






Hadoop:MapReduce第一个例子WordsCount
一,如何在eclipse上建立自己的第一个项目
二,这是wordscount.java程序
package wordscount.demo;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class wordscount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(wordscount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job,"hdfs://Master:9000/wordcount/input");
FileOutputFormat.setOutputPath(job, new Path("hdfs://Master:9000/wordcount/output"));
job.waitForCompletion(true);
}
}三, eclipse上如何导入hadoop的jar文件
右键WC项目,Build Path -> Configure Bulid Path... -> Libraries -> Add External Jars... 添加所需jar包。hadoop编程所需的jar包在hadoop-2.7.3\share\hadoop\下的文件的下一层的jar包(如果有的话),以及hadoop-2.7.3\share\hadoop\common\lib的里的jar包。
其实,可以事先将hadoop-2.7.3中所有的jar 放在_lib文件夹里。
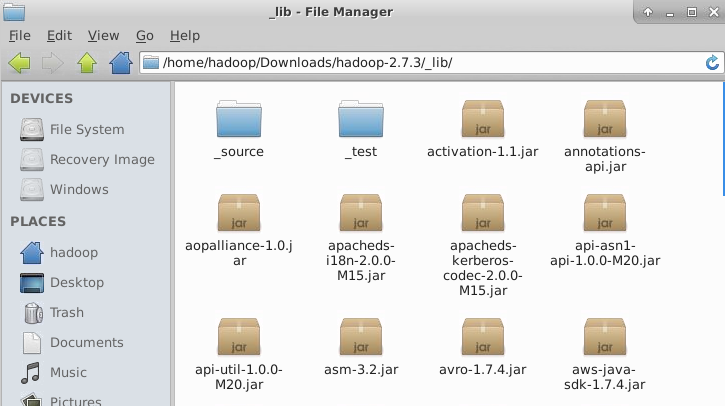
四,如何将wordscount.java 程序打包成 .jar 文件:
右键WC项目,Export -> Java -> JAR file.............
五,如何在Hadoop运行wordscount.jar
1) 准备测试数据 wordtest.txt 及其 words.txt,在本地上: 本地目录: /home/hadoop/words.txt
vi /home/hadoop/wordtest.txt
vi /home/hadoop/wordtest.txtHello tom
Hello jim
Hello ketty
Hello world
Ketty tomvi /home/hadoop/words.txtHello tom
Hello jim
Hello ketty
Hello world
Ketty tom
2) 在HDFS上建立 /wordcount/input 输入目录,这里有两种方法:
第一种: 命令
在hdfs上创建输入数据文件夹:
hadoop fs -mkdir -p /wordcount/input
第二种:在eclipse上直接创建文件夹a, 下载 hadoop-eclipse-plugin-2.7.3.jar 插件, 将这个插件复制到 /usr/lib/eclipse/plugins/ 里
sudo cp .......~/hadoop-eclipse-plugin-2.7.3.jar /usr/lib/eclipse/plugins/
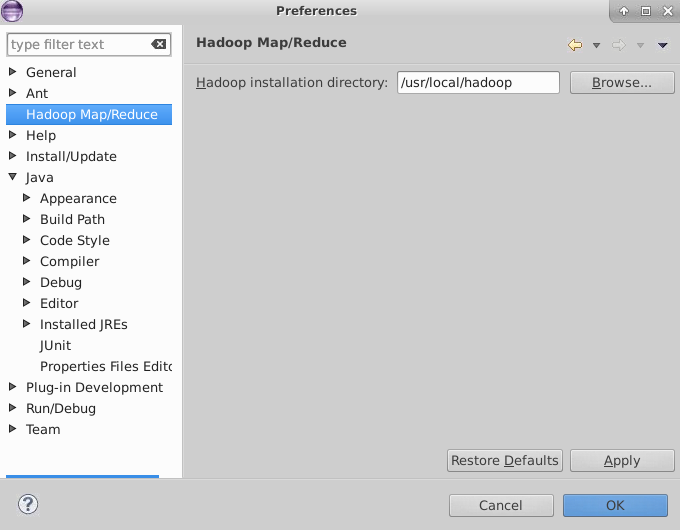
b, 重新打开eclipse, window ——> Preference
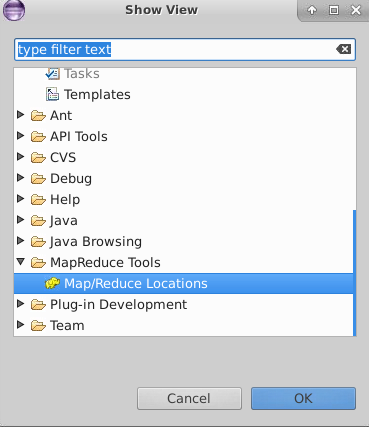
c, window ——> open perspective ——> other 点开 Map/Reduce;
window ——> show view ——> other 点开 Map/Reduce;
d,
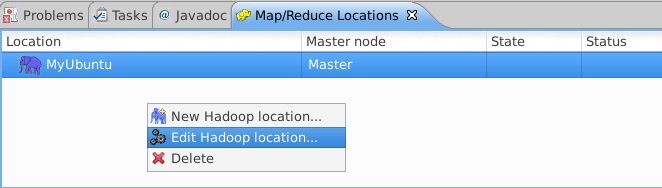
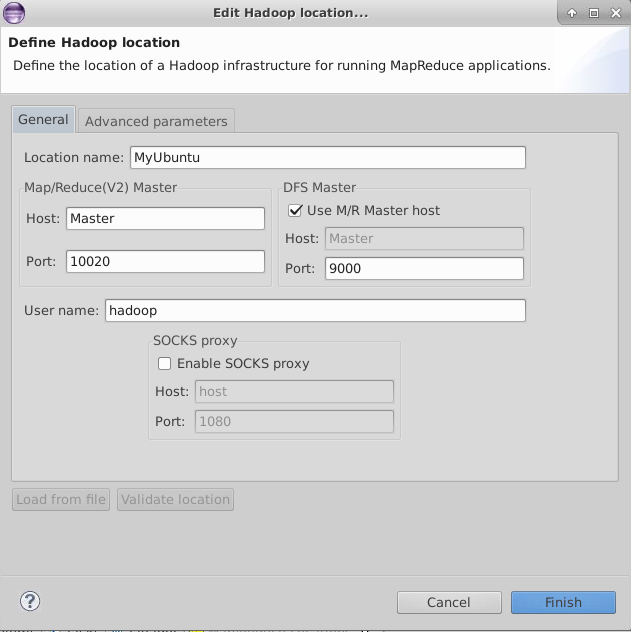
左边的port: 查看 core-site.xml , 左边的port:查看 hdfs-site.xml
e, 现在eclipse上就会显示 DFS location
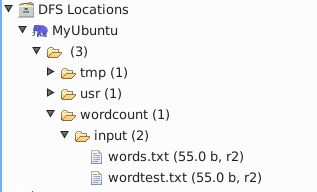
3) 将本地 的 words.txt 和 wordtest.txt上传到 hdfs上
hadoop fs –put /home/hadoop/words.txt /wordcount/input
查看: hadoop fs -cat /wordcount/input/words.txt
上传成功:

4) 使用命令启动执行wordcount程序jar包
hadoop jar wordscount.jar /wordcount/input /wordcount/output
5) 结果查看
程序运行成功:
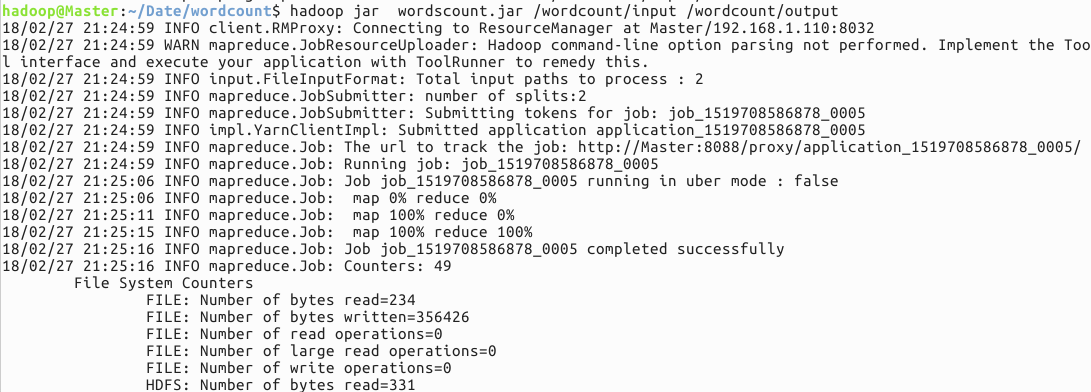
结果如下:
hadoop fs -ls /wordcount/output/
hadoop fs -cat /wordcount/output/part-r-00000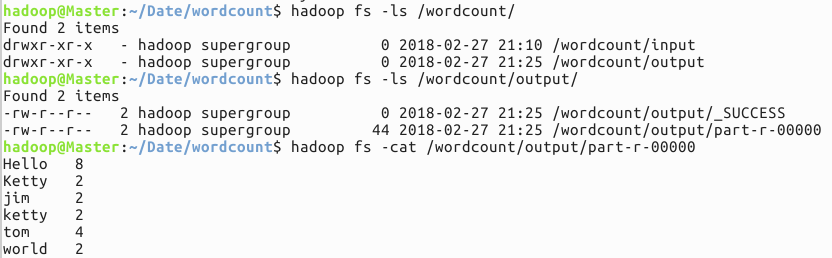















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









