






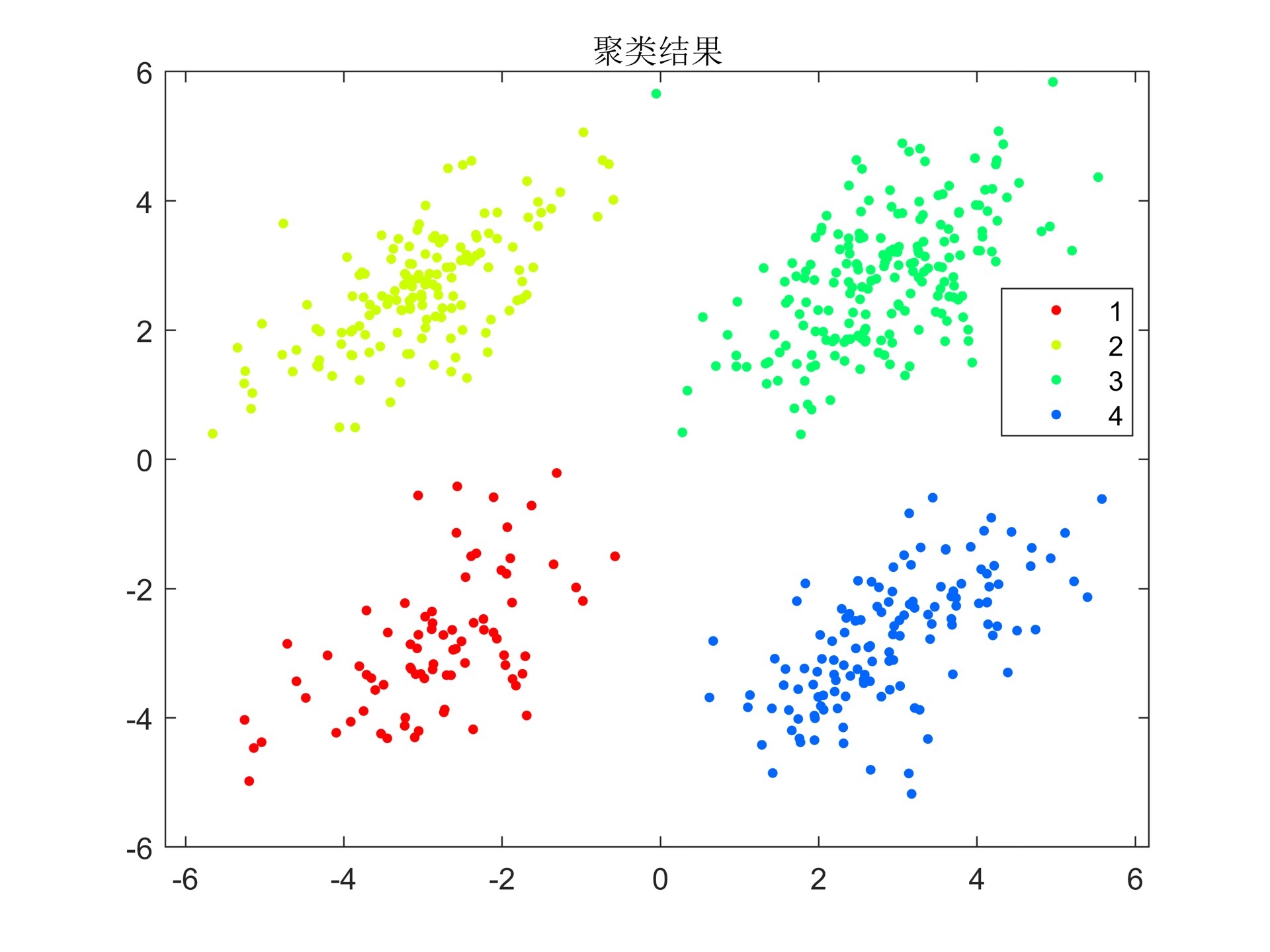
Kmeans聚类 确定最优聚类个数
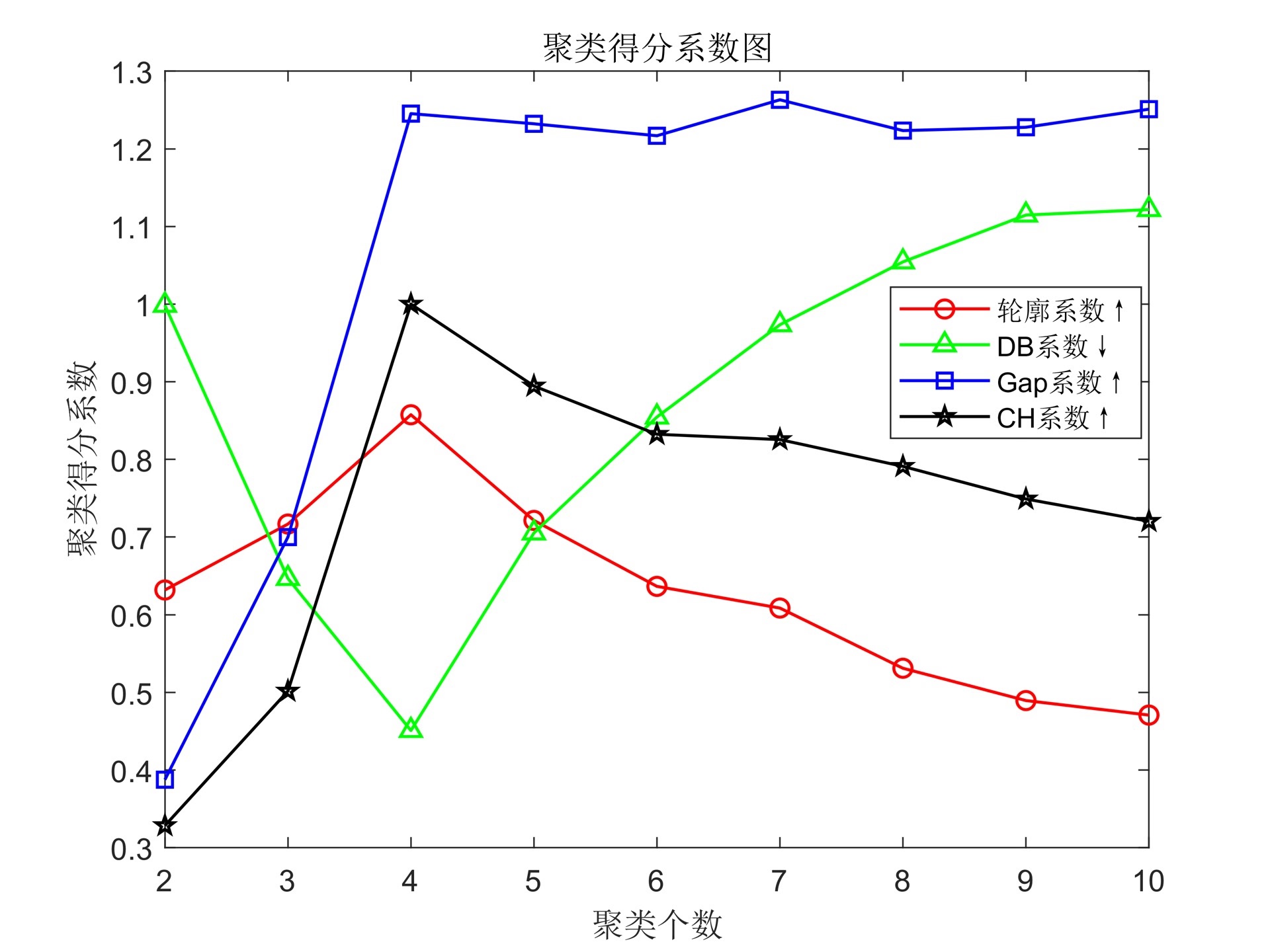
计算轮廓系数(↑)、DaviesBouldin值(↓)、GapEvaluation值(↑)和卡林斯基-哈拉巴斯指标等评价因子(↑),根据评价因子的大小确定最优聚类数目,更加准确得到聚类结果
Matlab代码,备注详细,易于使用,替换自己数据即可
ID:5950705905085151
Matlab编程
K-means是一种常用的聚类算法,在数据挖掘和机器学习领域得到了广泛的应用。确定最优聚类个数是使用K-means算法时一个重要的问题。本文将介绍如何使用轮廓系数、Davies-Bouldin值、Gap Evaluation值以及卡林斯基-哈拉巴斯指标等评价因子来确定最优的聚类个数,从而得到更加准确的聚类结果。
首先,我们来介绍一下这些评价因子。轮廓系数是一种衡量聚类结果质量的指标,其取值范围在-1到1之间,越接近1表示聚类结果越好。Davies-Bouldin值是另一种评价聚类质量的指标,其取值范围在0到正无穷之间,越接近0表示聚类结果越好。Gap Evaluation值是通过比较聚类结果和随机数据生成的结果之间的差异来评价聚类质量,取值越大表示聚类结果越好。卡林斯基-哈拉巴斯指标是一种综合考虑聚类结果内部的紧密性和聚类结果之间的分离性的评价指标,取值越大表示聚类结果越好。
在确定最优聚类个数的过程中,我们可以通过计算这些评价因子的值来进行比较。一般来说,我们希望轮廓系数尽可能接近1,Davies-Bouldin值尽可能接近0,Gap Evaluation值和卡林斯基-哈拉巴斯指标尽可能大。通过对不同聚类个数下这些评价因子的计算和比较,我们可以选择最优的聚类个数。
接下来,我们将使用Matlab编写代码来实现计算这些评价因子的功能。我们提供了一份Matlab代码,代码中包含详细的备注,只需替换自己的数据即可使用。这使得使用该代码变得十分简单和便捷。
在使用这些评价因子进行聚类时,我们还需要注意一些事项。首先,我们需要考虑是否需要联系作者以获得更多的帮助。作者只提供代码,不负责讲解。其次,我们要注意代码的使用方法和替换数据的方式。
综上所述,本文通过介绍轮廓系数、Davies-Bouldin值、Gap Evaluation值和卡林斯基-哈拉巴斯指标等评价因子的使用方法,以及提供Matlab代码来帮助读者确定最优的聚类个数。通过使用这些评价因子,我们可以得到更加准确的聚类结果。希望本文对读者在使用K-means算法进行聚类时有所帮助。
温馨提示:在使用代码时,如有需要可以联系作者以获取更多帮助。该代码只提供使用方法,并不负责讲解。代码示例参考Example_54。
(字数:780)
以上相关代码,程序地址:http://wekup.cn/705905085151.html















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









