






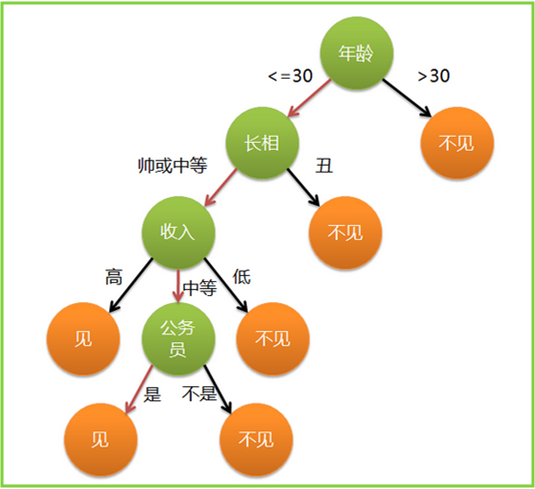
定义
决策树(decision tree)是一个树结构,决策树由节点和有向边组成。
节点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出。
决策树学习过程
决策树学习的本质是从训练数据集上归纳出一组分类规则,通常采用启发式的方法:局部最优。
具体做法就是,每次选择feature时,都挑选当前条件下最优的那个feature作为划分规则,即局部最优的feature。
决策树学习通常分为3 个步骤:特征选择、决策树生成和决策树的修剪。
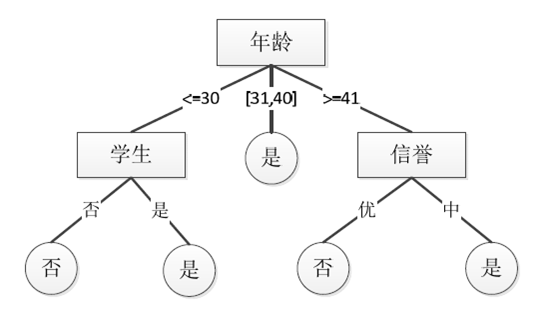
特征选择
选择特征的标准是找出局部最优的特征 ,判断一个特征对于当前数据集的分类效果。也就是按照这个特征进行分类后,数据集是否更加有序(不同分类的数据被尽量分开)。
衡量节点数据集合的有序性(纯度)有:
熵

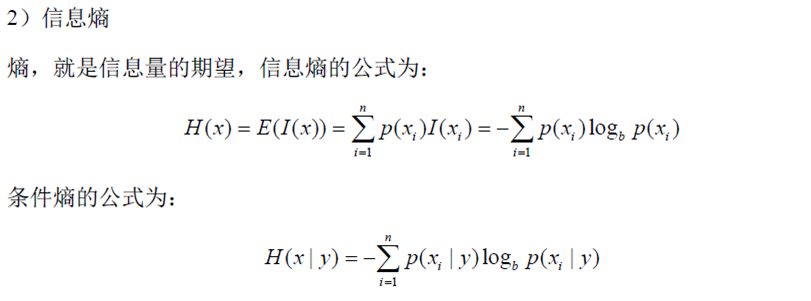


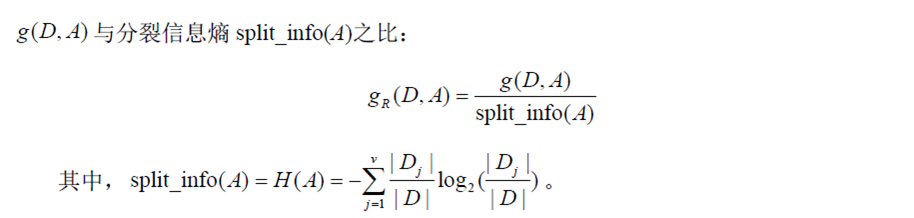
ID3算法



决策树生成实例


C4.5算法
C4.5是机器学习中的一种分类决策算法,是对ID3算法的改进。那么首先来介绍一下ID3算法,id3根据信息增益,运用自顶向下的贪心策略建立决策树。信息增益用于度量某个属性对样本集合分类的好坏程度。
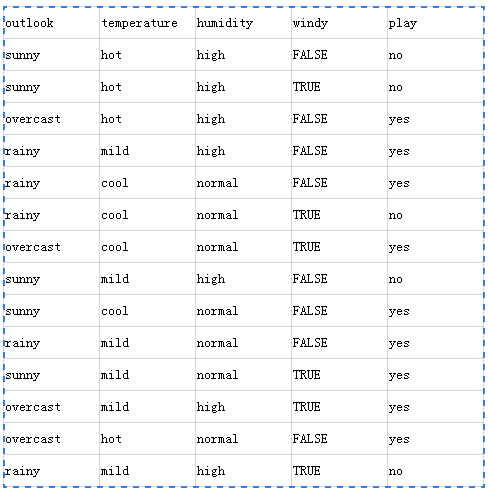
下面通过ID3作者论文中的例子来对ID3进行阐述。我们统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。如果给出新一天的气象指标数据:sunny,cool,high,TRUE,判断一下会不会去打球。
信息熵:(数据越均匀,信息熵越大,则越不好进行决策,因为我们不知道那种情况发生的概率大些)
熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,…,An),每部分发生的概率是(p1,p2,…,pn),那信息熵定义为:
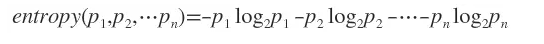
信息增益:
信息增益=所有信息熵减去某一属性的信息熵
根椐上述数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为(利用上述公式)0.94。(全部信息熵)
假设上述数据中outlook是确定的:
outlook=sunny时,2/5的概率打球,3/5的概率不打球。然后通过计算可得entropy=0.971
outlook=overcast时,entropy=0
outlook=rainy时,entropy=0.971
而根据历史统计数据,outlook取值为sunny、overcast、rainy的概率分别是5/14、4/14、5/14,所以当已知变量outlook的值时,信息熵为:5/14 × 0.971 + 4/14 × 0 + 5/14 × 0.971 = 0.693
那么我们可以得到outlook的信息增益为:0.971-0.693=0.247
同理,我们可以得到temperature的信息增益为:0.029,humidity的为0.152,windy的为0.048
然后我们可以知道outlook的信息增益最大(也就是说outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。
接下来我们按照上述步骤在(temperature,humidity,windy)挑出信息增益最大的项,依次迭代,构造出决策数。当系统的信息熵降为0时,就没有必要再往下构造决策树了,此时叶子节点都是纯的–这是理想情况。(属性的信息增益决定了属性所在的决策层数,信息增益愈大,那么它的决策在最上层)
ID3算法有个缺点:总是倾向于有大量值的值信进行上层决策(这有非常不合理)。
针对这一缺点,C4.5的作者提出了信息增益率这一概念。(如两个人跑步一个起始速度为10m/s,10s后速度为20m/s,而另一个人起始速度为1m/s,10s后他的速度为2m/s,实际上他们的加速度是一样的。加速度也就如信息增益率一样),从而兼顾了所有的属性,而不是倾向于数量多的属性。
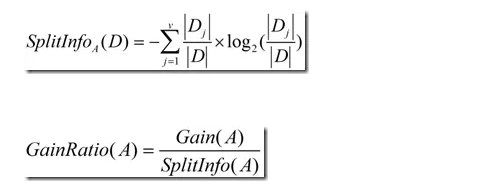
(信息增益率)
C4.5算法的缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
sparkmllib源码分析


DecisionTree伴生对象
def train(input: RDD[LabeledPoint], strategy: Strategy): DecisionTreeModel = {
new DecisionTree(strategy).run(input)
}
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int): DecisionTreeModel = {
val strategy = new Strategy(algo, impurity, maxDepth)
new DecisionTree(strategy).run(input)
}
。。。。。。
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int],
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel = {
val impurityType = Impurities.fromString(impurity)
train(input, Classification, impurityType, maxDepth, numClasses, maxBins, Sort,
categoricalFeaturesInfo)
}
。。。。。。。。。。。
def run(input: RDD[LabeledPoint]): DecisionTreeModel = {
val rf = new RandomForest(strategy, numTrees = 1, featureSubsetStrategy = "all", seed = seed)
val rfModel = rf.run(input)
rfModel.trees(0)
}RandomForest类
def run(input: RDD[LabeledPoint]): RandomForestModel = {
val trees: Array[NewDTModel] = NewRandomForest.run(input.map(_.asML), strategy, numTrees,
featureSubsetStrategy, seed.toLong, None)
new RandomForestModel(strategy.algo, trees.map(_.toOld))
}
def run(
input: RDD[LabeledPoint],
strategy: OldStrategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Long,
instr: Option[Instrumentation[_]],
parentUID: Option[String] = None): Array[DecisionTreeModel] = {
val timer = new TimeTracker()
timer.start("total")
timer.start("init")
val retaggedInput = input.retag(classOf[LabeledPoint])
val metadata =
DecisionTreeMetadata.buildMetadata(retaggedInput, strategy, numTrees, featureSubsetStrategy)
instr match {
case Some(instrumentation) =>
instrumentation.logNumFeatures(metadata.numFeatures)
instrumentation.logNumClasses(metadata.numClasses)
case None =>
logInfo("numFeatures: " + metadata.numFeatures)
logInfo("numClasses: " + metadata.numClasses)
}
// Find the splits and the corresponding bins (interval between the splits) using a sample
// of the input data.
timer.start("findSplits")
val splits = findSplits(retaggedInput, metadata, seed)
timer.stop("findSplits")
logDebug("numBins: feature: number of bins")
logDebug(Range(0, metadata.numFeatures).map { featureIndex =>
s"\t$featureIndex\t${metadata.numBins(featureIndex)}"
}.mkString("\n"))
// Bin feature values (TreePoint representation).
// Cache input RDD for speedup during multiple passes.
val treeInput = TreePoint.convertToTreeRDD(retaggedInput, splits, metadata)
val withReplacement = numTrees > 1
val baggedInput = BaggedPoint
.convertToBaggedRDD(treeInput, strategy.subsamplingRate, numTrees, withReplacement, seed)
.persist(StorageLevel.MEMORY_AND_DISK)
// depth of the decision tree
val maxDepth = strategy.maxDepth
require(maxDepth <= 30,
s"DecisionTree currently only supports maxDepth <= 30, but was given maxDepth = $maxDepth.")
// Max memory usage for aggregates
// TODO: Calculate memory usage more precisely.
val maxMemoryUsage: Long = strategy.maxMemoryInMB * 1024L * 1024L
logDebug("max memory usage for aggregates = " + maxMemoryUsage + " bytes.")
/*
* The main idea here is to perform group-wise training of the decision tree nodes thus
* reducing the passes over the data from (# nodes) to (# nodes / maxNumberOfNodesPerGroup).
* Each data sample is handled by a particular node (or it reaches a leaf and is not used
* in lower levels).
*/
// Create an RDD of node Id cache.
// At first, all the rows belong to the root nodes (node Id == 1).
val nodeIdCache = if (strategy.useNodeIdCache) {
Some(NodeIdCache.init(
data = baggedInput,
numTrees = numTrees,
checkpointInterval = strategy.checkpointInterval,
initVal = 1))
} else {
None
}
/*
Stack of nodes to train: (treeIndex, node)
The reason this is a stack is that we train many trees at once, but we want to focus on
completing trees, rather than training all simultaneously. If we are splitting nodes from
1 tree, then the new nodes to split will be put at the top of this stack, so we will continue
training the same tree in the next iteration. This focus allows us to send fewer trees to
workers on each iteration; see topNodesForGroup below.
*/
val nodeStack = new mutable.Stack[(Int, LearningNode)]
val rng = new Random()
rng.setSeed(seed)
// Allocate and queue root nodes.
val topNodes = Array.fill[LearningNode](numTrees)(LearningNode.emptyNode(nodeIndex = 1))
Range(0, numTrees).foreach(treeIndex => nodeStack.push((treeIndex, topNodes(treeIndex))))
timer.stop("init")
while (nodeStack.nonEmpty) {
// Collect some nodes to split, and choose features for each node (if subsampling).
// Each group of nodes may come from one or multiple trees, and at multiple levels.
val (nodesForGroup, treeToNodeToIndexInfo) =
RandomForest.selectNodesToSplit(nodeStack, maxMemoryUsage, metadata, rng)
// Sanity check (should never occur):
assert(nodesForGroup.nonEmpty,
s"RandomForest selected empty nodesForGroup. Error for unknown reason.")
// Only send trees to worker if they contain nodes being split this iteration.
val topNodesForGroup: Map[Int, LearningNode] =
nodesForGroup.keys.map(treeIdx => treeIdx -> topNodes(treeIdx)).toMap
// Choose node splits, and enqueue new nodes as needed.
timer.start("findBestSplits")
RandomForest.findBestSplits(baggedInput, metadata, topNodesForGroup, nodesForGroup,
treeToNodeToIndexInfo, splits, nodeStack, timer, nodeIdCache)
timer.stop("findBestSplits")
}
baggedInput.unpersist()
timer.stop("total")
logInfo("Internal timing for DecisionTree:")
logInfo(s"$timer")
// Delete any remaining checkpoints used for node Id cache.
if (nodeIdCache.nonEmpty) {
try {
nodeIdCache.get.deleteAllCheckpoints()
} catch {
case e: IOException =>
logWarning(s"delete all checkpoints failed. Error reason: ${e.getMessage}")
}
}
val numFeatures = metadata.numFeatures
parentUID match {
case Some(uid) =>
if (strategy.algo == OldAlgo.Classification) {
topNodes.map { rootNode =>
new DecisionTreeClassificationModel(uid, rootNode.toNode, numFeatures,
strategy.getNumClasses)
}
} else {
topNodes.map { rootNode =>
new DecisionTreeRegressionModel(uid, rootNode.toNode, numFeatures)
}
}
case None =>
if (strategy.algo == OldAlgo.Classification) {
topNodes.map { rootNode =>
new DecisionTreeClassificationModel(rootNode.toNode, numFeatures,
strategy.getNumClasses)
}
} else {
topNodes.map(rootNode => new DecisionTreeRegressionModel(rootNode.toNode, numFeatures))
}
}
}
protected[tree] def findSplits(
input: RDD[LabeledPoint],
metadata: DecisionTreeMetadata,
seed: Long): Array[Array[Split]] = {
logDebug("isMulticlass = " + metadata.isMulticlass)
val numFeatures = metadata.numFeatures
// Sample the input only if there are continuous features.
val continuousFeatures = Range(0, numFeatures).filter(metadata.isContinuous)
val sampledInput = if (continuousFeatures.nonEmpty) {
// Calculate the number of samples for approximate quantile calculation.
val requiredSamples = math.max(metadata.maxBins * metadata.maxBins, 10000)
val fraction = if (requiredSamples < metadata.numExamples) {
requiredSamples.toDouble / metadata.numExamples
} else {
1.0
}
logDebug("fraction of data used for calculating quantiles = " + fraction)
input.sample(withReplacement = false, fraction, new XORShiftRandom(seed).nextInt())
} else {
input.sparkContext.emptyRDD[LabeledPoint]
}
findSplitsBySorting(sampledInput, metadata, continuousFeatures)
}
DecisionTreeMetadata 类
def buildMetadata(
input: RDD[LabeledPoint],
strategy: Strategy,
numTrees: Int,
featureSubsetStrategy: String): DecisionTreeMetadata = {
val numFeatures = input.map(_.features.size).take(1).headOption.getOrElse {
throw new IllegalArgumentException(s"DecisionTree requires size of input RDD > 0, " +
s"but was given by empty one.")
}
val numExamples = input.count()
val numClasses = strategy.algo match {
case Classification => strategy.numClasses
case Regression => 0
}
val maxPossibleBins = math.min(strategy.maxBins, numExamples).toInt
if (maxPossibleBins < strategy.maxBins) {
logWarning(s"DecisionTree reducing maxBins from ${strategy.maxBins} to $maxPossibleBins" +
s" (= number of training instances)")
}
// We check the number of bins here against maxPossibleBins.
// This needs to be checked here instead of in Strategy since maxPossibleBins can be modified
// based on the number of training examples.
if (strategy.categoricalFeaturesInfo.nonEmpty) {
val maxCategoriesPerFeature = strategy.categoricalFeaturesInfo.values.max
val maxCategory =
strategy.categoricalFeaturesInfo.find(_._2 == maxCategoriesPerFeature).get._1
require(maxCategoriesPerFeature <= maxPossibleBins,
s"DecisionTree requires maxBins (= $maxPossibleBins) to be at least as large as the " +
s"number of values in each categorical feature, but categorical feature $maxCategory " +
s"has $maxCategoriesPerFeature values. Considering remove this and other categorical " +
"features with a large number of values, or add more training examples.")
}
val unorderedFeatures = new mutable.HashSet[Int]()
val numBins = Array.fill[Int](numFeatures)(maxPossibleBins)
if (numClasses > 2) {
// Multiclass classification
val maxCategoriesForUnorderedFeature =
((math.log(maxPossibleBins / 2 + 1) / math.log(2.0)) + 1).floor.toInt
strategy.categoricalFeaturesInfo.foreach { case (featureIndex, numCategories) =>
// Hack: If a categorical feature has only 1 category, we treat it as continuous.
// TODO(SPARK-9957): Handle this properly by filtering out those features.
if (numCategories > 1) {
// Decide if some categorical features should be treated as unordered features,
// which require 2 * ((1 << numCategories - 1) - 1) bins.
// We do this check with log values to prevent overflows in case numCategories is large.
// The next check is equivalent to: 2 * ((1 << numCategories - 1) - 1) <= maxBins
if (numCategories <= maxCategoriesForUnorderedFeature) {
unorderedFeatures.add(featureIndex)
numBins(featureIndex) = numUnorderedBins(numCategories)
} else {
numBins(featureIndex) = numCategories
}
}
}
} else {
// Binary classification or regression
strategy.categoricalFeaturesInfo.foreach { case (featureIndex, numCategories) =>
// If a categorical feature has only 1 category, we treat it as continuous: SPARK-9957
if (numCategories > 1) {
numBins(featureIndex) = numCategories
}
}
}
// Set number of features to use per node (for random forests).
val _featureSubsetStrategy = featureSubsetStrategy match {
case "auto" =>
if (numTrees == 1) {
"all"
} else {
if (strategy.algo == Classification) {
"sqrt"
} else {
"onethird"
}
}
case _ => featureSubsetStrategy
}
val numFeaturesPerNode: Int = _featureSubsetStrategy match {
case "all" => numFeatures
case "sqrt" => math.sqrt(numFeatures).ceil.toInt
case "log2" => math.max(1, (math.log(numFeatures) / math.log(2)).ceil.toInt)
case "onethird" => (numFeatures / 3.0).ceil.toInt
case _ =>
Try(_featureSubsetStrategy.toInt).filter(_ > 0).toOption match {
case Some(value) => math.min(value, numFeatures)
case None =>
Try(_featureSubsetStrategy.toDouble).filter(_ > 0).filter(_ <= 1.0).toOption match {
case Some(value) => math.ceil(value * numFeatures).toInt
case _ => throw new IllegalArgumentException(s"Supported values:" +
s" ${RandomForestParams.supportedFeatureSubsetStrategies.mkString(", ")}," +
s" (0.0-1.0], [1-n].")
}
}
}
new DecisionTreeMetadata(numFeatures, numExamples, numClasses, numBins.max,
strategy.categoricalFeaturesInfo, unorderedFeatures.toSet, numBins,
strategy.impurity, strategy.quantileCalculationStrategy, strategy.maxDepth,
strategy.minInstancesPerNode, strategy.minInfoGain, numTrees, numFeaturesPerNode)
}实例
Classification
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split the data into training and test sets (30% held out for testing)
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a DecisionTree model.
// Empty categoricalFeaturesInfo indicates all features are continuous.
val numClasses = 2
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "gini"
val maxDepth = 5
val maxBins = 32
val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
impurity, maxDepth, maxBins)
// Evaluate model on test instances and compute test error
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count()
println("Test Error = " + testErr)
println("Learned classification tree model:\n" + model.toDebugString)
// Save and load model
model.save(sc, "target/tmp/myDecisionTreeClassificationModel")
val sameModel = DecisionTreeModel.load(sc, "target/tmp/myDecisionTreeClassificationModel")Regression
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split the data into training and test sets (30% held out for testing)
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a DecisionTree model.
// Empty categoricalFeaturesInfo indicates all features are continuous.
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "variance"
val maxDepth = 5
val maxBins = 32
val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity,
maxDepth, maxBins)
// Evaluate model on test instances and compute test error
val labelsAndPredictions = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelsAndPredictions.map{ case (v, p) => math.pow(v - p, 2) }.mean()
println("Test Mean Squared Error = " + testMSE)
println("Learned regression tree model:\n" + model.toDebugString)
// Save and load model
model.save(sc, "target/tmp/myDecisionTreeRegressionModel")
val sameModel = DecisionTreeModel.load(sc, "target/tmp/myDecisionTreeRegressionModel")














 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









