







 本文是关于数据压缩的实验报告,重点探讨了Huffman编解码算法的实现细节。在实现过程中,使用二叉树表示编码,节点包含概率信息、节点类型以及子节点信息。由于Huffman码为变长码,采用指针存储码字序列,并记录比特位数。实验涵盖了从读入文件、构建码树、编码文件到解码文件的完整流程。
本文是关于数据压缩的实验报告,重点探讨了Huffman编解码算法的实现细节。在实现过程中,使用二叉树表示编码,节点包含概率信息、节点类型以及子节点信息。由于Huffman码为变长码,采用指针存储码字序列,并记录比特位数。实验涵盖了从读入文件、构建码树、编码文件到解码文件的完整流程。
一、实验原理
哈夫曼编码(Huffman Coding),又称霍夫曼编码或最佳码,是可变字长编码(VLC)的一种,属于无损压缩。该方法完全依据字符出现概率来构造码字,出现概率大的符号码长短,概率小的码长大,能有效的减小码长,对于概率分布相差大的信源压缩效率高,而对于接近于等概分布的信源压缩效率低。
1)统计个符号出现的次数,按照它们出现的概率并从大到小依次排列。
2)每次取概率最小的两个节点,合并概率,生成父节点,用父节点代替这两个子节点重新排序,直到根结点。
3)分配码字,二叉树的左节点为0,右节点为1,从根到叶子结点遍历得到码字。
二.实验步骤
哈夫曼编码(Huffman Coding),又称霍夫曼编码或最佳码,是可变字长编码(VLC)的一种,属于无损压缩。该方法完全依据字符出现概率来构造码字,出现概率大的符号码长短,概率小的码长大,能有效的减小码长,对于概率分布相差大的信源压缩效率高,而对于接近于等概分布的信源压缩效率低。
实际实现中常用二叉树来表示编码过程,节点需要表示的信息有它的概率;它是否为叶子节点,不是则表示是一个中间节点,它有左右子节点,是叶子结点则有一个符号;它的父节点用于建立码树。 由于huffman码为变长码,不能事先预留空间,所以用指针来表示它的码字序列,还需指出它所用的比特位数,为了后续输出码表还添加了概率。
每个节点的数据结构为:
typedef struct huffman_node_tag
{
unsigned char isLeaf;//是否为叶子结点
unsigned long count;//该符号的个数
struct huffman_node_tag *parent;//指向父节点的指针
union
{
struct
{
struct huffman_node_tag *zero, *one;//子节点
};
unsigned char symbol;//符号
};
} huffman_node;
typedef struct huffman_code_tag
{
//add by zhn
int count;//出现频率
//end add
/* The length of this code in bits. */
unsigned long numbits;//比特位数
unsigned char *bits;//比特流
} huffman_code;
1)统计个符号出现的次数,按照它们出现的概率并从大到小依次排列。
2)每次取概率最小的两个节点,合并概率,生成父节点,用父节点代替这两个子节点重新排序,直到根结点。
3)分配码字,二叉树的左节点为0,右节点为1,从根到叶子结点遍历得到码字。
二.实验步骤
1.Huffman编码流程
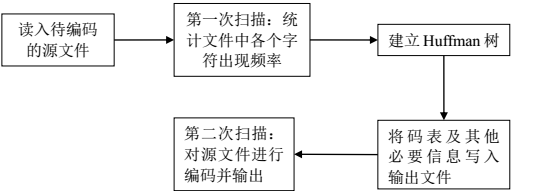
①读入文件
char memory = 0;//memory为1表示对内存编码
char compress = 1;//compress为1表示压缩,为0是解压
int 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5919
5919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









