






第一个spark程序
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
sc.stop()
}
}程序使sbt进行编译,新建sbt文件simple.sbt,里面配置项目的依赖。
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.2"这是项目的目录结构:
# Your directory layout should look like this
$ find .
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
# Package a jar containing your application
$ sbt package
...
[info] Packaging {..}/{..}/target/scala-2.11/simple-project_2.11-1.0.jar
# Use spark-submit to run your application
$ YOUR_SPARK_HOME/bin/spark-submit \
--class "SimpleApp" \
--master local[4] \
target/scala-2.11/simple-project_2.11-1.0.jarInitializing Spark
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)master指定Spark, Mesos or YARN cluster URL,或者使用”local”字符串进行本地运行。
spark-shell
./bin/spark-shell --master local[4]
//add JARs to the classpath
./bin/spark-shell --master local[4] --jars code.jar
// add maven dependencies
./bin/spark-shell --master local[4] --packages "org.example:example:0.1"RDDs
spark支持text, SequenceFiles, 和其他Hadoop InputFormat等外部文件。
文件rdd可以使用textFile 方法进行转化。
val distFile = sc.textFile("data.txt")textFile方法支持文件、目录、通配符。
textFile("/my/directory")
textFile("/my/directory/*.txt")
textFile("/my/directory/*.gz")除了text文件,spark还支持其他的几种数据格式。
//这个方法能读取目录中的多个小文件,返回一个由(文件名,文件内容)组成的pair
SparkContext.wholeTextFiles
//使用SparkContext’s sequenceFile[K, V]方法来读取SequenceFiles文件,k,v是Hadoop Writable接口的字类,如IntWritable,Text。spark也允许使用一些基本数据类型如sequenceFile[Int, String],它会自动的转换成IntWritables 和Text.
SequenceFiles
//其他的Hadoop InputFormat,我们可以使用SparkContext.hadoopRDD方法。方法参数是任意的JobConf 和inputFormat类key类和value类。
HadoopRDD(sc: SparkContext, conf: JobConf, inputFormatClass: Class[_ <: InputFormat[K, V]], keyClass: Class[K], valueClass: Class[V], minPartitions: Int)
RDD.saveAsObjectFile 和SparkContext.objectFile 能够保存序列化的java对象。不过没有Avro有效率。RDD操作
transformations
action
map是transformations操作,reduce是action操作。
所有的transformations都是lazy的。只有当在action操作中需要transformations后的数据时它才会进行计算。这样的话使得spark执行就更有效率了。默认情况下,每个action操作时,transformed RDD会被重新计算。当然你也可以使用persist方法把它持久化到内存。
基本操作
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)分析上述代码。lines没有保存到内存,它只是一个指向这个文件的指针。lineLengths 保存map transformation的结果,但是它没有马上执行。最后运行reduce action进行执行。这一步spark把计算分解成几个task在分布式集群上运行。
如果你想之后使用lineLengths ,那么你可以在reduce前使用:
lineLengths.persist()传递函数
spark api高度依赖传递函数。我们可以使用两种推荐的方式来开发传递函数。
匿名函数 (http://docs.scala-lang.org/tutorials/tour/anonymous-function-syntax.html)
使用全局对象的静态函数
object MyFunctions {
def func1(s: String): String = { ... }
}
myRdd.map(MyFunctions.func1)同样可以使用以下方式:
class MyClass {
def func1(s: String): String = { ... }
//类似rdd.map(x => this.func1(x))
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) }
}同样的我们可以访问外部对象的变量
class MyClass {
val field = "Hello"
//类似于 rdd.map(x => this.field + x)
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) }
}闭包理解
以下这个例子在同一个JVM下会有不同的结果。
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)这个操作会把分解成多个excutor上去,每个excutor有一个counter 的copy,且内存中保存着counter ,那么所有的excutor对counter 是不可见的,可见的只是counter 的copy。
为了实现这样的操作,我们用Accumulator类也进行实现。
类似的错误有如下代码:
rdd.foreach(println)
rdd.map(println).在单机环境下可能不会出错。要实现这种功能,可以使用:
rdd.collect().foreach(println)代替,因为他运行在内存。但是这种行为可能会导致OOM,因为它只是在一台机器上运行,安全的操作是抽样:
rdd.take(100).foreach(println)与Key-Value Pairs相随
最常用的使用是分布式中的“shuffle”操作。如通过key来grouping 、aggregating 元素。
PairRDDFunctions
In Scala, these operations are automatically available on RDDs containing Tuple2 objects (the built-in tuples in the language, created by simply writing (a, b)). The key-value pair operations are available in the PairRDDFunctions class, which automatically wraps around an RDD of tuples.
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)Transformations
map(func)
filter(func)
flatMap(func) //一对多
mapPartitions(func) //func 必须是 Iterator<T> => Iterator<U>这种形式
mapPartitionsWithIndex(func) //func 必须是 (Int, Iterator<T>) => Iterator<U>形式
sample(withReplacement, fraction, seed)
union(otherDataset)
intersection(otherDataset)
distinct([numTasks]))
groupByKey([numTasks]) 数据集 (K, V) 返回(K, Iterable<V>) pair
reduceByKey(func, [numTasks])
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
sortByKey([ascending], [numTasks])
join(otherDataset, [numTasks])
cogroup(otherDataset, [numTasks])
cartesian(otherDataset)
pipe(command, [envVars])
coalesce(numPartitions)
repartition(numPartitions)
repartitionAndSortWithinPartitions(partitioner) Actions
reduce(func)
collect()
count()
first()
take(n)
takeSample(withReplacement, num, [seed])
takeOrdered(n, [ordering])
saveAsTextFile(path)
saveAsSequenceFile(path)
saveAsObjectFile(path)
countByKey()
foreach(func)Shuffle
shuffle是spark为了重新分布数据的一种机制,有别于partitions。
以reduceByKey 为例,生成一个(key,fuc result)的元组RDD,有个困难就是对于同一个key来说不是所有的key都在同一个分区,但是他们必须一起协作得到结果。这样的话我们就必须保证对于同一个key来说必须要保证它们在同一个分区,这个操作就是shuffle。会引起shuffle的操作有repartition 操作( repartition 和 coalesce)、ByKey的操作(groupByKey 和reduceByKey),join 操作( cogroup 和join)。
shuffle性能影响
shuffle对于磁盘i/o、网络i/o及数据序列化来说是一个花费很大的操作。在map,reduce进行协作的时候,map生成的数据是存在内存的。同时shuffle在转换数据前后要使用相当大的堆内存。在操作过程中,会把中当数据存在内存,而当内存存储不下时,它又会把数据置换存在磁盘上,这会产生磁盘i/o和垃圾收集等问题。spark.local.dir这个参数配置临时存储目录。
RDD持久化
RDD持久化是以JAVA序列化对象进行储的。默认情况下,spark是使用StorageLevel.MEMORY_ONLY级别进行持久化。有以下几种存储级别。
MEMORY_ONLY
MEMORY_AND_DISK
MEMORY_ONLY_SER
MEMORY_AND_DISK_SER
DISK_ONLY
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc.
OFF_HEAP 共享变量
在spark中,变量在各台机器上不同及时更新,且机器之间彼此不可见,因些spark使用广播变量(broadcast variables )和 accumulators来共享变量。
广播变量broadcast variables
广播变量允许每台机器缓存一个只读的变量,而不是每个task中变量的副本。下面是使用方法。
SparkContext.broadcast(v)val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.valueAccumulators
Accumulators是一个只有在关联交换运算中被添加的一个变量。它能用来实现mapreduce中的counter及sum。spark本身只支持数值型的accumulators 。当然我们可以自己实现更多的类型。
如果accumulators 被创建了,那么在后台ui中是能够看到它的。如下图
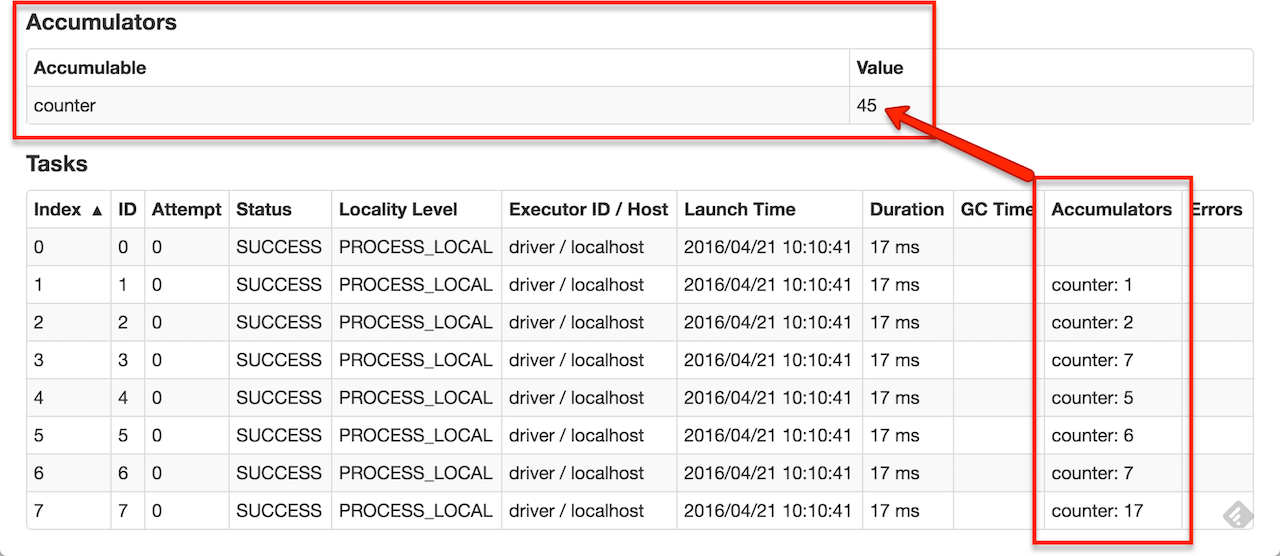
数值类型的Accumulators能够使用 SparkContext.longAccumulator() 或SparkContext.doubleAccumulator()等来创建。然后task能够使用add方法来进行++操作。但是tasks不能读取它的值,只有driver programmer 能读accumulator的值和使用value方法
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
accum.value我们可以继承AccumulatorV2这个类来实现自己的Accumulator。要实现以下几个方法:
reset //置零
add //加运算
merge //合并同类型的Accumulator
。。。object VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
val vec_ : MyVector = MyVector.createZeroVector
def reset(): MyVector = {
vec_.reset()
}
def add(v1: MyVector, v2: MyVector): MyVector = {
vec_.add(v2)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1")懒加载特性
val accum = sc.longAccumulator
data.map { x => accum.add(x); x } //x的值还会是0
// Here, accum is still 0 because no actions have caused the map operation to be computed.Launching Spark jobs from Java / Scala
import org.apache.spark.launcher.SparkAppHandle;
import org.apache.spark.launcher.SparkLauncher;
public class MyLauncher {
public static void main(String[] args) throws Exception {
SparkAppHandle handle = new SparkLauncher()
.setAppResource("/my/app.jar")
.setMainClass("my.spark.app.Main")
.setMaster("local")
.setConf(SparkLauncher.DRIVER_MEMORY, "2g")
.startApplication();
// Use handle API to monitor / control application.
}
}














 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









