






 本文分享了一个利用Apache Hadoop集群存储和检索医学影像文件的替代方案,通过开源软件和行业标准服务器降低解决方案成本,实现高性能、低成本的分布式图像处理,适用于存储和管理大规模医学影像数据。
本文分享了一个利用Apache Hadoop集群存储和检索医学影像文件的替代方案,通过开源软件和行业标准服务器降低解决方案成本,实现高性能、低成本的分布式图像处理,适用于存储和管理大规模医学影像数据。
原文链接:Processing and Indexing Medical Images With Apache Hadoop and Apache Solr
作者:Justin Kestelyn
译者:郭芮(guorui@csdn.net)
你还在为大规模图像管理感到头疼吗?读下去,看看这个团队是如何使用开源产品来更有效地索引和存储高分辨率医学图像的。
时下,医学影像迅速地成为了一种评估病人状况,以及确定是否存在医疗条件的最好非侵入性方法。多数情况下,用来协助诊断的影像是构建现代医学体系的第一步,而成像技术的进步也使我们能够收集到更详细的、分辨率更高的2D、3D、4D以及显微图像,从而帮助更快诊断和治疗某些复杂的情况。
在现实生活中,人脑的高分辨率显微扫描大小可以达到恐怖的66TB。在一些3D模式的例子中(例如计算机断层扫描),每幅图像大约4MB(2048×2048像素)。就目前的情况来看,美国所有资源库中有大约750PB的医学影像,并且预计在2016年底能达到1EB的储存量。基于这样的事实,很显然可以预感到医疗成像必将成为一个大数据问题。
目前,图像存档和通信系统(PACS)已经成为了医学影像存储和文件检索的行业标准,提供了专用的数据格式和对象。而在这篇文章中,我们分享了一个替代性的解决方案用来存储和检索医学影像文件,它利用一个Apache Hadoop集群(CDH)提供高性能和具有成本效益的分布式图像处理,其优点包括:
- 让医学影像数据接近其他已经在使用的数据源,例如基因组学、电子病历、药品、穿戴设备数据等等,减少数据存储和迁移成本
- 通过使用开源软件和行业标准服务器降低解决方案成本
- 允许在同一个集群内结合其他形势的数据做医学影像分析
本文将努力重现英特尔的工作,并将此作为可以在CDH集群上利用Apache Hadoop和Apache Solr索引DICOM(Digital Imaging and Communications in Medicine)图像,并实现存储、管理和检索功能的佐证。
解决方案概述
下面就来关注一个简单但重要的示例:存储和检索DICOM图像的能力,并且这个用例不依赖于其他现有的影像库。医院和成像设施将DICOM图像的副本发送到本地与HIPPA兼容的云或托管服务器集群并存储。在需要时,医生或护理者应该能够从连接到远程集群的本地机器上查看、搜索和检索病人的DICOM图像,如图1所示。
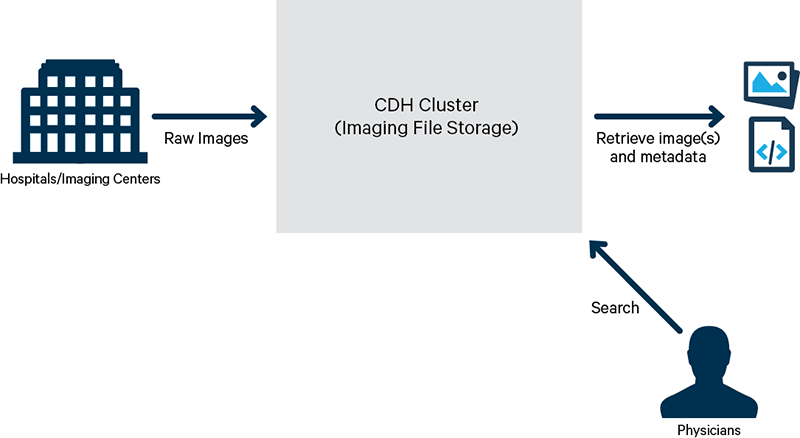
详细说明
DICOM图像包含两个部分:文本标题和二进制图像。要确保图像是像图2和图3所示的那样可存储和可被搜索,需使用下面几个步骤。
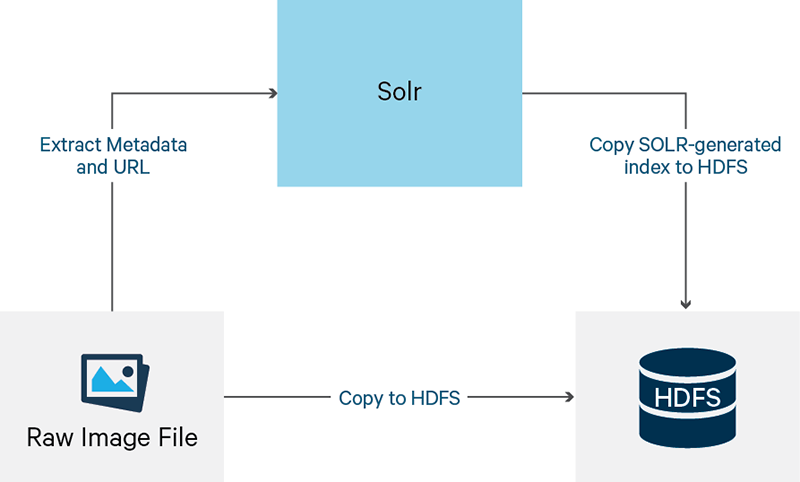
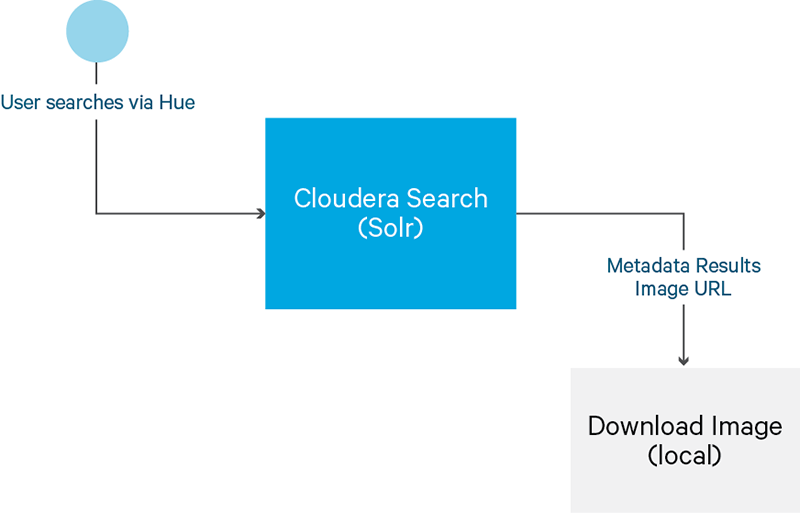
要注意,图2是从软件开发人员的角度来分析,而图3则是终端用户和解决方案交互的角度。作为软件开发人员我们必须亲身经历这个过程,来为最终用户更好地验证功能。
1、从DICOM图像中提取元数据。
2、HDFS中存储原始的DICOM图像。
3、利用元数据生成一个索引文件(也将被存储在HDFS里面)。
4、搜索使用Hue接口来检索图像。
5、下载图片到本地系统并使用DICOM查看器打开视图。
与高性能服务器节点的成本相比,行业标准服务器在性能和存储上更具灵活性。我们的服务器节点采用双CPU结构的英特尔至强E5家族处理器,4TB×12(48TB)存储和192GB内存。在必要时处理和存储的需求可以通过横向扩展来满足——即增加集群中的节点数。
系统设置和配置
以下是我们测试6节点CDH集群和1个边缘节点的关键指标。

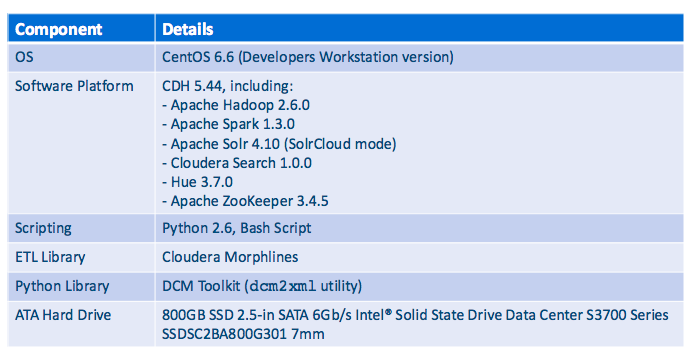
软件需求
为了测试这个解决方案,我们启用Cloudera管理器中的CDH5.4服务:
HDFS
- 存储需要被索引的DICOM XML文件
- 输出索引结果并存储
Apache Solr (Solrcloud模式)
- 通过SCHEMA.XML索引给定的DICOM XML文件
Apache ZooKeeper
- 在SolrCloud模式下使用ZooKeeper实现分布式索引
Hue(启用搜索特性)
- 在图形界面查看Solr的索引结果,也可以搜索基于索引字段的DICOM图像
Cloudera搜索
- 通过MapReduceIndexerTool做索引的离线批处理
数据集
我们的测试数据包含了从Visible Human Project下载的DICOM CT图像。
工作流
图4描述了工作流路径。
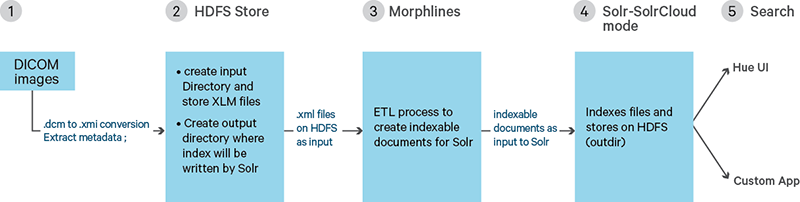
第1步:将所有的DICOM图像都存储在本地文件夹,然后使用DCM工具包(DCMTK)与dcm2xml功能从图像中提取DICOM元数据,并将其以XML格式存储。(参见附录1中的例子。)
Example: dcm2xml <input-file-path> <output-file-path>
./dcm2xml source.dcm source.xml
在上面的例子中,要想运行dcm2xml功能,必须事先在本地机器上下载好DCMTK,然后在.bashrc中设置如下路径。
Example: export DCMDICTPATH=”/home/root/Dicom_indexing/dicom-script/dcmtk-3.6.0/s
第2步:将已转换的DICOM图像导入到HDFS的at/user/hadoop/input-dir和create/user/hadoop/output-dir中并存储索引结果。
第3步:做ETL处理。这一步建议使用Morphlines配置文件,然后按照要求解析和提取所需内容并同时为Solr建立可索引文件。
第4步(参见下列过程):利用Solr中的schema.xml配置,从给定的XML文件字段中建立索引,同时还可以将MapReduceIndexerTool用于离线批处理索引。(见附件2)。
首先,请确认Solr服务(以SolrCloud模式)在集群上成功启动并运行(访问http://<your –solr-server-name>:8983/solr)。
然后使用solrctl生成配置文件,包括要索引的schema.xml字段(使用 - ZK选项将提供ZooKeeper的主机名,还可以在Cloudera Manager’s ZooKeeper中发现这个信息)。但是要注意IP地址的最后一项需要ZooKeeper端口,而且ZooKeeper主机IP会代替主机IP。
solrctl instancedir –zk hostip1,hostip2,hostip3:2181/solr –generate HOME/solr_config/conf
接下来需要在本地计算机中下载schema.xml文件并进行编辑,包括要索引的所有字段名,且字段名称要与XML索引文件的名称属性相匹配。这个例子中,DICOM XML文件仅需要索引成百上千个字段中的10-15个字段,同时还要记得将修改的schema.xml文件在/ conf文件夹中更新(见附录1查看生成的DICOM XML文件,见附录2查看定制的schema.xml文件)。
清理所有的收藏栏和现有的ZooKeeper实例目录:
solrctl --zk hostip1,hostip2,hostip3:2181/solr instancedir --delete demo-collection >- 上传Solr配置到SolrCloud。
solrctl –zk hostip1,hostip2,hostip3:2181/solr instancedir –create <strong>demo-collection</strong>$HOME/solr_configs
- 创建一个命名为demo-collection的Solr集合,-s2则表示该集合有两个碎片。
solrctl –zk hostip1,hostip2,hostip3:2181/solr collection –create demo-collection -s 2 -r 1 -m 2
- 创建一个空白目录,并将MapReduceBatchIndexer结果写到里面。
hadoop fs -rm -f -skipTrash -r output-dir
hadoop fs -mkdir -p output-dir
ETL再次处理,建议使用Morphlines配置文件(见附录3)。
利用MapReduceIndexerTool索引数据并现场演示,而且${DICOM_WORKINGDIR}所在的位置还可以找到log4j.properties和morphlines.conf。
[Math Processing Error]{HDFS_DICOM_INDIR} – Location of input dir folder on hdfs (ex: /user/hadoop/input-dir/)
- Solr会在上面所创建的输出目录中存储索引结果。
第5步:利用Hue查看索引结果;DICOM影像URL可用于本地下载以供观看。
测试
测试索引结果首先需要登录Hue界面(假设已获得并启用了Hue的搜索功能。)
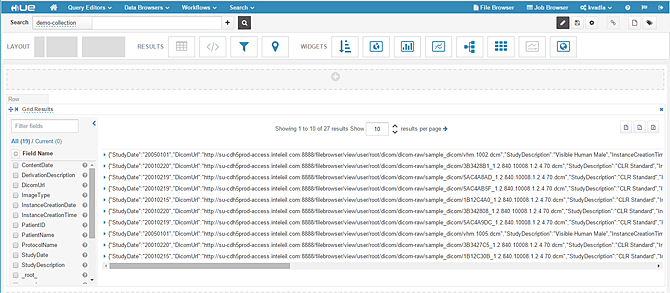
1、点击搜索和导航>索引>演示系列>搜索。下面是索引结果的默认视图。
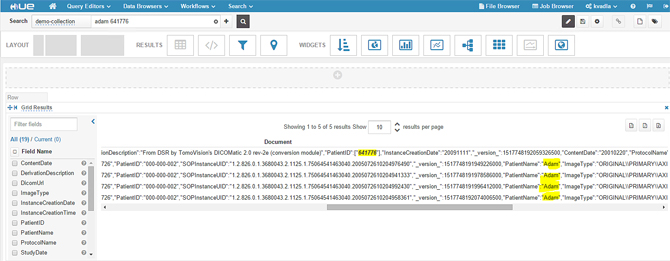
2、键入一位病人的姓名或身份证号,也可以是其他任何已编入索引的字段数据。在这个例子中,下面截图显示的是一位病人的名字和其他标识。
3、当你展开一个单一结果时,可以看到如下图所示的元数据字段。
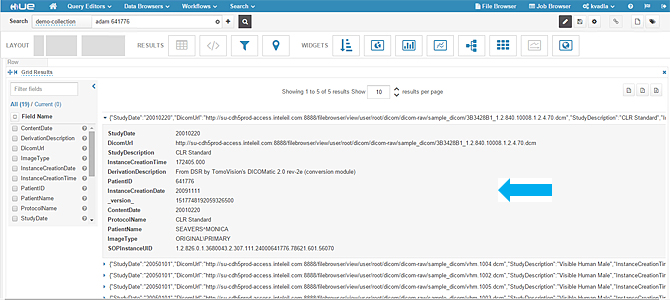
4、上面图片中的DICOM URL点击无效,所以要使用Hue中的图形控件创建一个良好的仪表板并添加一个可点击的URL。
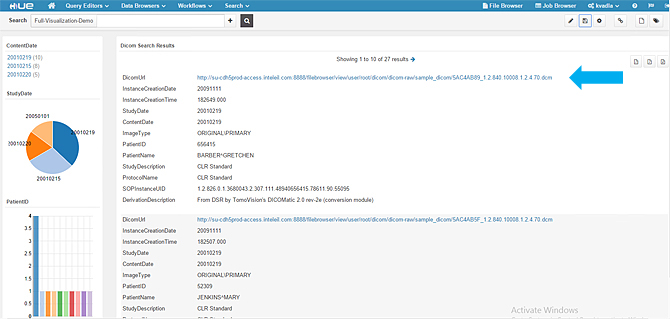
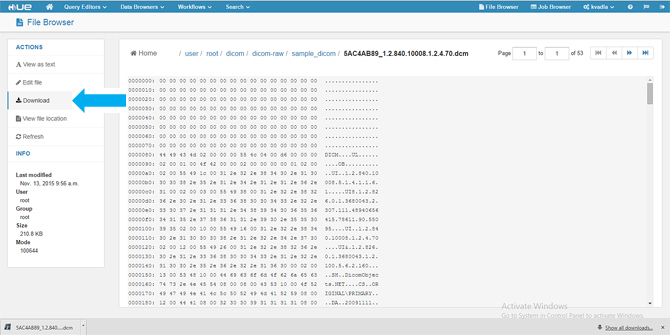
5、点击DICOM的URL ,可以选择将.dcm文件下载到本地计算机。在该版本中我们将它下载到本地计算机中,并用名为MicroDicom Viewer的开源工具查看。
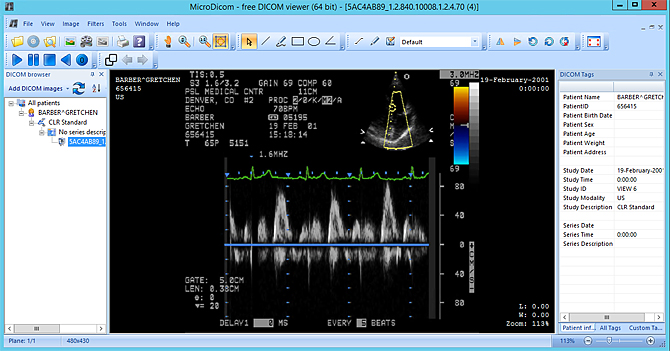
6、使用MicroDicom Viewer查看图像。
未来工作
我们计划继续开发这个参考架构,在此基础上利用插件提供更精简的方法,并力争做到允许用户直接下载浏览器内的DICOM文件。我们也将致力于更好的可视化能力研究,来支持多个图像同时下载。
文章贡献者:
KARTHIK Vadla,供职于Intel,Big Data Solutions Pathfinding Group部门软件工程师。
Abhi Basu,供职于Intel,Data Solutions Pathfinding Group部门软件架构师。
Monica Martinez-Canales,供职于Intel,Data Solutions Pathfinding Group部门首席工程师。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









