







Evaluation这一讲介绍了关于推荐系统很多的Evaluation的方法。也从不同的应用角度(商业、科研、竞赛等等)分析了各种的方法适用的范围。主要内容如下:
不同的Evaluation的分类
不同的评估方法也分为好几类:基于精度的度量方式、基于支持决策的度量、基于排名的度量、基于用户中心的度量。
Accuracy metrics
这种度量方式主要分为:
MAE——Mean Average Error
MSE——Mean Squared Error
RMSE——Root Mean Squared Error
在使用上述的度量方式的时候,需要注意以下几点:
1.注意如何区分用户评分数量不同,或者说是已有评价信息中各个用户的参与度不同,或者就理解为用户评价正确性的重要性/权重不同;
2.在进行推荐算法的对比时,应该保证数据集的尺度(scale)一致——评分的范围相同,采用的数据集大小相近)
这类评价指标的优点:
三种方式可以互换
拥有很多已知的数据集
缺点就是有时候人们并不关心真正的error的取值大小,而只是关心这个item到底是好还是坏。通俗点说,这个指标与用户关心的东西还是有差距的。用户并不关心这个指标的绝对误差是多少,用户只关心这个东西是不是我想要的。
Decision-support metrics
这种度量方式的一个评判指标——通俗点说,就是把好的预测称坏的或者把坏的预测成好的次数,通常用出现前面那种情况的次数来衡量。
rehearsal
就是large mistake。具体含义,举个例子,就是在5分评分的系统中,预测值与真实值差3分就可以认为这是一个rehearsal。这种评价方式现在不怎么用了。
下面的提到的几个指标就要用下图来进行说明了:
| Real | 1 | 0 | Pred |
|---|---|---|---|
| 1 | TP | FN | |
| 0 | FP | TN |
其中,各个含义分别如下:
Real——真实的结果;Pred——预测的结果
P
——预测结果为真;
F
——预测结果错误;
因此,
TP
就表示预测结果为真且真实结果也为真;同理,
FP
就表示预测结果为真,但真实结果为假。其余类似。
precision
预测值中返回的东西有多大的比例是好的,这个值越大,说明预测的东西中有用的东西多。
recall
评价没有丢弃有用东西的比例,这个值越大,说明丢失的有用的东西越少。
F-metric
结合了precision和recall的优点。F值越大,说明预测的好的东西中,有很大比例是真正的好的;同时,在真正好的东西里面,预测它是好的比例也非常大。
上述评价指标的问题——需要全套完整数据;评价的是整个数据集的效果,但是我们通常关心的topN-》precision@n recall@n
Precision and Recall、ROC(指导思想:推荐好的,摒弃不好的)
ROC(Receiver Operating Characteristics)曲线
选用不同的阈值(就是不同的评分标准作为物品好坏的区分标准,这个值可以从1.0到5.0。比如阈值取2.5时,可以得到一组
TPR
和
FPR
,将不同阈值得到的点连成线,就得到了ROC曲线),绘制出的
TPR
(True Positive Rate)与
FPR
(False Positive Rate)的曲线。
其中,
TPR=TPTP+FP
,
FPR=FPFP+TN
AUC——Aera Under Curve
这里的Curve指得就是ROC曲线,而AUC就是在ROC曲线下面的面积。通过对比不同算法的ROC的AUC,可以对算法的结果进行一个评判。AUC越大,算法效果越好。

ROC曲线的一个很好的地方就是当训练数据中正负样本的分布发生变化时,ROC曲线基本保持不变。[2]
Rank Metric
顾名思义,Rank Metric就是关于预测排名与真实排名之间相差程度的度量了,有如下的几种度量方式:
Mean Reciprocal Rank、Spearman Rank Correlation、Discounted Cumulative Gain、Fraction of Concordant Pairs
Reciprocal rank
1i
, where
i
is the rank of the first ‘good’ item
具体而言,就是看真实排名在第一位的物品在预测排名中的位置,将此位置记为
Spearman Rank Correlation
其中, r1 是物品 i 的预测排名,
这种度量方式没有考虑排名顺序的影响,一般而言,排名越靠前的出现错误,对结果的影响越大。因此,预测排名越靠前的那些项的权重应该大,因此就有了下面的度量方式:
Discounted Cumulative Gain
基本思想——最终预测排名越靠前的物品所占的权重越大
或
其中, rperfect 指真实的排名; r 表示预测排名;
Fraction of Concordant Pairs
另一种维度,比较推荐的topN中的pairs的正确的数量。
即对于下表所示的排名结果,A-E,真实的排名结果为3,5,4,1,4,预测的排名结果为1,2,3,4,5。此时,对于预测结果与真实结果来说,任取两个结果,例如AB,此时,预测结果中A的排名在B之前,真实结果中A的排名在B之后,因此,这就是一对错误的结果。再看一对AE,真实结果和预测结果对这两个物品的预测结果是正确的,因此这就是一组正确的结果。而Fraction of Concordant Pairs就是找出正确的pair数占总pair数的比例。显然,比例越高,预测结果越接近于真实结果。
| item | A | B | C | D | E |
|---|---|---|---|---|---|
| prediction | 1 | 2 | 3 | 4 | 5 |
| real | 4 | 1 | 2.5 | 5 | 2.5 |
下图是一个包含了上述所有rank指标的一个例子:
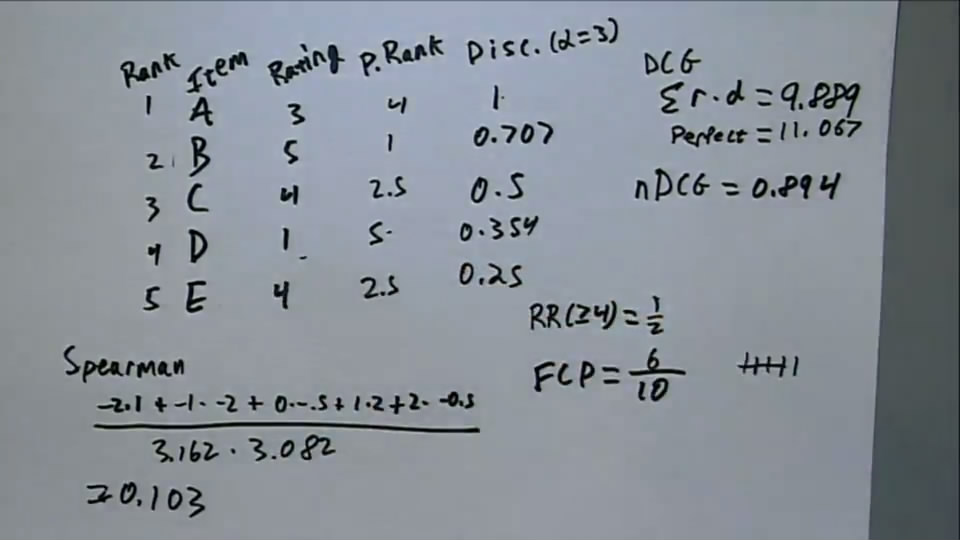
在该例子中,可以很好的说明
User and Usage-centered metrics
Coverage
对所有用户而言,预测结果集合数量占总物品数量的比例
Diversity
对单个用户来说,预测结果所涵盖的物品的种类的多少
Serendipity
这个比较难评估。叫做一见钟情。没太看明白怎么评估。
如何评价一个推荐系统
类似于机器学习中的cross validation
但是在应用时,是将用户对物品的评价做一个split,而不是简单的对用户进行split。进行split之后,可以计算出每个用户针对所有split的平均误差(前面所述的任意一种误差)然后再对所有用户的误差进行平均,就会得到最后的总的平均误差。
关于split,也有两种方式:
Random——对各个用户进行随机split
Time-based——挑选出用户最近评价的物品作为test set
Unary Data Evaluation
Unary Data,主要就是指二值数据。主要涉及的是用户产生的implicit数据。因此,这种评估主要是对implicit feedback data的一种评价,主要难点在于implicit,具体体现就是没有negtive的例子。
(有种情况下也算是有negtive data,就是在知道当时的context的情况下。比如已知有4个链接,排名分别为1234,用户最终点击的是3,就可以说明1,2是用户不喜欢的物品,就是negtive data。不过大部分时候是没有这种数据的)
对于Unary data,上面的一些评价标准是天生能够解决的。如下:
Precision/RecallMAP
Mean Reciprocal Rank
nDCG
存在的问题:总会存在未知物品推荐不到的问题
User-Centered Evaluation
主要是如何以用户为中心来评价推荐系统的好坏,对推荐系统进行评价的主要依据还是用户对系统的接受程度,主要有以下的几种方式:
Usage Logs
Polls, Surveys, Focus Groups
Lab (and online Lab) Experiments
Field Experiments and A/B Test















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









