









原文:
Chest X-Ray Images (Pneumonia)
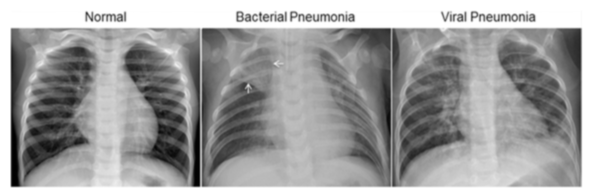
Figure S6. Illustrative Examples of Chest X-Rays in Patients with Pneumonia, Related to Figure 6
The normal chest X-ray (left panel) depicts clear lungs without any areas of abnormal opacification in the image. Bacterial pneumonia (middle) typically exhibits a focal lobar consolidation, in this case in the right upper lobe (white arrows), whereas viral pneumonia (right) manifests with a more diffuse ‘‘interstitial’’ pattern in both lungs.
The dataset is organized into 3 folders (train, test, val) and contains subfolders for each image category (Pneumonia/Normal). There are 5,863 X-Ray images (JPEG) and 2 categories (Pneumonia/Normal).
Chest X-ray images (anterior-posterior) were selected from retrospective cohorts of pediatric patients of one to five years old from Guangzhou Women and Children’s Medical Center, Guangzhou. All chest X-ray imaging was performed as part of patients’ routine clinical care.
For the analysis of chest x-ray images, all chest radiographs were initially screened for quality control by removing all low quality or unreadable scans. The diagnoses for the images were then graded by two expert physicians before being cleared for training the AI system. In order to account for any grading errors, the evaluation set was also checked by a third expert.
译:
胸部X光图像(肺炎)
图S6。肺炎患者胸部X射线的示例,如图6所示
正常胸部X光片(左图)显示的是清晰的肺部,图像中没有任何异常不透明的区域。细菌性肺炎(中)通常表现为局灶性肺叶实变,本例为右上肺叶(白色箭头),而病毒性肺炎(右)表现为两肺更弥漫的“间质”模式。
数据集被组织成3个文件夹(训练、测试、val),并包含每个图像类别(肺炎/正常)的子文件夹。共有5863张X射线图像(JPEG)和两类(肺炎/正常)。
胸部X光图像(前后)取自广州市妇幼医学中心1至5岁儿童患者的回顾性队列。所有胸部X光成像均作为患者常规临床护理的一部分进行。
对于胸部x光图像的分析,所有胸部x光片最初都是通过移除所有低质量或不可读的扫描进行质量控制筛查的。然后由两位专家医生对图像的诊断进行评分,然后再进行人工智能系统培训。为了解释评分错误,第三位专家也对评估集进行了检查。
大家可以到官网地址下载数据集,我自己也在百度网盘分享了一份。可关注本人公众号,回复“202204”获取下载链接。
















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











