







引言
在网络传输的过程中,经常会使用UTF-8编码,以避免乱码的问题。另外,我们使用文本编辑器编辑文件的时候,也可以选择诸如ANSI、Unicode、UTF-8等多种编码方式。那么,各种编码方式之间有什么区别呢?
ASCII编码
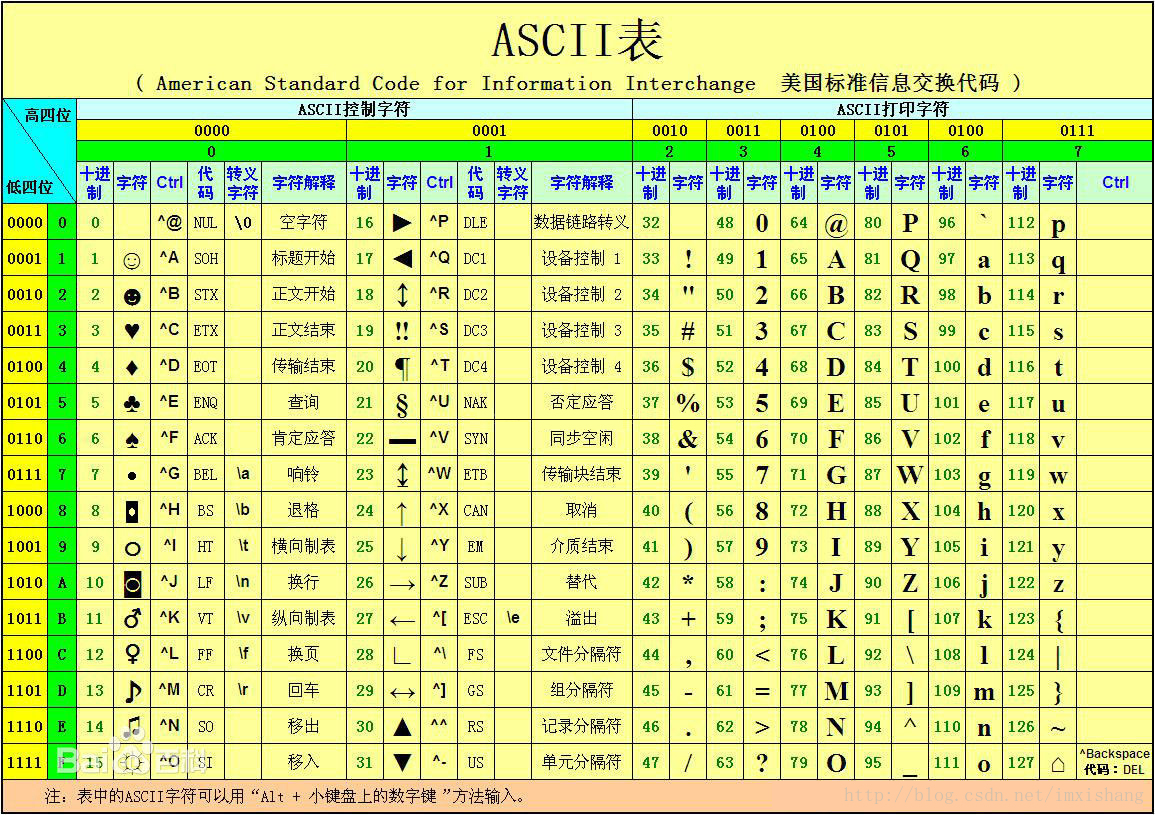
对于计算机来说,所有的文件都是以二进制的格式存储的。所谓编码,就是将二进制位映射到字符集的过程。计算机最早起源于美国,当时他们制定了一套字符编码,将英语字符到二进制位之间的关系,做了统一规定,称为 ASCII码。ASCII码规定,0x20(十进制32)以下的字节码称为“控制字符”,分别规定了特殊的用途;0x20到0x7F的字符称为“打印字符”。ASCII编码只使用一个字节的低7位。
ASCII码表:
非ASCII编码
ASCII码只能用来编码英文字符,各个国家为了表示他们自己的字符,分别扩展了ASCII码。
ISO8859
欧洲码表,单字节编码,包含一系列标准,如:ISO8859-1(西欧字符集)、ISO8859-2(东欧字符集)等
编码规则:
- 与 ASCII 相容,所有的低位皆不使用
- 高位中的前 32 个码位 (0x80 – 0x9F 或 128–159),保留给扩充定义的 32 个控制码,称为 C1 控制码 (0–31 称为 C0 控制码)
- 高位中第 33 个码位 (0xA0 或 160),也就是对应 ASCII 中 SP (空格) 的码位,总是代表 Non-breakable space,也就是不准许折行的空格
- 每个字符集定义至多 95 个字符,其码位都在 0xA1 – 0xFF 或 161–255
- 每个字符集收录欧洲某地区的共同常用字符,如:ISO8859-1
GB系列编码
汉字编码GB2312、GBK和GB18030,扩展了ASCII码的高位字节,并使用两个字节来进行编码。从ASCII、GB2312、GBK到GB18030,这些编码方式是向下兼容的,但是不同国家之间的字符编码各不相同。为了统一字符编码,ISO (国际标准化组织)发布了俗称“UNICODE”的编码规范。
Unicode
Unicode的学名是“Universal Multiple-Octet Coded Character Set”,简称为UCS,UCS可以看作是”Unicode Character Set”的缩写。
UCS有两种格式:UCS-2(两个字节编码)和UCS-4(四个字节编码),其中UCS-4实际上只用了31位,最高位必须为0。
UCS-4根据最高位为0的最高字节分成2^7=128个group,每个group再根据次高字节分为256个plane,每个plane根据第3个字节分为256行 (rows),每行包含256列(cells)。
group[0]的plane[0]被称为“Basic Multilingual Plane”,即BMP。也就是说UCS-4中高两位字节为0的码位被称作BMP,即:将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
除了ASCII编码之外,Unicode在制订时没有考虑与任何一种现有的编码方案保持兼容,因此GBK与Unicode在汉字的内码编排上完全是不一样的。
UTF-8和UTF-16
Unicode只是规定了字符的编码方式,UTF-8(UTF-16)是实现Unicode的一种用于传输的编码规范。UTF-8编码规则
- 使用单字节编码,字节的第一位为0,后面7位为这个符号的Unicode码。因此对于英文字符,UTF-8编码和ASCII码是相同的
- 使用n字节编码,第一个字节的前n位都为1,第(n+1)位为0,后面(n-1)字节的前两位都为“10”
UCS-2与UTF-8编码对照:
| UCS-2编码(16进制) | UTF-8编码(二进制) |
|---|---|
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
UTF-16
UTF-16以16位为单元对UCS进行编码,对于小于0x10000的UCS码,UTF-16编码就等于UCS码对应的16位无符号整数。对于不小于0x10000的UCS码,定义了一个算法。由于实际使用的UCS-2,或者UCS-4的BMP必然小于0x10000,因此可以认为UTF-16和UCS-2基本相同。但UCS-2只是一个编码方案,UTF-16却要用于实际的传输,所以就不得不考虑字节序的问题。
UTF的字节序和BOM
UTF-8以字节为编码单元,因此没有字节序的问题;而UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序,即大端法(Big endian)还是小端法(Little endian)。
Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。在UCS编码中有一个叫做“ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF,而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”,这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EFBBBF,所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
BOM作为一种标记方式,并不是强制要求的
| BOM | 编码方式 |
|---|---|
| EF BB BF | UTF-8 |
| FF FE | UTF-16/UCS-2, Little endian |
| FE FF | UTF-16/UCS-2, Big endian |
| FF FE 00 00 | UTF-32/UCS-4, Little endian |
| 00 00 FE FF | UTF-32/UCS-4, Big endian |
为什么网络传输时常使用utf8编码
- utf8具有较好的容错性,从utf8字节流任何一个地方截断都可以跳过非法的部分找到下一个字符的开头,如果采用unicode编码,从一个字的中间截断会导致接下来所有的字符解析都是错的,这在不可靠的网络传输中是有利的
- utf8是变长的,对于常用字符,只使用一个字节编码,可以有效节省存储空间或带宽
ANSI
Windows系统中,记事本的编码默认是ANSI,代表系统默认编码,在中文系统中一般是GB系列编码。
JVM采用的改进版的UTF-8格式
与“标准”的区别:
- “null”字符((char)0)用双字节编码,而不使用单字节,因此改进版的UTF-8格式不会直接出现null值
- 改进版的UTF-8只使用标准版UTF-8格式所定义的单字节、双字节和三字节格式,JVM不能识别标准版UTF-8定义的四字节格式,而是使用自定义的两个三字节格式来代替,且按照Big-Endian顺序存储
改进版UTF-8编码方式:
| 字节数 | 位模式 | 码点值 | 范围 |
|---|---|---|---|
| 单字节 | 0xxxxxxx(x) | x&0x7f | 0001 - 007F |
| 双字节 | 110xxxxx(x) 10xxxxxx(y) | ((x&0x1f)<<6) + (y&0x3f) | 0080 - 07FF |
| 三字节 | 1110xxxx(x) 10xxxxxx(y) 10xxxxxx(z) | ((x&0xf)<<12) + ((y&0x3f)<<6) + (z&0x3f) | 0800 - FFFF |
| 六字节 | 11101101(u) 1010xxxx(v) 10xxxxxx(w) 11101101(x) 1011xxxx(y) 10xxxxxx(z) | 0x10000 + ((v&0xf)<<16) + ((w&0x3f)<<10) + ((y&0xf)<<6) + (z&0x3f) | U+FFFF |
参考资料:
http://pcedu.pconline.com.cn/empolder/gj/other/0505/616631_1.html















 4544
4544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









