







1、背景
在做sql下推逻辑时,因为时间类型的自动转换导致自定义的下推逻辑失效 ,为了深入了解问题的原因和更好的解决问题,所以准备源码追踪下sparksql转换类型的具体时间点。另外因为只需要验证sql 字段转换的逻辑,所以只需要有一个库表就行,不需要启动大数据环境。
2、建表和插入数据
DROP TABLE IF EXISTS `person`;
CREATE TABLE `person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`salary` int(10) DEFAULT NULL,
`birthday` datetime(0) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of person
-- ----------------------------
INSERT INTO `person` VALUES (1, 'zhangsan', 22, 2300, '2023-04-02 10:10:57');
INSERT INTO `person` VALUES (2, 'lisi', 23, 3500, '2023-04-02 10:11:01');
INSERT INTO `person` VALUES (3, 'wangwu', 18, 4000, '2023-04-02 10:11:05');3、代码demo
def main(args: Array[String]): Unit = {
//1、创建sparkSession
val sparkSession = SparkSession.builder
.appName("test")
.master("local")
.getOrCreate
//2、编辑mysql连接参数
val url: String = "jdbc:mysql://127.0.0.1:3306/olap"
val table: String = "person"
var prop: Properties = new Properties
prop.put("user", "root")
prop.put("password", "123456")
//3、创建临时表
val dataset: Dataset[Row] = sparkSession.read.format("mysql").jdbc(url, table, prop)
dataset.toDF.createOrReplaceTempView("temp")
//4、查询展示
val dataset2: Dataset[Row] = sparkSession.sql("select id,name,birthday from temp")
val tt:Array[Row] = dataset2.collect()
println(tt.size)
}4、追踪过程
编辑mysql连接参数以及创建临时表,这里就不再细说,再前几篇系列文章中已经间接讲过几次临时表的源码创建过程,另外spark RDD只有在遇到行为算子才触发计算,所以这里我们直接从dataset2.collect()源码过程开始看。


如果对spark sql逻辑计算不熟悉,可能到这后就不知道怎么办了。 spark sql的查询是基于源进行。而对源的查询操作一般封装在各个源关系对象中。通过逻辑计划树可以看到,sql底层的源关系对象是JDBCRelation。所以我们到该对象的buildScan方法中继续追查(至于为什么是buildScan方法,这个是spark sql源的固定接口,不太熟悉的小伙伴可以查看我自定义数据源那篇文章):


源码追踪到这是不是感觉又进入死胡同了,不知道下个断点打哪。在这主要是考虑RDD的特性,这里返回的是JDBCRDD,既然是RDD,那么触发计算时肯定会调用它的compute方法。所以我们可以直接到compute方法中继续查看:

这里可以看到spark底层查询也是根据逻辑计划从新拼装sql,然后通过jdbc连接查询。其返回的结果是一个ResultSet对象。随后对ResultSet又进行封装,我们接着看下:

可以看到,这里把resultSet转换成包含InternalRow的迭代对象。类型转换也包含在这个方法里,即迭代封装成InternalRow时会将日期类型(日期、时间戳)转换成数字类型(整型或长整型)。 具体的代码则在迭代器的getters属性中,该属性对应makeGetters方法,我们到该方法中看一下:



可以看到这里会把日期转换成整型,时间戳转换成长整型。至此我们源码追踪的目的已经达到了一半。在获取的InternalRow对象中,日期类型被强制转换了。接下来我们看下InternalRow转换为其它格式什么时候再切换会原来的类。首先我们回到获取InternalRow集合方法中。

这里的executeCollect方法获取了InternalRow对象数组,然后通过fromRow映射为了其它类型。所以我们进入fromRow中接着查看:

 这里可以看到fromRow是一个反序列化的工具对象
这里可以看到fromRow是一个反序列化的工具对象

这里两个关键的点,一个是会根据传入的expression创建一个project对象,该对象专门将序列化InternalRow对象转换为Row对象,而且如果指定了字段类型,则会转换为对应的类型。从最下面的红框可以看出,expression中包含了每个字段的原始类型。另外一个点则是根据创建的project对象转换InternaleRow。
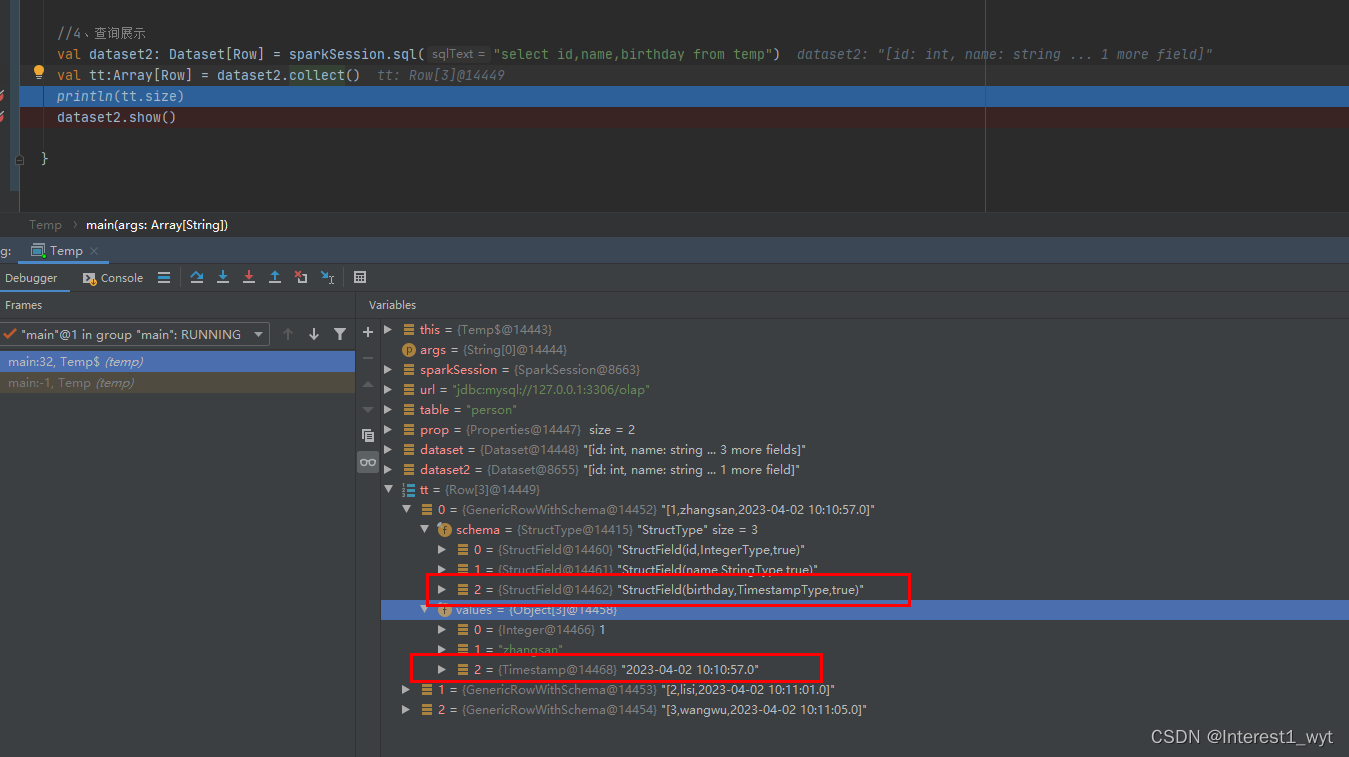
可以看到在反序列化后,长整型的时间戳字段被还原为了Timestamp类型。
5、总结
1)在通过jdbc获取的ResulSet中,迭代封装成InternalRow时会将日期类型(日期、时间戳)转换成数字类型(整型或长整型)。
2)在反序列化时会根据字段类型进行还原,即反序列化时将数字类型转换为日期类型,至于长整型的值如何还原成日期时间戳,这个没追踪到,感兴趣的小伙伴可以到反序列化的代码中自行查看。
3)本次是通过jdbc查询mysql来追踪的源码,所以查看的是JDBCRelation中的scan方法以及JDBCRDD中的compute方法,如果换了关系源或者使用了自定义的源。需要看对应源的解析过程,这里mysql的追踪过程是提供一种通用的源码追踪和解决思路。














 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









