







我没有去很关注数学,下次补上
突然产生一个疑问,我为什么每次写博客,都没有以尽可能别人看的舒服看的明白为目标,都是以自己想到哪就记录哪?
Bitmap能够将原先需要用32bit存的整数用1bit来表示,它的空间复杂度与要表示的最大的数有关,与有多少个数无关。当要存的数到达64bit的时候占用内存依旧太大
bloom filter是对Bitmap的扩展,有很高效的时间和空间,但是是以牺牲一定的准确度为代价的,以及存在删除困难的问题
文章目录
Bitmap
应用背景:大数据查找和排序
Bitmap
漫画算法:什么是 Bitmap 算法?
一个byte是8bit,每个bit位代表一个数,如果bit值为1,说明这个数出现过,如果bit值为0.说明没出现过。以byte[0]所示为例,第8,6,3,2位上是1,表示数字7,5,2,1出现过。
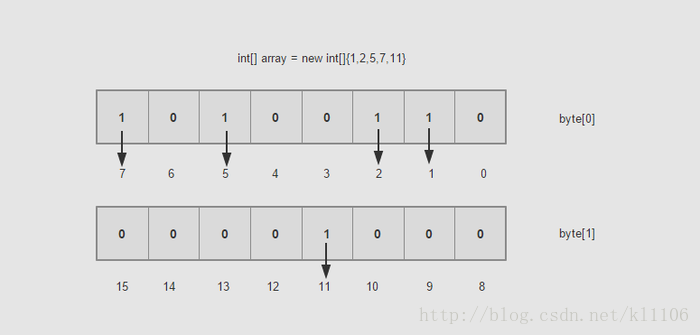
从上图可以看出,逻辑上我们开长度为8的byte数组来存储数据。我们在维护Bitmap时,需要知道每个数对应数组的什么位置,其本质是要知道数字x在A[][8]中的行数和列数(从0开始计数)。但实际时我们用一维数组A[](称之为位数组),他代表一个整数,每个整数有8个bit,可以存储8个数据。
如果数据中的最大值是n,那么需要开的数组大小是(n>>3)+1
数据x的行数index为(x>>3),即落入哪个byte中
数据x的列数position为(x&0x07) 本质上是取后三位来定位列 即落入byte的哪个bit中
A[index]|=1<<position
判断一个数x是否存在:
A[index]&(1<<position)如果为1则存在,说明A[index]的position位bit被置为1,说明x存在。否则bit位为0,x不存在。
清除一个数x:
A[index]&=~(1<<position) 不影响其他位,只把position位清零
当我需要进行排序的时候,遍历一下byte[bit],如果是1就输出下标,那么最后输出的就是排好序的数字。比如上图 1 2 5 7 11
bloom filter
大数据量下的集合过滤—Bloom Filter
讲的很清晰
常见的几个应用场景:
- cerberus在收集监控数据的时候, 有的系统的监控项量会很大, 需要检查一个监控项的名字是否已经被记录到db过了, 如果没有的话就需要写入db.
- 爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
- 垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
需要补充的是expectedInsertions是字符串总数量
fpp是可接受误差
package com.qunar.sage.wang.common.bloom.filter;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









