







现状:基于 mxnet 开发的深度学习应用比 tensorflow 等框架 占用的显存更少、运行更快;
mxnet 官方网站有一篇文章介绍了 mxnet 在显存方面的优化,以下概括大意:
- 使用同一个图去计算前向预测和反向传播还是显式地指定反向传播路径?Caffee,CXXNet,Torch 选择了前者,Theano,CGT,mxnet 选择了后者,同时 mxnet 也支持类似前者的情况;使用后者的好处是,对于反向计算不需要用到的节点可以在前向运算后就回收显存,另一个好处是可以灵活设置反向路径,不必和前向一致;
- In-place 内存复用:在计算过程中让某些节点使用同一块显存,而不是为每一个节点单独分配,前提是这块显存不会被同时使用;
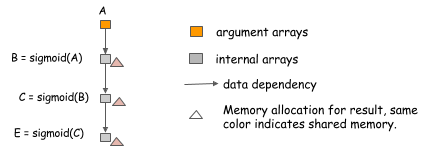
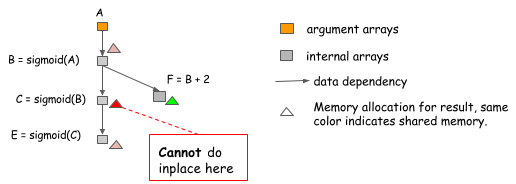
- 内存分配算法:原则是“allow memory sharing only between variables whose lifetimes don’t overlap”,与2描述类似
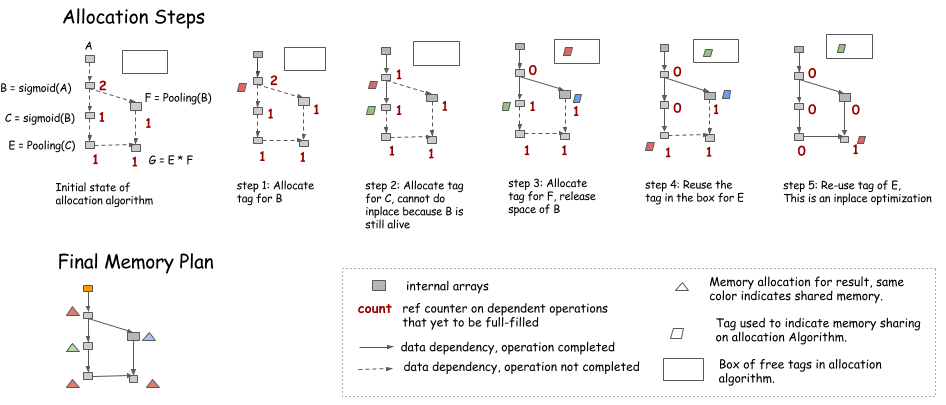
- 带引用计数的动态分配方式;
- 内存共享和并行运算是一对矛盾,确保计算结果的正确性和安全性是首选,也就意味着在确保并行计算的同时可能会没法通过共享显存来降低显存占用;
- 一种方法是计算图中的最大路径来确定哪些节点可以共享内存;
- 在仅做前向计算的情况下,因为内存复用,可以更大地减少显存占用;
反观 tensorflow 什么的就差多了,甚至要等到整个进程退出才释放显存
附一篇有点过时的文档 mxnet-learning-sys.pdf















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









