







字符串
字符串是零个或多个字符组成的有限序列。字符串匹配是算法中的常见问题之一。
字符串也和线性表一样,有顺序存储和链式存储两种方式。顺序存储为预定义大小的定长数组,字符串终结为“\0”,(可存储在堆上,用C语言的malloc和free、C++的new和delete);链式存储也成立,只要每个数据元素都是一个字符char,但这种方式不灵活,效率不高。
子串在主串的定位操作叫作串的模式匹配。它比一般的字符串操作要有用的多,所以重要呢。
朴素的模式匹配算法
思想:子串沿着主串单步移动。
若主串长m,子串长n,最好的情况是一开始就匹配成功,时间复杂度为O(m+n);最差的情况是每次都是n的最后一位让匹配失败,时间复杂度是O((m-n+1)*n)。所以这个算法比较低效。
#include <iostream>
#include <string>
using namespace std; //string类型在C++定义,C语言没有
/*返回子串T在主串S中的位置,不存在则返回0*/
int Index(string S, string T)
{
int i = 0;
int j = 0;
int lenS = S.length();
int lenT = T.length();
while (i<(lenS-lenT+1) && j<lenT)
{
if (S[i] == T[j])
{
++i;
++j;
}
else
{
i = i - j + 1; /*S的指针退回并移一位*/
j = 0;
}
}
if (j >= lenT)
return i - lenT; /*S中第i-lenT+1个元素*/
else
return 0;
}KMP模式匹配算法
思想:根据子串每一位的相同前后缀计算出一个数组 next,用它来控制子串在主串上的移动,提高效率。省掉了很多次重复的比较。
next 的计算:
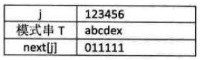



以第一行第二个为例,next[1]=0;next[2]=1,因为左边是a没有重复前后缀;next[5]=2,因为左边abca有长度为1的重复前后缀a;next[6]=3,因为左边abcab有长度为2的重复前后缀ab。以此类推。
(程序里j从0开始)
#include <iostream>
#include <string>
using namespace std;
void generateNext(string T, int *next)
{
int i = 0;
int j = 0;
next[i] = 0;
int lenT = T.length();
while (i < lenT)
{
if (j == 0 || T[i] == T[j - 1]) /*T的相邻元素相等,也就是有前后缀相等*/
{ /*T[i]相当于后缀,T[j-1]相当于前缀*/
++i; /*j==0条件补充了j-1<0的情况*/
++j;
next[i] = j;
}
else
{ /*T相邻元素不相等时,让T[j-1]向前回溯,T[i]保持原位不变*/
j = next[j - 1]; /*向前回溯,可能回溯到j=0或T[i]=T[j-1]*/
}
}
}
/*除了计算next,与朴素匹配规则差不多*/
int indexKMP(string S, string T)
{
int i = 0;
int j = 0;
int lenS = S.length();
int lenT = T.length();
int next[255];
generateNext(T, next);
while (i < (lenS - lenT + 1) && j < lenT)
{
if (j == 0 || S[i] == T[j]) /*比朴素匹配增加了j=0判断,因为next[0]=0,防止死循环*/
{
++i;
++j;
}
else
{
j = next[j]; /*j回到合适的位置,i不变*/
}
}
if (j >= lenT)
return i - lenT; /*S中的索引*/
else
return 0;
}
改进KMP模式匹配算法
思想:子串里有重复字符(不是说重复前后缀)时,仍然有多余的比较,所以还可以改进一下 next 的计算。


以第一个为例,next[1]=0;next[2]=1,因为当前字符b和前缀a不相等;next[3]=0,因为当前字符a即T[3]和前缀字符a即T[1]相等(因为几次回溯使T[j]返回到了T[1],也就是回到了第一个判断的j=0情况);next[4]=1,因为当前字符b即T[4]和字符T[2]相等(因为回溯使T[j]返回到了T[2],也就是回到了第一个判断的T[i]=T[j]情况)
(程序里j从0开始)
#include <iostream>
#include <string>
using namespace std;
void generateNext(string T, int *next)
{
int i = 0;
int j = 0;
next[i] = 0;
int lenT = T.length();
while (i < lenT)
{
if (j == 0 || T[i] == T[j - 1])
{
++i;
++j;
/*改进的地方,加快T的移动速度*/
if (T[i] != T[j - 1]) /*和上面的if不同,这里是+1后的当前字符与前缀字符,此时前缀字符未必是邻位的*/
next[i] = j; /*不相等的话按正常的KMP来*/
else
next[i] = next[j - 1]; /*相等的话,就把前缀字符的next拿来*/
} /*解释:前缀的next比较小,T[j]回溯的时候就更靠前,而S[i]又不变,意味着T移动步数多了,也就是移得快了*/
else
{
j = next[j - 1]; /*向前回溯*/
}
}
}
int indexKMP(string S, string T)
{
int i = 0;
int j = 0;
int lenS = S.length();
int lenT = T.length();
int next[255];
generateNext(T, next);
while (i < (lenS - lenT + 1) && j < lenT)
{
if (j == 0 || S[i] == T[j])
{
++i;
++j;
}
else
{
j = next[j]; /*j回溯到合适的位置,i不变*/
}
}
if (j >= lenT)
return i - lenT; /*S中的索引*/
else
return 0;
}















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









