






相对于Hadoop、hive、storm、spark以及其他大数据组件的优势
a、使用门槛低、开发周期短、上线快。
b、性能好、查询快、实时展示结果。
c、扩容方便、可以快速支持迅猛增长的数据(可支持到TB、PB级别的数据)。
Elastic Stack包含哪些组件
Kibana、Elasticsearch、Logstash、Beats
Kibana:数据的探索与可视化分析。
Elasticsearch:数据存储、查询与分析。
Logstash、Beats:数据收集与处理,可以理解为ETL工具,支持多种数据源的数据采集;例如:日志文件、excel、网络数据、mysql等等。同时还可以自定义,给拓展待来了无限的可能。
常见术语
Doucment(文档):用户存储在es中的数据文档,类似于mysql中的一条数据。
Index(索引):有具有相通字段的文档列表组成,类似于mysql中的表。
Node(节点):一个Elasticsearsh运行的实例节点,集群的构成单元。
Cluster(集群):由一个或者多个Node组成,对外提供服务。
Doucment介绍
结构由json格式构成。常见的数据类型:
字符串:text、keyword;text是分词的,keyword不分词。
数值类型:long、integer、short、byte、double、float、half_float、scaled_float。
布尔类型:boolean。
日期:date。
二进制:binary。
范围类型:integer_range、float_range、long_range、double_range、date_range。
每一个Doucment都有一个唯一的标示,可以自行指定,如果不指定es自动生成。
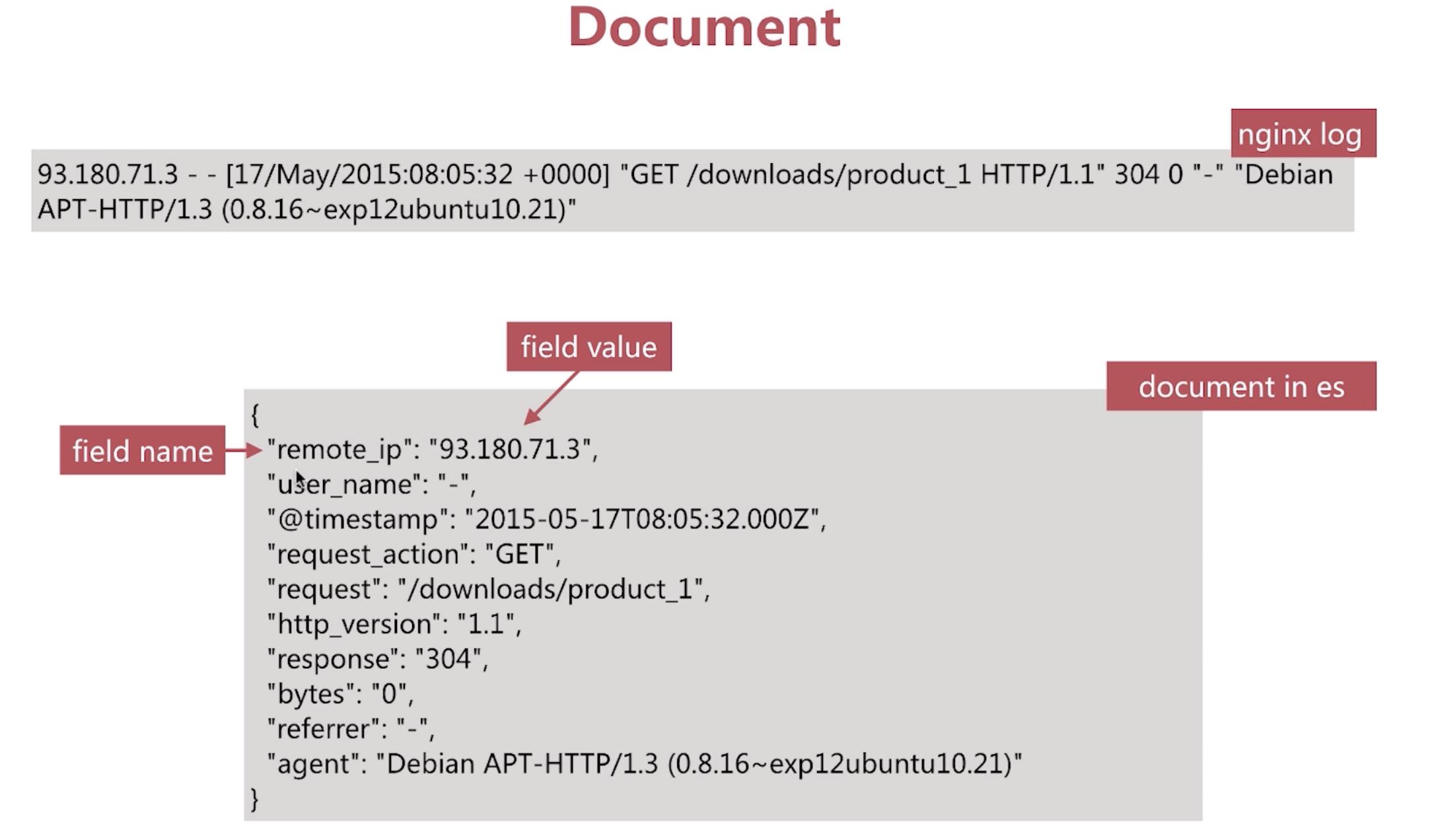
Document Meta Data
元数据,用与标注文档的相关信息。
_index:文档所在的索引名称。
_type:文档所在的类型名。
_id:文档id。
_uid:组合id,由_type+_id组成(6.x版本以后_type不再起作用,此值与_id相同)。
_source:文档的原始json数据,可以从这里获取每一个字段的内容。
_all:整合所有字段内容到该字段,可以对整个doucment直接进行查询,针对所有字段内容进行分词,新版本中官方已经不推荐使用,默认禁用。缺点是占用大量的磁盘空间性能也不是很好。
Index介绍
索引中存储具有相同结构的文档(Document)集合。
每个索引都有自己的mapping定义(类似于mysql的表结构),用于定义字段名和类型。
一个集群可以有多个索引,比如:nginx日志存储的时候可以日期每天生成一个索引来存储。
nginx-2022-02-21
nginx-2022-02-22
nginx-2022-02-23
Index Rest Api
es支持通过http请求的方式对Index进行操作,创建、修改、查询、删除。
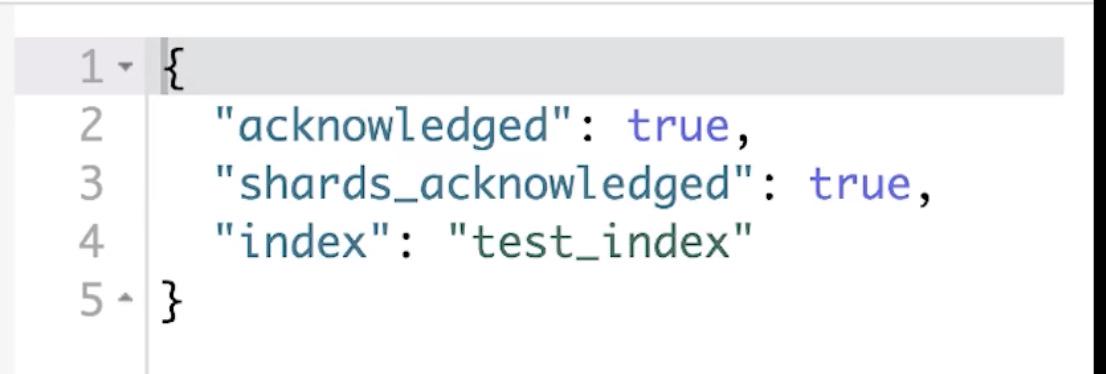
创建
http method=PUT,/test_index,test_index为Index的名称。
成功后返回:
查询所有Index
http method=GET,_cat/indices。
成功后返回:

删除索引
http method=DELETE,/test_index,test_index为Index的名称。
成功后返回:

Document Rest Api
指定id创建文档
http method=PUT,/test_index/doc/1,doc为type(高级版本将会去掉type),1为指定的id。(创建文档时如果对应的Index不存在es会自动创建对应的Index和type)
{
"username":"alfred",
"age":1
}
上述的json为文档的内容。
成功后返回:

不指定id创建文档
http method=POST,/test_index/doc,es会自动生成id。
{
"username":"tom",
"age":20
}
上述的json为文档的内容。
成功后返回:

根据id查询文档
http method=GET,/test_index/doc/1
成功后返回:

不存在的返回:

查询所有文档
http method=GET,/test_index/doc/_search
成功后返回:
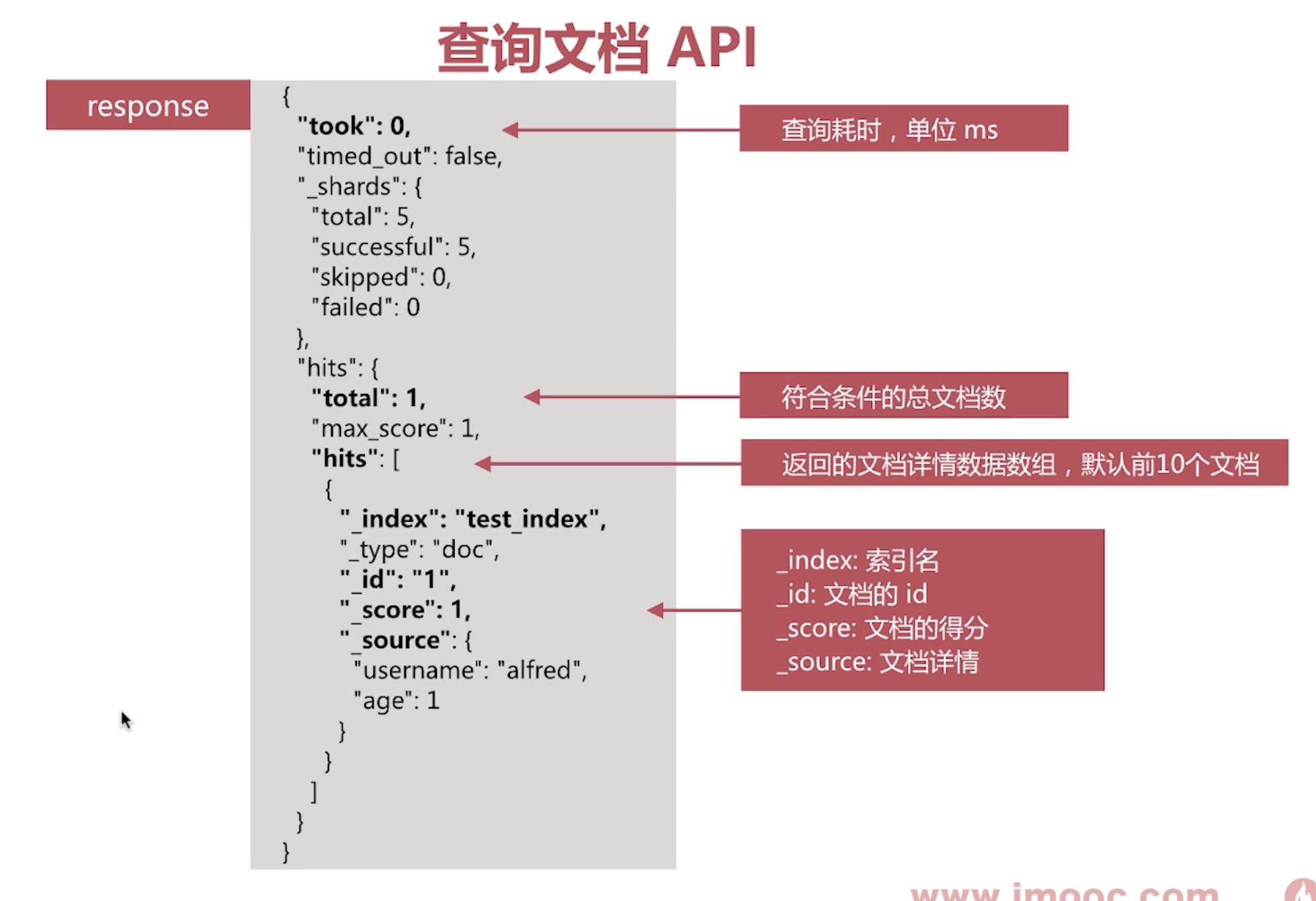
通过_search api指定查询条件查询
http method=GET,/test_index/doc/_search
{
"query":{
"term":{
"_id":"1"
}
}
}
成功后返回:

来源:















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









