






软件:sql server 2014
核心语句:
select row_number() over (
partition by 重复字段 order by 排序字段
) as flag, * from 表名
1 准备语句:
drop table eDelRepeatData
create table eDelRepeatData
(
ID int identity(1,1) ,
aaa int,
bbb int,
ccc int
)
Insert Into eDelRepeatData(aaa,bbb,ccc)
Select 1,2,3
union all
Select 1,2,3
union all
Select 1,2,3
union all
Select 3,2,1
union all
Select 3,2,1
union all
Select 4,5,6
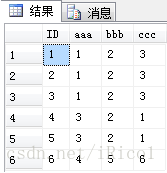
测试下:select * from eDelRepeatData
由结果见,字段aaa,bbb,ccc三个字段都重复的数据有ID为1,2,3这三条重复,4,5重复;
2 接下来就是对数据进行分组:
select row_number() over (
partition by aaa, bbb, ccc order by id
) as flag, * from eDelRepeatData
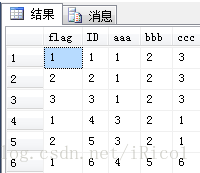
结果为:
对比上面的select * from eDelRepeatData,发现多了一个flag字段,而且flag不为1的数据均为我们要删除的重复数据,这样就好办了;
3 删除flag不为1的数据:
delete from eDelRepeatData
where id in (
select id from (
select row_number() over (
partition by aaa, bbb, ccc order by id
) as flag, * from eDelRepeatData
) a where flag<>1
)
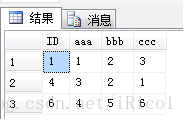
执行结果为:
ID为1, 4, 6的数据保存,ID为2, 3, 5的重复数据删除了,完成指定功能;
**最后说明:
例子在sql server软件中F5跑下来再结合语句应该就能利用一开始的核心语句来完成指定字段的重复语句的操作(查询和删除),即使你不懂得row_number(), partitionby, over()这些是什么 ,本篇文章用来快速地解决处理指定字段的重复数据的问题;
**














 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









