










This series of articles are the study notes of "An Introduction to Programming the Internet of Things", by Prof. Harris, Department of Computer Science, University of California, Irvine. This article is week 3, Lessen 2: Microcontrollers and Software.
2. Lesson 2 Microcontrollersand Software
2.1 Lecture 2.1 Microcontroller Components
This lecture will talk about microcontrollers in a little bit more detail. Specifically, we're going to talk about the storage elements and how you store data inside a microcontroller. So we need toknow a little bit about that.
2.1.1 AVR ATmega2560
So first, here's a picture of taken out of a datasheet for an AVR at mega 2560 microcontroller. This at Mega 2560 is not the same as what's in the Arduino, or not in the regular Arduino. In the Arduino uno, it doesn't have this. Actually I think there is an Arduino that uses one of these, but this is the same series of processes that you find in anArduino. And here's some of the information that you would find right on the front page of the datasheet.
- 8-bit microcontroller
- Up to 16MHz
- 256KB of flash memory
- 4KB EEPRO,
- 8KB SRAM
- Peripherals (ADC, etc.)

2.1.2 Microcontroller Storage elements
Storageelements
- Data stored in different components
- Speed/cost (are a) tradeoff
Storage elements are basically elements that store data. There's a need for a lot of data; so you need to store data. You can store data, you can store the program itself. The program itself is data.There are different types of storage elements.There's aspeed performance tradeoff. So some types of storage are veryfast, but theycost more. Usually they cost more, because of area. They take up a lot more area on the chip. Where on the other hand, there are other types of storage elements that areslower to access, but theycost less. They are much smaller on the chip. There's also apower tradeoff that I didn't mention here.
2.1.3 Registers
(1) Register: stores a single value
- Like a single memory location
- Extremely fast & expensive
So most basic storage element, fastest storage element is the register. A registerstores only a single value. Now depending on how many bits the register is, it saves one number. So if you have a 32-bit data path, you'll typically have 32-bit registers. So, it can store one 32-bit number. It stores whatever you want. Maybe the location in a certain memory locates, the value in a location in a memory location. It stores some numberthat you're working with, some variable that you're working with right now inthe program. Registers is very fast,the access timeis a lot less than a clock cycle, butit'sexpensive. So you can't have too many of them on chip, because they're so big.
(2) Several special-purpose registers, used internally
So there are several special purpose registers that are devoted to particular tasks on the microcontroller, like theprogram counter is a common one. Program counteris the register that tells you what instruction you're executing in a code, it's the address of the instruction you're currently executing.
(3) General-purposeregisters, used by the program
There are also a set of general-purpose registers that your program can actually use for computation, arithmetic, things like that.
(4) Registerfile: stores many values
There's also a register file. A registerfile is basically, a group of registers put together. So these are commonly how registers are organized inside microcontrollers. It acts like a memory, just avery fast memory. You can only read one or two of these registers at the same time, but usually you don't need to read more than two in a particular clock cycle.
(5) Instruction operands are here
add $r3 $r2 $r1
Add $r3, $r2, $r1. It's not going to look like that to you. That's what the machine is actually running, the simplein structions that the machine's actually executing. $r3 is the destination register, that's the name of a register, $r2 and $r1 are the two source operands. So what this instruction does is it takes the contents of register $r1, contents of register $r2, adds them together, puts the results in register $r3.
(6) Can onlyread one or two at a time
(7) May contain ~32 registers in a microcontroller
2.1.4 Memories
Memories are made to store a lot more data than registries, so you won't just have 32 registries. Memories will a lot bigger. So there are varieties of memory.
(1) Cache: Stores many values
- Slower than a register file
- Cheaper than a register file
- Still fairly fast and expensive
So usually cacheis a lot bigger than register files, but they'realso slower than register files. Where a register file, you could access that in a fraction of a clock cycle. A cache typically takes you a clock cycle to access, a full clock cycle, which is pretty good, but not as good as a register file.Cache is still fast and expensive. They're cheaper than register files, but they're more expensive than larger memories. So that's a cache and that's on chip. You'd find that on the same integrated circuit as the microcontroller.
Typically, commonly in the microcontroller is that we are using what is called the Harvard architecture. So you'll have two different caches, at least two. You will have a data cache and an instruction cache.
- Datacacheholds data that theprogram operates on
- nstructioncacheholds programinstructions
(2) Main memory
- Very big: Gigabytes (Gb)
- Not in the CPU
Main memory is like cache, except it's bigger and cheaper and slower. So you can see the pictures right there of main memory. If you've ever taken your taken your computer and installed memory into your desktop, you'll get something that looks like what we see in the picture and you can plug it into a slot inside the board. So it's very big gigabytes ofmemory not in the CPU, so it's not on the same chip.

- Connected to the CPU via system bus
- Memory access is slow
If you look at that memory, it is multiplechips all put together. It's connected to the system, connected to the CPU via system bus. So there are system bus that basically has a group of wires, that are written. Basically, drawn onto the circuit board, the printed circuit board that connect to the main microcontroller to the memories. The memory access is slow relative to the cache. So what that means is that in a cache, you might beable to access a cache in one clock cycle. And main memory, maybe you have to wait 100 clock cycles to access on main memory.
Von NeumannBottleneck
- Memory is much slower than the CPU
- Memory access time slows program execution
So all your time is going into memory accessesand that is why people use caches,so that to avoid this Von Neumann Bottleneck. So, theVon Neumann Bottleneck is the bottleneck to accessing main memory. It's the fact that the memory, it's much slower than the processor. You try to rely on the cache and the registers as much as you can, so that you don't have to go to main memory.
Now all these complexities that I'm talking about, about are you accessing the cache, the register or the main memory. A lot of these we will not be dealing with in this class, because we'll be writing code in either C or in Python. So, all these details of where the data is going to be? Is this register going to contain this variable or is the variable going to be in the cache or main memory?All those issues are dealt with by the compiler, if it's C or C++ or the interpreter, if it's say, Python. Sowe are not going to have to worry about this level of detailso much, butit's important to understand the difference in the different types of storage elements and how they act and how fast they are, how slow they are and so on.
2.2 Lecture 2.2 compilation and Interpretation
This lecture will talk about the software side a little bit. Specifically how the software is processed before it's actually executed in the micro-controller. So key here is that the code that you actually write isn't literally processed by the micro-controller. It's not executed directly. It has to be processed first compiled or interpreted and then it's processed.
2.2.1 Software Translation
(1) Machine language: CPU
Instructions represented in binary.
A micro-controller or CPU as we're calling right here, micro-controller, it understands. It doesn't understand C, or C++,or Java, or Python, or any of those languages that most humans program in. It understands its own machine language. Different processor families understand their own machine language. Now, machine language is basically a set of really small simple instructions encoded in binary, zeroes and ones. So take an Intel processor. It understands Intel machine language, X86 machine language it's called.
(2) Assembly language: CPU
- Instructions with mnemonics
- Easier to read
- Like machine language
Now assembly language is basically a one toone mapping from the machine code that's actually executed to a pneumonic, asimple pneumonic that a human can read. And now, it's not easy to read, but it'seasier than the zeros and ones. So, instead of having a sequence of zeros and ones, assembly code will say add R1, R2, R3, or something like that. So that's readable. But still it's very low level. These instructions are very simple.
So assembly language to machine language they are one to one mapping, right. You have an assembly instruction, it is exactly equal to a machine language instruction. So it's very simple, but at least it's readable.
(3) High-level language: commonly used languages (C, C++, Java)
- Easier to use
What we'll work with are high level languages, what we'll call high level languages. The commonly used languages of C, C++, Java, dot dot dot. Python, which is what we're going to look at. We'll focus on C, C++, and python, but there are many high level languages that people program in. So these are much easier to use. They give you the regular programming constructs that programmers are used to.
High-level language is not what's actually executed. The machine language is what's actually executed. So, this high-levellanguage has to be converted into machine language before execution. All the software that you write in a high-level language has to be translated into machine language. Translate into the machine language of the micro-controller before you can actually execute it.
2.2.2 compilation and Interpretation
You're going to write the code, then you're going to do the translation and then it gets executed. Now there are two waysthat this can go. Depending on if it's a compiled language or aninterpretive language.
(1) Compilation: translate instructions once before running the code
- C, C++, Java, (partially)
- Translation occurs only once, saves time
So compiled language, what happens is compilation happens where the language, the instructions, get translated into machine code, before execution, one time. And you get what's called an executable at the end, which is basically the machine code and plus some extra data, but essentially machine code. And this executable is what is run every time you run the code. So the compilation, the translation from the high-level language to the machine code happened one time before you executed it, and then every time you execute it after that, you don't have to do that conversion,okay. Socompile languages include C, C++, Java half way.
(2) Interpretation: translate instructions while code is executed
- Basic, Java (partially), Visual Basic, Python
- Translation occurs every execution
- Translation can adapt to runtime situation
So in interpretive language, what happens is the instructions, the Python instructions I say, are converted into machine code at runtime, so every time you execute that code, you have to convert the Python into machine code, unlike the compiled language. Compile language, you compiled it once and you got the machine code, and then every time you executed it, you didn't have to compile again.
(3) Compare oftwo high-level languages
Now there are advantages and disadvantages. The disadvantage is that it's slow. Compared to compiled code, it's slow because you have to do that whole conversion from high-level to low-level every single time. But it has a lot of advantages because it allows you, as aprogrammer, it relieves you of certain burdens. So certain things you, the programmer don’t have to think of because the interpreter will deal with them. So, for instance, just as an example let's say in C, you're using a variable, you're defining a variable, an integer. In C if you want to use an integer, you have to declare that integer, you have to say int x, let's say. And you have to put that atthe top of your code so the compiler can know he needs an integer in x, right? With an interpreter, like with a Python language, you don't have to declare x as an integer. You can just start using a variable called x. And the interpreter will figure out, oh I think this, he means for this to be an integer. I'll refer to this as an integer. Or, if it sees you're using the variable differently it'll make it a floating point or something like that. But that's a burden that the programmer no longer has to deal with, right. The interpreter at run time can figure out what the type is rather than you as aprogrammer having to deal with it. So interpretive languages do have the advantages that they are generally easier to program in, but they are slow.
2.3 Lecture 2.3 Python vs. C/C++
So this lecture, we'll talk about acomparison between Python and C, C++. Because Python is what we're going to usein the Raspberry Pi. C, C++, we'll be using with the Arduino.
2.3.1 Python
- Python is an interpreted – a scripting language.
- Python is easier to work with, if speed is not primary.
Advantages of Python
So there are certain things the programmer does not have to deal with, like the type of variables. Is it an integer, is it in floating point, is it a string, you don't have to worry about that in Python. Python figures that all out based on how you use the code, or you use the variable. So at run time, while it's executing and doing an interpretation, it can figure that out.
Other things too, like memory management, in C, C++ you have to deal with that. You have to say, look, I need more space. There's a function called malloc, you can allocate more space, I need more memory for this variable. Python, you don't have to say that, it'll just make it for you, right. And when you're done with it, it'll get rid of it. So where in C you, have to make it explicitly, and you have to, as a programmer, have to know oh, now I'm done with it, let me free that memory. So there are a lot of these burdens, these programming burdens, that you don't have to deal with in a language like Python, because the interpreter is there take care of it for you at run time.
2.3.2 C/C++
- C and C++ are compiled
- C and C++ are more common for performance
C and C++ are compiled languages. So you write the code, you compile it once, and then you get an executable, which is machine code plus extra information. And you only execute the machine code. You don't have to do the interpretation at run time. Soas a result C, C++ programs are generally a lot faster than Python programs, but the programmer has to deal with a lot more details. Now, dealing with a lot of details is hard. But when it comes to embedded systems, it's often useful because sometimes, not just sometimes, often the programmer, an intelligent programmer, can write code more efficiently than the Python interpreter can.
So in C and C++ are commonly using embedded systems. Outside of embedded systems, you see them used less. Maybe Java is favored, or something like that. But because of the level of control that you get with C, C++, they are much more commonly usedin embedded systems.
2.3.3 Compilation and Assembler
At the top, you've got, say, some regular C code, and actually that code is pretty generic. You can have a = b + c in any number of languages, Java, Python, they look all very similar. Except for these mi-colon at the end, that could've been Python. So you get the high-level language at the top. And in the end, you want to get what you see at the bottom, a sequence of zeros and ones that represent the instructions. So, what happens is if you look at that top instruction, it's actually broken down into a set of smaller steps, of smaller behaviors. So that instruction a = b + c, it's not just an add instruction, it's not just an add that'll be performed.
So that one high level instruction breaks down to four simpler assembly level instructions. And thenthe assembler takes each of those four instructions, and converts it into a sequence of zeroes and ones. So you can see, at the bottom you see actually one instruction, just the add instruction. But presumably, you would have four instructions, four sequences of zero and ones just like that, to correspond to each one of the four assembly instructions. So that's the process of compilation, a very simple version of it.
2.3.4 Software Tool Chain
So this is a high level view of your standard tool chain, software tool chain. A tool chain is basically a term that is used in embedded systems a lot, and in IoT devices a lot. It describes the sequence of tools, of software tools, that you have to use in order to convert a program that you code into an executable program on the platform.
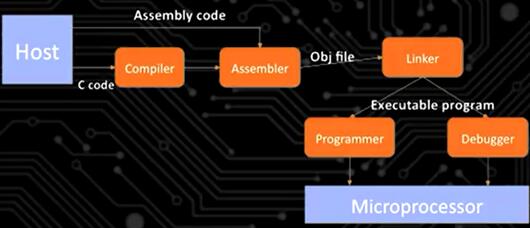
(1) Writing code on a host
We start with the host up at the top left. The host is laptop, desktop, whatever it is that you're actually writing the code on. So, you write you code on the host using some text editor, it doesn't really matter which one. Then, and this is actually a compile tool chain. So you write your code, let's assume it's C, the C code comes out of the host, goes into a compiler.
(2) Compile a high-level language code in the compiler → get assembly code
So the compiler, actually I should have said here, this is what's called a cross compiler. So across compiler is a compiler, it takes the C code, and coverts into an assembly code, okay. But the assembly code is for the target platform. So the target platform is whatever microprocessor you're targeting. So let's say I'm using an Arduino. The processor onthere is going to be an AVR ATmega processor. So the compiler that is a cross compiler, it'll compile and make assembly code that works for that AVR ATmega processor. So the compiler makes that.
(3) Assembly code go to assembler → get Obj file (machine code)
Then that code goes to an assembler and gets an object file that's generated, which is actually machine code. Again, for the target platform, for the AVR ATmega whatever it is. And so the OBJ file, the object file, that has the machine code plus extra debugging information and other assorted information in there, but it has the machine code. Now,you'll notice there's a path on the top from the host into the assembler assembly code. You could write assembly code directly. So you could write C code, which is what we'll do. You could also write assembly code directly. We will not do that, but you could, and that would get merged in at the assembly phase. So then once you get the object file, the object file, that describes all the code that you wrote.
(4) Use function with linker
But remember that we're using library functions all the time. And we haven't done this yet, but in our code, you always want to use library functions to handle complicated tasks. Now, library functions arereally just functions that are prewritten, but you didn't write them. You just call the function. You just write the name of the function, and that code gets executed. So, all those library functions have to get integrated into your program at some point, and that's what the linker does. So the linker, we don't see this in the picture, butthe linker, it has access to all the libraries. And the linker basically takes the library's code and inserts it into your code at the appropriate places. It creates links between your code and the library code that you use. And then the output of the linker is going to be some executable program.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









