






dict字典
dict全称dictionary,使用键-值(key-value)存储,具有极快的查找速度,类似perl里面哈希hash字典的创建
字典的每个创建key=>value对用冒号:分割, 每个键值对之间用逗号,分割,整个字典包括在花括号{}中,格式如下:dict={'a':1,'b':2,'b':3}print(dict)#{'a': 1, 'b': 3}字典的特性:
1、 键必须不可变,所以可以用 数字,字符串或元组充当,所以 用列表就不行(列表是可变类型)2、值可以没有限制地取任何Python对象,既可以是标准的对象,也可以是用户定义的。d={'Name':'Zara','Age':7,'Name':'Manni'}print(d)#{'Name': 'Manni', 'Age': 7}d={(22,"ss"):"ss"}print(d)#{(22, 'ss'): 'ss'}修改字典
向字典中添加新内容的方法是增加新的键/值对,修改或删除已有的键/值对
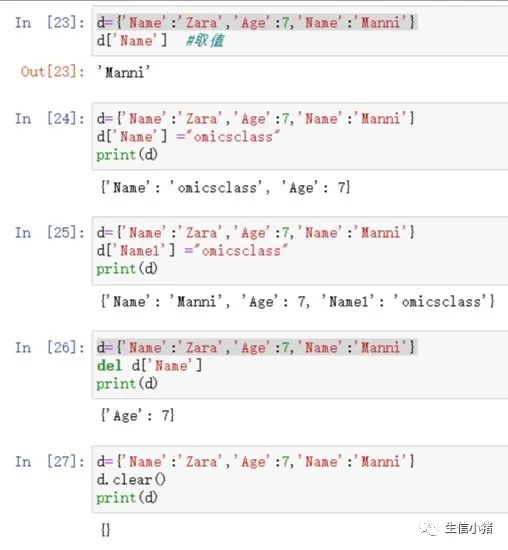

判读字典key是否存在
#使用格式#key in dict#key not in dictd={'Name':'Zara','Age':7,'Name':'Manni'}'Name' in d'Name' not in d集合
set集合
set集合是一个无序的不重复元素序列,是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。集合创建
可以使用大括号{}或者set()函数创建集合。注意:创建一个空集合必须用set()而不是{},因为{}是用来创建一个空字典。集合的创建与运算
set('omicsclass')#{'a', 'c', 'i', 'l', 'm', 'o', 's'}'omicsclass'[0:4]#'omic'genes={'gene1','gene1','gene2','gene3','gene4','gene5'}print(genes)#{'gene3', 'gene2', 'gene4', 'gene5', 'gene1'}genes=set(['gene1','gene1','gene2','gene3','gene4','gene5']) #将列表准换成集合print(genes)#{'gene3', 'gene2', 'gene4', 'gene5', 'gene1'}#集合的运算与判断genes=set(['gene1','gene1','gene2','gene3','gene4','gene5'])'gene1' in genes#True#字符有列表特征,所以可以直接seta=set('omicsgene')b=set('omicsclass')#集合a中包含而集合b中不包含的元素a=set('omicsgene')b=set('omicsclass')a-b#{'e', 'g', 'n'}#集合a或b中包含的所有元素a=set('omicsgene')b=set('omicsclass')a|b#{'a', 'c', 'e', 'g', 'i', 'l', 'm', 'n', 'o', 's'}#集合a和b中都包含了的元素a=set('omicsgene')b=set('omicsclass')a&b#{'c', 'i', 'm', 'o', 's'}#不同时包含于a和b的元素a=set('omicsgene')b=set('omicsclass')a^b#{'a', 'e', 'g', 'l', 'n'}集合常用操作方法

basket={'apple','orange','apple','pear','orange','banana'}basket.add(("aa","dd"))print(basket)#{'pear', ('aa', 'dd'), 'orange', 'banana', 'apple'}basket={'apple','orange','apple','pear','orange','banana'}basket.update(("aa","dd"))print(basket)#{'pear', 'aa', 'orange', 'dd', 'banana', 'apple'}basket={'apple','orange','apple','pear','orange','banana'}basket.update("dd")print(basket)#{'pear', 'd', 'orange', 'banana', 'apple'}basket={'apple','orange','apple','pear','orange','banana'}basket.remove("apple")print(basket)#{'banana', 'orange', 'pear'}basket={'apple','orange','apple','pear','orange','banana'}basket.discard("apple")print(basket)#{'banana', 'orange', 'pear'}basket={'apple','orange','apple','pear','orange','banana'}basket.clear()print(basket)#set()
#批量赋值a,b,c,d,e=20,5.5,"ATCGG",True,4+3j#获得数据类型print(type(a),type(b),type(c),type(d),type(e))#a=1isinstance(a,int) #a是否是整数#True类型转换函数
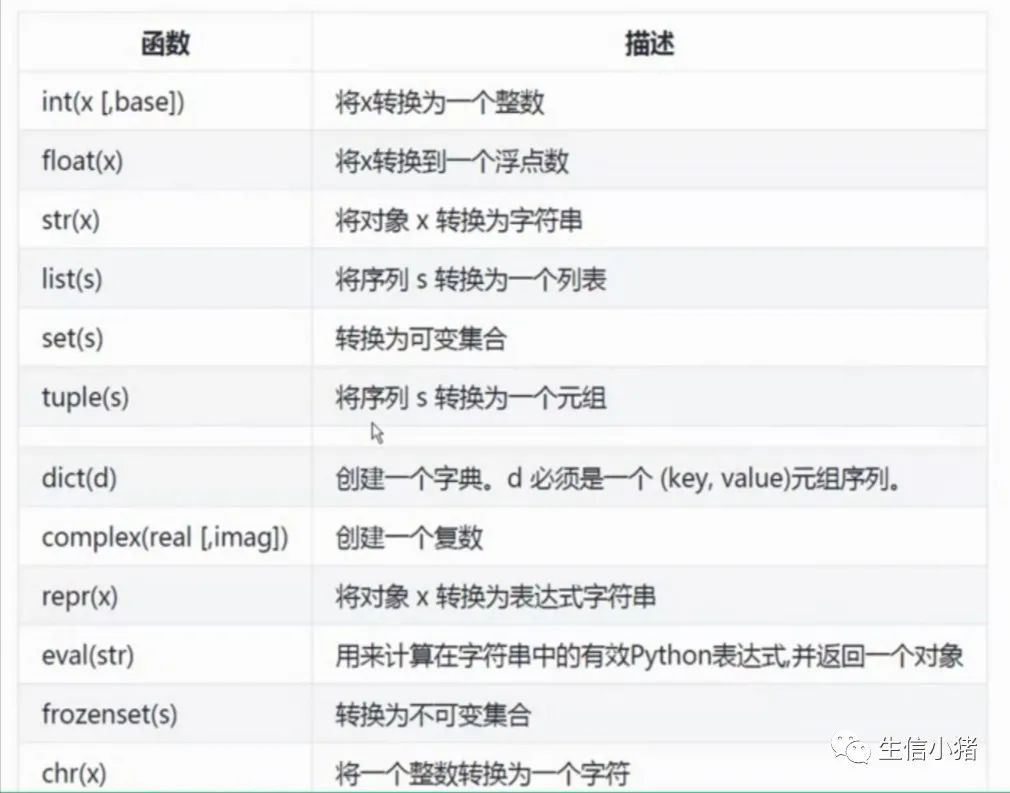
python中语句(if、for、while)
if语句做判断计算机之所以能够做很多自动化的任务,因为它可以自己做条件判断python中常见比较判断运算符
==、!=、、>=、<=、in、not in
注意:in、not in:判断是否存在列表中或者字典的键中
#简单的判断age=20if age >= 18: print('your age is',age) print('adult')else: print(False) print("not adult")#your age is 20#adultA=['Fast','Smooth','fast','isa','isb','smooth']s={'gene1','gene1','gene2','gene3','gene4','gene5'}d={'gene1':122,'gene2':2212,'gene3':3121,'gene4':2323,'gene5':2543}A=['Fast','Smooth','fast','isa','isb','smooth']var='Fast'if var not in A: print(True)else: print(False)#False#in只会判断字典的键,不会判断字典的值d={'gene1':122,'gene2':2212,'gene3':3121,'gene4':2323,'gene5':2543}var=122if var in d: print(True)else: print(False)#Falsed={'gene1':122,'gene2':2212,'gene3':3121,'gene4':2323,'gene5':2543}var=122if var in d.values(): print(True)else: print(False)#Trued={'gene1':122,'gene2':2212,'gene3':3121,'gene4':2323,'gene5':2543}var=122if var not in d.values(): print(True)else: print(False)#Falseage=3if age >= 18: print('adult')elif age >= 6: print('teenager')else: print('kid')#kid逻辑运算符 增加判断条件
与、或、非:and、or、not
1、and如果第一个表达式为False,后面没有必要计算2、or如果第一个表达式True,后面就没有必要计算了3、条件很多不知道判断优先顺序可以添加小括号#逻辑运算符age=20gender="male"if age>=18 and age<=60 and gender=="female": print("adult woman")if age<18 and age>60 and gender=="female": print("kid or old woman")if age>=18 and age<=60 and not gender=="female": print("adult man")#adult man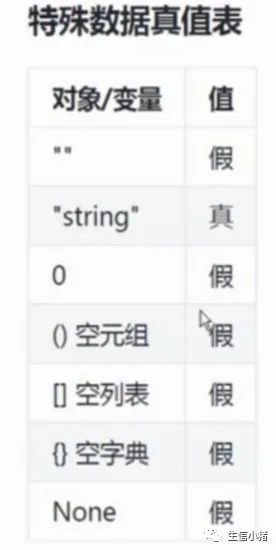
var=""if var: print(True)else: print(False)#Falsevar="daf"if var: print(True)else: print(False)#Truevar={}if var: print(True)else: print(False)#Falsefor循环语句
计算机之所以能批量的执行数据分析,就是因为有循环语句。for...in循环,in后面跟可迭代对象#列表遍历names=['Michael','Bob','Tracy']for name in names: print(name)#Michael#Bob#Tracysum=0for x in [1,2,3,4,5,6,7,8,9,10]: sum=sum+xprint(sum)#55for x in [1,2,3,4,5,6,7,8,9,10]: print(sum) sum=sum+xprint(sum)#55#56#58#61#65#70#76#83#91#100#110#产生连续的数字函数:range(start,stop[,step])range(10)#range(0, 10)range(2,10)#range(2, 10)#也可以转换成list对象list(range(10))#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]list(range(1,11))#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]list(range(0,30,5))#[0, 5, 10, 15, 20, 25]sum=0for x in range(101): sum=sum+xprint(sum)#5050#enumerate函数,同时获取索引还有值#用法enumerate(sequence,[start=0])names=['Michael','Bob','Tracy']for index,value in enumerate(names): print(index,value)#0 Michael#1 Bob#2 Tracy#字典遍历dict={'Name':'Zara','Age':7,'Class':'First'}for k,v in dict.items(): print(k,v)#Name Zara#Age 7#Class Firstdict={'Name':'Zara','Age':7,'Class':'First'}for k in dict.keys(): print(k,dict[k])#Name Zara#Age 7#Class Firstwhile循环
while循环,只要条件满足,就不断循环,条件不满足时退出循环sum=0n=99while n>0: sum=sum+n n=n-2print(sum)#2500循环控制语句
break提前退出循环 continue提前结束本轮循环n=1while n<=100: if n>10: #当n=11时,条件满足,执行break语句 break #break语句会结束当前循环 print(n) n=n+1print('END')#1#2#3#4#5#6#7#8#9#10#ENDn = 0while n < 10: n += 1 if n % 2 == 0:#如果n是偶数,执行continues语句 continue #continue语句会直接继续下一轮循环,后续的print()语句不会执行 print(n)#1#3#5#7#9for 循环打印金字塔
for i in range(1,6): for j in range(0,6-i): print("",end="") print("*"*(i),end="") print("*"*(i-1),end="") print("")打印乘法口诀
for m in range(1,10): for n in range(1,m+1): print("%d*%d=%d\t"%(n,m,n+m),end="") print("")













 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









