






文章目录
工作四年,我学会了用 Idea本地调试线上测试服务器代码
工作四年,我学会了用 Idea本地调试线上测试服务器代码
🔊一位 Java 开发者的使用总结,谈使用经验也聊聊工作原理
📆 一.那些辛酸的过往
历历在目的场景🥹(❁´◡❁)(❁´◡❁)
- 线上出现问题,但是没加日志打印拍脑门惋惜为啥不多打一行日志
- 加日志重新部署,半小时没了,问题还没有找到,头顶的灯却早已照亮了整层楼…
- 排查别人线上的 bug,不仅代码还没看懂,还没一行日志,捏了一把汗!
- 一个问题排查一天,被 Diss 排查问题慢…
- 那些只能发布才能调试、部署一次要半小时的应用,真的会让生命变得廉价
直到我学会了本地debug线上代码,那些曾经束手无策的问题,都变得轻而易举。于是想把这些遇到的场景和用法做个总结。
📕二.远程debug原理
通过启动本地idea中的remoteDebug,启动后本地remoteDebug程序会与服务器上远程代码建立一个socket连接,当用户访问远程服务器端代码接口时,服务器端会先去判断本地idea中是否有断点,有则停在断点,没有则直接走远程服务器返回结果给用户
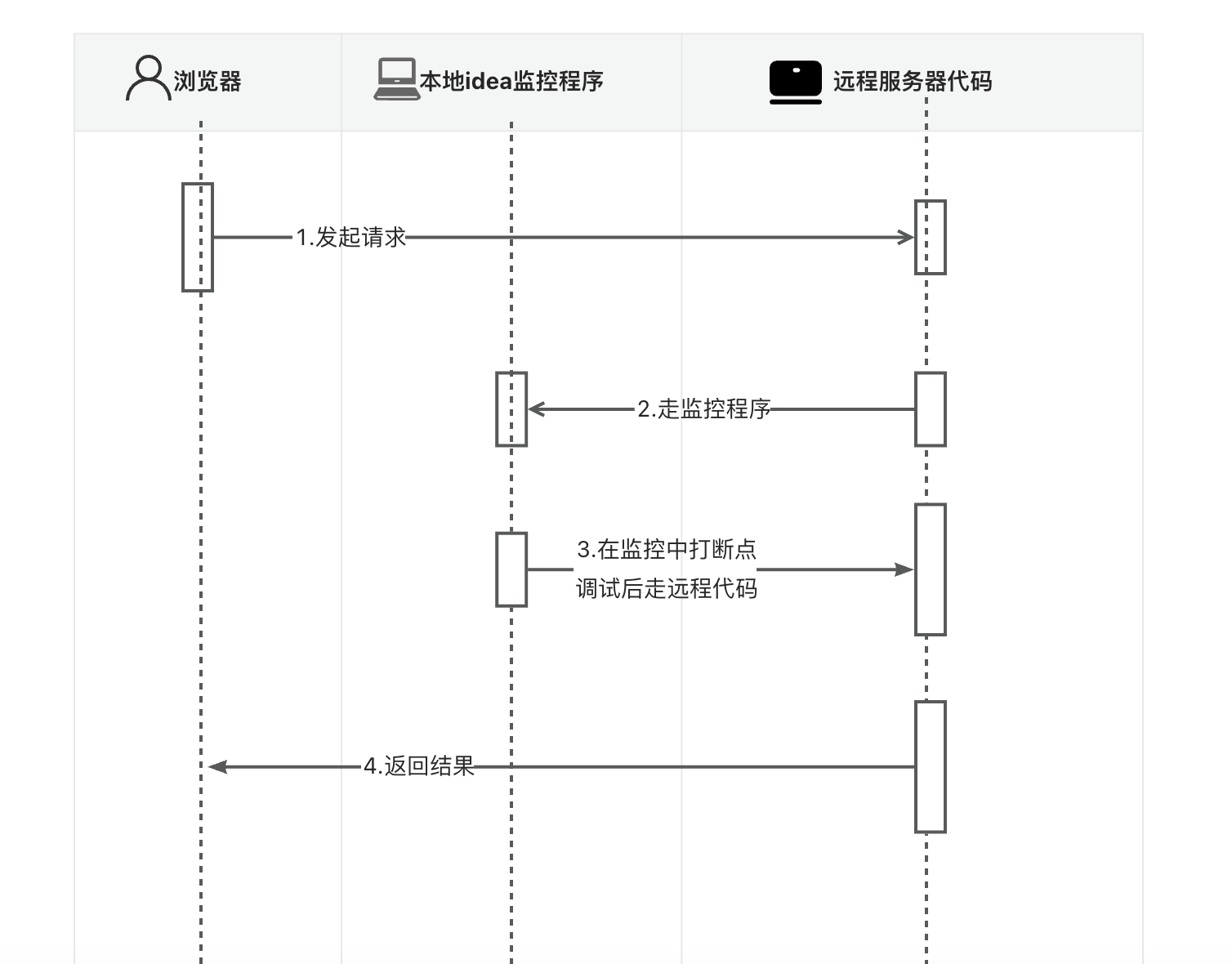
远程调试分类
远程调试分为主动连接调试,和被动连接调试。
主动连接调试:
服务端配置监控端口,本地IDE连接远程监听端口进行调试,一般调试问题用这种方式。
被动连接调试:
本地IDE监听某端口,等待远程连接本地端口。一般用于远程服务启动不了,启动时连接到本地调试分析。
👋三.操作步骤
3.1.准备一个简单springboot程序 例如helloworld
写一个controller

打包成jar包
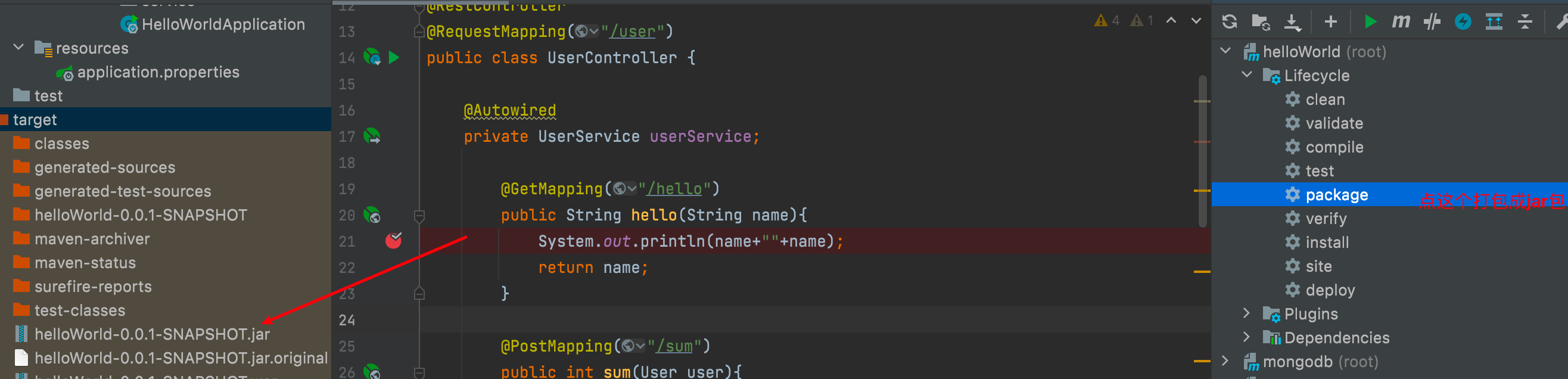
点击配置

3.2.添加远程调试

3.3.配置调试的参数
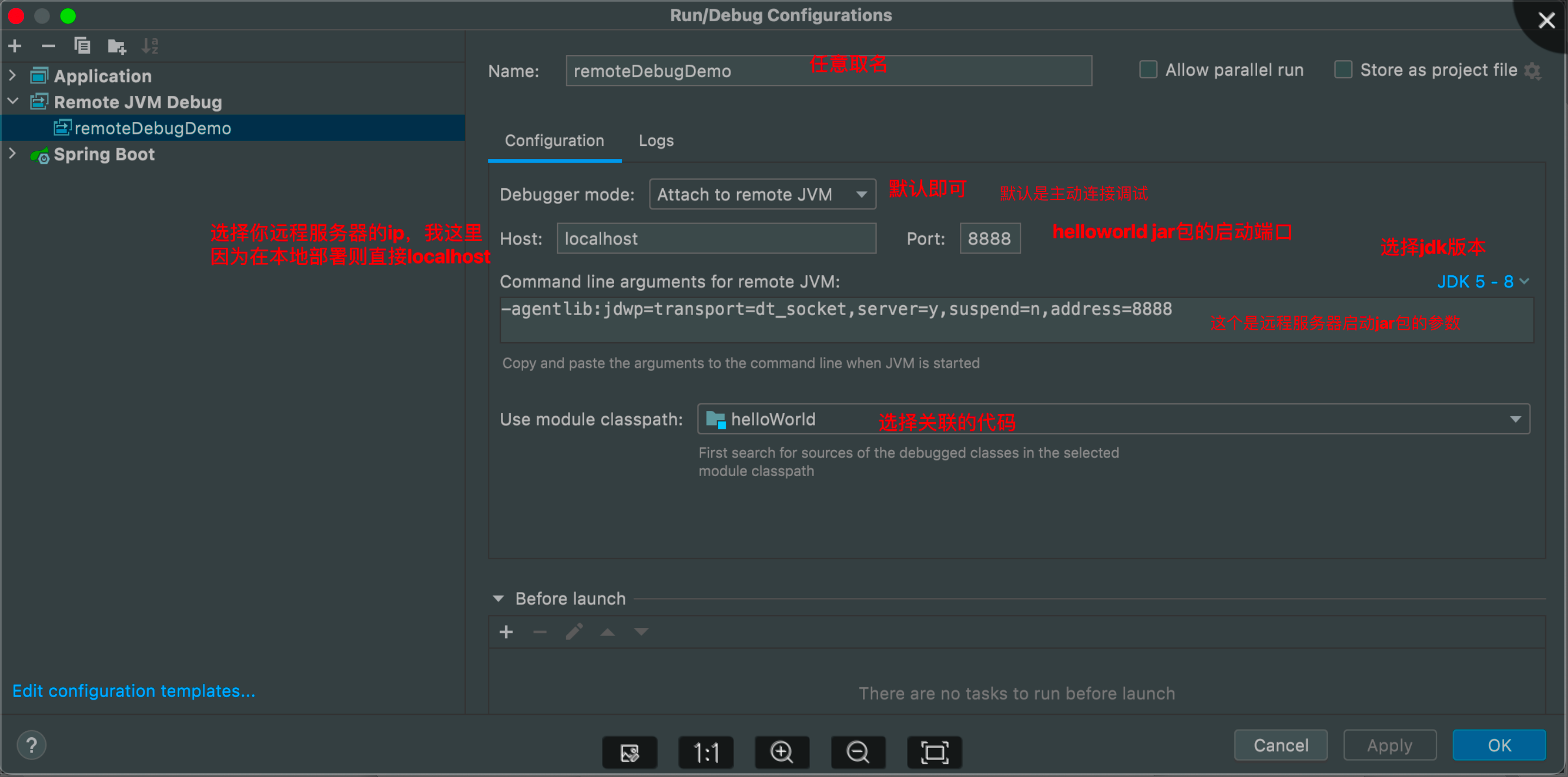
点击ok,然后我们开始启动jar包
3.4.新建一个remotoDemo目录,将jar包复制到remotoDemo目录下,在idea中打开终端

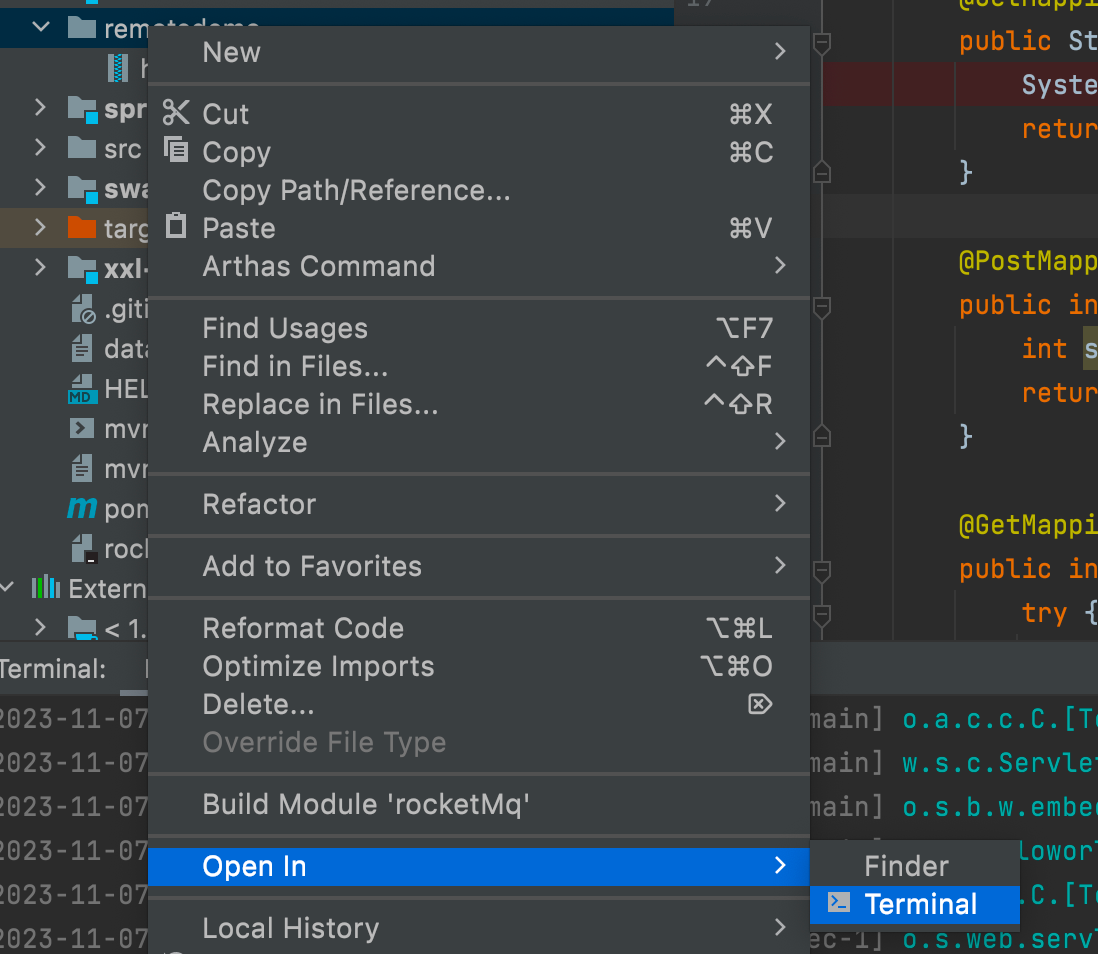
3.5.启动jar包
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8888 -jar helloWorld-0.0.1-SNAPSHOT.jar
如果想后台启动则用
nohup java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8888 -jar helloWorld-0.0.1-SNAPSHOT.jar &
启动效果图

3.6.然后我们启动刚刚配置的remote JVM Debuger

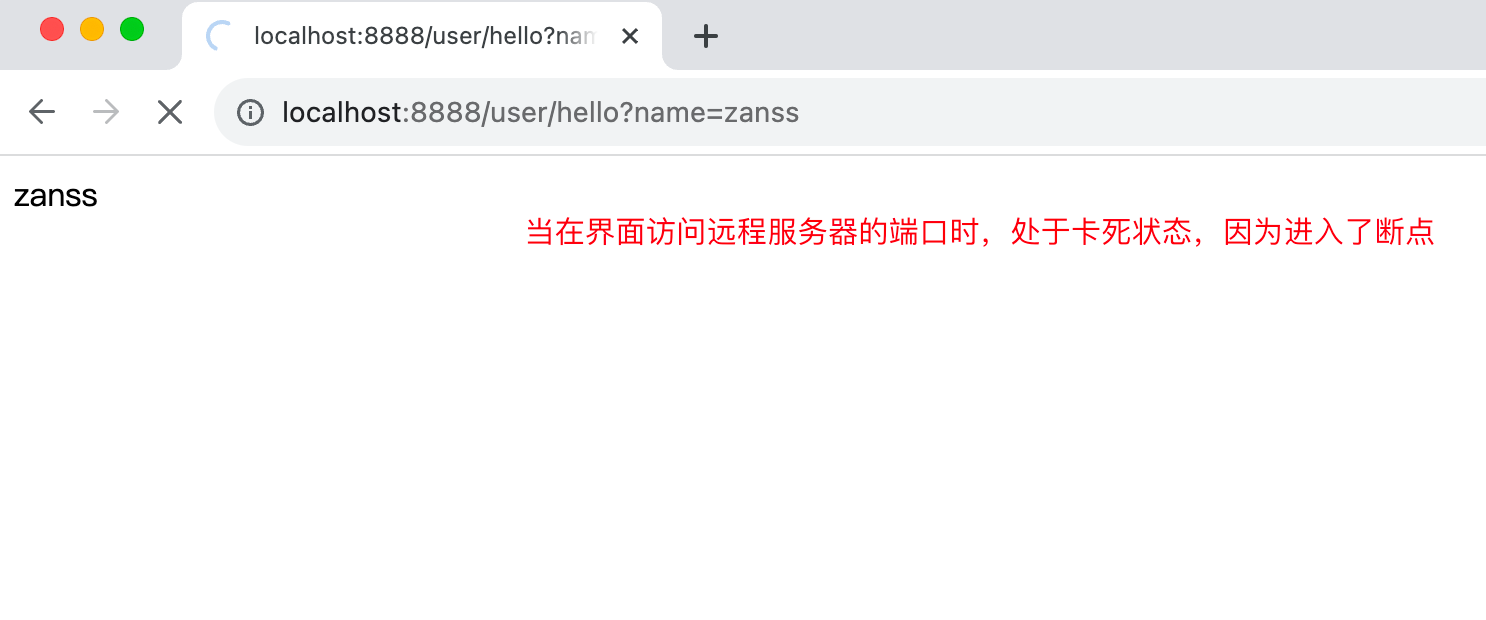
3.7.开始验证
访问远程服务器接口,注意这里访问的localhost:8888访问的是启动的helloworldjar包,而不是remote监控程序,如果你有远程服务器,则可以将jar包放到服务器上,然后通过服务器ip:端口去访问接口,同样会进入断点

🧣四、最后的话
🖲要成为远程debug的好手,一定多多练习:纸上得来终觉浅,绝知此事要躬行。

















 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









