






一、Spark-Streaming(http://spark.apache.org/streaming/)
1、作用
Spark Streaming makes it easy to build scalable fault-tolerant streaming applications.
基于Spark之上(RDD)的流处理,
流:
source ==> compute ==> store
比如:flume,采集数据到HDFS,spark按批次来处理数据。N个批次连接起来就是流。
离线是特殊的流。
2、易用

Spark Streaming brings Apache Spark's language-integrated API to stream processing, letting you write streaming jobs the same way you write batch jobs. It supports Java, Scala and Python.
Spark Streaming将Apache Spark的语言集成API用于流处理,让您可以像编写批处理作业那样编写流作业。它支持Java、Scala和Python。
3、容错

out of the box :开箱即用、内置(OOTB)
SparkStreaming可以恢复丢失的作业和操作状态,无需再开发,没有额外的代码。
4、综合

5、部署

6、概要
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
Spark Streaming是核心Spark API的扩展,它支持对实时数据流进行可伸缩、高吞吐量、容错的流处理。数据可以从多种来源摄取,如Kafka、Flume、Kinesis或sockets,可以使用映射、reduce、连接和窗口等高级函数表示的复杂算法进行处理。最后,可以将经过处理的数据推送到文件系统、数据库和实时仪表板。实际上,您可以将Spark的机器学习和图形处理算法应用到数据流上。
(1)SparkStreaming不需要单独部署。比Sqoop方便很多。
(2)SparkCore的调优也能用在SparkStreaming上。

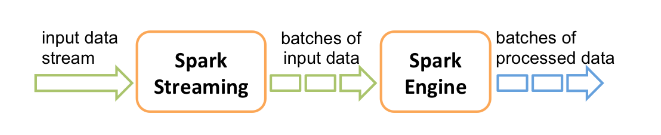
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
在内部,它的工作方式如下。Spark Streaming接收实时输入数据流并将数据划分为批,然后由Spark引擎(core)处理这些数据,以分批生成最终的结果流。

SparkStreaming编程模型:DStream:不间断的流的数据
SparkCore编程模型:RDD
SparkSQL编程模型:DF/DS
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
Spark Streaming提供了一个名为离散流或DStream的高级抽象,它代表了一个连续的数据流。可以从来自诸如Kafka、Flume和Kinesis等源的输入数据流创建(跟RDD创建一样),也可以通过对其他DStreams应用高级操作来创建(类似RDD转RDD2,DS转DS2)。在内部,一个DStream被表示为一系列的RDD。
二、DStream实践
1、官网
Streaming入口:StreamingContext
Core入口:SparkContext
SQL入口:SparkSession(2.x版本)
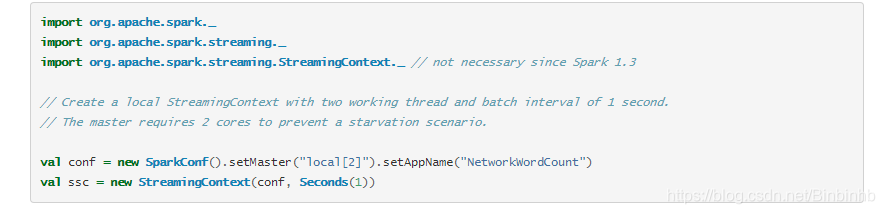
(1)需要传conf给StreamingContext,查SparkContext有getConf方法,但是这里不能出现两个SparkContext所以不能用这个方法。

流处理的时间间隔
val ssc = new StreamingContext(sc, Seconds(10))

创建要一个DStream
val lines = ssc.socketTextStream("localhost", 9999)

val words = lines.flatMap(_.split(" "))
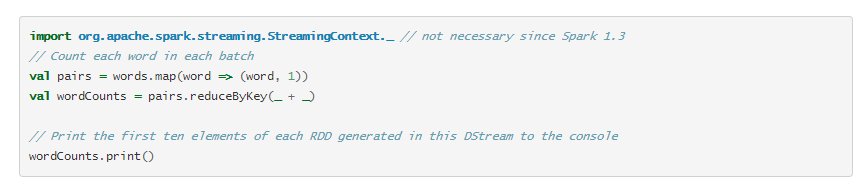
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
此处的.print()理解为RDD的action,可以触发操作。

ssc.start()
ssc.awaitTermination()
综上:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(10))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()(2)需先打开端口

您将首先需要使用以下方法作为数据服务器运行Netcat(在大多数类Unix系统中都有的小型实用程序)
nc -lk 9999
(3)执行
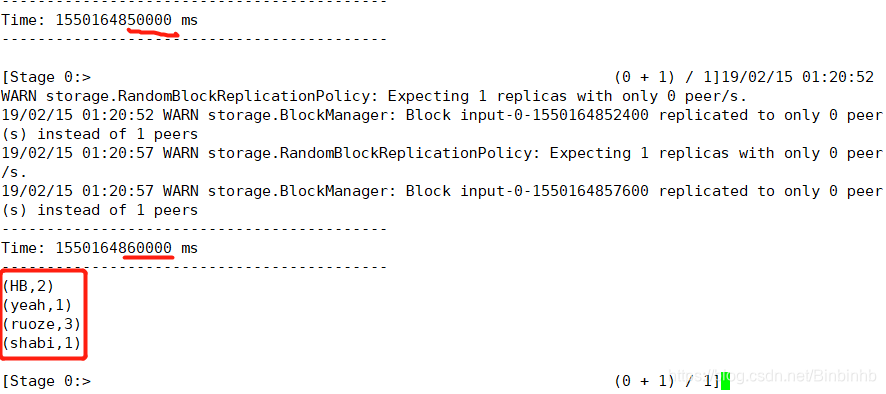
(4)后台

(5)Streaming
控制台输入,Streaming页面变化

总结:
批次处理时间合理,不要出现时间间隔太短,上一个批次没处理完,下一个批次就进来。
资源分配需合理。
2、源码:StreamingContext入口
(1)作用
Main entry point for Spark Streaming functionality. It provides methods used to create
[[org.apache.spark.streaming.dstream.DStream]]s from various input sources. It can be either
created by providing a Spark master URL and an appName, or from a org.apache.spark.SparkConf
configuration (see core Spark documentation), or from an existing org.apache.spark.SparkContext.
The associated SparkContext can be accessed using `context.sparkContext`. After
creating and transforming DStreams, the streaming computation can be started and stopped
using `context.start()` and `context.stop()`, respectively.
`context.awaitTermination()` allows the current thread to wait for the termination
of the context by `stop()` or by an exception.
1)提供从各种数据源创建DStream的方法
2)可以提供URL and an appName,也可以从SoarkConf里面get
3)对DStream做转换
4)通过context.start()开启,context.stop()停止
(2)StreamingContext构造方法

(2)Duration
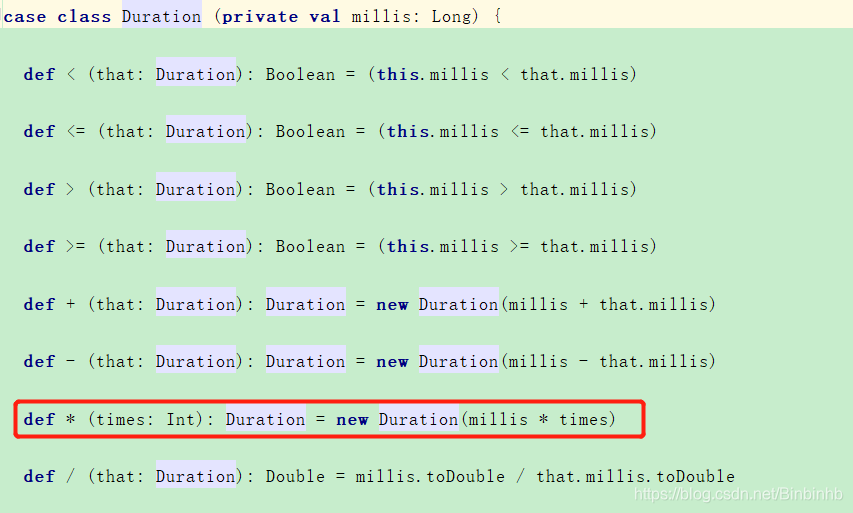
1)case class 说明不用new
2)这里是毫秒为单位,而Seconds是Duration的伴生对象,创建了对象,是秒单位,所以可以传秒给StramingContext。

(2)附属构造器
所以上面可以直接传sc


3、socketTextStream VS socketStream
(1)socketTextStream
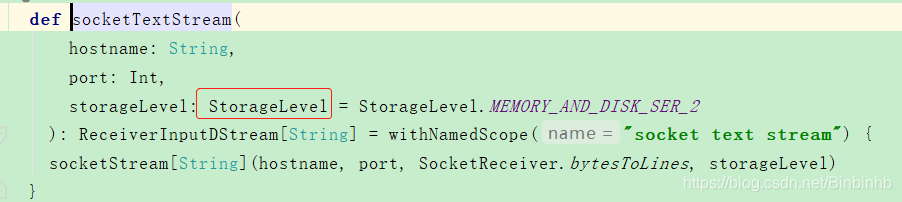
Core的Storeage是memory only.cache调用了persisit(Memory only)
Streaming的是MEMORY_AND_DISK_SER_2(默认参数)
调用了socketStream()
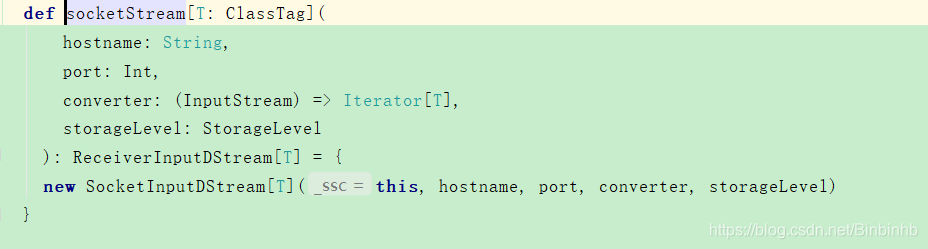
(2)socketStream
4、IDEA实践
源码:
package com.HBinz.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWCApp {
def main(args: Array[String]): Unit = {
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("StreamingWCApp")
val scc = new StreamingContext(sparkconf,Seconds(10))
//已有scc,要进行实时流处理,需要有源头的DStream
val lines = scc.socketTextStream("hadoop002",8888)
//transformation
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
//action = output
wordCounts.print()
scc.start()
scc.awaitTermination()
}
启动开始

(1)输入zidong zidong daxia zidong daxia

成功
5、初始化StreamingContext
The appName parameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local[*]” string to run in local mode. In practice, when running on a cluster, you will not want to hardcode master in the program, but rather launch the application with spark-submit and receive it there. However, for local testing and unit tests, you can pass “local[*]” to run Spark Streaming in-process (detects the number of cores in the local system). Note that this internally creates a SparkContext (starting point of all Spark functionality) which can be accessed as ssc.sparkContext.
The batch interval must be set based on the latency requirements of your application and available cluster resources. See the Performance Tuning section for more details.
appName参数是要在集群用户界面上显示的应用程序的名称。主节点是一个Spark、Mesos或YARN集群URL,或者一个在本地模式下运行的特殊“local[*]”字符串。实际上,当在集群上运行时,您不会希望在程序中硬编码master,而是通过spark-submit启动应用程序并在那里接收它。但是,对于本地测试和单元测试,您可以通过“local[*]”来在进程中运行Spark流(检测本地系统中的核心数量)。注意,这在内部创建了一个SparkContext(所有Spark功能的起始点),可以作为ssc.SparkContext访问。
必须根据应用程序和可用集群资源的延迟需求设置批处理间隔。有关更多细节,请参见性能优化部分。
WARN StreamingContext:
spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
如果你的数据有receivers,那么你的local[n],n需要大于1。因为占用一个core。所以socket需要local[2]以上。
(1)基础
After a context is defined, you have to do the following.
Define the input sources by creating input DStreams.
Define the streaming computations by applying transformation and output operations to DStreams.
Start receiving data and processing it using streamingContext.start().
Wait for the processing to be stopped (manually or due to any error) using streamingContext.awaitTermination().
The processing can be manually stopped using streamingContext.stop().
在定义了上下文之后,您必须执行下列操作。
通过创建输入流定义输入源。
通过对DStreams应用转换和输出操作来定义流计算。
开始接收数据并使用streamingContext.Start()处理数据。
请等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)。
可以使用streamingContext.stop()手动停止处理。
(2)重点
Once a context has been started, no new streaming computations can be set up or added to it.
Once a context has been stopped, it cannot be restarted.
Only one StreamingContext can be active in a JVM at the same time.
stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of stop() called stopSparkContext to false.
A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
上下文一旦启动,就无法设置或添加新的流计算。
上下文一旦停止,就不能重新启动。
JVM中只能有一个StreamingContext同时处于活动状态。
StreamingContext上的station()也停止了SpaskContext。若要仅停止流上下文,请将start()的可选参数设置为false。
只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SpamkContext),就可以重新使用SpamkContext来创建多个StreamingContext。
(3)文件系统
For reading data from files on any file system compatible with the HDFS API (that is, HDFS, S3, NFS, etc.), a DStream can be created as via StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass].
File streams do not require running a receiver so there is no need to allocate any cores for receiving file data.
For simple text files, the easiest method is StreamingContext.textFileStream(dataDirectory).
为了从任何与HDFS API兼容的文件系统(即,HDFS、S3、NFS等)上的文件中读取数据,可以通过StreamingContext.fileStream[KeyClass、ValueClass、InputFormatClass]来创建。
文件流不需要运行接收器,所以不需要为接收文件数据分配任何内核。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
6、读HDFS文件系统进行流计算实践
(1)textFileStream()源码分析
Create an input stream that monitors a Hadoop-compatible filesystem
for new files and reads them as text files (using key as LongWritable, value
as Text and input format as TextInputFormat). Files must be written to the
monitored directory by "moving" them from another location within the same
file system. File names starting with . are ignored.
创建一个输入流来监视与Hadoop兼容的文件系统对于新文件并将它们作为文本文件读取(使用key作为LongWritable,value作为文本和输入格式作为文本输入格式)。文件必须写入到通过从同一目录中的另一个位置“移动”它们来监视目录文件系统。从.开始的文件名将被忽略。
def textFileStream(directory: String): DStream[String] = withNamedScope("text file stream") {
fileStream[LongWritable, Text, TextInputFormat](directory).map(_._2.toString)
}textFileStream返回值是DStream,所以没有receivers
问题1:为什么要调用textFileStream方法需要key-value
因为key值相当于偏移量,通过偏移量找到text,所以value是text
问题2:为什么要把第二个字段取出来转String格式
第二个字段才是text
(2)数据准备
hdfs dfs -mkdir -p /streaming/input/
hdfs dfs -put /opt/data/HBinzTest.txt /streaming/input/1.txt
hdfs dfs -put /opt/data/HBinzTest.txt /streaming/input/2.txt
hdfs dfs -put /opt/data/HBinzTest.txt /streaming/input/3.txt
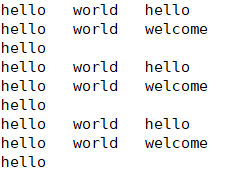
hdfs dfs -text /streaming/input/*
(3)源码
package com.HBinz.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingHDFSApp {
def main(args: Array[String]): Unit = {
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("StreamingHDFSApp")
val scc = new StreamingContext(sparkconf,Seconds(10))
//读取文件系统
val lines = scc.textFileStream("/streaming/input")
//transformation
val words = lines.flatMap(_.split("\t"))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
//action = output
wordCounts.print()
scc.start()
scc.awaitTermination()
}
}
没数据。
再上传文件
hdfs dfs -put /opt/data/HBinzTest.txt /streaming/input/4.txt
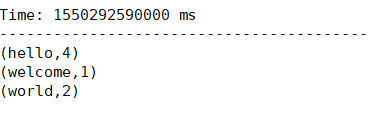
总结:
Streaming只认Spark启动之后上传到HDFS的文件。
7、如何监听文件目录

重点:
(1)所有的文件是相同格式
8、累加功能

(1)updateStateByKey

updateStateByKey操作允许您在用新信息不断更新状态的同时维护任意状态。要使用它,您必须执行两个步骤。
定义状态——状态可以是任意数据类型。
定义状态更新函数——指定一个函数如何使用以前的状态和输入流中的新值更新状态。
在每个批处理中,Spark将对所有现有的键应用状态更新函数,不管它们是否有新的数据在批处理中。如果update函数返回则密钥-值对不会被消除。
让我们用一个例子来说明这一点。假设您要维护文本数据流中看到的每个单词的运行计数。在这里,运行计数是状态,它是一个整数。我们将更新函数定义为:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}(2)将updateFunction放到代码里
newValues:新的信息流
runningCount:已有信息流(可能为空)
(3)代码
package com.HBinz.spark.streaming.day01
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingStateApp {
def main(args: Array[String]): Unit = {
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("StreamingHDFSApp")
val scc = new StreamingContext(sparkconf,Seconds(10))
//socket
val lines = scc.socketTextStream("hadoop002",8888)
//transformation
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
//累加
val result = pairs.updateStateByKey(updateFunction)
//action = output
result.print()
scc.start()
scc.awaitTermination()
}
/** key不处理,只处理value
* 比如:第一批次:(hello,1) (hello,1) ===》 (1,1)===》 (hello,2)
*
*/
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val curr = newValues.sum
val pre = runningCount.getOrElse(0)
Some(curr + pre)
}
}报错:
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
因为有已有信息流,所以需要建立一个目录来存放,以便多次操作
(4)优化
scc.checkpoint("C:\\Users\\dell\\Desktop")

生成很多临时文件

(5)build,linux操作
命令:
./spark-submit --master local[2] --name StreamingStateApp \
--class com.HBinz.spark.streaming.day01.StreamingStateApp \
/opt/lib/spark-train-1.0.jar

checkpoint文件目录在:















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









