






最近受到SAM的震撼以及一些优秀作品的问世,思考了一下当前优秀论文的特点,以及为以后自己的工作做一个方向
对大模型加小组件
tunable prompt
代表作:
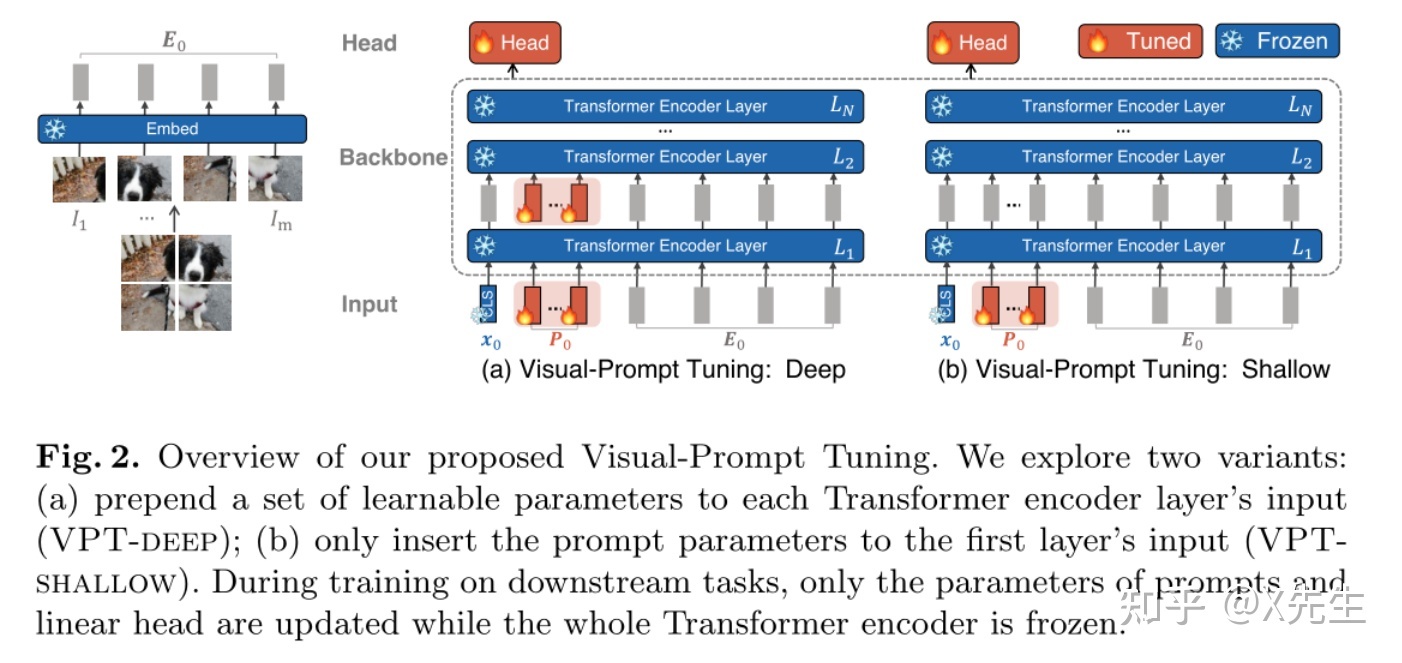
[VPT]([2203.12119] Visual Prompt Tuning (arxiv.org))
- insight:视觉中的可学习的prompt。图片token加入可学习的token,随着attention交互,学习这个token。VPT对于多个下游任务都是有帮助的,只需要为每个任务存储学习到的prompt和分类头,重新使用预训练的Transformer,从而显著降低存储成本。
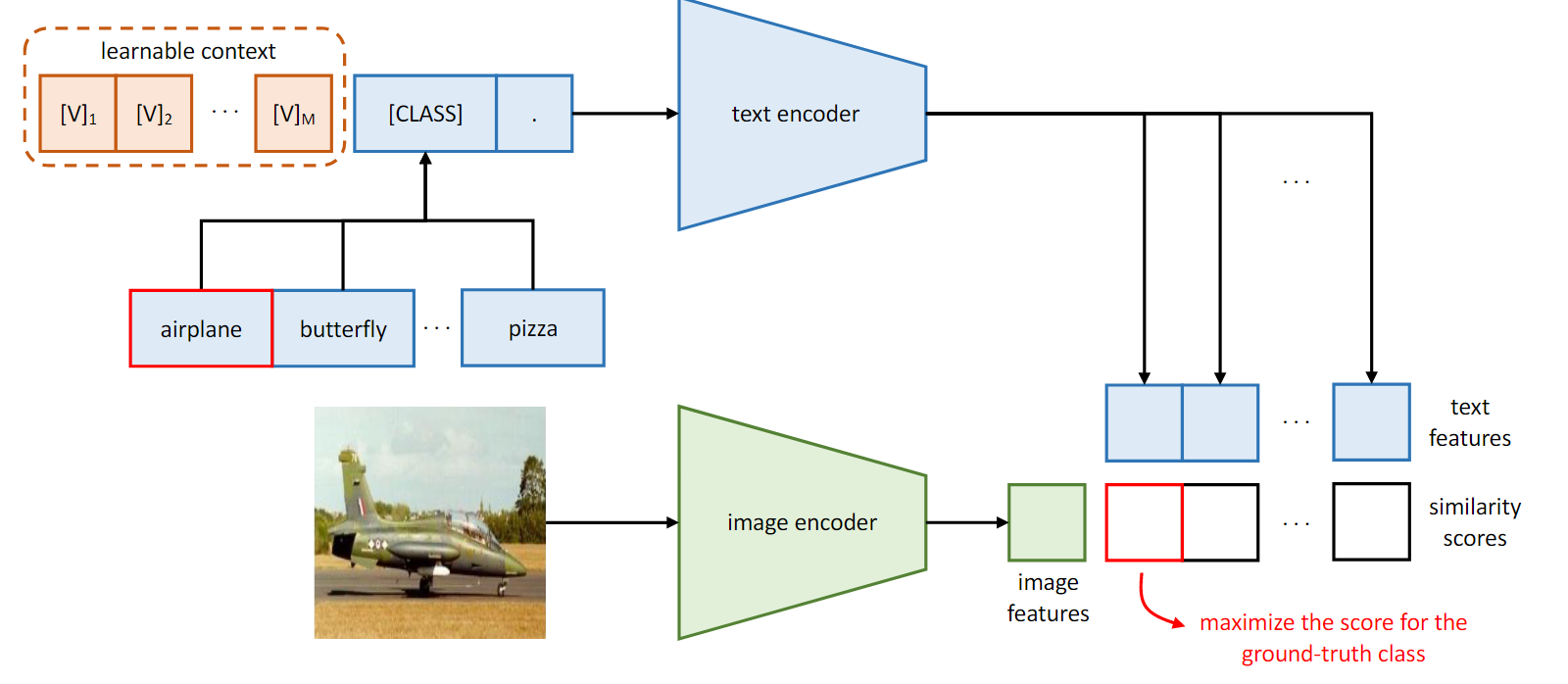
CoOp
- insight:对给定的数据,随机初始化文本(或者初始化为 xxxxxxxx ),并学习这些sudo words。
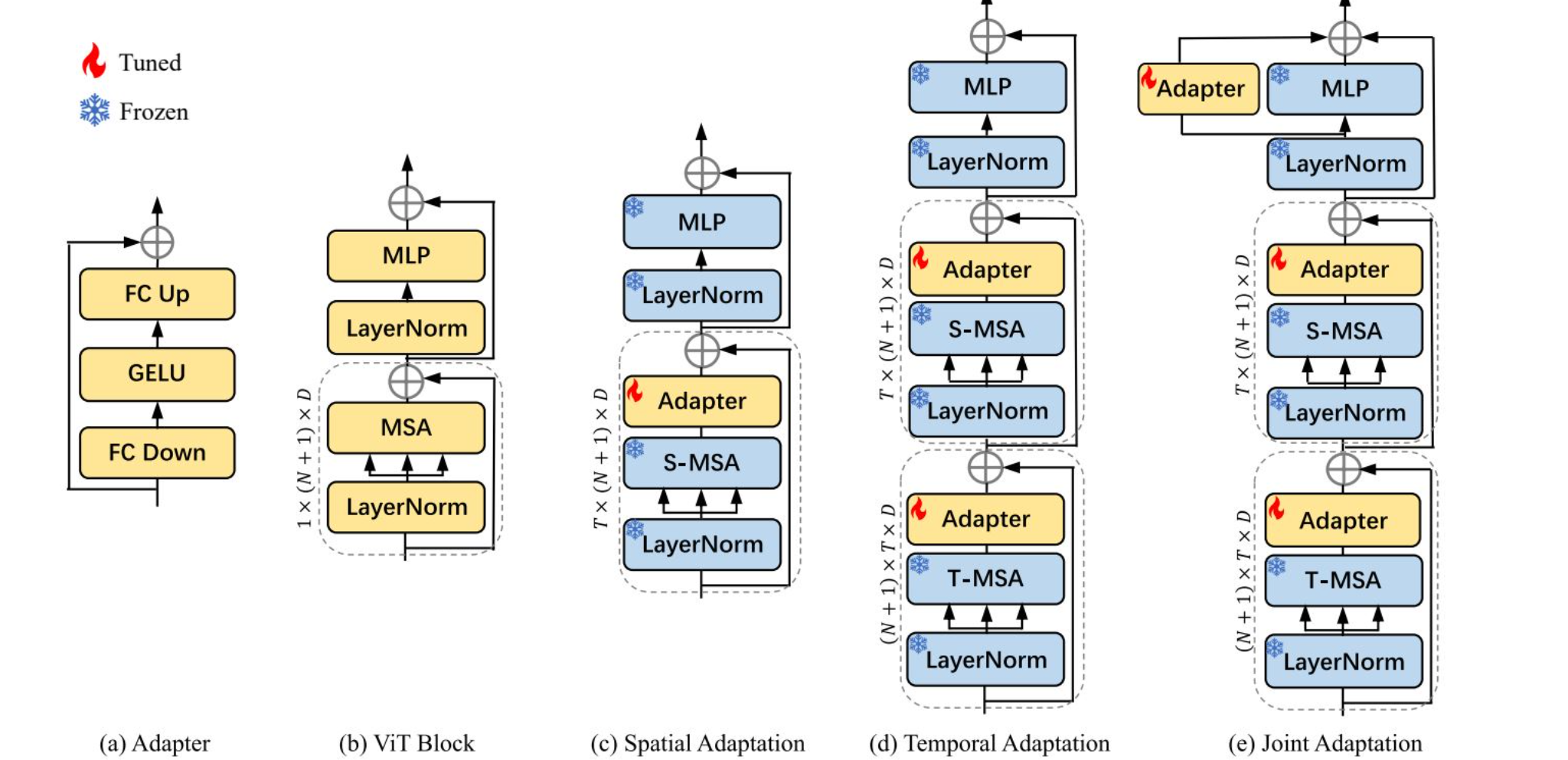
adapter
代表作:
AIM
- insight:预训练好的图像模型已经展示出优越的性能,我们认为不需要再微调模型,而是加一些parameter efficient的adapter学学习即可对下游任务的适应
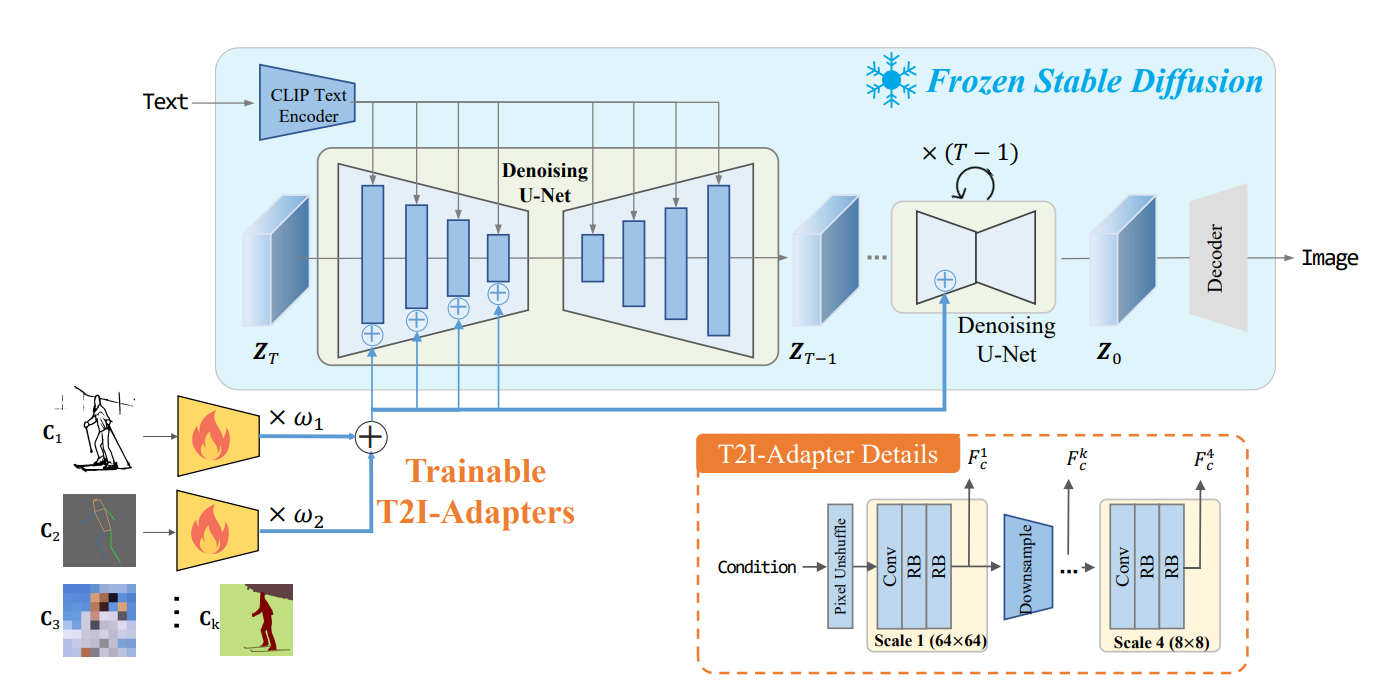
[T2I-Adapter](T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models)
- insight: stablediffusion 生成能力好但是物体和物体的组合能力不佳。我们保存SD模型原有生成能力的前提下显式的注入一些条件控制这种组合信息。
zero convolution
代表作:
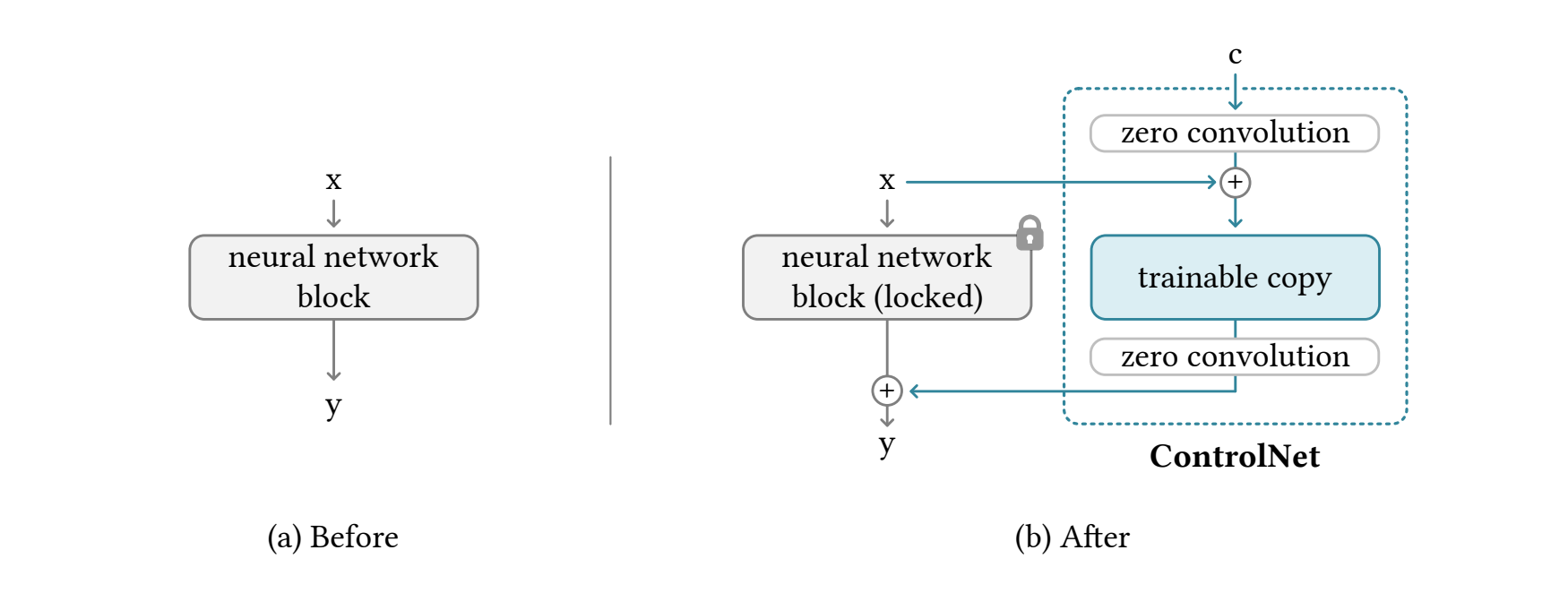
ControlNet
- insight:利用复制的新的一样的train copy 去学习,然后和原来的网络进行残差连接。即可慢慢生成一个定制化的网络。
lightweight expert(controllable net)
代表作:
[Composer](Composer: Creative and Controllable Image Synthesis with Composable Conditions)
- insight: 用GLIDE进行多组条件的组合。生成多样性可控的结果
优化目标:可以写成和GLIDE相似的形式。这里
c
2
c_2
c2可以是多种条件的组合
GLIDE
:
ϵ
^
θ
(
x
t
,
c
)
=
ω
ϵ
θ
(
x
t
,
c
)
+
(
1
−
ω
)
ϵ
θ
(
x
t
)
Ours
:
ϵ
^
θ
(
x
t
,
c
)
=
ω
ϵ
θ
(
x
t
,
c
2
)
+
(
1
−
ω
)
ϵ
θ
(
x
t
,
c
1
)
\begin{align} \text{GLIDE}: \hat{\boldsymbol{\epsilon}}_{\theta}\left(\mathbf{x}_{t}, \mathbf{c}\right) &=\omega \boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, \mathbf{c}\right)+(1-\omega) \boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}\right)\\ \text{Ours}: \hat{\boldsymbol{\epsilon}}_{\theta}\left(\mathbf{x}_{t}, \mathbf{c}\right) & = \omega \boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, \mathbf{c}_{2}\right)+(1-\omega) \boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, \mathbf{c}_{1}\right) \end{align}
GLIDE:ϵ^θ(xt,c)Ours:ϵ^θ(xt,c)=ωϵθ(xt,c)+(1−ω)ϵθ(xt)=ωϵθ(xt,c2)+(1−ω)ϵθ(xt,c1)

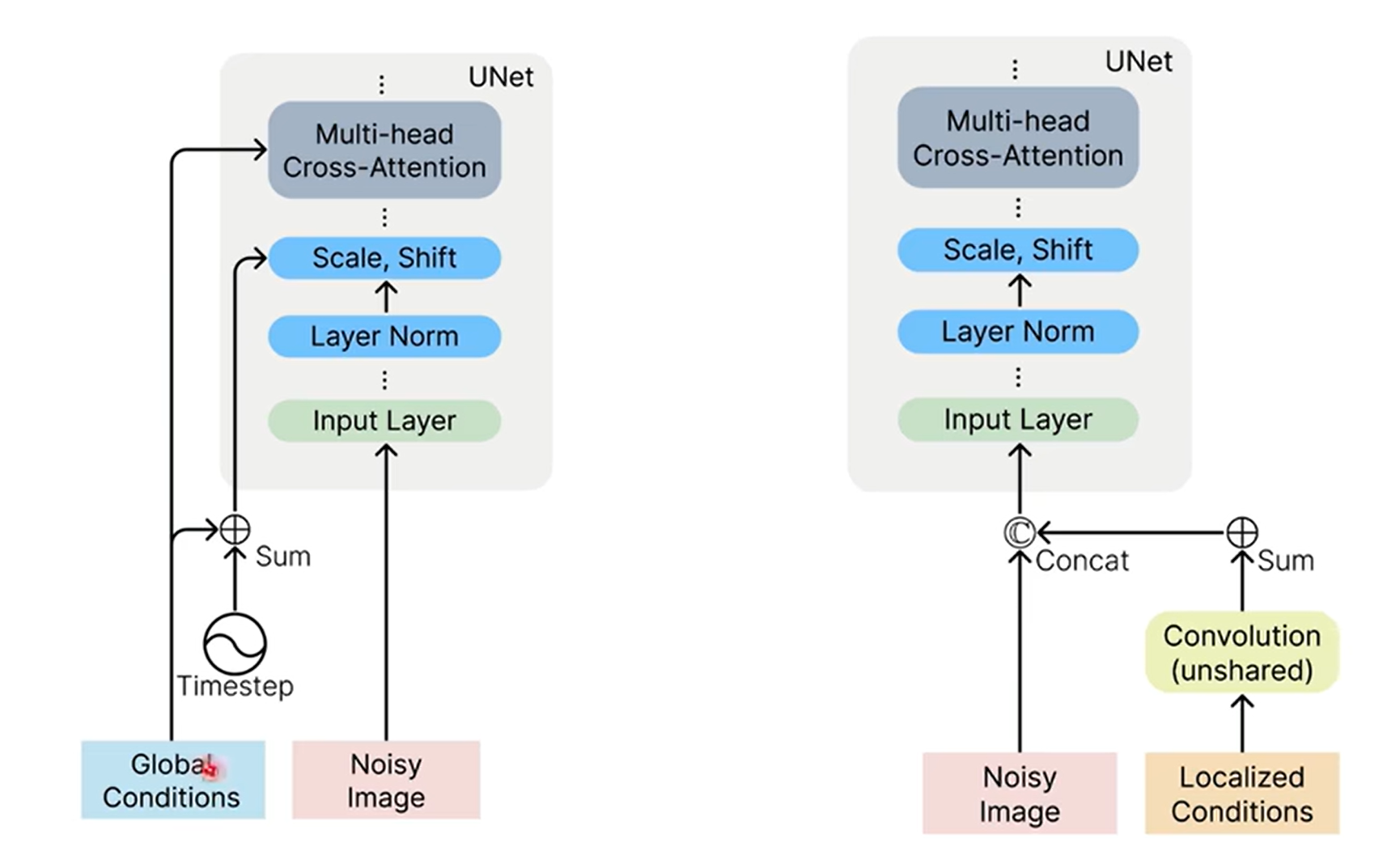
将条件注入到模型当中的过程:
dataset engine
model in the loop
代表作:
Alpaca
- insight 人工给出几个种子任务,然后丢给chatgpt根据回答筛选出52k个instruction以及答案,用这52k个instruct去训练fundation model LLaMa

SAM
- insight
用model 对生成的mask评价,如果该mask含有object,则说明生成的mask是好的,然后丢进去模型继续训练。

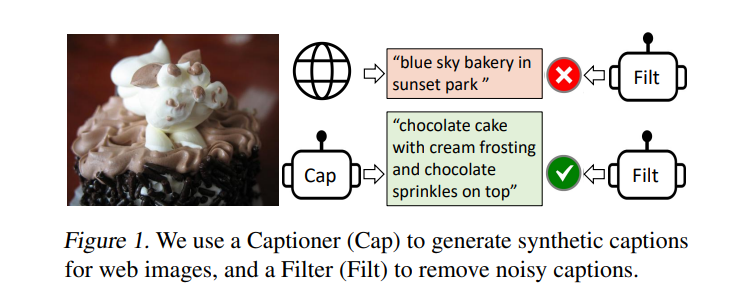
BLIP
- insight 由于网上爬取的数据带有noise ,所以用filter 模型对搜集和生成的caption进行过滤,选择最符合图片的caption

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











