







 本文介绍了一种名为LSH(局部敏感散列)的算法,该算法用于从大规模文本数据集中高效地找出相似文本。通过使用特定的技术如shingle方法和合理的参数设置,能够显著降低时间复杂度,并给出了一种实用的实现方案。
本文介绍了一种名为LSH(局部敏感散列)的算法,该算法用于从大规模文本数据集中高效地找出相似文本。通过使用特定的技术如shingle方法和合理的参数设置,能够显著降低时间复杂度,并给出了一种实用的实现方案。
LSH——Locality Sensitive Hashing,就是一种找疑似相似项的方法。找疑似相似项的目的是为了找到最终真正相似的项。这么做的目的无非是为了减少时间复杂度。
问题描述
MMD自带的LSH练习的主要要求如下:
从一个存储着千万量级的文本数据中找到相似的数据[1]。这里需要说明的两个问题就是:
一,原始的单个数据是按行组织的。一行文本就叫做一条数据。值得注意的是,每行文本至少包含10个单词(这一点很重要,是后面hashing的依据);
二,两条文本之间相似指的是,两条文本的edit distance小于2.这一点也很重要。因为原始的计算两条文本之间的edit distance的方法的时间复杂度较高约为
O(mn)
,其中
m,n
分别为两条文本的长度。但是只判断两个文本之间的edit distance小于2的话,时间复杂度瞬间变为
O(n)
或
O(m)
——首先判断长度,若长度差大于1,直接pass;若长度差小于等于1,这逐个比较。
问题分析:
因为原始数据量非常大,
N=O(107)
,如果直接进行pair的对比的话,呵呵,时间复杂度瞬间变为
O(N2)=O(1014)
,这至少对现在计算机(假设主频为3G赫兹)来说,算上个
105
秒,也就是大概27.777777小时。这还没有考虑单机内存的限制(就是这个玩意,成了后来单机计算的瓶颈)。因此,不得不使用LSH先选出一些候选者(candidate)来。
1
k
的取值
我们可以从课程中[2]的得到一些hashing的启发,那就是运用shingle的方法,就是将连续的
这时,每条数据至少十个单词这一信息就变得极为有用了。可以分析一下:
同理,
k
为2、3、4、5时都不会出现这种问题。直到
数据1:q w e r t y u i o p
数据2:q w e r e y u i o p
显然,数据一与数据二的shingle集中没有一条是相同的,因此,数据二就不可能落在数据一的candidate set。这就会造成结果的错误。因此这里的
k
就选择为5。
2 是否需要进行AND 和 OR的过程
这一表述有点太露骨(low、表象)了。因为在原始的课程当中的相似项发现中,就有一个步骤来进行minhashing,从而将最终结果正确率大大提高,好像使用了minhashing之后生活就会立马更加美好一样。
但是,在这里,采用的上面的shingle方式,再进行minhashing,效果是没有什么提升的。分析如下(还以上面的那组简单数据为例):
数据1:q w e r t y u i o p
数据2:q w e r e y u i o p
如果要进行AND和OR过程的话,首先,
shingles1:qwe, wer, ert, rty, tyu, yui, uio, iop
shingles2:qwe, wer, ere, rey, eyu, yui, uio, iop
假设我们选取相邻的两个hash结果(注意这里没有重复)进行AND,则上述两个shingle变为下面的形式:
shingles1:{qwe, wer} {ert, rty} {tyu, yui} {uio, iop}
shingles2:{qwe, wer} {ere, rey} {eyu, yui} {uio, iop}
可以看到,这样的结果和
k
直接取4其实并没有什么太大的不同。
因此,对于这个应用来说,使用minhashing的效果其实课增加k的大小是没有区别的。(不对,还是有区别的,多了进行minhashing的计算量)
3 实际计算时内存的限制
这里只针对python进行求解的情况进行说明。
因为原始数据量非常大(其实也还好了,只是对于单机和32位的python编译器来说),在直接将所有数据读取到内存中时,不知道读取到什么程度的时候,程序就直接报Memory error了。原因如下:
32位的系统[3]:
windows下单个进程可以用到2G内存
linux下单个进程可以用到4G内存
(原谅我直接用百度搜索“python 内存限制”搜出的百度知道的结果作为参考文献)
所以,在进行实际的计算的时候需要考虑内存的限制。这里最直接的思路就是将原始数据分块,分别计算各个块内的相似项,然后再计算各个块之间的相似项。
这里,计算块与块之间的相似项时,注意不要进行重复计算就可以了。(就是算了数据块1与数据块2之间的相似项,接着马上有计算了数据块2与数据块1之间的相似项,切记)
问题解答
具体的数据和题目要求见[1]中的“Finding Similar Sentences (Optional programming assignment)”这个问题
最终的结果见[4]中Alper Halbutogullari的解答结果。
结果总结
自己按照上面所述的思路实现的一个运行结果如下:
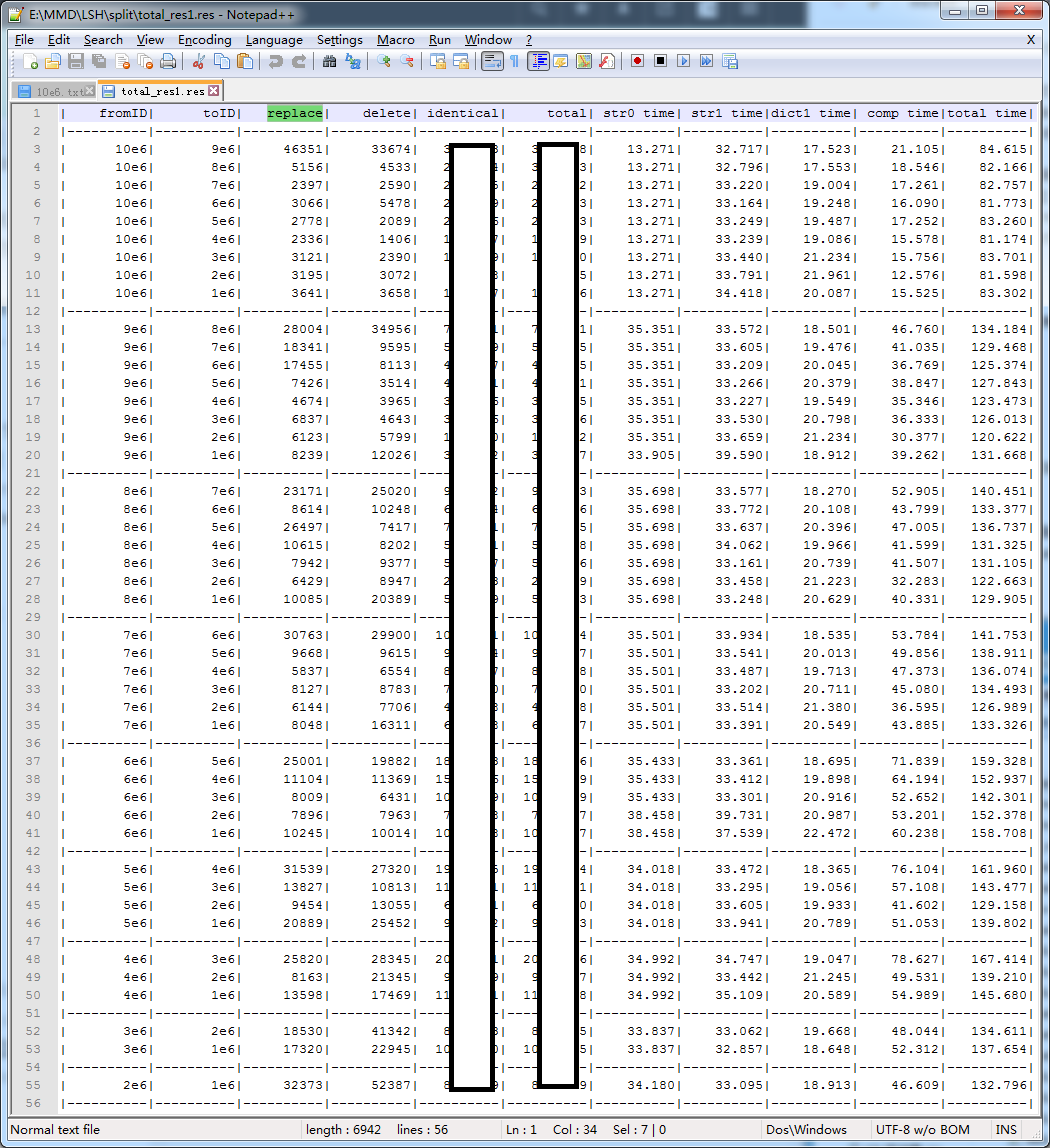
从运行结果中可知,我将源数据分成了10块。其中,total就是fromID和toID之间的相似项的结果(为了遵守Coursera上的Honor Code的要求,将部分结果隐藏了啊)。
replace表示两条数据之间经过一次replace后完全一致的数据pair数量;其余的同理。
str0 time是读取fromID源数据的时间,Str1是读取toID源数据的时间,dict1是将Str1中所有数据hash到不同桶中的时间。
comp time是计算相似项的时间(所有的时间单位均为秒)
total time是读取文件加上计算dict和相似项的总时间。
(下面的就不是直接从运行结果中看出来的了)
由于10e6中包含的数据条数是397’023,因此它的时间都相对较短,其余的*e6包含的数据条数均为1’000’000条,因此时间较长。可以看到,这里进行两个
参考文献:
[1] Coursera上《海量数据挖掘》所有练习
[2] Coursera上《海量数据挖掘》Week2的内容
[3] 百度知道上关于python内存限制的问答
[4] Coursera上《海量数据挖掘》寻找相似项的题目答疑


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









