







概述
很多大型企业有不少分厂, 或则由于数据吞吐量太大,采用多个结构相同的数据库服务器处理数据是一种常见的方法,各个数据库之间数据各自独立,种种原因,往往又有数据库合并的需求,涉及数据table往往几百甚至上千,数据库数据成千上亿.而合并过程中将会有大量的数据冲突.
分析
对于多个数据库合并,首先是统一最终数据结构,当然这里多个数据库数据结构大都相同,部分数据库有新增,删减,更改.导致有部分差异,那么怎么怎么决定最终结构这就是跟客户开会讨论的问题.
确定了最终数据库.那么我们便可以遍历所有服务器的数据库获得所有table name的list,直接插入数据,流程图如下

这里首先获得foreign key的意义在于给table的插入顺序排序,如果一个table有Foreign key,那么就需要确保foreign table导入顺序在先.
当然这完全是理想状态,假设各个数据库各个table没有重复的数据.(重复的数据意思是说primary key相同,不过也不一定是检查primary key.比如很多table 的primary key是id等现实中没有意义的信息,那么实际需要检查的key就需要在配置文件里额外设置) ,直接把所有的数据库insert到最终数据库就可以了,但这种情况显然不可能存在.
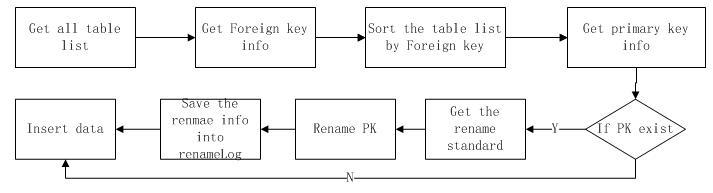
首先我们考虑一个底层table(意思就是table内数据完全是独立的,不存在foreign key),当不存在重复的数据时,直接插入,当已经存在的时候,那么就检查这2笔数据是否完全雷同(雷同的意思是说所有的column全部相同,当然有时候需要跳过某部分column的检查,比如lastupdate之类的信息,那么这就需要在配置文件里面额外设置了),如果雷同就跳过,如果不雷同的话就需要读取重命名规则根据规则重命名重复的数据,并插入table,并把重命名的信息写入renameLog 表,数据流程图如下
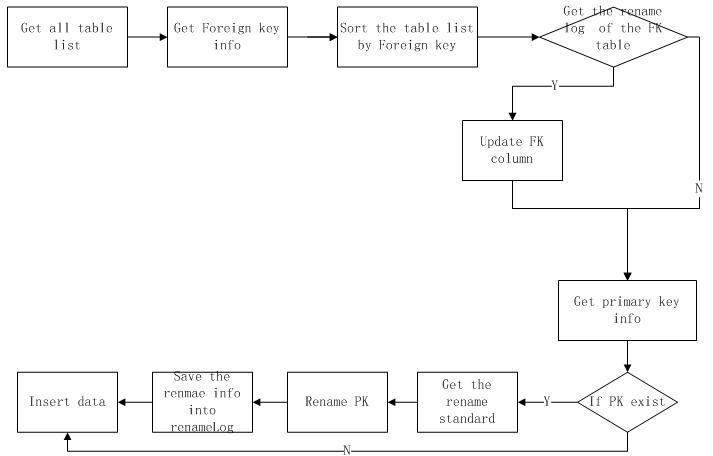
那么我们再考虑一个高层table(就是存在foreign key指向更低层的table),首先我们需要判断foreign key 的数据有没有变化,通过检查renameLog,当foreignkey的数据已经有变化的时候,那么我们就需要更新所有foreign key 数值.然后接下来的步骤就和底层table一样检查primary key,数据流程图如下.
设计
模块大致分为4部分,数据库连接,配置文件读写,数据逻辑模块,图形界面,这里给出简略的uml图表
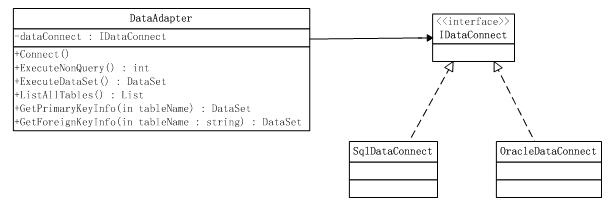
a:数据库连接,uml如下
b.配置文件读写,所有文件设置都保存为xml文档.uml如下:
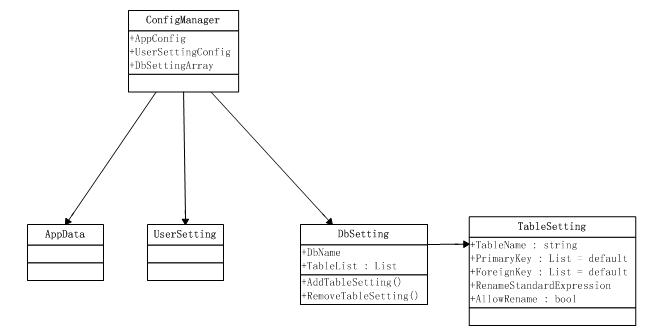
各个server数据库url,用户个人信息保存在userSetting config种
DbSetting/TableSetting config配置具体table的重命名策略,主键检查策略,外键检查策略.当数据合并的时候通过读取这些config配置来运用这些策略.每个db对应一个dbsettingConfig 文件.而具体config文件应该由UI动态生成.
c.数据逻辑
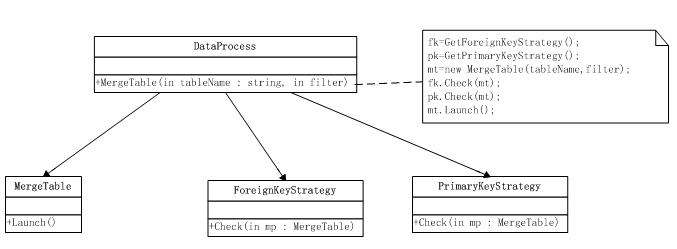
合并数据的方法可以先读取配置文件,获得相应的外键和主键策略.具体流程可以参考上面的流程图,uml如下.
d.UI
这个就见仁见智了,各个人ui各不相同,简单可以分为3部分
1:用户设置窗口
2:用户运行窗口(通过读取datatable,config文件 动态获得合并table 信息,提供交互界面)
3:dbsetting config编辑器,这个是给我们自己使用的配置文件编辑器
部分sql细节
这里以sql server为例
1 跨server的数据查询
a 首先用sp_addlinkedserver建立linked server, 语句如下:
exec sp_addlinkedserver
@server='srv_link ' --linked server name here
, @srvproduct='ms ' --product description
, @provider='SQLOLEDB ' --connect provider
, @datasrc='192.168.11.52 ' --data source
b 然后用sp_addlinedsrvlogin登陆,如果当前账号就有权限的话,可以直接用以下语句登陆
exec sp_addlinkedsrvlogin
@rmtsrvname=' srv_link ' --linked server name
,@useself='true ' --use current account
如果没有权限,那就需要填写用户账号信息,如下:
exec sp_addlinkedsrvlogin
@rmtsrvname='srv_link ' --linked server name
,@useself='false ' --not use self
,@rmtuser='testUser ' --username
,@rmtpassword='testPassword ' --userpassword
c 查询的时候table表示方式就是 [linkedServerName].[databaseName].dbo.[tablename],示例如下:
select * from srv_link .common.dbo.employee
注意:linkedserver不支持用[dbName]..[tbName]代替[dbName].dbo.[tbName]的表示方式.
2 .获取table的主键信息,语句如下:
declare @tbName varchar (20)
set @tbName='employee ' --here set the table name
select pk.name PK,tb.name tbName,col.name columnName,type_name(col.xtype) type,col.length
from sysobjects pk
,sysobjects tb
,syscolumns col
,sysindexKeys indexKey
,sysindexes indexes
where pk.xtype='PK'
and pk.parent_obj=tb.id
and col.id=tb.id
and indexKey.id=tb.id
and indexKey.colid=col.colid
and indexes.id=indexKey.id
and indexes.indid=indexKey.indid
and indexes.status between 2048 and 4095 --status in(2048,4095) means this index is primary key
and tb.name=@tbName
结果如下:
![]()
3 获取table的外键信息,语句如下:
declare @tbName varchar (20)
set @tbName='employee ' --here set the table name
select fk.name FK,tb.name tbName,col.name columnName,
rtb.name rtbName,rcol.name rcolumnName, type_name(rcol.xtype) type,rcol.length
from sysforeignkeys cons
,sysobjects fk
,sysobjects tb
,sysobjects rtb
,syscolumns col
,syscolumns rcol
where fk.id=cons.constid
and tb.id=cons.fkeyid
and rtb.id=cons.rkeyid
and col.colid=cons.fkey
and col.id=tb.id
and rcol.colid=cons.rkey
and rcol.id=rtb.id
and tb.name=@tbName
结果如下:
















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









