







 本文介绍了如何使用Python的sklearn库进行线性回归和非线性多项式回归分析,通过实例演示了体重与身高、运动时长的关系,并讨论了多重共线性和模型选择的重要性。
本文介绍了如何使用Python的sklearn库进行线性回归和非线性多项式回归分析,通过实例演示了体重与身高、运动时长的关系,并讨论了多重共线性和模型选择的重要性。
回归分析(regression analysis)是量化两种或两种以上因素/变量间相互依赖关系的统计分析方法。回归分析根据因素的数量,分为一元回归和多元回归分析;按因素之间依赖关系的复杂程度,可分为线性回归分析和非线性回归分析。我们通过一下两个例子介绍如何使用python完成回归分析。
在python中有多个软件包可以用于回归分析,在这里我们选择 sklearn软件包中的LinearRegression训练算法,之所以选择该算法是因为它支持多元回归,还可以用于非线性回归分析(多项式回归)。
1.线性回归分析
某调查公司采集了多人健康数据,试图建立体重与身高和每天运动时长的量化关系。
| 人员 | 体重 | 身高 | 运动时长 |
| 1 | 52 | 1.65 | 2 |
| 2 | 63 | 1.68 | 2 |
| 3 | 71 | 1.75 | 1 |
| 4 | 82 | 1.78 | 1 |
| 5 | 90 | 1.92 | 2 |
| 6 | 108 | 1.8 | 1 |
| 7 | 85 | 1.78 | 2 |
| 8 | 72 | 1.75 | 1 |
| 9 | 63 | 1.62 | 1 |
代码如下:
import numpy as np
from sklearn.linear_model import LinearRegression
#构造样本数据之因变量(体重)
y=np.array([52,63,71,82,90,108,85,72,63])
#构造样本数据之因变量(身高和运动时长)
X=np.array([[1.65,2],[1.68,2],[1.75,1],[1.78,1],[1.92,2],[1.8,1],[1.78,2],[1.75,1],[1.62,1]])
#创建回归模型
model=LinearRegression().fit(X,y)
#查看模型,第一个是截距,后面是自变量的系数(身高变量和运动时长变量)
model.intercept_,model.coef_
#(-173.9154414624661, array([150.83625049, -9.33963438]))
公式为:。拟合值及其残差如下表所示。
| 人员 | 体重 | 身高 | 运动时长 | 拟合值 | 残差 |
| 1 | 52 | 1.65 | 2 | 56.2695 | -4.2695 |
| 2 | 63 | 1.68 | 2 | 60.7944 | 2.2056 |
| 3 | 71 | 1.75 | 1 | 80.6925 | -9.6925 |
| 4 | 82 | 1.78 | 1 | 85.2174 | -3.2174 |
| 5 | 90 | 1.92 | 2 | 96.9936 | -6.9936 |
| 6 | 108 | 1.8 | 1 | 88.234 | 19.766 |
| 7 | 85 | 1.78 | 2 | 75.8774 | 9.1226 |
| 8 | 72 | 1.75 | 1 | 80.6925 | -8.6925 |
| 9 | 63 | 1.62 | 1 | 61.0846 | 1.9154 |
如果残差均值接近0且服务正态分布,也就是说残差是白噪声,则模型通过质量评价。以下为模型评价代码。
#可决系数,自变量对因变量变化的影响程度,越接近1越好,但无经验阈值
r2 = model.score(X, y)
print(r2)
#求预测值
y1=model.predict(X)
#查看模型准确率
print(1-(abs(y1-y)/(y+0.00001)).mean())
#计算残差,残差是白噪声(均值为0的正态分布)系列说明拟合公式已经提取完全部有用信息
res=y-model.predict(X)
#绘制QQ图
from statsmodels.graphics.api import qqplot
%matplotlib inline
ax=qqplot(res,line="s")
#或使用Ljung-Box检验,p值>0.05可认定为白噪声
from statsmodels.stats.diagnostic import acorr_ljungbox
print(acorr_ljungbox(res))输出结果为:
0.6816823621107787
0.9097391886649957
lb_stat lb_pvalue
1 0.022422 0.880971
上述模型的可决系数, 准确率为0.9097(公式为
),Ljung-Box检验 p值=0.880971。模型通过评价。其残差QQ图如下(没有按对角线分布,残差质量不是很高,说明该模型因素间不是质量很高的线性回归关系,因此拟合出来的线性回归模型准确率也不算高)。


2.非线性回归分析
我们对上例进行多项式回归分析,试图用多项式(单项式的线性组合)来拟合其非线性关系。所谓单项式就是数字与字母的乘积,如。
代码如下:
#引入高阶单项式构造函数
from sklearn.preprocessing import PolynomialFeatures
#构造2阶单项式
new_X=PolynomialFeatures(degree=2).fit_transform(X)构造出的新的单项式为
| 人员 | ||||||
| 1 | 1 | 1.65 | 2 | 2.7225 | 3.3 | 4 |
| 2 | 1 | 1.68 | 2 | 2.8224 | 3.36 | 4 |
| 3 | 1 | 1.75 | 1 | 3.0625 | 1.75 | 1 |
| 4 | 1 | 1.78 | 1 | 3.1684 | 1.78 | 1 |
| 5 | 1 | 1.92 | 2 | 3.6864 | 3.84 | 4 |
| 6 | 1 | 1.8 | 1 | 3.24 | 1.8 | 1 |
| 7 | 1 | 1.78 | 2 | 3.1684 | 3.56 | 4 |
| 8 | 1 | 1.75 | 1 | 3.0625 | 1.75 | 1 |
| 9 | 1 | 1.62 | 1 | 2.6244 | 1.62 | 1 |
然后以上述数据为自变量,与y建立线性回归关系,就构造出现二元二次多项式回归公式。代码如下。
model=LinearRegression().fit(new_X,y)
model.intercept_,model.coef_
#(-706.4617834336859,
array([ 0. , 739.84211301, 2.80313388, -157.23758678,
-20.80508628, 8.40940164]))
r2 = model.score(new_X, y)公式为
可决系数,与线性回归没有太多差异,说明二阶多项式拟合能力一般。我们可以再尝试更高阶的多项式。比如将阶数提高到3后,其可决系数值高达0.97,准确率达到0.98,取得了良好的拟合效果。

需要说明的是:
(1)回归分析要注意自变量之间的多重共线性(即变量之间高度相关),这说明有些变量是冗余变量需要剔除,以免影响模型的泛化水平。
(2)如果我们剔除了冗余变量,就需要重新拟合回归模型,重新进行模型评价。因此模型的拟合一般需要进行多轮才能获得高质量回归模型。
(3)模型不是阶数越高越好,而是可决系数和残差比较满意的前提下,阶数越低、变量越少越好(模型越简单越好)避免出现过拟合,降低模型的泛化能力,也就是我们平时所说的“奥卡姆剃刀法则”。
(4)回归方法是一个相对保守的方法,将所有点位的信息都予以考虑,避免造成信息损失。但是缺陷也很大,会将很多离群值(outliers)也包含进去,影响模型质量。因此,建模前尽量将这些离群值、干扰和噪声清洗出去。一般来说,微量的噪声、干扰对回归模型影响不大,可以不予考虑,但是离群值会严重影响模型拟合质量,需要尽可能剔除。偏离值的剔除有很多方法,如下表所示:
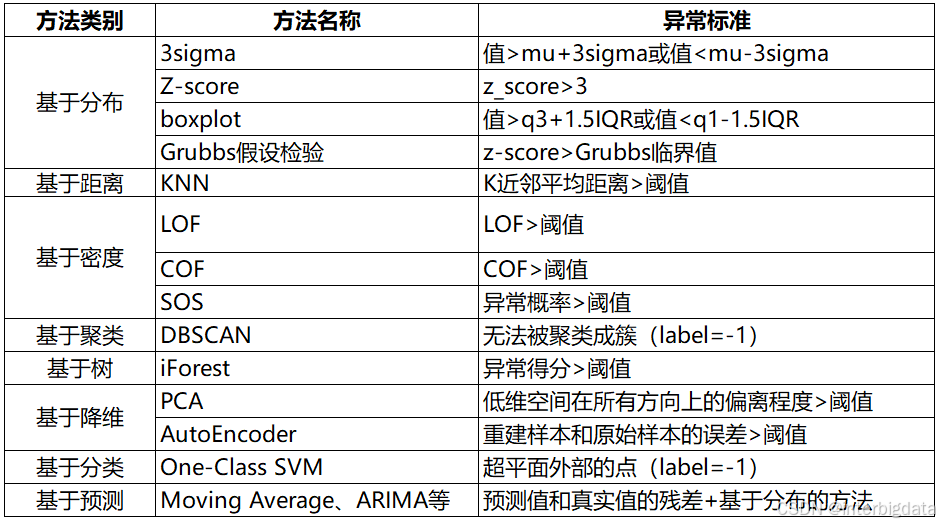
今天我们介绍一个更加常用的方法——随机抽样公式算法(RANSAC)。RANSAC算法与一般回归算法不同,它会割舍掉一些离群数据。如下图所示:
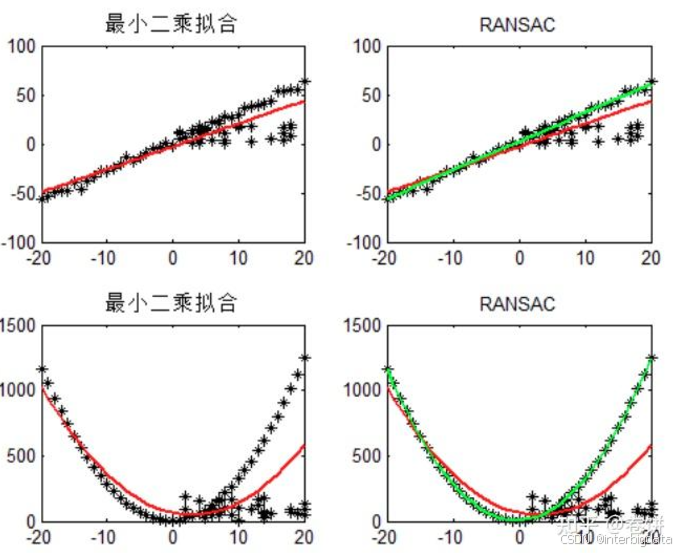
红色曲线是传统回归算法拟合出的模型曲线,而绿色曲线是使用RANSAC后拟合出的新模型曲线,可以看出绿色模型消除了离群数据的干扰。关于RANSAC算法的更多内容参见:《随机抽样一致算法(Random sample consensus,RANSAC)详解》https://zhuanlan.zhihu.com/p/402727549



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











