







相关性是量化不同因素间变动关联程度的指标。在样本数据降维(通过消元减少降低模型复杂度,提高模型泛化能力)、缺失值估计、异常值修正方面发挥重要作用,是机器学习样本数据预处理的核心工具。
样本因素之间相关程度的量化使用相关系数corr,这是一个取之在[-1,1]之间的数值型,corr的绝对值越大,不同因素之间的相关程度越高——负值表示负相关(因素的值呈反方向变化),正值表示正相关(因素的值呈同方向变化)。
样本数据的相关系数计算有多种算法,最常用的是Pearson相关系数,还有Spearman相关系数和Kendall相关系数。当涉及相关性分析的因素的标准差为0时,Pearson相关系数就无法使用了,此时还可以考虑向量夹角余弦值来衡量。
1.Pearson相关系数
相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量。计算公式如下:![]()
Numpy和Pandas都提供了Pearson相关系数的计算函数,分别为np.corrcoef()和Pandas.corr(),使用非常方便。如下例:
某公司2018年几个月份的耗电量和销售收入如下:
- 耗电量:1200,2000,1800,1500,2100
- 销售收入:180,250,270,220,280
试分析单位耗电量产生的销售收入以及耗电量与销售收入是否相关。
我们使用Numpy.corrcoef()来计算两组变量的相关系数。
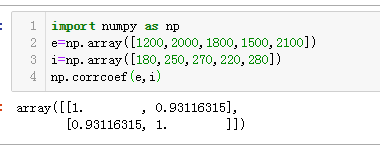
主对角线的值是两个变量的自相关系数,自然都是1,次对角线的值就是两组数据的Pearson相关系数值。我们可以看出耗电量和销售收入正相关性还是很高的,用Seaborn的回归图也能比较直观的看出两组数据的相关水平。如下图:
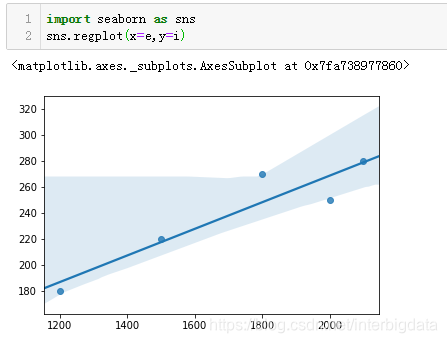
数据点比较紧密的集中在直线附近,这表明两组数据的相关性很高。
Pearson相关系统适合正态分布、连续随机变量、线性相关程度高的情况。
2.向量夹角余弦
把两组数据作为两个n维向量,通过计算两个向量的夹角余弦值,也可以衡量数据的相关程度,其取值范围也在[-1,1]之间。向量的夹角余弦值也称为向量余弦距离或向量相似度,其公式如下:

我们来看上一个案例的余弦相关系数的计算结果,同样也非常高

3.Spearman相关系数
Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作相关分析,是一种非参数方法,对原始变量的分布不作要求,也没有线性相关要求。
Scipy中的spearmanr()函数可以帮助我们计算Spearman相关系数。
Spearman相关系数有如下特点:
- 属于非参数统计方法,适用范围更广。
- 对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
- 秩次:样本数据正向排序后的序号(从1开始)
我们构造两组样本数据,它们之间的非线性关系很高。我们来看一下Pearson相关系数和Spearman相关系数的差异。
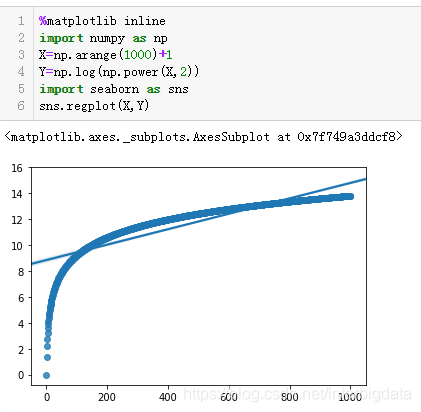

可以看出对于非线性相关的数据,Spearman相关系数要比Pearson相关系数更显著。
4.Kendall相关系数
肯德尔秩相关系数也是一种秩相关系数,不过它所计算的对象是分类有序/等级变量,如质量等级、考试名次等。对样本量小,有极端值的情况也更适用。其特点为:
- 1)如果两组排名是相同的,系数为1 ,两个属性正相关。
- 2)如果两组排名完全相反,系数为-1 ,两个属性负相关。
- 3)如果两组排名是完全独立的,系数为0。
如下例查看身高和体重的排名是否相关:

以下是上述数据的计算过程
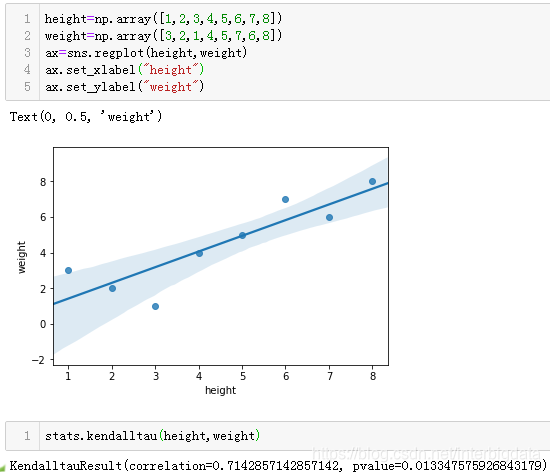
整体上,我们发现体重与身高大多数情况下有较强的相关性。
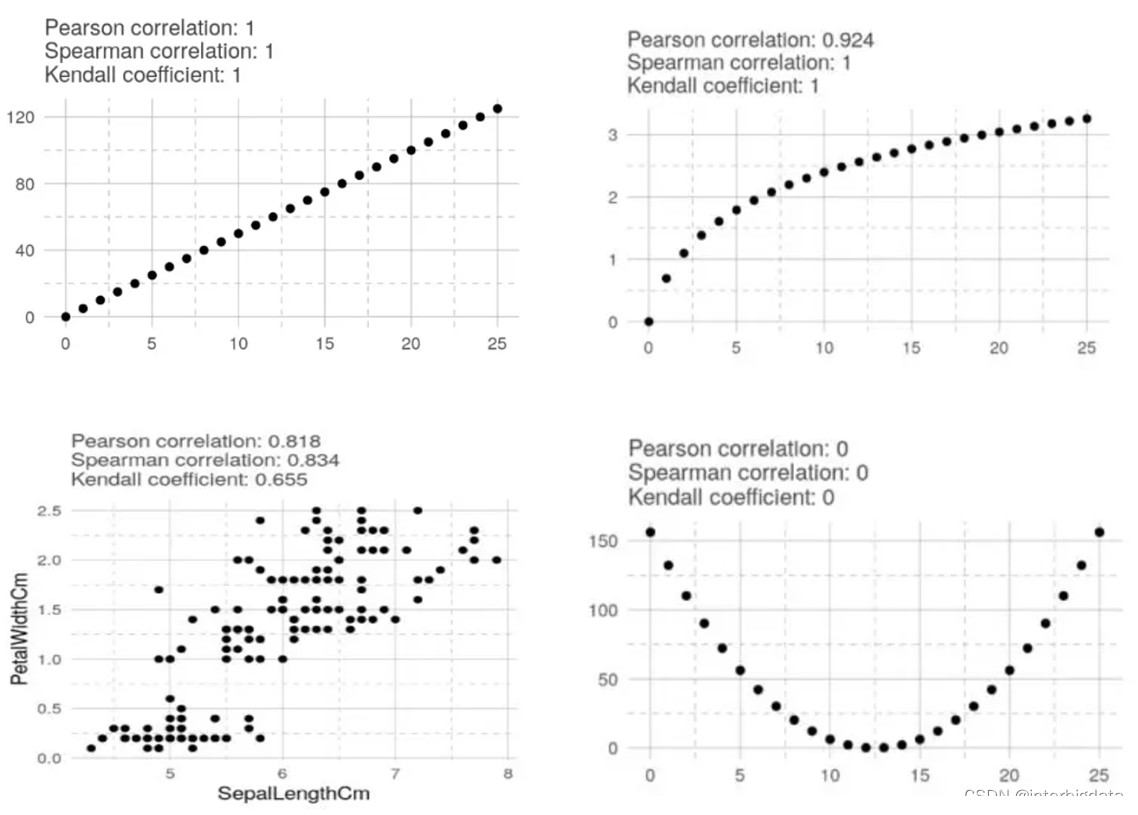
下图直观的体现了三种相关系数的有效性。可以看出,在相关性极为明显(极相关或极不相关)的情况下,三者效果是无差异的。而对于相关性不太明确的情况(图3),Kendall相关系数更为保守一些。


















 6212
6212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











