







一.实验原理
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
二.实验流程
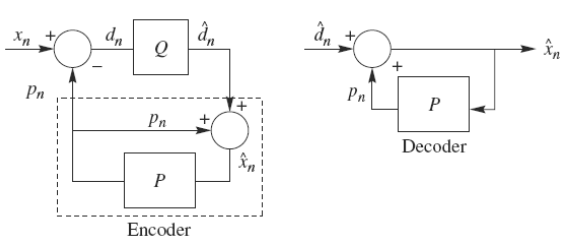
三.实验关键代码
在BMP2YUV实验代码的基础上添加以下代码
CJ = (unsigned char *)malloc(frameWidth * frameHeight);
WC = (unsigned char *)malloc(frameWidth * frameHeight);
int m,n;
unsigned char *py,*pcj,*pwc,*pu,*pv;
py=yuv.Y;pcj=CJ;pwc=WC; pu=yuv.U;pv=yuv.V;
for(m=0;m<frameHeight;m++)
{
for(n=0;n<frameWidth;n++)
{
if(n==0)
{
*pcj=128; //第一列的预测值为128
if((*py-*pcj)/2+128>256) *pwc=256;//把范围固定在0~256,进行量化
else if((*py-*pcj)/2+128<0) *pwc=0;
else *pwc=(*py-*pcj)/2+128;
py+=1;pcj+=1;pwc+=1;
}
else
{
if((*py-*(pcj-1))/2+128>256) *pwc=256;//把范围固定在0~256,进行量化,计算误差
else if((*py-*pcj)/2+128<0) *pwc=0;
else *pwc=(*py-*(pcj-1))/2 + 128;
*pcj= ((*pwc-128)*2)+*(pcj-1);//重建
py+=1;pcj+=1;pwc+=1;
}
}
}把两个块数据写入文件
fwrite(CJ, 1, frameWidth * frameHeight, chongjianFile);
fwrite(WC, 1, frameWidth * frameHeight, wuchaFile);四.实验结果
原始图现象,重建图像,预测误差图像
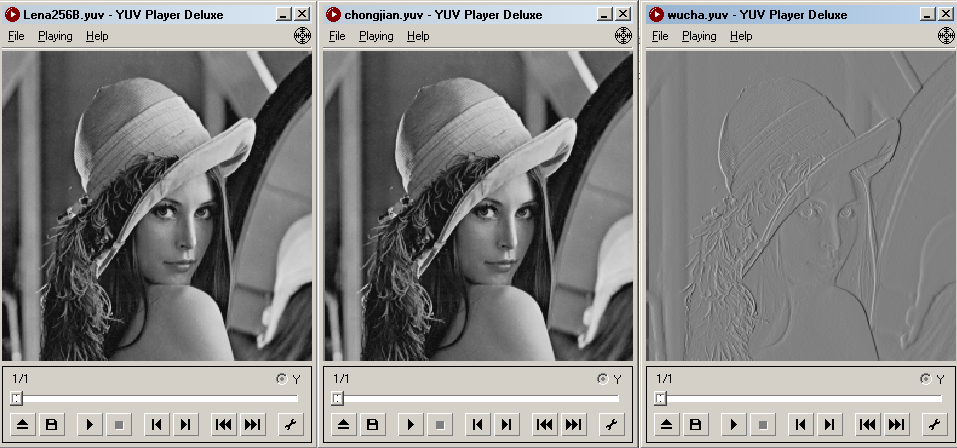
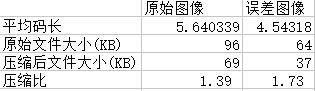
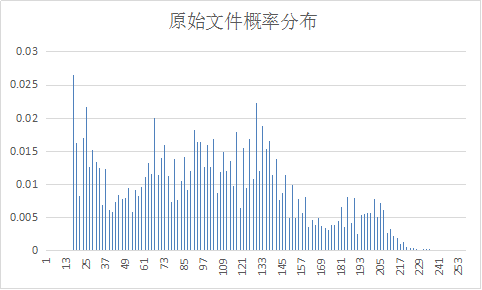
将三个文件用Huffman进行熵编码,得到以下数据
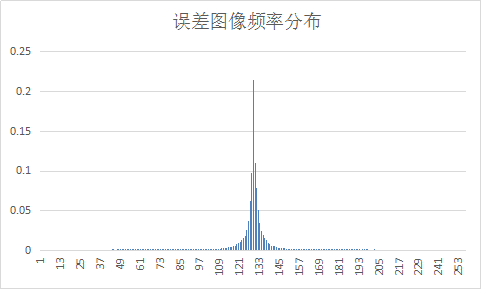
五.实验结论
经过DPCM编码后,信源符号概率分布变得集中,压缩比也提高了















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









