






本文是笔者在学习深度学习过程中的代码分享,主要是对实现代码的一些注释
dl库中的函数
###softmax回归
#加载图片分类数据集
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=4,pin_memory=False),
data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=4,pin_memory=False))
#累加器实现
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):#类的初始化方法,self 是对当前对象实例的引用,而n 表示将要累加的变量的数量
self.data = [0.0] * n#创建了列表包含 n 个初始值为0.0的浮点数于存储累加的结果
def add(self, *args):#累加
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):#重置
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):#索引
return self.data[idx]
#正确预测数量
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)#获取最大元素(概率最大)的索引值
cmp = y_hat.type(y.dtype) == y#与标签进行比较预测是否正确
return float(cmp.type(y.dtype).sum())#总数
#计算精度
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
net.eval() # 将模型设置为评估模式(不进行参数更新)
metric = Accumulator(2) # 累加器保存正确预测数、预测总数
with torch.no_grad():#关闭梯度下降
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())#numel获取该张量中的元素总数
return metric[0] / metric[1]#正确预测/预测总数
#迭代周期
def train_epoch_lnn(net, train_iter, loss, updater):
"""训练模型一个迭代周期"""
net.train()# 将模型设置为训练模式
metric = Accumulator(3) #累加器保存训练损失总和、训练准确度总和、样本数
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)#计算标签值,实现为softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
#softmax:X_exp = torch.exp(X),partition = X_exp.sum(1, keepdim=True),X_exp / partitio应用广播机制
l = loss(y_hat, y)#损失函数,实现为- torch.log(y_hat[range(len(y_hat)), y]),
updater.zero_grad()#清空
l.mean().backward()#梯度下降
updater.step()#更新
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]# 返回训练损失和训练精度
#训练模型
def train_lnn(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型"""
#建立三个存储列表
train_losses = []
train_accs = []
test_accs = []#存储每个迭代周期的训练损失、训练准确率和测试准确率
# 遍历每一个训练轮次
for epoch in range(num_epochs):
# 训练模型一个迭代周期,并返回训练损失和准确率
train_loss, train_acc = train_epoch_lnn(net, train_iter, loss, updater)
# 在测试集上评估模型的准确率
test_acc= evaluate_accuracy(net, test_iter)
train_losses.append(train_loss)
train_accs.append(train_acc)
test_accs.append(test_acc)
# 绘制训练过程中的损失和准确率
epochs = range(1, num_epochs + 1)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accs, label='Train Accuracy')
plt.plot(epochs, test_accs, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 使用断言确保训练损失、训练准确率和测试准确率在合理范围内
assert train_loss < 0.5, train_loss#检查训练损失是否小于 0.5,如果 train_loss 大于或等于 0.5,程序将抛出异常,并显示实际的 train_loss 值
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc调用pytorch实现Softmax回归
import torch
from torch import nn
from dl import torch as dl
#加载数据
batch_size = 256
train_iter, test_iter = dl.load_data_fashion_mnist(batch_size)
#初始化模型参数
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))# PyTorch不会隐式地调整输入的形状,在线性层前定义了展平层(flatten),来调整网络输入的形状(将任何维度的tensor转化为2D的tensor)
def init_weights(m):
if type(m) == nn.Linear:
# normal_:正态分布,以均值0和标准差0.01随机初始化权重
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);# apply():当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并将元组或者字典中的参数按照顺序传递给参数
#定义损失函数
loss = nn.CrossEntropyLoss(reduction='none')
#优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)#梯度下降,学习率0.1
#训练模型
num_epochs = 10#训练次数
if __name__ == "__main__":
dl.train_lnn(net, train_iter, test_iter, loss, num_epochs, trainer)运行结果显示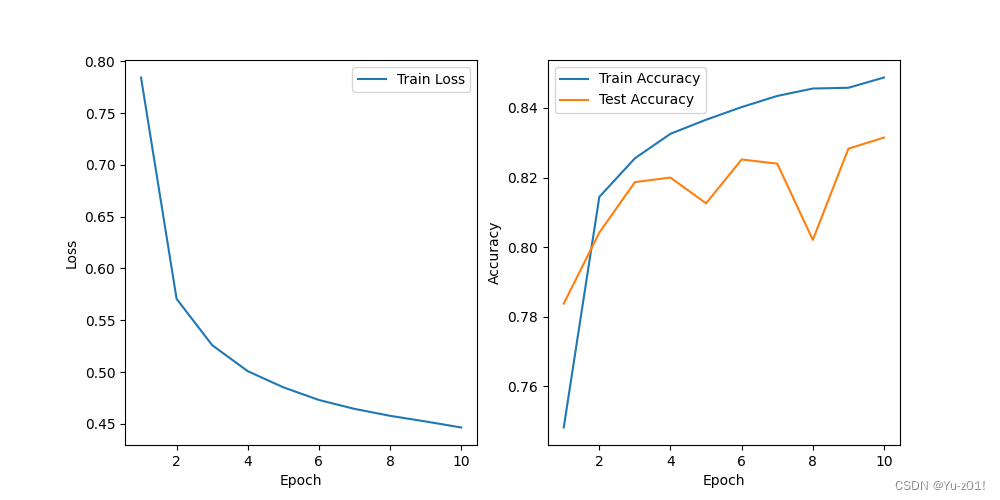















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









