象中的属性名。这个函数会从对象中删除name所指定的属性。比如delattr(x, 'foobar')等效于del x.foobar。 -
class dict(**kwarg)|class dict(mapping, **kwarg)|class dict(iterable, **kwarg):表示创建新的字典。 -
dir([object ]):如果不带任何参数,表示返回当前局部作用域中的名字列表,如果带一个参数,则表示返回该对象的属性列表。 -
divmod(a, b):a, b是两个数字,不能是复数。这个函数返回一对数字,第一个数字为商(a//b),第二个数字为余数(a%b)。 -
enumerate(iterable, start=0):返回一个枚举类型对象,iterable要求为顺序类型、迭代器或者其他支持迭代操作的对象。 -
eval(expression[, globals[, locals]]):expression要求是字符串,globals以及locals这两个参数可以省略,如果提供了,globals必须是字典,locals可以是任意的map类型的对象。expression会被解释器解析为Python表达式,使用globals以及locals这两个字典用于约束表达式的计算名称空间。 -
exec(object[, globals[, locals]]):这个函数支持动态执行Python代码,object必须是字符串或者code对象。如果时字符串,那么需要能够被解析为Python语句,以便随后解释器执行该语句。另外,需要注意return语句以及yield语句是不能在函数定义范围之外工作的,所以即便是在exec的上下文环境中,也不要使用这两个语句。 -
filter(function, iterable):从iterable包含的项目中构建迭代器,以便function可以返回True。iterable可以是顺序类型、支持迭代操作的对象或者是迭代器。如果function是None,就表示会移除iterable中所有为False的项目。注意:当function不为None的时候,filter(function, iterable)等效于生成器表达式(item for item in iterable if function(item));如果function是None,则等效于(item for item in iterable if item)。 -
class float([x]):表示从x返回浮点数,其中x可以是数字,也可以是字符串。支持的符号包括如下图所示:

-
format(value[, format_spec]):将value使用格式化表达式打印。关于格式化表达式的规范,参见formatspec。 -
class frozenset([iterable]):使用iterable构建新的frozenset对象,其为不可变类型。 -
getattr(object, name[, default]):返回object的命名属性值,name参数必须是字符串,如果name是object的属性,这个函数的结果就是该属性的属性值。 -
globals():返回当前全局范围的符号表构成的字典,且总是当前模块的字典。 -
hasattr(object, name):这个函数带两个参数,一个对象,一个字符串,如果name是object的属性,则该函数返回True,否则返回False。 -
hash(object):返回object的哈希值,哈希值是整数,用于在字典查询的时候,快速比较字典的key。相等的数字具有相同的哈希值(即便一个是整数,一个是浮点数,它们的哈希值也是相同的,比如1和1.0的哈希值是相同的)。 -
help([object]):交互式调用内建的帮助系统,如果不指定任何参数,则打印解释器的标准帮助信息的同时进去交互式help接口。 -
hex(x):表示将整数转换为带0x前缀的十六进制数组成的字符串。 -
id(object):返回对象的ID,在对象的生命周期中,这个ID表示的整数是恒定的且独一无二的。两个生命周期不重叠的对象可能具有相同的ID。 -
input([prompt]):如果prompt存在,会被写入到标准输出中,并且不会自动换行。该函数从标准输入读取用户输入的内容,并将其转换为字符串(截取掉换行符),并返回该字符串。 -
class int([x])|class int(x, base=10):返回从x构建的整数对象。其中x既可以是数字,也可以是字符串。如果不指定任何参数,则返回0。base值默认为10,表示将x转换为10进制数;允许的取值为0,2,8,16。其中0意味着将x解释为代码字面意思,所以实际的用于数制转换的取值为2,8,10,16这四个。
-
isinstance(object, classinfo):如果object是classinfo的实例对象或者子类,则返回True。如果object不是给定类型的实例对象,则返回False。 -
issubclass(class, classinfo):如果class是classinfo的子类,则返回True。一个类可以被认为是自身的子类。其中classinfo可以是类对象的元组,此时其中的每个项目都会被检查。 -
iter(object[, sentinel]):返回一个迭代器对象,第一个对象如何被解释,取决于第二个参数sentinel(哨兵)。如果没有第二个参数sentinel,那么object必须是支持迭代协议(定义了__iter__()方法)的对象的集合,亦或者支持顺序协议(定义了__getitem__()方法)。如果object不支持这两种协议,就会抛出TypeError异常。
如果存在第二个参数sentinel,那么object必须是可调用对象。在这种情况下创建的迭代器会在每次调用
__next__()方法的时候,采用无参数传递的方式调用object。如果返回的值等于sentinel,就会抛出StopIteration异常,否则返回这个值。 -
len(s):返回s的长度,即s中包含了多少个项目。s可以是顺序类型(比如string、bytes、tuple、list或者range)或者是集合类型(比如dict,set,forzenset)等。 -
class list([iterable]):用于创建列表实例对象。 -
locals():更新并且返回表示当前局部符号表的字典。注意,在模块级别,locals()与globals()实际是相同的字典。 -
map(function, iterable, ...):返回一个迭代器,这个迭代器会将function应用到iterable中的每个项目上,并且产出结果。如果给这个函数传递了额外的iterable,那么此时就要求function支持传递多个参数,并且可以并行的处理多个iterable。对于存在多个iterable的情况,function会在处理完最短的一个iterable之后就停止。 -
max(iterable, *[, key, default])|max(arg1, arg2, *args[, key]):从iterable的各个项目中返回最大的一个。或者是两个或者多个参数中最大的那个。如果提供了一个位置参数,那么这个位置参数必须是可迭代类型。最终这个函数将会返回这个可迭代类型中最大的那个项目。如果给定了两个或者多个位置参数,将返回最大的那个位置参数。另外还有两个可选的只能以关键字方式提供的参数,key和default。其中key参数指定一个只能处理一个参数的函数用于排序,比如
list.sort()函数。default参数用于指定当iterable为空的时候,返回的默认值。 -
class memoryview(obj):从给定的参数obj中创建一个memory view对象。 -
min(iterable, *[, key, default])|min(arg1, arg2, *args[, key]):从iterable中返回其中最小的一个项目,或者从多个位置参数中返回最小的那个参数。参数的含义与max函数一致。 -
next(iterator[, default]):通过调用__next__()函数从迭代器中返回iterable中下一个项目。如果给定了default参数,那么在迭代器遍历完成之后,返回该默认值。否则抛出StopIteration异常。 -
class object:返回一个新特性类,object是所有类的基类。其中包含了所有其他类实例对象所需要的通用方法。 -
oct(x):将x转换为以0o开头的八进制字符串,这个结果是有效的Python表达式。如果x不是int对象,那么就需要其中定义并且实现__index__()方法用于返回整数。 -
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None):用于打开文件,并且返回相关的文件对象。如果无法打开file,则抛出OSError异常。file是类似路径的对象,其中给出了file的文件名和路径,或者封装的文件整数描述符。
mode是可选参数,为字符串,用以指定文件的打开模式。默认是
'r',表示以读取的方式打开;其他常用的值还包括:'w',表示以写入的方式打开(如果文件已经存在,则会清空文件并且写入本次的内容);'x',表示排他创建;'a',表示追加。在文本模式下,如果encoding参数没有指定,那么编码方式取决于程序运行的平台。可以调用locale.getpreferredencoding(False)查看当前平台的当前编码方式。其他mode支持的取值如下图所示:
 buffer参数是可选的,用于设置buffer策略的整数。当该值为0的时候,表示关闭buffer(只允许应用在二进制模式下);当该值为1时,表示行缓存(只适用于文本模式);当值大于1的时候,表示指定固定字节数的缓存块。当不给顶该参数的时候,默认的缓存策略如下所示:
buffer参数是可选的,用于设置buffer策略的整数。当该值为0的时候,表示关闭buffer(只允许应用在二进制模式下);当该值为1时,表示行缓存(只适用于文本模式);当值大于1的时候,表示指定固定字节数的缓存块。当不给顶该参数的时候,默认的缓存策略如下所示:
-
二进制文件被缓存在固定大小的缓存块中;缓存大小是通过启发式,根据设备的块大小(block size)以及
io.DEFAULT_BUFFER_SIZE确定下来的。在很多系统上,这个缓存块大小为4096或者8192字节。 -
交互式文本文件使用行缓存模式,其他文件则使用上一条描述的二进制文件的缓存策略。
encoding参数是个字符串,表示编码或者解码文件所用的方法。通常只用在文本模式中,默认的编码方式取决于程序运行的平台,可以通过调用locale.getpreferredencoding()查看当前支持的默认编码方法。
errors参数是一个可选的字符串参数,用于指定如何编码或者解码错误信息,无法应用在二进制模式中。有多种标准错误处理句柄可用,因为只要是在codecs.register_error()中注册过的句柄,都是有效的。支持的标准名字如下:
'strict',表示编码错误的时候,抛出ValueError异常。默认值None具有相同的效果。'ignore',忽略错误。注意:忽略编码错误可能会导致数据丢失。'replace',使用替换标记(比如?)插入到数据异常的地方。'surrogateescape',将任意的不正确的字节呈现为Unicode Private Use Area的范围从U+DC80到U+DCFF的编码点。'xmlcharrefreplace',只有当写入到文件的时候才支持。编码方法不支持的字符会被替换为合适的XML字符引用&#nnn;。'backslashreplace',使用Python的转义序列替换不正确的字符。'namereplace',使用\N{...}转义序列替换不支持的字符。
newline参数,用于可控制通用换行符的工作模式(只能被应用在文本模式下),支持的值包括None,' ','\n','\r'以及'\rn'。其工作方式如下:
- 当从标准输入流中读取内容的时候,如果该参数为None,就使能了通用换行模式,此时输入流中的多个行之间可以用
'\n','\r'或者'\rn'进行分隔,在将输入流的内容返回给函数调用之前都会将这些换行符统一替换为'\n'。 - 当将内容写入到标准输出流的时候,如果该参数为None,那么
'\n'会被自动翻译为系统支持的换行符(可以通过os.linesep进行查看)。如果换行符是' '或者'\n',那么就不会有替换操作发生。如果换行符是其他合法字符,那么'\n'会被翻译为指定的字符。
closefd参数,如果该参数为False,且文件描述符不是指定的文件名,那么当文件被关闭的时候,潜在的文件描述符会保持打开的状态。如果filename参数给定了,那么该参数必须为True,否则会发生错误。
opener参数,用于指定自定义的文件打开器,文件对象的潜在描述符通过调用带(file, flags)这两个参数的opener打开,opener必须返回一个打开的文件描述符。
-
ord(c):对于一个给定的Unicode字符,大引其对应的Unicode编码。比如ord('a')返回整数97。 -
pow(base, exp[, mod]):返回base的exp次幂的值,如果mod参数存在,同时计算对mod的模,这种取模的方式比pow(base, exp) % mod的方式效率更高。这三个参数都必须是数字类型。 -
print(*objects, sep=’ ’, end=’\n’, file=sys.stdout, flush=False):用于将object打印到文本流文件中,sep参数制定了文件内容的分隔符,end参数指定了文件的行结束符。另外sep, end, file, flush这几个参数如果存在,那么必须以关键字参数的形式传递才可以。 -
class property(fget=None, fset=None, fdel=None, doc=None):返回property属性,fget适用于提取属性值的函数;fset是用于设置属性值的函数;fdel适用于删除属性值的函数;doc用于给属性创建docstring字符串。 -
class range(stop)|class range(start, stop[, step]):range实际是一个不可变类型的顺序存储对象。 -
repr(object):返回一个包含对象的可打印表达的字符串。对于很多类型来说,这个函数只是尝试返回一个类似于eval处理过的对象产生的结果一样的字符串。否则会使用花括号将包含对象类型和名字的字符串括起来。 -
reversed(seq):返回一个反转的迭代器,参数seq必须是实现了__reversed__()方法的对象,或者支持顺序协议(实现了__len__()方法以及__getitem__()方法)。 -
round(number[, ndigits]):按照ndigits的范围对number进行四舍五入计算,如果ndigits未指定,或者为None,那么返回距number最近的整数。 -
class set([iterable]):返回一个新的集合对象,集合的项目从iterable中获得。 -
setattr(object, name, value):对立于getattr()函数,三个参数必须分别是对象、字符串以及任意值。name必须是字符串,表示object中存在的属性。这个函数用于将value代表的属性值分配给object对象的name属性。 -
class slice(stop)|class slice(start, stop[, step]):返回一个range(start, stop, step)指定范围的切片。 -
sorted(iterable, *, key=None, reverse=False):从iterable中的项目中返回一个新的排序后的列表。其中key参数用于指定对iteralbe中的各个项目进行排序的函数(比如key=str.lower),默认值是None。
reverse参数是布尔值,如果设置为True,则表示将排序结果极性反转。
-
@staticmethod:将方法函数转换为静态方法。静态方法不接受隐式的第一个参数,这一点不同于类方法。 -
class str(object=”)|class str(object=b”, encoding=’utf-8’, errors=’strict’):返回str版本的object字符串对象。 -
sum(iterable, /, start=0):将start于iterable中的各个项目相加在一起。iterable中的值应该是数字,且start不允许是字符串。 -
super([type[, object-or-type]]):用于授权一个类的父类中的方法调用。对于访问继承的方法是很有用的。 -
class tuple([iterable]):使用iterable中的项目创建元组。 -
class type(object)|class type(name, bases, dict):当带一个参数的时候,返回这个参数的类型;当带三个参数的时候,返回一个新的type类型对象。 -
vars([object]):为带有__dict__属性的模块、类、实例对象或者其他对象返回一个__dict__属性。 -
zip(*iterables):将每个iterable中的项目分组一一聚合在一起。 -
copyright:返回Python的版权信息 -
credits:返回致谢信息 -
license:返回许可信息
6. References
[1]. Pascals Triangle
[2]. 杨辉三角
[3]. Builtin Functions















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









