






本文是笔者在学习深度学习过程中的代码分享,主要是对实现代码的一些注释
dl库中的函数
#生成数据
def synthetic_data(w, b, num_examples):
"""y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))调用pytorch实现线性回归
import numpy as np
import torch
from torch.utils import data
from dl import torch as dl
#生成数据集
true_w=torch.tensor([2,-3.4])
true_b=4.2
features,labels=dl.synthetic_data(true_w,true_b,1000)
#读取数据集
def load_arry(data_arrys,batch_size,is_train=True):#构造pytorch数据迭代器
dataset=data.TensorDataset(*data_arrys)#*data_arrys是解包操作,将数据数组解包为独立的数组
return data.DataLoader(dataset,batch_size,shuffle=is_train)#shuffle指定了是否在每次开始时打乱数据
batch_size=10
data_iter=load_arry((features,labels),batch_size)
#定义模型
from torch import nn
net=nn.Sequential(nn.Linear(2,1))#将线性层放入顺序层,参数为输入、输出维度,nn.Sequential:一个时序容器,Modules 会以他们传入的顺序被添加到容器中
#初始化模型参数
net[0].weight.data.normal_(0,0.01)#权重参数服从正态分布
net[0].bias.data.fill_(0)#偏差值为0(fill_ 直接修改 data 中的值,将其全部设置为指定的数值)
#损失函数
loss=nn.MSELoss()
#优化算法——梯度下降
trainer=torch.optim.SGD(net.parameters(),lr=0.03)#torch.optim是PyTorch 中的一个模块,用于实现各种优化算法, net.parameters()返回一个迭代器包含模型中的所有可学习参数
#训练
num_epochs=3
for epoch in range(num_epochs):
for X,y in data_iter:
l=loss(net(X),y)
trainer.zero_grad()#清除之前的梯度(因为梯度默认累加)
l.backward()#对损失函数进行反向传播,计算每个参数的梯度
trainer.step()#根据计算出的梯度更新模型的参数(告诉优化器执行一次学习步骤,即根据当前批次的梯度调整模型的权重,根据选择的优化算法进行更新)
l=loss(net(features),labels)
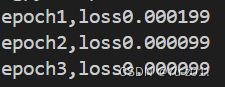
print(f'epoch{epoch+1},loss{l:f}')
运行结果显示















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









