






 本文详细介绍了XTuner的个人小助手部分,包括环境安装、数据生成、模型训练与对话,以及模型对比差异。此外,还涉及了多模态部分的XTuner多模态训练、LLaVA方案和Finetune前后性能对比。
本文详细介绍了XTuner的个人小助手部分,包括环境安装、数据生成、模型训练与对话,以及模型对比差异。此外,还涉及了多模态部分的XTuner多模态训练、LLaVA方案和Finetune前后性能对比。
一.XTuner个人小助手部分
1.环境安装
首先我们需要先安装一个 XTuner 的源码到本地来方便后续的使用,假如速度太慢可以 Ctrl + C 退出后换成 pip install -e '.[all]' -i https://mirrors.aliyun.com/pypi/simple/。
2.前期准备
首先我们先创建一个文件夹来存放所需要的所有文件。之后我们可以在 data 目录下新建一个 generate_data.py 文件,将代码复制进去然后运行该脚本即可生成数据集。然后打开该 python 文件后将下面的内容复制进去并将文件 name 后面的内容修改为你的名称。比如说我是剑锋大佬的话就是:修改完成后运行 generate_data.py 文件即可。

完成之后在data的路径下便生成了一个名为 personal_assistant.json 的文件,里面就包含了 5000 条 input 和 output 的数据对。

之后通过模型准备,配置文件选择,配置文件修改之后,我们就可以真是启动XTuner。



3.模型训练



4.模型对话


5.模型对比差异
假如 prompt-template 选择有误,很有可能导致模型无法正确的进行回复。看到模型已经严重过拟合,回复的话就只有 “我是剑锋大佬的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这句话。我们下面可以通过对比原模型的能力来看看差异。(第一张图所示)
可以看到在没有进行我们数据的微调前,原模型是能够输出有逻辑的回复,并且也不会认为他是我们特有的小助手。


6.web demo部署


和原来的 InternLM2-Chat-1.8B 模型对话

二.多模态部分
1. XTuner多模态训练与测试
给LLM装上电子眼:多模态LLM原理简介
a.文本单模态
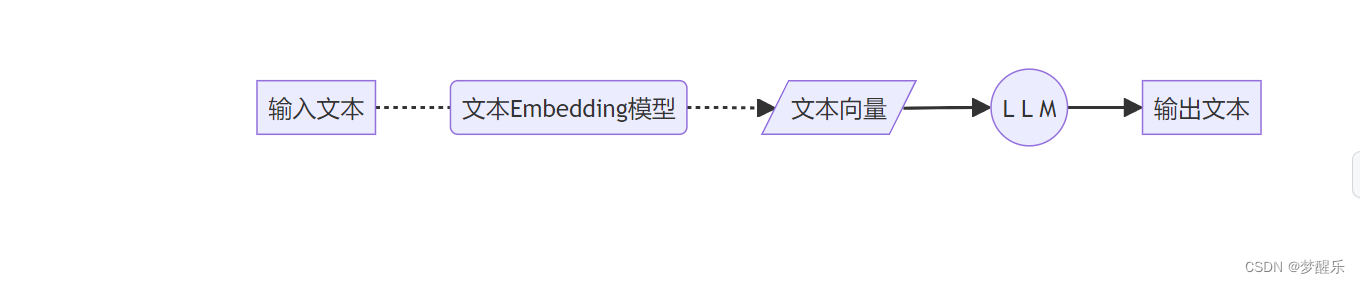
b. 文本+图像多模态

2. 什么型号的电子眼:LLaVA方案简介
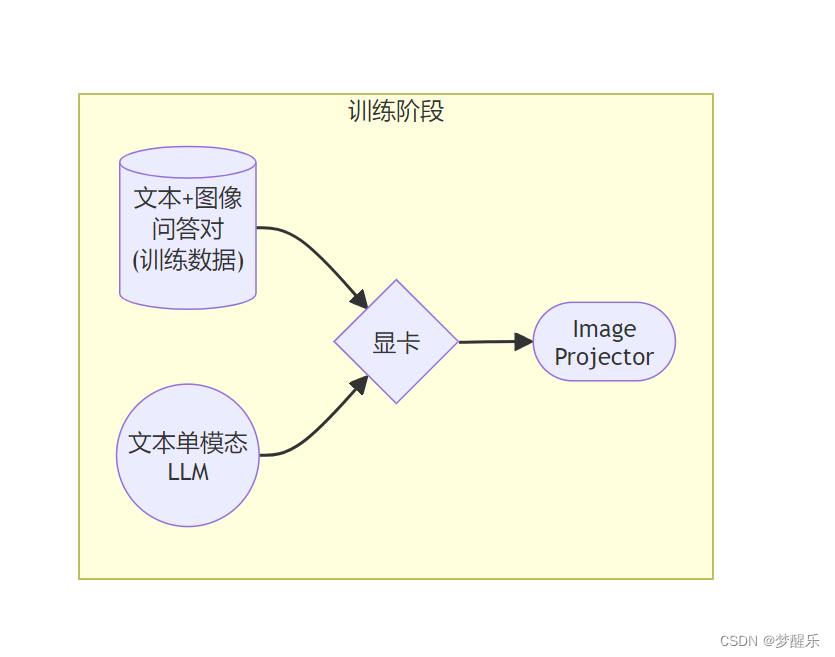
a. LLaVA训练阶段示意图
b. LLaVA测试阶段示意图

3. 环境准备
由于前面进行了XTuner安装,可以直接进行下一步
4.概述

5Finetune阶段与 Pretrain阶段
a.Pretrain阶段
在Pretrain阶段,我们会使用大量的图片+简单文本(caption, 即图片标题)数据对,使LLM理解图像中的普遍特征。即,对大量的图片进行粗看。
b.Finetune阶段
在Finetune阶段,我们会使用图片+复杂文本数据对,来对Pretrain得到的Image Projector即iter_2181.pth进行进一步的训练。通过训练数据构建,准备配置文件,就可以开始Finetune

6.对比Finetune前后的性能差异
根据这张图片来进行测试Finetune前后的性能差异

a.Finetune前

b.Finetune后
















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









