







前言
Python文件默认的编码格式是ascii ,无法识别汉字,因为ascii码中没有中文。
所以py文件中要写中文字符时,一般在开头加 # -*- coding: utf-8 -*- 或者 #coding=utf-8。
这是指定一种编码格式,意味着用该编码存储中文字符(也可以是gbk、gb2312等)。
关于测试的几点注意 ------------------------------------------------------------------------------------
注1:代码中有中文,就要在头部指定编码方式,如果用编辑器写代码,还要注意IDE的文件存储编码格式(一般在setting)
注2:python3.x的源码文件默认使用utf-8编码,可以解析中文,开头不指定也行,但为了规范和避免一些意想不到的问题,都指定一下为好
注3:linux交互式命令(左)和py文件(右)的运行结果会有不同:
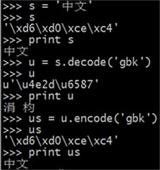
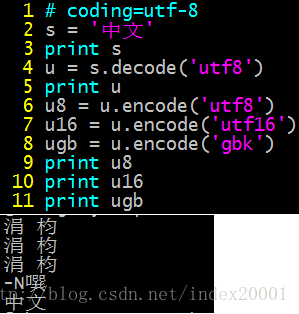
左图,因为我cmd设置了gbk编码格式,所以u是s用gbk解码后的unicode对象,配套的解编码才能使原中文字符在print下正常显示,所以再用gbk编码;右图,py文件指定了utf8编码,所以u是s用utf8解码后的unicode对象(其他方式会运行错误),而且想要在屏幕上打印出中文,还须encode成cmd设置的编码(其他方式显示乱码)。
注4:测试中文字符的显示和匹配时,最好用py文件写,否则遇到两边不一样的情况就会感到十分坑爹
-----------------------------------------------------------------------------------------------------------
下面实验是基于python2.7和linux系统,不测试windows控制台和windows下的IDE;
下面实验是关于为了正常显示中文和正则匹配中文的转码测试。
(一)python的str和中文字符串
简单理解,编码意味着 unicode -> ch-str,解码意味着 ch-str -> unicode,
关于print显示中文。举个例子,用gb18030和utf-8编码的内容相同的两份文档测试:
#coding=utf-8
import sys
with open('ch_input_gbk', 'r') as f1, open('ch_input_utf', 'r') as f2:
for l1 in f1:
lines = l1.strip().split('\t') # lines是list, 通过打印它可以看看str不同编码的内容
sent = lines[0] # sent是ch-str
print lines, sent
for l2 in f2:
lines = l2.strip().split('\t')
sent = lines[0]
print lines, sent
print sent.decode('utf8').encode('gbk')
#print str(sent).decode('string_escape').decode('utf8').encode('gbk')输出:
['\xd3\xc4\xc8\xcb\xd6\xf1\xc9\xa3\xd4\xb0'] 幽人竹桑园
['\xb9\xe9\xce\xd4\xbc\xc5\xce\xde\xd0\xfa'] 归卧寂无喧
['\xce\xef\xc7\xe9\xbd\xf1\xd2\xd1\xbc\xfb'] 物情今已见
['\xb4\xd3\xb4\xcb\xd3\xfb\xce\xde\xd1\xd4'] 从此欲无言
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1807
1807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









